保存数据到文件的模块(configparser,json,pickle,shelve,xml)_python
Posted 陈小赞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了保存数据到文件的模块(configparser,json,pickle,shelve,xml)_python相关的知识,希望对你有一定的参考价值。
一、各模块的主要功能区别
json模块:将数据对象从内存中完成序列化存储,但是不能对函数和类进行序列化,写入的格式是明文。 (与其他大多语言交互的类型)
pickle模块:将数据对象从内存中完成序列化存储,可以能对函数进行序列化,写入的格式是二进制格式wb。 (支持python的所有数据类型,python特有的)
configparser模块:保存字典内容到文件,并按照一定的格式写入文件保存。
shelve模块:将对象写入到文件,保存没有格式。(较为轻便好用)

xml模块:不同语言或程序之间数据交换(早期常用,目前较少用,逐渐被json取代)。
二、各模块使用例子
1、configparser模块
(1)写入文件
import configparser
config=configparser.ConfigParser()
config[\'default\']={\'name\':\'chen\',\'age\':21,\'sex\':\'male\'} #字典格式的内容1
config[\'default2\']={\'class\':\'1\',\'num\':\'43\',\'team\':\'6\'} #字典格式的内容2
f=open(\'configfile\',\'w\') #创建一个文本
config.write(f) #将字典内容写入文本
保存格式:
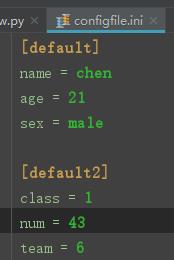
(2)读取文件内容
config=configparser.ConfigParser()
config.read(\'configfile.ini\')
print(config.sections()) #[\'default\', \'default2\'],查看键值
print(config[\'default\'][\'age\']) #21,读取分区里面键值内容
(3)修改文件内容
config=configparser.ConfigParser()
config.read(\'configfile.ini\') #先读取文件放到内存
config.remove_section(\'default2\') #对内存文件进行修改,这里是删除分区
config.set(\'default\',\'name\',\'chenchenchen\') #将分区里面的\'name\'键对应的值改为\'chenchen\'
config.add_section(\'ddd\') #增加分区
config.set(\'ddd\',\'dddd\',\'ddddd\') #添加分区内容
f=open(\'configfile.ini\',\'w\') #直接覆盖
config.write(f) #将已修改的内存文件内容保存到硬盘文件
2、shelve模块(较为轻便,好用)
(1)写入文件
import shelve
f=shelve.open(\'shelvetest\') #创建文件
f[\'default\']=1 #写入内容,值可以是数值,字典,函数等等数据类型
f.close()
(2)读取文件
f=shelve.open(\'shelvetest\') #创建文件
data=f.get(\'default\')
print(data) #1
f[\'default\']={\'name\':\'chen\',\'age\':21,\'sex\':\'male\'}
data=f.get(\'default\')
print(data) #{\'name\': \'chen\', \'age\': 21, \'sex\': \'male\'}
保存格式:

3、json模块
(1)写入文件
import json
dic={\'name\': \'chen\', \'age\': 21, \'sex\': \'male\'}
data=json.dumps(dic) #序列化简化
f=open(\'json.txt\',\'w\')
f.write(data) #写入
f.close()
保存格式:明文

(2)读取文件
f=open(\'json.txt\',\'r\')#打开文件
data=f.read() #读取文件
data=json.loads(data) #反序列化,反简化
print(data)
注:一般使用dump一次和load一次,否则数据容易混乱
4、pickle模块(对比json,可以对包括函数和类的对象做序列化)
(1)写入文件
import pickle
def add():
print(\'add\')
data=pickle.dumps(add)
f=open(\'pickle.txt\',\'wb\') #注意这里写入的是二进制格式,不是明文,这也是与json不同的点
f.write(data)
f.close()
保存格式:
(2)读取文件
f=open(\'pickle.txt\',\'rb\') #对应也是需要二进制b读取
data=f.read()
data=pickle.loads(data) #取出变量名
data() #函数取出的是变量名add,需要执行的话脚本里面还要有add函数本体。若是保存其他对象的话,可以直接打印,如列表
json和pickle模块通用方法:
dump(简化,相当于dumps和write的功能)
f=open(\'pickle.txt\',\'wb\')
data=pickle.dump(add,f) #相当于后面两行
# data=pickle.dumps(add)
# f.write(data)
f.close()
load(简化,相当于loads和read的功能)
f=open(\'pickle.txt\',\'rb\')
data=pickle.load(f) #相当于后面两行一起
# data=f.read()
# data=pickle.loads(data) #
print(data)
5、xml模块(了解)
不同语言或程序之间数据交换的协议
(1)python处理xml


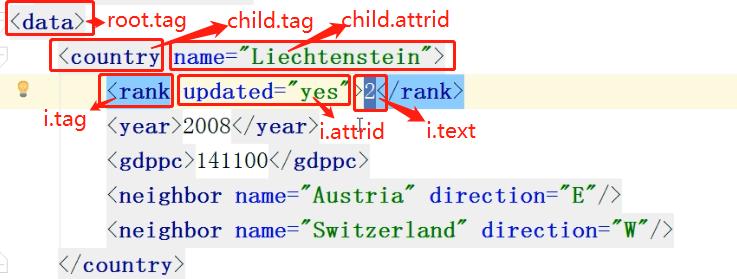

(2)修改
读取之后修改写回
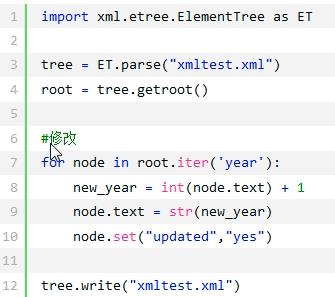
修改之后:
(3)删除:

(4)创建:

以上是关于保存数据到文件的模块(configparser,json,pickle,shelve,xml)_python的主要内容,如果未能解决你的问题,请参考以下文章