python| MongoDB聚合(countdistinctgroupMapReduce)
Posted 人生见识大于知识 | 经历大于学历 Huang Jiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python| MongoDB聚合(countdistinctgroupMapReduce)相关的知识,希望对你有一定的参考价值。
1. count:返回集合中文档的数量。
db.friend.count()
db.friend.count({\'age\':24})
增加查询条件会使count查询变慢。
2. distinct:找出给定键的所有不同的值。
使用时必须指定集合和键:
db.runCommand({\'distinct\':\'friend\',\'key\':\'age\'}),返回一个文档,\'value\'键的值就是这个\'age\'键的所有不同值组成的数组。
或:
db.friend.distinct(\'age\'),直接返回\'age\'键的所有不同值组成的数组。
3. group:分组统计。
示例:找出相同年龄(age)中,积分(score)最高的人。
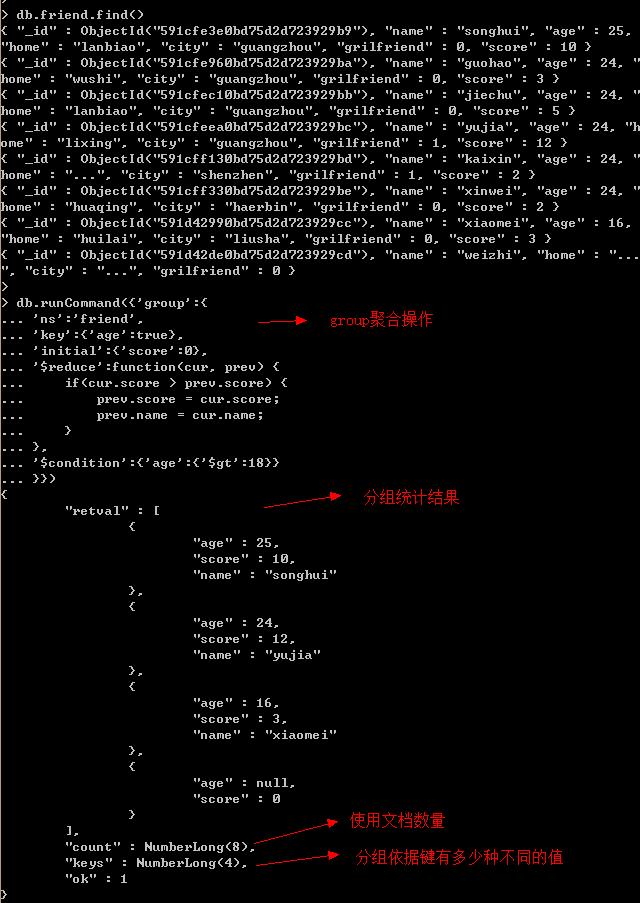
参数说明:
ns:指定要进行分组的集合。
key:指定文档分组依据的键,键值相同的所有文档分为一组。
initial:每一组reduce函数调用时作为第二个参数传递给reduce函数的初始文档,每一组的所有成员都会使用这个累加器,所以改变会被保留住。
$reduce:每个文档都对应一次这个调用,两个参数分别是当前文档和累加器文档(本组当前的结果)。每一组都有一个独立的累加器存储本分组的结果。
condition:只处理满足条件的文档。
finalize:函数,完成器,在每组结果传递到客户端之前被调用一次,用以精简从数据库传到用户的数据。
例如,在上面的例子中可以在group中加入finalize参数来去除结果中的’age’键:
‘finalize’: function(prev) {
delete prev.age;
}
(参数prev是每个分组结果文档)
$keyf:将函数作为键使用,用作分组依据。当分组依据变得复杂,不再只是一个简单的键值那么简单的时候,’key’参数已经无法满足需求,此时可以使用’$keyf’参数,它可以依据各种复杂的条件进行分组。
使用场景之一:依据分组键值进行分组,但忽略大小写。
‘$keyf’: function(x) {
return {‘name’:x.name.toLowerCase()};
}
(参数x表示当前文档对象,返回值一定要是一个对象,对象的键即是分组键。group中不能同时包含key参数和$keyf参数)
注意:分组依据键不存在的文档会被分到一组,并显示键值为null,可以在condition参数中加入{‘$exists’:true}来去掉这一组。
4. MapReduce:
使用MapReduce的代价就是速度慢,不能用在“实时”环境中。要作为后台任务来运行MapReduce,创建一个保存结果的集合,然后对这个集合进行实时查询。
示例:找出集合中的所有键。
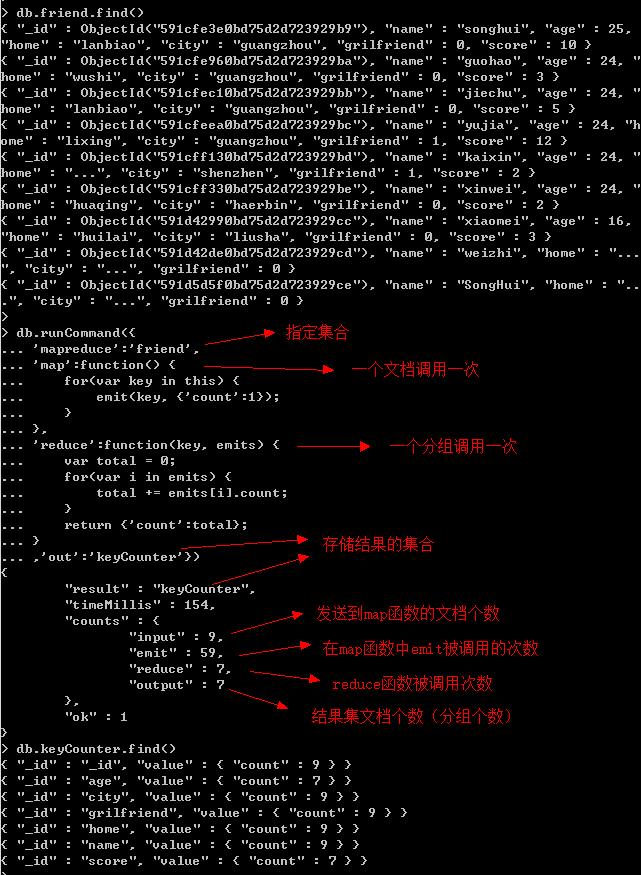
参数说明:
mapreduce:字符串,指定需要进行MapReduce操作的集合的名称。
map:函数,分组函数,将集合中的文档根据某个键的值进行分组(一个文档调用一次)。
reduce:函数,每个分组的处理函数(一个分组调用一次)。
在以上例子中,执行完map函数之后,传递给reduce函数的参数格式类似:key为’age’,emits为[{‘count’:1},{‘count’:1},{‘count’:1}...]。
最终产生的结果集中”_id”键值为分组key的键值,”value”则是reduce函数返回的内容,目前reduce函数不支持返回数组,会报错:multiple not supported yet。
finalize:函数,处理reduce调用之后产生的结果,MapReduce的最后一步(一般用于清除多余信息)。
keeptemp:布尔,连接关闭时临时结果集合是否保存。
out:字符串,结果集名称,设置该项则隐含着keeptemp:true。不指定’out’参数会报错:’out’ has to be a string or an object。
query:文档,发往map函数前先使用指定条件过滤文档。
sort:文档,发往map函数前先给文档排序。
limit:整数,发往map函数的文档数量的上限。
scope:文档,JavaScript代码中要用到的变量。
scope是MapReduce的作用域键,可以使用“变量名:值”这样的普通文档来设置该选项,然后在map、reduce和finalize函数中就能使用了。
verbose:布尔,是否产生更加详细的服务器日志。(查看MapReduce的运行过程,也可以用print把map、reduce、finalize过程中的信息输出到服务器日志上。)
每个传递给map函数的文档都要事先反序列化,从BSON转换成JavaScript对象,这个过程非常耗资源。要是事先能确定只对集合的一部分文档执行MapReduce,使用query、sort、limit来增加一层过滤层会极大地提高速度。可以在MapReduce操作产生的结果集合上再进行MapReduce操作!
Group的结果集有4MB的大小限制,MapReduce则没有这个限制。
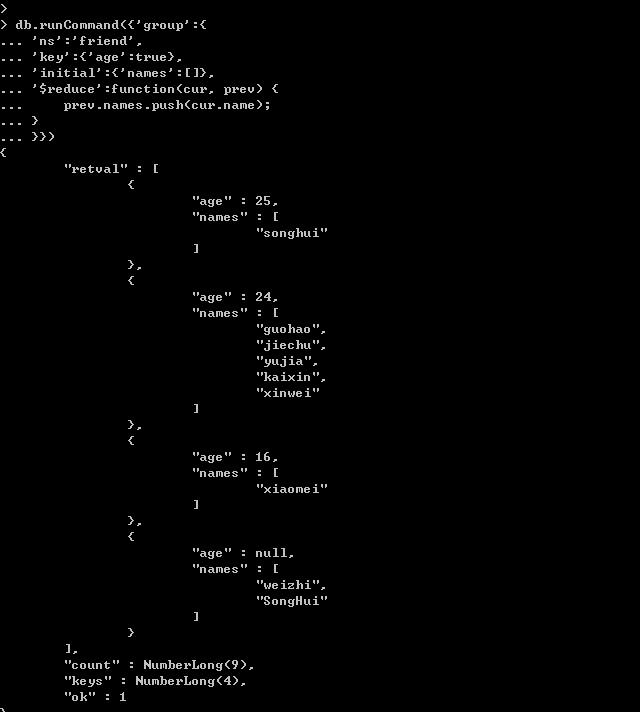
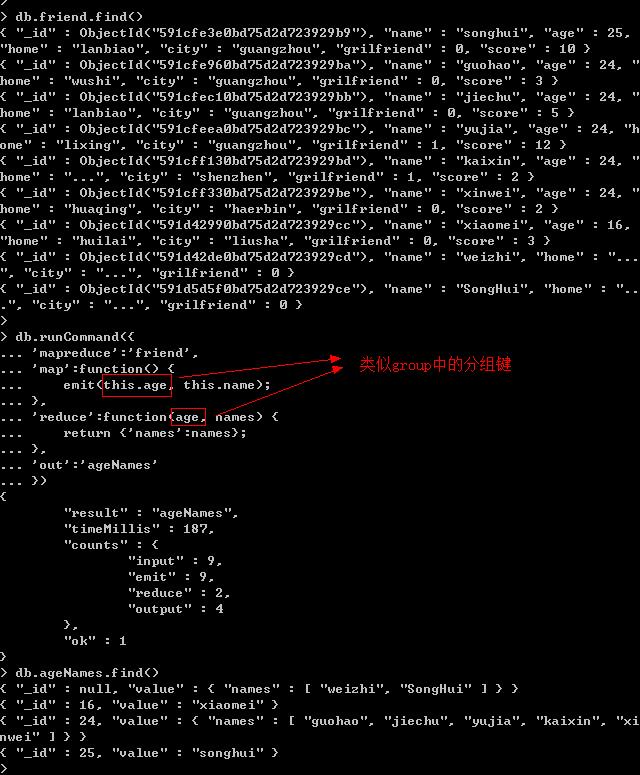
group和MapReduce对比示例:查询相同年龄人的名字。
(1)group:
(2)MapReduce:
以上是关于python| MongoDB聚合(countdistinctgroupMapReduce)的主要内容,如果未能解决你的问题,请参考以下文章