python爬虫——urllib使用代理
Posted kuaidaili
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫——urllib使用代理相关的知识,希望对你有一定的参考价值。
收到粉丝私信说urllib库的教程还没写,好吧,urllib是python自带的库,没requests用着方便。本来嘛,python之禅(import this自己看)就说过,精简,效率,方便也是大家的追求。不过大家有要求,那就写一篇关于urllib的基础教程。
***
本文中的知识点:
- get请求
- 使用代理
- post请求
安装
urllib是python自带的,不用安装,直接import进来即可
代码样例
注意这里需要先定义opener,在打开我们要发送的request请求。返回的字符串编码用utf-8处理
import urllib.request
from urllib.parse import urlencode
opener = urllib.request.build_opener()
# 发送request请求
req = urllib.request.Request('https://www.baidu.com/')
res = opener.open(req)
# 打印response code
print(res.status)
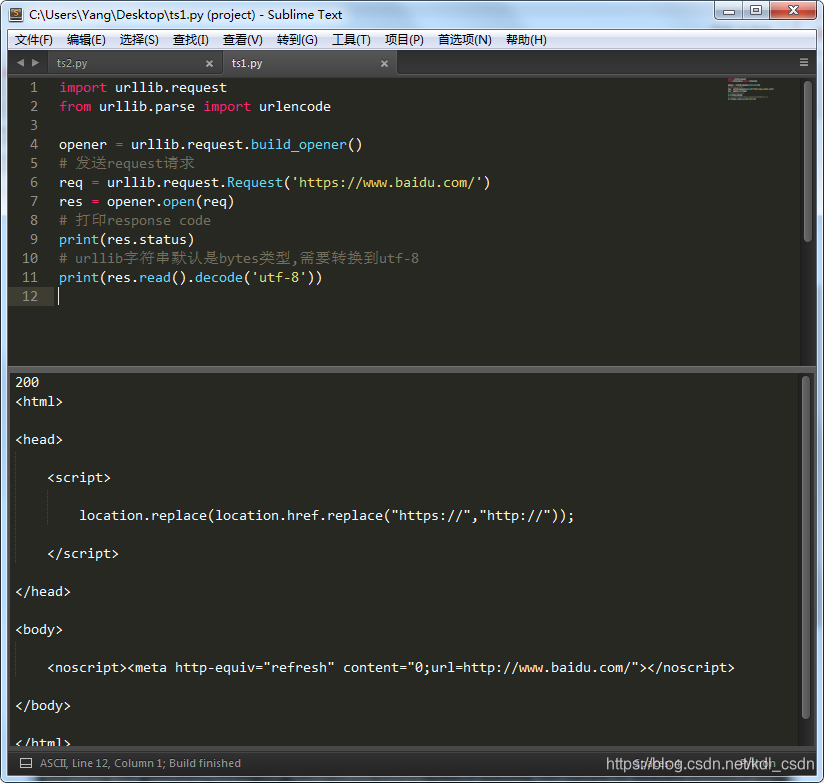
# urllib字符串默认是bytes类型,需要转换到utf-8
print(res.read().decode('utf-8'))运行下,结果如下图
使用代理
注意还是要模拟用户请求,加上header参数
import urllib.request
from urllib.parse import urlencode
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
# 代理IP,由快代理提供
proxy = '124.94.203.122:20993'
proxy_values = "%(ip)s" % {'ip': proxy}
proxies = {"http": proxy_values, "https": proxy_values}
# 设置代理
handler = urllib.request.ProxyHandler(proxies)
opener = urllib.request.build_opener(handler)
# 发送request请求
req = urllib.request.Request('https://www.baidu.com/s?ie=UTF-8&wd=ip', headers=headers)
res = opener.open(req)
# 打印response code
print(res.status)
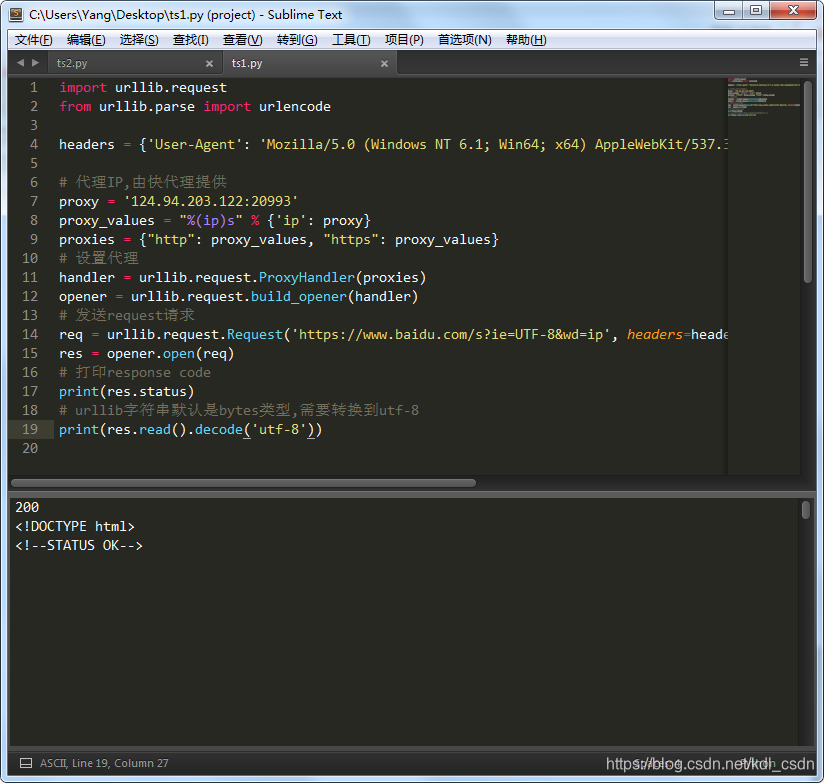
# urllib字符串默认是bytes类型,需要转换到utf-8
print(res.read().decode('utf-8'))运行下,结果如下。正常打开了这个网页
 ***
***
POST请求
上述的默认使用的是get请求,那要使用post加一个method参数即可。
注意method参数POST是大写,因为我的urllib源码提示得大写。不过有的同学小写也可以,大家可以自己试下。
import urllib.request
from urllib.parse import urlencode
page_url = 'https://dev.kdlapi.com/testproxy/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
# 代理IP,由快代理提供
proxy = '115.203.13.59:21216'
proxy_values = "%(ip)s" % {'ip': proxy}
proxies = {"http": proxy_values, "https": proxy_values}
# 设置代理
handler = urllib.request.ProxyHandler(proxies)
opener = urllib.request.build_opener(handler)
# 发送request post请求
data = bytes(urlencode({"info": "send post request"}), encoding="utf-8")
req = urllib.request.Request(url=page_url, headers=headers, data=data, method="POST")
res = opener.open(req)
# 打印response code
print(res.status)
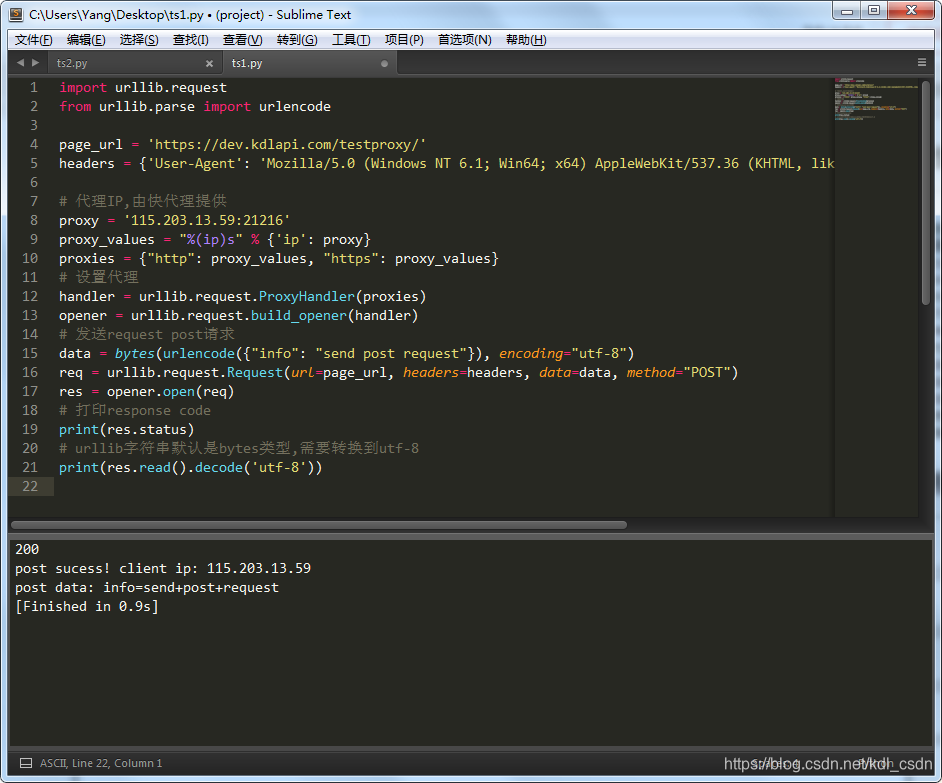
# urllib字符串默认是bytes类型,需要转换到utf-8
print(res.read().decode('utf-8'))运行下试试,post成功,如图
进阶学习:
- urllib库,自己看下帮助文档或者源码吧。。。(滑稽)
- 代理IP的使用
以上是关于python爬虫——urllib使用代理的主要内容,如果未能解决你的问题,请参考以下文章
Urllib库基本使用详解(爬虫,urlopen,request,代理ip的使用,cookie解析,异常处理,URL深入解析)