selenium webdriver从安装到使用(python语言),显示等待和隐性等待用法,切换窗口或者frame,弹框处理,下拉菜单处理,模拟鼠标键盘操作等
Posted 白杨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了selenium webdriver从安装到使用(python语言),显示等待和隐性等待用法,切换窗口或者frame,弹框处理,下拉菜单处理,模拟鼠标键盘操作等相关的知识,希望对你有一定的参考价值。
selenium的用法
selenium2.0主要包含selenium IDE 和selenium webDriver,IDE有点类似QTP和LoadRunner的录制功能,就是firefox浏览器的一个插件,用来录制在浏览器的一系列操作,录制完成后可以回放,可以转换为代码输出出来。本节主要讲的是selenium的webdriver功能。结合Python语言来讲解具体用法。
WebDriver 的实现原理:
WebDriver直接利用了浏览器的内部接口来操作浏览器。
对于不同平台中的不同浏览器,必须依赖浏览器内部的 Native Component (原生组件)来实现把对WebDriver API 调用转化为对浏览器内部接口的调用。
Selenium 1.0采用JavaScript的合成事件来处理网页元素的操作,例如要单击某个页面元素,要先使用JavaScript 定位到这个元素,然后触发单击事件。
而 WebDriver 使用的是系统的内部接口或函数,首先是找到这个元素的坐标位置,并在这个坐标点触发一个鼠标左键的单击操作。
环境配置
在使用之前,首先要将用到的环境配置好,这里主要需要两个环境,一个是selenium库,是一个第三方库,用pip install selenium安装即可,或者可以去pypi官网下载安装。(这里要注意版本要和webdriver对应,所以可以先不装这个,先装webdriver。)第二个环境就是浏览器的webdriver下载。
ChromeDriver的安装
下载地址:http://chromedriver.storage.googleapis.com/index.html
如果下载后,使用的过程中出现问题,可以检查一下是否因为driver的版本和浏览器不兼容,有一个对应关系:
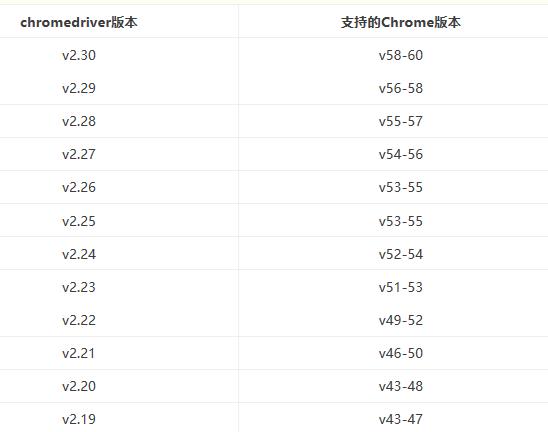
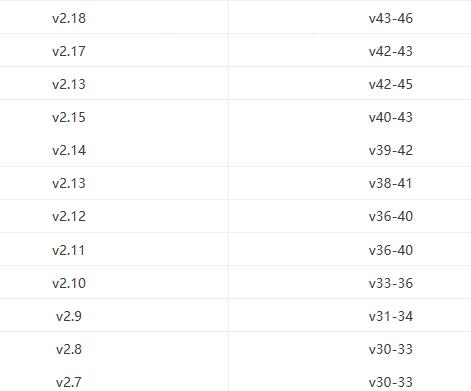
Firefox的webdriver下载安装
我当时下载Firefox也是费了很大劲,刚开始所有都是用的最新版本,结果调用浏览器总是报错,后来把版本降低才可以,并且这里driver和Firefox也有对应关系,并且selenium3.6也只能支持Firefox47.0以上的版本.
从网上查的是:firefox 47+selenium 3.13.0+geckodriver 0.15.0
或者selenium3.5.0,firefox57,geckodriver-v0.19.1
我自己的笔记本配置也不是很好,所以我用的更低版本,目前看来这个版本还挺好用,selenium用的2.48.0,Firefox用的35版本,网盘地址:
https://pan.baidu.com/s/10KKwT5y4QPYRaZ4alniOgA
如果想自己下载更新版本,也可以到下面这个网址去下
下载地址:https://github.com/mozilla/geckodriver/releases/
注意:如果想要使用低版本,但是selenium已经装了最新的版本,可以使用pip uninstall selenium去卸载掉,卸载之后重新装pip install selenium==2.48.0。pip show selenium指令可以查看你自己安装的版本。
再注意:Firefox浏览器要关闭更新,找到选项--高级--更新,选择不检查更新,点击确定,就可以了。一定要关闭自动更新。
IE的webdriver安装
下载网址:https://www.nuget.org/packages/Selenium.WebDriver.IEDriver/
配置driver
下载好driver之后将下载下来的exe文件直接放到Python的安装目录即可。
2. selenium webdriver用法
2.1 driver的一般操作
使用webdriver之前要先导入模块:
from selenium import webdriver
使用webdriver写自动化测试脚本的步骤:
第一步:获取浏览器的驱动,driver
第二步:打开待测试网址
第三步:找到你需要操作的元素,对这些元素进行单击,双击,输入文字等操作
第四步:关闭浏览器
对应的代码:
driver = webdriver.Firefox() #将火狐浏览器的驱动赋值给driver,这样driver就可以有很多可以使用的方法了,比如下面这个打开一个网址的方法 driver = webdriver.Chrome() #获取谷歌浏览器驱动 driver = webdriver.Ie() #获取IE浏览器驱动 driver.get(\'http://www.baidu.com\') driver.quit() #关闭driver driver.close() #关闭当前页面
driver的其他常用方法或者属性:
获取当前页面标题内容 driver.title
查看浏览器的名字 drvier.name
获取当前网页地址 driver.current_url
获取当前页面元素 driver.page_source
回退到之前打开的页面 driver.back()
前进到回退之前的页面 driver.forward()
页面刷新 driver.refresh()
截取当前页面并保存到1.png driver.get_screenshot_as_file("..\\\\1.png")
设置浏览器窗口大小:
driver.set_window_size(800,600)
driver.maximize_window()
例如:
# encoding=utf-8 from selenium import webdriver driver = webdriver.Chrome() driver.get(r\'http://www.baidu.com\') driver.maximize_window() print(driver.title)
2.2 find_element_by_xxx方法查找页面上的元素
元素定位有很多种方法,比如通过元素的id属性,name属性,link_text属性,class属性,xpath或者css等
driver.find_element_by_id(\'su\') #寻找id为’su’的元素 driver.find_element_by_name(\'wd\') #寻找name为’wd’的元素 driver.find_element_by_link_text(\'贴吧\') #寻找链接文本信息为’贴吧’的元素 driver.find_element_by_class_name(\'c-tips-container\') #寻找classname为’c-tips-container’的元素 driver.find_element_by_tag_name(\'div\') #寻找标签名带有’div’的元素 driver.find_element_by_partial_link_text(\'新\') #寻找链接文本部分带有’新’的元素 driver.find_element_by_xpath(\'//*[@id="kw"]\') #寻找id属性为kw的元素 driver.find_element_by_css_selector(\'#kw\') #寻找id属性为kw的元素
前面六种都比较简单,第一种,根据id定位,什么时候使用呢?一般就是你要查找的这个元素有id属性并且id属性的值在网页中是唯一的。name,classname也同id一样。使用方法就是调用driver的driver.find_element_by_id(\'su\'),参数传你要查找的元素的id属性值。
link_text查找的是一个链接,根据链接的文本信息的内容进行查找。
tag_name按照标签的名字进行查找,不常用。
partial_link_text同link_text,但是后面的内容可以不用写全部的值。比如下面这个元素<a href="http://news.baidu.com" name="tj_trnews" class="mnav">新闻</a>
想找到这个元素,就可以这样写:driver.find_element_by_partial_link_text(\'新\'),前提是你的网页没有别的包含新的链接。如果有的话,默认是找到的第一个,如果没找到,会抛NoSuchElementException的异常。
xpath和css在另外的博客随笔里单独介绍了,这里就不说明了,这么多种定位元素的方法,应该用哪种呢?基本常用的有通过id,name,class,然后就是xpath或者css了,xpath和css基本上所有的元素都可以定位到,所以一定要学习一下。通常用这两个其中的一种就足够了。推荐使用css,写法更简单,速度更快。但是如果后面要做移动自动化,还得学习一下xpath,因为安卓自动化里面用的是xpath。
2.3 find_elements_by_xxx
driver还有一些和find_element_by_xxx类似的方法叫find_elements_by_xxx,这类方法返回的是一个列表,比如driver.find_elements_by_id(\'su\') 这样写就获取到了页面上所有id属性为su的元素。想要使用第几个元素,用下标取即可。
2.4 对找到的元素进行操作
获取元素坐标:
driver.find_element_by_id(\'su\').location
在百度文本搜索框内输入内容Python Selenium:
driver.find_element_by_name(\'wd\').send_keys(\'Python Selenium\')
清空文本搜索框的所有内容:
driver.find_element_by_name(\'wd\').clear()
点击搜索按钮:
driver.find_element_by_id(\'su\').click()
提交搜索按钮:
driver.find_element_by_id(\'su\').submit()
获取搜索框的大小:
driver.find_element_by_id(\'kw\').size
获取控件id为’jgwab’所显示的内容:
driver.find_element_by_id(\'jgwab\').text
获取控件id为’jgwab’的tag名称:
driver.find_element_by_id(\'jgwab\').tag_name
获取控件id为’su’的type属性:
driver.find_element_by_id(\'su\').get_attribute(\'type\')
判断搜索文本框当前是否被显示:
driver.find_element_by_name(\'wd\').is_displayed()
判断元素是否被选中:
driver.find_element_by_id(\'su\').is_selected()
例如百度一下‘python’,先打开百度首页的网址,在输入框输入Python,点击搜索:
# encoding=utf-8
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(r\'http://www.baidu.com\')
driver.find_element_by_id("kw").click()
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys("Python")
driver.find_element_by_id("su").click()
2.5 模拟鼠标操作
需要导入模块:from selenium.webdriver.common.action_chains import ActionChains
注意:当你调用ActionChains()的方法时,不会立即执行,而是会将所有的操作按顺序存放在一个队列里,当你调用perform()方法时,队列中的内容会依次执行。
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
#在搜索文本框利用context_click()进行鼠标右击 ActionChains(driver).context_click(driver.find_element_by_id(\'kw\')).perform() #在搜索文本框利用double_click()进行双击 ActionChains(driver).double_click(driver.find_element_by_id(\'kw\')).perform() #利用drag_and_drop(source,target)从搜索文本框移动到‘百度一下’按钮 ActionChains(driver).drag_and_drop(driver.find_element_by_id(\'kw\'),driver.find_element_by_id(\'su\')).perform() #利用move_to_element()停留在文本搜索框上 ActionChains(driver).move_to_element(driver.find_element_by_id(\'kw\')).perform() #利用click_and_hold()可以点击并且停留在搜索按钮上 ActionChains(driver).click_and_hold(driver.find_element_by_id(\'su\')).perform()
例如:
# encoding=utf-8
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains #导入模块
driver = webdriver.Chrome()
driver.get(r\'http://www.baidu.com\')
label = driver.find_element_by_css_selector("#u1 > a.pf") # 找到百度首页上的设置链接
ActionChains(driver).move_to_element(label).perform() # 模拟用户悬浮
label_bel = driver.find_element_by_link_text("高级搜索") #设置的下拉菜单里的高级搜索链接
label_bel.click() # 模拟用户点击
2.6 模拟键盘操作
需要引入包Keys:
from selenium.webdriver.common.keys import Keys
driver.find_element_by_id(\'kw\').send_keys(Keys.BACK_SPACE) #Backspace键
driver.find_element_by_id(\'kw\').send_keys(Keys.SPACE) #Space键
driver.find_element_by_id(\'kw\').send_keys(Keys.DELETE) #Delete键
driver.find_element_by_id(\'kw\').send_keys(Keys.CONTROL,\'a\') # CTRL + A
driver.find_element_by_id(\'kw\').send_keys(Keys.CONTROL,\'x\') # CTRL + X
driver.find_element_by_id(\'kw\').send_keys(Keys.CONTROL,\'v\') # CTRL + V
driver.find_element_by_id(\'kw\').send_keys(Keys.ENTER) #ENTER键
driver.find_element_by_id(\'kw\').send_keys(Keys.CONTROL,\'c\') # CTRL + C
driver.find_element_by_id(\'kw\').send_keys(Keys.TAB) # TAB键
2.7 切换window或者Frame
对于现在的web应用程序来说,很少有单个window的情况,都是嵌入了其他的frame。WebDrvier支持使用”switchTO”方法切换到其他window。
切换window
获取当前driver的所有窗口的方法:
driver.window_handles
切换到新窗口的方法:
driver.switch_to.window(窗口名或者窗口列表下标)
例如:
from selenium import webdriver
from time import sleep
# 打开chrome浏览器,并执行设置
driver = webdriver.Chrome()
driver.implicitly_wait(30)
driver.maximize_window()
# 打开百度首页
driver.get("https://www.baidu.com")
# 输入 腾讯课堂
driver.find_element_by_id(\'kw\').send_keys(\'腾讯课堂\')
# 点击 百度一下
driver.find_element_by_id("su").click()
# 获取所有窗口
windows = driver.window_handles
print(\'切换之前的窗口{}\'.format(windows))
# 点击腾讯课堂链接
driver.find_element_by_xpath(\'//*[@id="1"]/h3/a[1]\').click()
sleep(4)
# 切换到新窗口
driver.switch_to.window(driver.window_handles[-1])
print(\'切换后的窗口{}\'.format(driver.current_window_handle))
# 点击登录按钮
sleep(5)
driver.find_element_by_id(\'js_login\').click()
切换frame(或者iframe)
方法:driver.switch_to.frame(‘’)
例如:
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.implicitly_wait(30)
driver.maximize_window()
# 打开百度首页
driver.get("https://www.baidu.com")
# 输入 腾讯课堂
driver.find_element_by_id(\'kw\').send_keys(\'腾讯课堂\')
# 点击 百度一下
driver.find_element_by_id("su").click()
# 获取所有窗口
windows = driver.window_handles
print(\'切换之前的窗口{}\'.format(windows))
# 点击腾讯课堂链接
driver.find_element_by_xpath(\'//a[contains(text(),"全部课程_在线 培训 视频 教程_")]\').click()
sleep(4)
# 切换到新窗口
driver.switch_to.window(driver.window_handles[-1])
print(\'切换至后的窗口{}\'.format(driver.current_window_handle))
# 点击登录按钮
sleep(5)
driver.find_element_by_id(\'js_login\').click()
sleep(5)
# 点击QQ登录
driver.find_element_by_xpath(\'//div[@class="content-btns"]/a[1]\').click()
# 切换到qq登录的frame
driver.switch_to.frame(\'login_frame_qq\')
sleep(5)
# 点击账号密码登录
driver.find_element_by_id(\'switcher_plogin\').click()
# 输入账号密码,点确定
driver.find_element_by_id(\'u\').send_keys(\'xx\')
driver.find_element_by_id(\'p\').send_keys(\'xx\')
driver.find_element_by_id(\'login_button\').click()
2.8 显式等待和隐式等待
等待方法:
1.强制等待
time.sleep(3)
强制等待,不管你浏览器是否加载完,程序都得等待3秒,3秒一到,继续执行下面的代码,不建议经常使用这种强制等待方法
2.显性等待WebDriverWait
from selenium.webdriver.support.ui import WebDriverWait
WebDriverWait(driver, 超时时长, 调用频率x, 忽略异常).until(可执行方法, 超时时返回的信息)
WebDriverWait,配合该类的until()和until_not()方法,就能够根据判断条件而进行灵活地等待了,它主要的意思就是:程序每隔x秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException
例如:
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# 打开会话
driver = webdriver.Chrome()
driver.get(\'http://www.baidu.com\')
driver.find_element_by_id(\'kw\').send_keys(\'selenium\')
driver.find_element_by_id(\'su\').click()
# 显性等待,等找到百度翻译selenium这个链接
WebDriverWait(driver,20).until(EC.visibility_of_element_located((By.XPATH,"//div[@id=\'5\']/h3/a")))
#点击百度翻译
driver.find_element_by_xpath("//div[@id=\'5\']/h3/a").click()
print(driver.current_url)
# driver.quit()
3.隐性等待implicitly_wait
driver.implicitly_wait(30)#在页面上隐式等待30 秒
隐性等待是设置一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一步。注意这里有一个弊端,那就是程序会一直等待整个页面加载完成,也就是一般情况下你看到浏览器标签栏那个小圈不再转,才会执行下一步,但有时候页面想要的元素早就在加载完成了,但是因为个别js之类的东西特别慢,我仍得等到页面全部完成才能执行下一步
2.9 弹框处理
操作浏览器的时候偶尔会遇到弹框,一般弹框分为三种:1、警告类弹框alert(),就是只显示一个信息,一个确认按钮那种,用于通知用户;
2、确认类弹框confirm(),有确定和取消两个按钮。
3、消息类弹框,prompt(),需要输入一些信息后再点击确认按钮或者取消按钮。
这些弹框一般都是JavaScript生成的,定位弹框使用的方法是:
driver.switch_to.alert()
找到弹框后对弹框可以做相应的操作:
text 属性,返回 alert/confirm/prompt 中的文字信息
accept() 点击确认按钮。
dismiss() 点击取消按钮,如果有的话。
send_keys() 输入值,这个 alert\\confirm 没有对话框就不能用了,不然会报错。
举例如下:
接受弹窗
driver.switch_to_alert().accept()
得到弹窗的文本消息,比如得到:请输入用户名!
message=driver.switch_to_alert().text
print(message)
取消按钮
driver.switch_to_alert().dismiss()
输入值
driver.switch_to_alert().send_keys(“hello”)
例如:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from time import sleep
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get("http://www.baidu.com")
# 鼠标悬停至"设置连接
link = driver.find_element_by_link_text(\'设置\')
ActionChains(driver).move_to_element(link).perform()
# 打开搜索设置
driver.find_element_by_link_text(\'搜索设置\').click()
sleep(2)
# 保存设置
driver.find_element_by_class_name(\'prefpanelgo\').click()
sleep(2)
# 接受警告框
text = driver.switch_to_alert().text
print(text)
sleep(5)
# 点击确认按钮
driver.switch_to_alert().accept()
sleep(10)
driver.quit()
2.10 下拉菜单处理
假如有一个这样的下拉菜单,默认选中第三个,我们想选中第一个,怎么选?
源代码:
<html>
<body>
<form>
<select name="cars">
<option value="volvo">Volvo</option>
<option value="saab">Saab</option>
<option value="fiat" selected="selected">Fiat</option>
<option value="audi">Audi</option>
</select>
</form>
</body>
</html>
使用python的webdriver来操作的话,如下:
import time from selenium import webdriver from selenium.webdriver.support.select import Select # 导入选中下拉菜单需要用的包 driver = webdriver.Chrome() driver.get(\'file:///C:/Users/Administrator/Desktop/a.html\') time.sleep(2) # 创建一个Select实例,参数传的是select菜单的element对象 s = Select(driver.find_element_by_name(\'cars\')) # 第一种方式可以通过索引,索引从0开始,下面这句表示选择第一个索引的内容Volvo s.select_by_index(0) time.sleep(2) # 第二种方式通过value值,注意value是一个属性 s.select_by_value(\'audi\') time.sleep(2) # 第三种方式通过显示出来的文本值 s.select_by_visible_text(\'Saab\')
上面的例子是选择一个选项,那么怎么取消选择呢?
用s.deselect_by_index(0)
s.deselect_by_value(\'audi\')
s.deselect_by_visible_text(\'Saab\')
s.deselect_all() # 将所有选中的都取消选择
all_selected_options属性是表示哪些元素被选中了,下面可以遍历一下所有被选中的元素:
options = Select(driver.find_element_by_name(\'cars\')).all_selected_options
for option in options:
print(\'已经被选中option文本值:\' + option.text)
selenium IDE用法简介
简单说一下IDE的用法吧,IDE有时候也有点用处,比如你刚开始学习selenium,还不知道怎么下手,可以先用IDE录制的方式去看看IDE是怎么形成自动化测试代码的。
selenium IDE的安装比较简单,去Firefox的附加组件里面去搜索selenium IDE(注意中间有一个空格),安装即可,我发的百度网盘链接里面也有一个IDE插件,可以直接装到我发的那个火狐浏览器版本里面。
安装好之后会有一个这个图标:
这个就是selenium IDE插件了。使用它只需要三步,第一步,点击它,打开如图:
执行第二步:回放:
第三步:导出你想要的脚本
导出脚本以后打开,我导出的是Python2,unittest,webdriver,可以主要参考下面这块,
class TestBaiDu(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url = "https://www.baidu.com/"
# self.verificationErrors = []
# self.accept_next_alert = True
def test_TestBaiDu(self):
driver = self.driver
driver.get(self.base_url + "/")
driver.find_element_by_id("kw").click()
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys("Python")
driver.find_element_by_id("su").click()
以上是关于selenium webdriver从安装到使用(python语言),显示等待和隐性等待用法,切换窗口或者frame,弹框处理,下拉菜单处理,模拟鼠标键盘操作等的主要内容,如果未能解决你的问题,请参考以下文章