使用C语言为python编写动态模块--从底层深度解析python中的对象以及变量
Posted traditional
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用C语言为python编写动态模块--从底层深度解析python中的对象以及变量相关的知识,希望对你有一定的参考价值。
楔子
我们知道可以通过使用C语言编写动态链接库的方式来给python加速,但是方式是通过ctypes来加载,通过类CDLL将动态链接库加载进来得到一个对象之后,通过这个对象来调用动态链接库里面的函数。那么问题来了,我们可不可以使用C语言为python编写模块呢?然后在使用的时候不使用ctypes加载动态库的方式,而是通过python的关键字import进行加载。
答案是可以的,我们知道可以通过编写py文件的方式来得到一个模块,那么也可以使用C语言来编写C源文件,然后再通过python解释器进行编译得到import可以直接导入的模块,这样的模块我们称之为扩展模块。在Windows上文件后缀为pyd(等价于dll),在linux上还是so文件,只不过此时的dll或者so,不再是通过ctypes进行加载了,而是python的import语法可以直接识别,然后调用。
到这里估计很多人已经明白了,C语言在编写原文件之后,是需要python解释器进行编译的,然后才能得到扩展模块。这一过程就决定了在编写C的代码的时候,是需要遵循一定的标准的,只有这样python才能正确得到扩展模块。所以我们在介绍如何使用C编写扩展模块之前,还需要一些python源码的知识。
python中的对象在C语言中的实现
估计用python比较长的人都知道,python中的对象在C中都是一个PyObject(一切皆对象),事实上确实如此,我们下面来看一下python中的对象在C语言中都分别长什么样子。
首先python中的对象本质上就是C语言中的malloc函数为结构体实例在堆区申请的一块内存。python中对象在C中是遵循一定标准的,如果是实例对象,那么都是Py...Object,如果是类对象,那么都是Py..._Type。这些对象底层都是一个结构体或者结构体指针,并且对应的结构体都嵌套了PyObject这个结构体,我们后面会说。
int(): 一个PyLongObject结构体实例的指针, int: 一个PyTypeObject结构体实例(PyLong_Type)str(): 一个PyUnicodeObject结构体实例的指针, str: 一个PyTypeObject结构体实例(PyUnicode_Type)tuple(): 一个PyTupleObject结构体实例的指针, tuple: 一个PyTypeObject结构体实例(PyTuple_Type)list(): 一个PyListObject结构体实例的指针, list: 一个PyTypeObject结构体实例(PyList_Type)dict(): 一个PyDictObject结构体实例的指针, dict: 一个PyTypeObject结构体实例(PyDict_Type)set(): 一个PySetObject结构体实例的指针, set: 一个PyTypeObject结构体实例(PySet_Type)object(): 一个PyBaseObject结构体实例的指针, object: 一个PyTypeObject结构体实例(PyBaseObject_Type)type(): 一个PyTypeObject结构体实例(PyType_Type), type: 一个PyTypeObject结构体实例(PyType_Type)
神秘的PyObjet
我们看到这些类型都非常固定,至于int和str,在python2中是PyIntObject和PyStrObject,但是在python3中改成了PyLongObject和PyUnicodeObject。刚才我们说python一切皆对象,类也是一个对象,它们都嵌套了PyObject这个结构体。下面我们看看这个结构体长什么样子:
typedef struct _object {
//引用计数
Py_ssize_t ob_refcnt;
//类型
struct _typeobject *ob_type;
} PyObject;我们看到这个结构体里面有两个字段,一个是ob_refcnt,一个是ob_type。ob_refcnt表示对象的引用计数,有多少个变量在引用它,Py_ssize_t可以看成是有符号的long long,当然还有一个Py_size_t表示无符号的long long。从这里我们可以知道,python中一个对象的引用计数不能超过Py_ssize_t的存储范围,不过如果不是吃饱了撑的写恶意代码,是不可能超过这个范围的;而ob_type表示对象的类型,就是我们在python中通过type函数、或者__class__得到的结果,我们看到这是一个结构体指针,从定义上来看,我们可以得出,python中内建的类对象在底层都是一个struct _typeobject。
typedef struct _typeobject PyTypeObject;或者是一个PyTypeObject,当然这个结构体里面也嵌套了PyObject,类对象也有引用计数和类型(我们知道是type),只不过像int、str、dict这些类对象的引用计数我们不关心,这是python解释器初始化的时候内部就创建好了的,我们只关心根据类对象创建出来的实例对象。因此目前我们可以得到如下结论:
int()、str()、list()等等实例对象,底层都是不同的结构体实例。int、str、list等等类对象,底层都是同一个结构体(PyTypeObject)实例无论是类对象还是实例对象,底层对应的结构体都嵌套了PyObject,都有引用计数、以及类型。
PyVarObject
我们说像str、tuple、list之类的实例对象,它们有一个共同的特点,就是它们都具有长度的概念,都可以使用len方法计算长度。这些实例对象可以看成是一个容器,里面可以容纳元素。因此像这样的对象,我们称之为变长对象,那么在底层就还需要一个变量,来专门维护变长对象的长度。而这个维护长度的变量和PyObject组合起来就是PyVarObject。而python中的对象大部分都是变长对象,所以我们说底层对应的结构体都嵌套了PyObject,也可以说大部分都嵌套了PyVarObject。
typedef struct {
//一个PyObject
PyObject ob_base;
//一个ob_size,变长对象的长度
Py_ssize_t ob_size;
} PyVarObject;我们看到PyVarObject多了一个ob_size来维护变长对象的长度,另外先剧透一下,这个ob_size还具有其它的意义。比如int对象,我们知道python里面一个整型是没有len方法的,但是不好意思,在底层整型(PyLongObject)也是一个变长对象,而且这个ob_size在PyLongObject中还可以小于0,所以类型是Py_ssize_t,而不是Py_size_t。至于细节如何,我们介绍int实例对象(PyLongObject)的时候再说。
PyObject_HEAD和PyObject_VAR_HEAD
在C语言中有着一个宏的概念,其实就是简单的字符串的替换,为了书写方便。那么python针对PyObject实例和PyVarObject实例分别提供了一个宏。
#define PyObject_HEAD PyObject ob_base;
#define PyObject_VAR_HEAD PyVarObject ob_base;我们看到PyObject_HEAD就是一个PyObject实例,PyObject_VAR_HEAD是一个PyVarObject实例,实例的名字都叫ob_base。另外在C中,一个Py_ssize_t占8个字节,一个指针也占8个字节,所以一个变长对象的大小至少占24个字节,至于具体占多少,则由其它的结构体成员决定了。
PyLongObject解密
整数算是最简单的对象了,我们就从它来"开刀",既然要分析,那么是不是首先得知道长什么样子呢?
底层存储
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
typedef struct _longobject PyLongObject;我们看到PyLongObject是一个变长对象,关键里面还有一个ob_digit,这是一个digit(占四个字节的unsigned int)类型的数组,而ob_size维护的显然是这个数组的长度。很明显这个ob_digit就是存储整型具体的数值的,里面不一定只有一个元素,具体多少由整型的数值大小决定。
但是为什么要用数组呢?其实在python2中,用的就是一个long来存储的,当然那时候结构体名字还叫PyIntObject,而且也不是一个变长对象(PyVarObject),而是一个定长对象(PyObject)。但是在python3中,它变成了数组,因为C中整型是有存储范围的,那么python的做法就是你一个数字存不下,我多用几个不就行啦,根据数值大小决定具体用多少个,用了多少个数组的长度就是多少。
我们说digit是一个unsigned int,总共32位,那么一个digit能表示的最大范围就是2?**?32?-?1,如果我超过了这个范围呢?那就再来一个digit,存不下的位就用新的digit来存。而python的底层就是这么存储的,只是有一点和我们说的不一样,那就是一个digit有32位,但是python只用30位,这么做是为了保证计算的时候方便。
不过还有一个问题,我们说digit是无符号的,如果表示负数怎么办?还记得之前说的ob_size吗?这为老铁除了能表示这个数组用了几个元素之外,还能表示这个整型的正负,如果ob_size为正,说明这个整型为正,反之亦然,所以更准确的说:对于PyLongObject而言,ob_size的绝对值表示数组的元素个数。因此如果存在两个互为相反数的整型,那么它们对应PyLongObject的ob_digit完全一样、而ob_size互为相反数,很好理解吧。如果不好理解,我们来就画图来分析一下,整型的底层存储。
整数0
注意,当要表示的整数为0时,ob_digit这个数组为空,不存储任何值,ob_size为0,表示这个整数的值为0,这是一种特殊情况。

整数1
当存储的值为1的时候,可以看到ob_size变成了1,表示ob_digit这个数组里面只有一个元素。
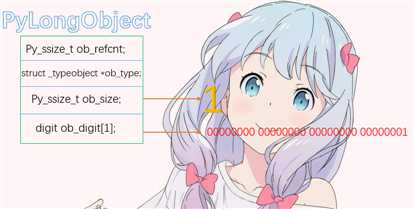
整数-1
当存储的值为负数的时候,ob_size为-1,说明ob_size除了能表示对象的个数,对于PyLongObject来说,还可以表示值的正负。

整数(1 << 30) - 1
30位,表示可以存储的最大数字是(1<<30)-1

整数1 << 30
注意啦,我们说一个digit只用30位,能存储的最大数值为(1 << 30) - 1,现在超过了,那么肯定还需要一个digit

此时我想你应该明白了python中int对象在底层是如何存储的了。
既然弄清了底层存储,那么我相信对于python中的任何一个整型,你都能知道它占多少个字节。
我们说一个PyLongObject是一个变长对象,PyVarObject使得它至少占24个字节,那么具体占多少个字节就由ob_digit数组的元素个数决定了。假设有n个,那么这个整型的大小就是24?+?4?*?n,很好理解。
# 我们说如果为0,那么数组为空,这是个特例,所以大小是24
a1 = 0
print(a1.__sizeof__()) # 24
# 数组只需要一个digit就能存储,所以是 24 + 4 * 1 = 28
a2 = 1
a3 = 2 ** 30 - 1
print(a2.__sizeof__()) # 28
print(a3.__sizeof__()) # 28
# 一个digit只用30位,所以还需要1个,24 + 4 * 2 = 32
a4 = 2 ** 30
a5 = 2 ** 60 - 1
print(a4.__sizeof__()) # 32
print(a5.__sizeof__()) # 32
# 同理,24 + 4 * 3 = 36
a6 = 2 ** 60
a7 = 2 ** 90 - 1
print(a6.__sizeof__()) # 36
print(a7.__sizeof__()) # 36
# 24 + 4 * 4 = 40
a8 = 2 ** 90
print(a8.__sizeof__()) # 40比较大小
我们再来看看两个整数是怎么比较大小的。
static int
long_compare(PyLongObject *a, PyLongObject *b) //接收两个PyLongObject对象的指针
{
Py_ssize_t sign; //8字节的long
//Py_SIZE:这是一个宏,用来获取对象的ob_size
//#define Py_SIZE(ob) (((PyVarObject*)(ob))->ob_size)
if (Py_SIZE(a) != Py_SIZE(b)) {
//我们看到先判断ob_size是否相等
//首先ob_digit的元素个数就越多,那么对应的绝对值越大
//而且对于PyLongObject来说,ob_size还负责正负号的问题
//所以毫无疑问,如果ob_size不相等,是可以直接比较出两者的大小的
sign = Py_SIZE(a) - Py_SIZE(b);
}
else {
//如果相等,说明a和b符号相同,那么不管正负,直接取ob_size的绝对值,得到数组元素个数
Py_ssize_t i = Py_ABS(Py_SIZE(a));
//我们之前说了,数组里面的元素都是大于0的,并且一个元素存储不下,就需要第二个元素
//而比较元素显然是从高位开始比,位数越高,对应的元素的索引越大,所以从数组索引大的元素开始比
//因此在c的层面来说,直接比较对应数组元素的大小即可
/*
a = 011111111 00000000 11111111 00000000 00000000 00000000 00000000 00000001
b = 011111111 00000000 11111111 00000000 00000000 00000000 00000000 00000011
比如这里的a和b,直接比较a->ob_digit[1]和b->ob_digit[1]的大小即可。
a->ob_digit[1]是1, b->ob_digit[1]是2,所以很容易判断b > a
如果a->ob_digit[1]和b->ob_digit[1]一样,那么就比较两者的ob_digit[0]
*/
//所以这里循环进行--i(会先将i减1),然后比较对应数组的元素是否相等
//一旦不相等,结束循环
while (--i >= 0 && a->ob_digit[i] == b->ob_digit[i])
;
//如果对应元素都相等,那么最终i=-1
if (i < 0)
sign = 0; //sign等于0,表示两者相等
else {
//否则的话,必然会存在一个index,使得对应的ob_digit[index]不一样
//直接做差,注意此时的差是a和b的绝对值之差
sign = (sdigit)a->ob_digit[i] - (sdigit)b->ob_digit[i];
//继续判断ob_size是否小于0,如果小于0说明a和b都是负数
//负数的绝对值越大, 那么其实对应的值反而越小
if (Py_SIZE(a) < 0)
//所以是负数的话,还要再加上个负号
sign = -sign;
}
}
//最终判断sign小于0就是-1,否则的话,看它是否大于0,是的话就是1,不是就是0
return sign < 0 ? -1 : sign > 0 ? 1 : 0;
}所以我们看到,python底层数值的比较还是比较复杂的,当然这是由PyLongObject的存储结构所决定的,不过仔细分析的话,发现python的底层并不是那么让人望而生畏。
至于四则运算以及其它的运算,有兴趣的话可以自己杀进源码(Object/longobject.c)中查看,我们这里主要介绍最核心的东西,至于支持的API(比如四则运算、位运算)、缓存机制(比如这里的小整数对象池)等等、这些python提供的功能性的东西我们就不看了,我们只看一些存储结构、底层实现之类的。
创建PyLongObject
我们如何创建一个PyLongObject对象呢?首先在python中,我们怎么创建一个int对象?我们可以直接创建、或者使用int函数将别的类型的对象进行转化。
在底层也是如此,直接创建可以通过_PyLong_New,并且还可以通过其他对象进行转化。
直接创建:_PyLong_New根据long来创建:PyLong_FromLong根据double来创建:PyLong_FromDouble根据char *来创建:PyLong_FromString根据python中的字符串来创建:PyLong_FromUnicode
PyUnicodeObject解密
python中的str在底层的存储比较复杂,因为我们知道在python3中默认都是unicode。
底层存储
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding the
* terminating �. */
char *utf8; /* UTF-8 representation (null-terminated) */
Py_ssize_t wstr_length; /* Number of code points in wstr, possible
* surrogates count as two code points. */
} PyCompactUnicodeObject;
typedef struct {
PyObject_HEAD
Py_ssize_t length; /* Number of code points in the string */
Py_hash_t hash; /* Hash value; -1 if not set */
struct {
unsigned int compact:1;
unsigned int ascii:1;
unsigned int ready:1;
unsigned int :24;
} state;
wchar_t *wstr; /* wchar_t representation (null-terminated) */
} PyASCIIObject;我们看到结构体的定义很复杂,但是只要抓住核心即可。我们看到里面存在着三种unicode编码,分别是latin1、ucs2、ucs4,这三者编码的字符一个分别占1、2、4字节,所以python会根据不同的字符串选择不同的编码。关于介绍怎么选择编码之前,我们先来抛出一个问题。首先我们知道python支持通过索引查找一个字符串中指定位置的字符,而且python中默认是以字符的个数为单位的,比如s[2]搜索的就是字符串s中的第3个字符。
那么问题来了,我们知道python中通过索引查找字符串的指定字符,时间复杂度为O(1)。那么python是怎么通过索引、比如这里的s[2],一下子就跳到第3个字符呢?显然是通过指针的偏移,用索引乘上每个字符占的大小,只有这样才能在定位到指定字符的同时保证时间复杂度为O(1),但是这就需要一个前提:那么就是字符串中每个字符所占的大小必须是相同的,否则如果每个字符占的大小不同,只能通过扫描逐个字符,这样的话时间复杂度肯定不是O(1),而是O(n)。
所以这上面有3个编码,编码的字符每一个分别是1、2、4字节。因此python在创建字符串的时候,会先扫描。或者尝试使用占字节数最少的latin1编码存储,但是范围肯定有限。如果发现了存储不下的字符,只能改变编码,使用ucs2,继续扫描。但是又发现了新的字符,这个字符ucs2也无法存储,因为两个字节最多存储65535个不同的字符,所以会再次改变编码,使用ucs4存储。ucs4占四个字节,肯定能存下了。
一旦改变编码,字符串中的所有字符都会使用同样的编码。比如这个字符串:"hello古明地觉",肯定都会使用ucs2,不存在说"hello"使用latin1,"古明地觉"使用ucs2,一个字符串只能有一个编码。所以尽管python明面上是可变长的utf-8,但那是在encode成字节的时候。对于python中的字符串unicode,所有的部分都是使用同一个编码。
另外关于字符串PyUnicodeObject所占的大小,我们说如果编码是latin1,那么这个结构体实例额外的部分会占49个字节,编码是ucs2,占74个字节,编码是ucs4,占76个字节。然后字符串所占的字节数就等于:额外的部分 + 字符个数 * 单个字符所占的字节
# 此时全部是ascii字符,那么latin1编码可以存储
# 所以结构体实例额外的部分占49个字节
s1 = "hello"
# 有5个字符,一个字符一个字节,所以加一起是54个字节
print(s1.__sizeof__()) # 54
# 出现了汉字,那么latin肯定存不下,使用ucs2
# 所以此时结构体实例额外的部分占74个字节
# 但是别忘了此时的英文字符也是ucs2,所以也是一个字符两字节
s2 = "hello憨"
# 6个字符,74 + 6 * 2 = 86
print(s2.__sizeof__()) # 86
# 这个牛逼了,ucs2也存不下,只能ucs4存储了
# 所以结构体实例额外的部分占76个字节
s3 = "hello憨??"
# 此时所有字符一个占4字节,7个字符
# 76 + 7 * 4 = 104
print(s3.__sizeof__()) # 104除此之外,我们再举一个例子更形象地证明这个现象。
s1 = "a" * 1000
s2 = "a" * 1000 + "??"
# 我们看到s2只比s1多了一个字符
# 但是两者占的内存,s2却将近是s1的四倍。
print(s1.__sizeof__(), s2.__sizeof__()) # 1049 4080
# 我们知道s2和s1的差别只是s2比s1多了一个字符,但就是这么一个字符导致s2比s1多占了3031个字节
# 显然这多出来的3031个字节不可能是多出来的字符所占的大小,什么字符一个会占到三千多个字节
# 尽管如此,但它也是罪魁祸首,不过前面的1000个字符也是共犯
# 我们说python会根据字符串选择不同的编码,s1全部是ascii字符,所以latin1能存下,因此一个字符只占一个字节
# 所以大小就是49 + 1000 = 1049
# 但是对于s2,python发现前1000个字符latin1能存下,但是不幸的是,最后一个字符发现存不下了,只能使用ucs4
# 而字符串的所有字符只能有一个编码,为了保证索引或者切片查找的时候,时间复杂度为O(1),这是python的设计策略
# 因此导致前面一个字节就能存下的字符,每一个也变成了4个字节。
# 而我们说使用ucs4,结构体额外的内存会占76个字节
# 因此s2的大小就是:76 + 1001 * 4 = 76 + 4004 = 4080因此,python面对不同的字符会采用不同的编码。需要注意的是,python中的每一个str都需要额外的占用49-76字节,因为要存储一些额外信息,比如:哈希、长度、字节长度、编码类型等等。这也是为什么一个空字符串要占49个字节。
如果字符串中的所有字符都在ASCII范围内,则使用1字节latin1对其进行编码。基本上,latin1能表示前256个Unicode字符。它支持多种拉丁语,如英语、瑞典语、意大利语、挪威语。但是它们不能存储非拉丁语言,比如汉语、日语、希伯来语、西里尔语。这是因为它们的代码点(数字索引)定义在1字节(0-255)范围之外。
大多数流行的自然语言都可以采用2字节(UCS2)编码。当字符串包含特殊符号、emoji或稀有语言时,使用4字节(UCS4)编码。Unicode标准有将近300个块(范围)。你可以在0XFFFF块之后找到4字节块。假设我们有一个10G的ASCII文本,我们想把它加载到内存中,但如果我们在文本中插入一个表情符号,那么字符串的大小将增加4倍。这是一个巨大的差异,你可能会在实践当中遇到,比如处理NLP问题。
print(ord("a")) # 97
print(ord("憨")) # 25000
print(ord("??")) # 128187为什么python底层存储字符串不使用utf-8
最著名和流行的Unicode编码都是utf-8,但是python不在内部使用它。至于原因我们上面已经解释的很清楚了:
当一个字符串使用utf-8编码存储时,根据它所表示的字符,每个字符使用1-4个字节进行编码。这是一种存储效率很高的编码,但是它有一个明显的缺点。由于每个字符的字节长度可能不同,因此就导致无法按照索引瞬间定位到单个字符,只能通过逐个扫描字符的方法。因此要对使用utf-8编码的字符串执行一个简单的操作,比如string[5],就意味着python需要扫描每一个字符,直到找到需要的字符,这样效率是很低的。但如果是固定长度的编码就没有这样的问题,python只需要将索引乘上一个字符所占的长度(1、2或者4),就可以瞬间定位到某一个字符。所以当Latin 1存储的"hello",在和"憨"这个汉字组合之后,整体每一个字符都会向大的方向扩展、变成了2字节。这样定位字符的时候,只需要将索引成上2即可。但如果原来的"hello"还是一个字节、而汉字是2字节,那么只通过索引是不可能定位到准确字符的,因为不同类型字符的编码不同,必须要扫描整个字符串才可以。但是扫描字符串,效率又比较低。所以python内部才会使用这个方法,而不是使用utf-8。
创建PyUnicodeObject
创建一个PyUnicodeObject,常用方式如下:
直接创建:PyUnicode_New。我们说Py..._New这种创建对象的方式很常见,但是对于int和str来说,还是通过Py..._From...这种形式比较常见。根据ascii字符创建:PyUnicode_FromASCII根据char *创建:PyUnicode_FromString根据unicode创建:PyUnicode_FromUnicode当然还可以根据其他对象创建,PyUnicode_FromWideChar根据宽字符、PyUnicode_FromObject根据对象创建等等
PyUnicodeObject的效率问题
我们说python中的对象除了定长对象和变长对象之外,还可以分为可变(mutable)对象和不可变(immutable)对象。对于可变对象,它维护的是值是可以动态改变的,但是对于不可变对象,如果想改变只能创建新的对象。
比如字符串的拼接,我们知道可以使用+将两个字符串拼接起来,但是这种做法的效率确是非常低下的。因为PyUnicodeObject是一个不可变对象,这就意味着当两个PyUnicodeObject相加时,必须要创建新的PyUnicodeObject对象,维护的字符串是之前的两个对象维护的字符串的拼接。每两个PyUnicodeObject相加就要创建一个新的,那如果n个PyUnicodeObject相加,就意味着除了本来的n个之外还要创建n-1个PyUnicodeObject对象,而且创建了还需要销毁。毫无疑问,这极大地影响了python的效率。
官方推荐的做法是,将n个PyUnicodeObject对象放在list或者tuple中,然后使用PyUnicodeObject的join操作,这样的话只需要分配一次内存,执行效率大大提高。我们来看看底层是如何实现的。
如果是相加的话
PyObject *
PyUnicode_Concat(PyObject *left, PyObject *right)
{
...
//获取两个PyUnicodeObject对象的长度
left_len = PyUnicode_GET_LENGTH(left);
right_len = PyUnicode_GET_LENGTH(right);
...
//相加作为新的PyUnicodeObject对象的长度
new_len = left_len + right_len;
//计算两个字符串的编码对应的字节
maxchar = PyUnicode_MAX_CHAR_VALUE(left);
maxchar2 = PyUnicode_MAX_CHAR_VALUE(right);
//取较大的一个,保证都能存下
maxchar = Py_MAX(maxchar, maxchar2);
//申请一个新的PyUnicodeObject对象,大小为原来两个字符串的长度之和 乘上 maxchar
result = PyUnicode_New(new_len, maxchar);
...
//将原来的两个字符串按照顺序一个字符一个字符拷贝过去
_PyUnicode_FastCopyCharacters(result, left_len, right, 0, right_len);
assert(_PyUnicode_CheckConsistency(result, 1));
return result;
}
//可以看到+这种做法的效率是相当低下的如果采用join的方式
join的话代码比较长,这里就不贴了,但是逻辑不难。就是获取列表或者元组里面的每一个PyUnicode的ob_size、也就是长度,然后加在一起,一次性申请对应的空间,然后再逐一进行拷贝。所以拷贝是避免不了的,+这种方式导致低效率的主要原因就在于大量PyUnicodeObject的创建和销毁。
因此如果我们要拼接大量的PyUnicodeObject,那么使用join列表的方式;如果数量不多,还是可以使用+的,毕竟维护一个列表也是需要资源的。使用join的方式,只有在PyUnicodeObject的数量非常多的时候,优势才会凸显出来。
PyListObject解密
当看到python中的list的时候,我的内心是惊奇的。我们知道python中的list对象是一个大仓库,什么都可以往里面装,里面的类型没有任何要求。于是这就产生了一个问题,我们知道列表也是支持通过索引查找指定位置的元素的,并且时间复杂度是O(1),可是类型不同、占的字节大小也不同,那么它是怎么保证时间复杂度是O(1)的。
我们知道字符串是通过保证所以字符都具有相同的字节做到的,那么列表呢?我们先带着这些疑问,因为在分析列表之前,我们需要一些其它前置的知识,有了这些知识才能更好的理解列表,并且这些知识也会让你对python有一个更加高度的认识。
python中的变量存储与命名空间
我们知道a?= 3这句代码表示创建了一个变量a,a的值为3。并且python和其他静态语言不同,python中是先有值再有变量,a =?3,表示先创建一个PyLongObject对象,这个对象里面的ob_digit数组维护的值是3,有了这个结构体 之后,再让a这个符号指向这个结构体。所以说python中的变量实际上相当于一个便利贴,可以贴在任何地方,至于类型就是对应结构体对象里面的ob_type。因此尽管我们创建变量的时候不需要声明类型,但它实际上是强类型语言,类型是根据python解释器根据创建的结构体对象推断出来的。如果创建的结构体是PyLongObject,那么ob_type就是PyLong_Type。如果此时我们再写上a?= "satori",就表示创建一个PyUnicodeObject,然后让a指向这个新创建的PyUnicodeObject,至于原来PyLongObject,则会因为引用计数变为0,而被回收。
那么问题来了,我们创建的变量a它存在什么地方呢?并且我们在使用a的时候,它是怎么找到a的呢?这里就引入了一个概念:命名空间。
命名空间,就是python用来存储变量以及查找变量的地方,它的底层是一个PyDictObject对象,也就是一个字典。a?= 3就表示在命名空间里面添加一个键值对叫"a": 3,我们在使用a这个变量的时候,会从对应的命名空间那到key等于"a"所对应的value。
像函数、类、模块都有自己的命名空间,我们说对于一个普通的函数来讲,内部变量的查找会从本地作用域、全局作用域、内置作用域里面查找,这个本地作用域就是local命名空间、全局作用域就是global命名空间、内置作用域就是builtins命名空间,因此我们python中对于一个普通函数来讲,变量的查找遵循LGB规则。
对于函数来讲,它的local命名空间显然就是函数的局部作用域,但是global命名空间则是外层模块的全局命名空间。这里稍微扯远一点,python在执行函数的时候,会将其编译成PyFunctionObject对象,于此同时会将外层模块的全局命名空间传递到这个PyFunctionObject对象里面去,只有这样函数内部找不到对应的变量的时候,才会找我们在外部定义的变量。不过对于外层模块来讲,它的local空间和global空间显然是一样的,所以此时就不存在所谓本地和全局。但是对于函数来讲,它local空间和global空间显然是不一样的。这些我们后面还会介绍:
# 在python中获取local空间可以通过函数locals(),获取global空间通过函数globals()
# 我们这里是全局模块,所以两者是一样的。并且这个空间全局唯一,通过locals()或globals()可以直接获取底层的字典
print(locals() == globals()) # True
# 我们说a = 3表示将"a": 3放到了命名空间中,print(a)则是获取key为"a"对应的value
a = 3
print(globals()["a"]) # 3
# 那么我们如果在命名空间中手动放置一个键值对呢?
globals()["b"] = "satori"
# 尽管我们没有直接创建变量b,但是我们说python中查找变量的时候就是到对应的空间里面去找
# 此时命名空间里面有"b"这个key,那么我们就可以使用b这个变量
print(b) # satori
# 如果你用的是PyCharm这样智能的编辑器,会发现这个b下面飘红了,因为它检测到我们没有定义变量b
# 但是却使用了,因为我们通过底层的命名空间设置了变量b我们再来看看函数,我们说python如果看到了def关键字,那么知道这是一个函数,底层会编译成PyFunctionObject,同时会把global空间传进去,那么此时在函数内部就能访问外部的变量。
def foo():
globals()["a"] = 123
try:
# 此时没有定义变量a
print(a)
except NameError as e:
print(e) # name 'a' is not defined
foo()
# 但是一旦当我执行了foo函数,那么就会将"a": 123设置到global空间中
# 我们说函数内部的global空间和外层的global空间是一样的,这是一个字典全局唯一
# 因此这就意味着即便我们是在函数里面设置的,在外部依旧可以访问
print(a) # 123因此此时我想你应该明白python中的变量是怎么存储的了,核心就在于命名空间。变量=值,这种形式就等价于在对应的命名空间设置了?"变量": 值这么一个键值对,查找变量的时候,也就相当于在命名空间中查找key为"变量"对应的值。所以我们看到python中变量的存储是依赖于字典的,像类、实例对象、模块等等都有自己的属性字典。比如一个类的实例对象ins,我们通过ins.attr?= "xx"设置属性,就等价于ins.__dict__["attr"] =?"xx",而ins.attr则等价于ins.__dict__["attr"]。所以字典在python内部是一个高度优化的数据结构,不仅仅是我们在使用,python的内部也在大量的使用这种数据结构。
另外我们说,函数内部的global空间和外层模块的global空间是一样的,其实很好理解,python为了保证函数内部找不到变量的时候能够去外部找,那么就必须要把global空间交给函数,不管这个函数嵌套了多少层。
def f1():
def f2():
def f3():
def f4():
globals()["a"] = "把我藏起来又能怎样?"
return f4
return f3
return f2
f1()()()()
print(a) # 把我藏起来又能怎样?我们看到每创建一个函数都会编译成PyFunctionObject对象,都会把global空间传进去。至于函数的local空间我们后面会详细介绍,其实global空间没啥难的,就是外层模块的global空间,但是函数的local空间显然就是自己独立的了,在函数内部使用locals()获取的就是函数内部的local空间,并且变量会先从local空间查找,这一方面我们后面会细说。
了解python中变量的存储以及命名空间之后,我们再来看看变量的传递,这是理解python中列表时间复杂度为O(1)的关键。
python中的变量传递
我们说python是引用传递,a?=?1;?b?= a就表示将a的引用传递b,让b指向了a所指向的内存。但是有一点我比较好奇,传递引用,这个引用到底是个什么东西,指针吗?还是其他的什么东西,能不能更好量化、或者描述呢。我们还是先通过命名空间来解释这一过程:
a = 1
# 其他的一些信息,比如__name__、__doc__什么的我就不打印了
print(locals()) # {..., 'a': 1}
b = a
print(locals()) # {..., 'a': 1, 'b': 1}我们知道a?= 1,表示将"a": 1放到了命名空间里面,那么b =?a毫无疑问肯定是把a对应的值交给b,组合成"b": 1塞到命名空间里面,我们还可以看看字节码:
1 0 LOAD_CONST 0 (1)
2 STORE_NAME 0 (a)
3 4 LOAD_NAME 0 (a)
6 STORE_NAME 1 (b)LOAD_CONST表示加载一个常量1,STORE_NAME表示使用a这个变量存储起来,放到命名空间中;LOAD_NAME表示从命名空间中加载一个变量,相当于拿到变量对应的值,然后再STORE_NAME用变量b存储起来。所以我们看到LOAD_CONST表示加载常量,LOAD_NAME则表示加载变量对应的值,因此两者本质是类似的,最终都表示找1这个PyLongObject。那么函数呢?我们说函数的传递和变量的赋值本质是一样的:
def foo(a1):
print(a1)
a2 = 1
foo(a2)
"""
1 0 LOAD_CONST 0 (<code object foo at 0x0000017DF7DE8870...>)
2 LOAD_CONST 1 ('foo')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (foo)
5 8 LOAD_CONST 2 (1)
10 STORE_NAME 1 (a2)
6 12 LOAD_NAME 0 (foo)
14 LOAD_NAME 1 (a2)
16 CALL_FUNCTION 1
18 POP_TOP
20 LOAD_CONST 3 (None)
22 RETURN_VALUE
"""
# 我们看到先是LOAD_CONST将函数对应的字节码load进来,然后load一个字符串foo
# 这里我们提一句,python中的函数名和函数体是分离的,函数也可以看成是一个变量,变量名就是函数名,函数体相当于值
# 然后MAKE_FUNCTION,这里表示将字节码编译成PyFunctionObject,然后STORE_NAME将这个对象用foo存储起来
# 显然此时的命名空间里面一定存在"foo": <function foo at 0x......>
# 同理下面的LOAD_CONST则是load一个常量1,STORE_NAME则是将"a2": 1组合起来放到命名空间中
# 然后我们foo(a2)对应的是两个LOAD_NAME,表示从命名空间中将符号foo和a2对应的值load进来
# 然后CALL_FUNCTION进行调用,后面的1表示传递了一个参数。至于函数的字节码细节我们就不贴了
# 这个过程就展示了代码的整个过程,那么变量的传递呢?
# 由于a1是参数,在编译成PyFunctionObject对象的时候就确定了,就知道有这么一个符号,放在了符号表中
# 因此当我传递a2的时候,想都不用想,肯定是将通过LOAD_NAME得到的符号a2对应的值交给了a1
# 只不过却并没有将"a1": 1放到对应的local空间中,这一点我们后面还会聊
# 不过目前你可以理解为:函数的参数传递就是通过LOAD_NAME将值load进来,然后通过STORE_NAME将值和函数参数组合起来,放到了函数的local空间中
# 这样的话,查找直接去local空间查找即可正所谓bug不断,一生三、三生万物,我们的问题也是会不断地涌现。我们目前的分析看似拨开了python中变量传递的迷雾,但是如果仔细推敲的话会发现隐藏着一个致命的问题,当然这并不是我们的问题,我们当前的分析每一步都是正确的。只是说有一个点没有得到解决,那就是变量传递、函数参数传递到底传递的什么?这个问题我们之前就抛出来了,我们刚才是通过命名空间来解释的,那么就用命名空间的方式将问题再次转换一下,LOAD_NAME加载这一过程本质是什么?我们说b?= a,表示先通过LOAD_NAME将a对应的值加载进来,然后STORE_NAME交给b,那么这个load加载过程是什么样子的,难道是将值拷贝一份吗?答案确实如此。我们先来看看C和golang:
package main
import (
"fmt"
)
func main() {
var a = 1
b := a
fmt.Printf("%p %p", &a, &b) // 0xc000062080 0xc000062088
}#include <stdio.h>
int main(int argc, char const *argv[]) {
int a = 1;
int b = a;
printf("%p %p
", &a, &b); //000000000062FE4C 000000000062FE48
return 0;
}我们看到对于C和golang来说,就是将1这个值拷贝了一份,那么python呢?
a = 1
b = a
print(id(a) == id(b)) # True惊了,两者的id是一样的,因为按照我们之前的理解,知道python是引用传递,a和b指向的对象是一样的。可你不是又说python的load是把值拷贝一份吗?咋又变了?难道是因为小整数对象池,答案不是的,如果把a?= 1换成其它的大整数,得到两个id还是一样的。b?= a这个过程确确实实是把a对应的值拷贝了一份赋值给b,但为什么a和b的id一样,应该不一样啊。而且我们知道小整数是预先定义好的,只有一份,可按照当前这个逻辑,1这个小整数就应该变成两份啊。所以基于以上,我们就引出了下一个要分析的东西,也就是python中变量的本质,python中变量到底是什么?
python中变量的本质
python中变量的本质?变量不就是一个符号嘛,一个名字而已。a?= 1,那么变量a就是一个整型,a?= "xxx",那么变量a就是一个字符串,不就是这样吗?
其实上面说的不是很准确,a?= 1,我们知道底层就是一个PyLongObject,但是这个a存储的并不是这个PyLongObject本身,而是它的指针。是的,python中所有的变量对应的都不是值本身,而是这个值的指针、或者说是内存地址。a?= 1,我们知道在命名空间中会存在"a": 1这么个键值对,那么在底层符号a就应该对应一个PyLongObject,但是实际上a对应并不是PyLongObject,而是它的内存地址。无论是整型、还是字符串、元组、列表、字典等,只要变量 = 值这种形式,那么这个变量本身存储的并不是值本身,而是这个值的内存地址。
在python中传递就是传递一个指针,a?= 1;?b =?a,确实是把a的值拷贝了一份传递给了b,但是a它是一个指针啊,所以等于把指针拷贝了一份给了b,这个是b存储的也是一个地址、一个指向存储的值为1这块的内存的地址。然后在python中,如果操作一个变量,那么会自动操作这个变量存储的地址所指向的值。
因此id(a)表示获取a的内存地址,更准确的说是获取a指向的内存的内存地址。因为a本身就是一个地址,所以我们发现id(a)获取的就是a本身,只不过虽然变量a在底层存储的是一个地址,在python的层面上它代表的就是这个地址所指向的值。a既然存储了一个地址,但是a本身是不是也有一个地址,对的这在C中就是二级指针,只不过我们在python中看不到,最多只能看到一级指针。所以a在底层是一个指针变量,存储了一个地址,如果a?= "xxx"的话,那么a存储的指针就指向了一个内部的值为"xxx"的PyUnicodeObject,要是再来b =?a的话,那么把a的值拷贝一份(没错是把a的值拷贝一份,不是a的地址,因为a本身就是个地址,或者说把a指向的值的地址拷贝一份也可以,当然此时就是a本身),赋值给b,此时b也存储的地址也是指向了"xxx"这个PyUnicodeObject结构体。所以id(a)和id(b)是一样的,因为a和b存储的地址是一样的,不过虽然存储的地址一样、但是这两个变量本身的地址肯定是不一样的,因为是两个不同的变量,只是存储的地址一样罢了,所以在python中我们说a和b两者本身也是没有关系的,只是它们指向了同一个值。所以还是那句话,在python中一切变量都是指针,只是在操作指针的时候会自动操作指针所指向的内存。
所以我们说python中变量的传递是引用传递,但是又说b?= a会把a的值拷贝一份给b,而这两者又是不矛盾的。就是因为a存储的值并不是对象本身,而是对象的内存地址。传递的时候会拷贝指针,但是在操作这个变量的时候会自动操作指针指向的内存。因此我们知道了python中的变量在C的层面实际上就是一个指针,只是在python的层面上我们理解为值,因为操作会自动操作指向的内存。
所以我们说id(a)是获取a的内存地址这句话真要从底层抠起来,实际上不准确的,因为在底层a本身就是个地址,id(a)获取的是a本身才对。只不过在python中,操作a实际上操作的是a指向的内存,那么id(a)获取的是a指向的内存的地址,在结果上这不就是a本身吗?当然虽然底层是这样,但是在python的层面上,变量就代表值,尽管底层它存储的是指针。因此我们可以得出以下三点结论:
python中的变量存储的不是值本身, 值存储在堆区,变量存储实际是值的地址。每当有一个变量指向它,这个值内部的ob_refcnt就会自增1,当变量被销毁、或者指向了其它对象,那么ob_refcnt自减1,当ob_refcnt为0,这个值就会被销毁。python中的变量在传递的时候等价于把变量对应的值(指针)拷贝一份,赋值给另一个变量。但是在python的层面变量就代表值,那么我们说把变量对应的值拷贝一份容易产生误解,尽管它存储的是指针、并且从底层分析我们知道这是正确的,但是为了避免歧义,我们也可以说成把变量指向的值的地址拷贝一份,这样说也是可以的。python中的变量虽然存储的是地址,传递的时候也是拷贝地址,但是在操作该变量的时候、则是操作其指向的内存。
像我们在命名空间看到{"a": 1, "b": 1},实际底层存储也不是1这个PyLongObject,而是PyLongObject的指针,但是正如我们说的,虽然存储的是指针,但是在操作的时候操作的是指向的内存,所以空间里面显示的是1这个PyLongObject。
我们看一下源码吧,比如两个整型a和b,我们知道这是两个PyLongObject对象,a + b会调用long_add方法。
static PyObject *
long_add(PyLongObject *a, PyLongObject *b)
{
PyLongObject *z;
...
return (PyObject *)z;
}
//我们这里不看python中两个整数相加的具体实现,而是希望你观察一下函数接收的参数类型和返回值类型
//我们看到接收的是什么参数啊?是不是两个PyLongObject *啊
//说明这个函数接收的是指针,而a和b我们说它们就是指针,而且是一个PyLongObject类型的指针
//指向了PyLongObject,所以再一次证明了python中的变量都是对应值的指针
//底层函数接收的也是指针,但是在操作的时候会操作指针所指向的了内存
//而我们加完了要使用变量接收
//所以我们看到z也是一个PyLongObject *,它指向了*a和*b相加之和的结果
//而且不光如此,其它类型所具有的操作接收和返回的都是指针,只是操作的是指针指向的内存,因为操作指针本身没有太大意义
//至于指针指向的是什么类型,则根据我们创建的值来决定
//但是不管怎样,总之传递和返回的都是指针,因为python中的变量本质上就是一个指针函数的local空间
我们说对于global空间,python底层是通过字典来存储和查找的。但是对于函数,我们说python是通过先在local空间中查找,再去global空间查找,然而事实上python并没有创建local空间。
因为函数的局部变量在编译的时候就已经确定了,所以会事先通过静态的方式进行存储,而不会临时构建一个字典、然后动态添加。因为函数的参数也可以看成是一个局部变量,那么在编译的时候就已经连同内部的局部变量一起放到了字节码对象的符号表co_varnames中,并且这些是有顺序的。至于局部变量的值则都放在字节码对象的co_const这个域里面,两者是对应的。但是参数此时还是没有值的、那么就是NULL,即便有默认值我们也可以进行替换。当我们调用一个函数,传递的参数的值就会按照传参的规则和相应的符号一一对应。所以如果最后发现符号表还有符号对应的值为NULL,那就证明参数少传递了,当然python如何传递参数、参数怎么匹配、以及扩展位置参数、扩展关键字参数怎么处理,就又是一个新的问题了,这里我们暂时不讨论这些。
只是想告诉大家,python中的函数在编译成PyFunctionObject对象的时候,那个local空间是为NULL的,因为函数的参数在编译的时候就可以确定,是通过静态方式事先就已经定好了的,并不会在执行期间才临时构建这个local空间。而我们通过locals()函数确实可以获取局部变量的,而且它也是一个字典,这是怎么回事,其实你可以把local空间看成是根据前面静态存储的变量临时构建的字典,这个字典可以看成是前面空间的一个拷贝,由于变量和值都是一样的,所以我们也说函数查找变量会先从local空间里面查找,举个例子:
def foo():
a = 2
locals()["a"] = 1
print(locals())
foo() # {'a': 2}所以我们看到并没有受到影响,因为函数的变量在编译时候已经确定,local空间不过是一个拷贝。即便修改了,那么当我再次获取的时候依旧原来的变量和值。这里涉及的深入一些,如果不理解的话可以跳过。python在执行函数的时候会为其创建一个栈帧(PyFrameObject对象),这个栈帧里面有一个f_localsplus,函数的局部变量就存在这个f_localsplus里面。
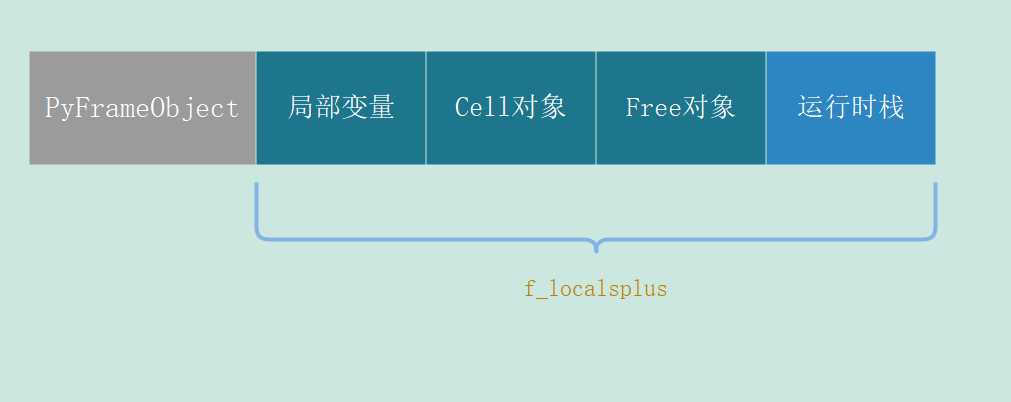
我们看到f_localsplus这块内存是给4个老铁使用的,当函数在执行的时候会把变量压入到运行时栈,而这个运行时栈也是位于f_localsplus里面的。这几个老铁虽然内存上是连续的,但是却又老死不相往来。这一部分如果不是很理解的话,可以百度一下,或者跳过也行。总之只需要记住:函数的参数在编译时就已经确定,通过静态的方式存储;local空间实际上就是对存储局部变量的那段空间的一个拷贝,修改local空间不会影响到局部变量。
为什么列表查找的时间复杂度为O(1)
估计这个问题已经不需要我来介绍了,list1 = [1, "xxx", (1, 2, 3), {"a": 1}],存储的真的是这些值吗?显然不是,存储的是这些值对应的指针,指针的大小是固定的,所以通过索引能够瞬间定位到对应的指针,然后操作的时候操作指针指向的内存,再比如:
a = "a" * 1000
b = 1 << 1000
c = "c" * 2000
list1 = [a, b, c]
# 至于list对象的大小是怎么计算的,我们看PyListObject的时候再说
print(list1 .__sizeof__()) # 64
print(list1[0].__sizeof__()) # 1049我们看到列表里面的第一个元素占了1049个字节,但是这个列表本身居然只占了64个字节。就是因为a、b、c本身是一个指针,不管你指向的内存有多大,但是指针的大小是固定的,在64位机器上固定是8字节。所以尽管a、b、c三个元素都指向了一个比较大的内存,而这些内存和该列表没有关系,尽管列表存储了a、b、c,但本质上是存储了3个指向内存的指针。我们说list1[0], list1[1]这些也可以看成是一个变量,那么就等于把a、b、c指向的内存的地址拷贝了一份放到列表里面,所以列表计算大小的时候计算的是指针的大小,至于list1,它在底层当然也是一个地址。那么list1.__sizeof__(),等价于获取list1指向的内存(PyListObject)的大小,list1[0].__sizeof__()则是等价于获取该PyListObject的第一个元素(一个指针)所指向的内存的大小。
a = 1
b = "xx"
list1 = [[a, b]]
print(list1.__sizeof__()) # 48
print(list1[0].__sizeof__()) # 56
# 虽然现在我们不知道一个列表到底怎么计算大小
# 但是可以肯定list1[0]的大小肯定比list1多8,原因很简单
# list1[0]和list1都是列表,而list1[0]里面存了两个指针,而list只存了一个指针
# 所以list1[0]会比list1多出一个指针的大小,而一个指针8字节,所以list1[0]大小会多8
# 我们再来看一下地址
print(hex(id(list1[0]))) # 0x2cd886e28c0
print(hex(id(a))) # 0x7fffbb02c6a0
print(hex(id(b))) # 0x2cd886455f0我们画一下图,图形是个好东西。
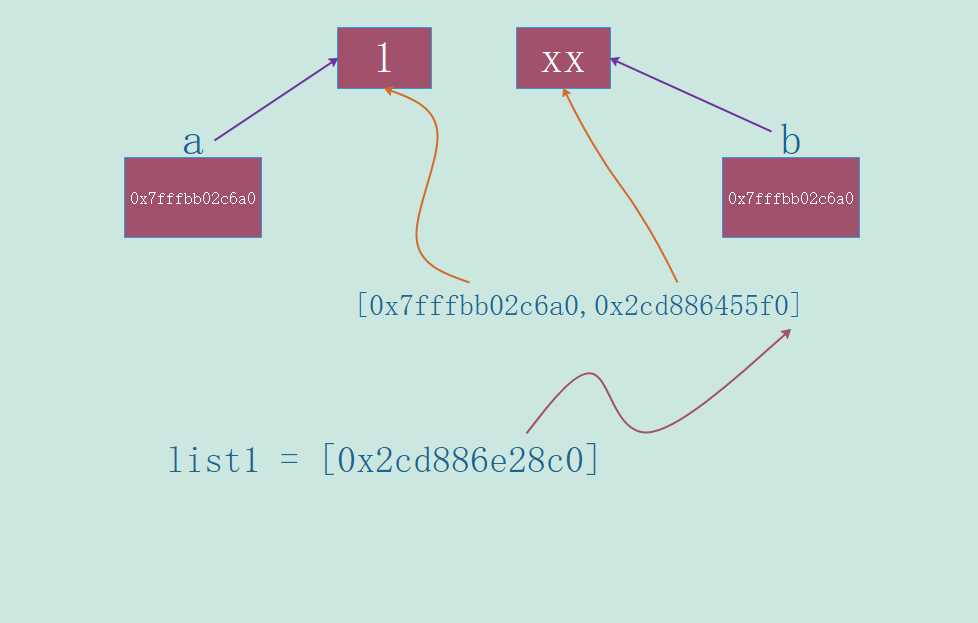
我们此时可以自信的说,我们已经明白了列表明明可以存储不同类型的值(其实存储的是同一类型,都是指针,只不过指向的值的类型不同),但是时间复杂度却是O(1)。所以我们前面要花费那么长的时间介绍变量的本质、以及传递方面的知识,因为只有明白了这些知识,我们再理解列表的时间复杂度的时候才会水到渠成。当然不光是时间复杂度,还有列表本身的数据结构,这些前置知识,都可以加速我们的理解。
底层存储
oh,shit!终于到了列表的结构了,老规矩,看看list对象底层对应的结构体PyListObject长什么样子吧。
typedef struct {
//变长对象的公共部分,一个ob_refcnt,一个ob_type,一个ob_size(这里维护的显然是列表元素个数)
PyObject_VAR_HEAD
//ob_item是一个二级指针,指向了一个数组,或者说数组首个元素的地址
//显然这个数组是我们真正用来存储值的,而根据我们之前的分析,这个数组存储的一定是指针
//我们看到这个数组的类型也正是PyObject *,一个PyObject指针
//并且我们说,无论是PyLongObject *、PyUnicodeObject *、PyListObject *,还是其他的什么*
//它们都是PyObject *,所以存储的是各种对象的指针,也再次证明了我们之前的分析
PyObject **ob_item;
//表示当前对象的容量,我们知道列表是可以动态扩容的,扩容就要申请内存
//如果每次扩容都要申请内存会肯定麻烦,所以会事先申请的多一些
//至于怎么扩容我们后面会说
Py_ssize_t allocated;
} PyListObject;我们还是来分析一下,一个list对象所占的字节数。首先PyObject_Var_HEAD还记的是什么吗?对了,是一个宏,PyVarObject ob_base,它占24个字节,一个ob_item二级指针,8个字节,然后allocated,也是8字节。所以一个列表至少要占5 *?8 = 40个字节。至于具体占多少就看里面的元素个数了,如果存储了n个元素,那么大小就是 40 + 8?*?n,我们来测试一下。
l1 = [] # 40
l2 = [1] # 40 + 1 * 8
l3 = ["xx" * 1000, 222] # 40 + 2 * 8
l4 = [[]] * 1000 # 40 + 1000 * 8
print(l1.__sizeof__()) # 40
print(l2.__sizeof__()) # 48
print(l3.__sizeof__()) # 56
print(l4.__sizeof__()) # 8040列表的扩容
下面我们来看看列表是如何扩容的,扩容调用的函数是list_resize,我们看到接收的是指针PyListObject?*,另外这个参数名叫做self,所以我们定义类的时候,方法的第一个参数也叫self
static int
list_resize(PyListObject *self, Py_ssize_t newsize)
{
//参数self就是PyListObject *对象本身
//参数newsize就是当前的ob_size
PyObject **items;
//既然resize,所以new_allocated就是新的最大容量
size_t new_allocated, num_allocated_bytes;
//这里的获取当前PyListObject的allocated
Py_ssize_t allocated = self->allocated;
//如果当前的容量大于newsize(ob_size),并且newsize >= 容量除以2
//基本上啥也没干直接返回,这一步不需要关心。
//因为执行这一步表示内存不需要重新分配
if (allocated >= newsize && newsize >= (allocated >> 1)) {
assert(self->ob_item != NULL || newsize == 0);
Py_SIZE(self) = newsize;
return 0;
}
/*
计算重新分配的内存的大小
这一步很重要,新分配的容量就等于newsize + newsize >> 3 + 3 if newsize < 9 else 6
*/
new_allocated = (size_t)newsize + (newsize >> 3) + (newsize < 9 ? 3 : 6);
if (new_allocated > (size_t)PY_SSIZE_T_MAX / sizeof(PyObject *)) {
PyErr_NoMemory();
return -1;
}
//如果新的ob_size是0,那么新分配的容量也是0
if (newsize == 0)
new_allocated = 0;
//所占的字节,就是new_allocated * sizeof(PyObject *)
//申请空间,大小为容量乘上一个指针的大小,因为存储的就是指针
num_allocated_bytes = new_allocated * sizeof(PyObject *);
//为ob_item申请内存
items = (PyObject **)PyMem_Realloc(self->ob_item, num_allocated_bytes);
if (items == NULL) {
PyErr_NoMemory();
return -1;
}
//指向新的内存块,扩展列表。
self->ob_item = items;
//将ob_size变为newsize
Py_SIZE(self) = newsize;
//将allocated变为新的new_allocated
self->allocated = new_allocated;
return 0;
}我们看到了python的扩容方式,当append或者extend的时候如果元素的个数超过了容量allocated,那么会进行扩容。至于扩容的规则,我们看到是按照new_allocated = (size_t)newsize + (newsize >> 3) + (newsize < 9 ? 3 : 6)来的,我们来测试一下。
# 初始的空列表,容量和size都是0
allocated = 0
print(allocated, end=" ")
for size in range(100):
# size主键增大,如果allocated小于size,那么就扩容了
if allocated < size:
allocated = size + (size >> 3) + (3 if size < 9 else 6)
print(allocated, end=" ") # 0 4 8 16 25 35 46 58 72 88 106l = []
# 初始的空列表,容量和size都是0
allocated = 0
print(allocated, end=" ")
for _ in range(100):
# 添加元素,size在增大
l.append(_)
# 如果size超过了allocated,那么扩容
if len(l) > allocated:
# 用l的大小减去空列表的大小,再除以指针就是容量
# 注意是容量,即便没有使用,但是容量已经申请了,所以就要耗费内存。
# 就好比房子,你一旦租了,就算你人不住,房租该给还是要给的
allocated = (l.__sizeof__() - [].__sizeof__()) // 8
print(allocated, end=" ") # 0 4 8 16 25 35 46 58 72 88 106我们看到计算的结果是一样的,说明python底层就是按照这种方式来扩容的。python底层是使用C语言的数组存储的,当扩容的时候,实际上是会创建新的数组,并把原来数组存储的指针依次拷贝过去,并让ob_item指向这个新的数组。因此即便扩容了,PyListObject对象的地址是不会变的,变的是ob_item。但我们在python中通过id查看的是PyListObject的地址,所以即便列表扩容,id函数的返回结果也是不变的。
另外我们说,解释器是在往列表中添加元素发现容量不够、塞不进去的时候才会扩容,至于我们创建列表的时候,指定了多少元素、容量就是多少。
创建PyListObject
我们知道对于PyLongObject和PyUnicodeObject来说,更常用的方法是PyLong_FromXXX和PyUnicode_FromXXX,但是对于PyListObject来说,官方只提供了一种方式:PyList_New,这个函数接收一个size参数,表示申请多大空间的PyListObject。我们在python中创建列表的时候,可以将str、tuple、dict对象转成list对象啊,其实那是事先计算元素的个数,然后调用PyList_New申请对应的空间,再把元素依次拷过去。
PyObject *
PyList_New(Py_ssize_t size)
{
//声明一个PyListObject *对象
PyListObject *op;
#ifdef SHOW_ALLOC_COUNT
static int initialized = 0;
if (!initialized) {
Py_AtExit(show_alloc);
initialized = 1;
}
#endif
//如果size小于0,直接抛异常
if (size < 0) {
PyErr_BadInternalCall();
return NULL;
}
//缓冲池是否可用,如果可用
if (numfree) {
//直接使用缓冲池的空间
numfree--;
op = free_list[numfree];
_Py_NewReference((PyObject *)op);
#ifdef SHOW_ALLOC_COUNT
count_reuse++;
#endif
} else {
//不可用的时候,申请内存
op = PyObject_GC_New(PyListObject, &PyList_Type);
if (op == NULL)
return NULL;
#ifdef SHOW_ALLOC_COUNT
count_alloc++;
#endif
}
//如果size小于0,ob_item设置为NULL
if (size <= 0)
op->ob_item = NULL;
else {
//否则的话,为维护的列表申请空间
op->ob_item = (PyObject **) PyMem_Calloc(size, sizeof(PyObject *));
if (op->ob_item == NULL) {
Py_DECREF(op);
return PyErr_NoMemory();
}
}
//设置ob_size和allocated,然后返回op
Py_SIZE(op) = size;
op->allocated = size;
_PyObject_GC_TRACK(op);
return (PyObject *) op;
}我们看到python在创建PyListObject对象的时候,分了两部分。我们知道python中所有对象底层对应的结构体里面字段都可以分为两部分,一部分是结构体的额外信息,另一部分就是真正用来存储值的。对于PyLongObject来说,它的"另一部分"就是ob_digit,对于这里的PyListObject,它的"另一部分"就是这里的ob_item指向的数组。而对于PyListObject来说,它的这两部分是分开创建的。
内存布局
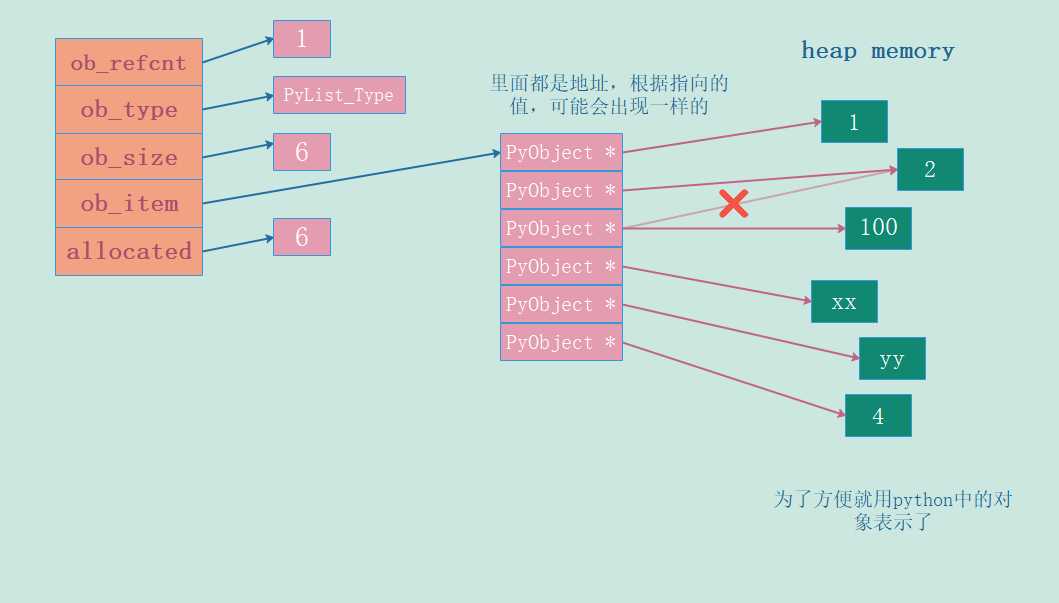
假设我们创建一个列表l = [1, 2, 2, "xx", "yy", 4],那么它的内存布局就是这样。
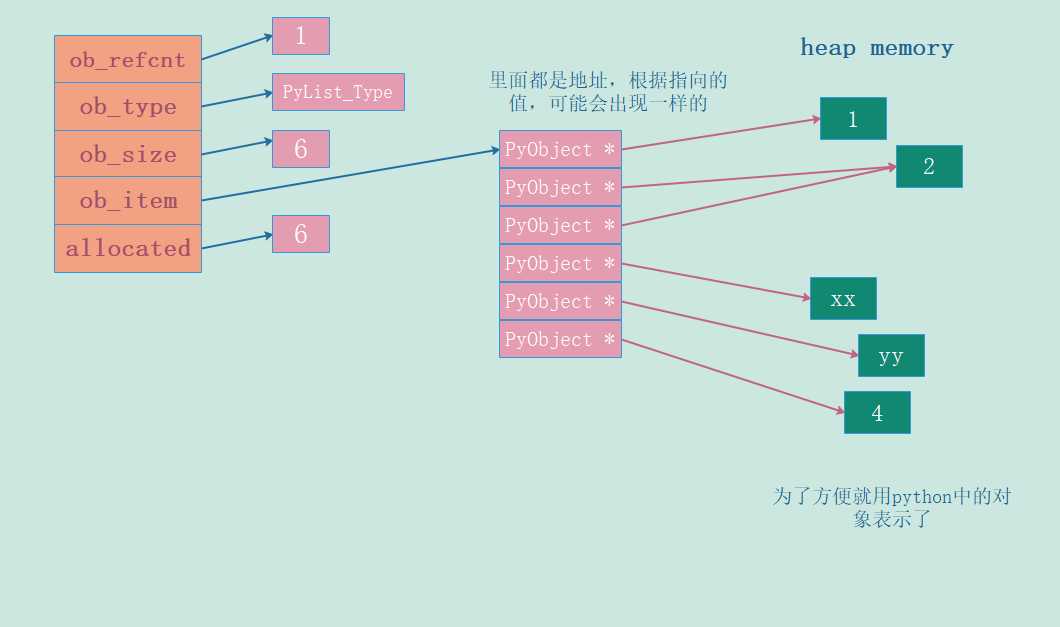
设置元素
我们知道python给对象对应的操作都设置了一个魔法方法,比如列表设置值操作对应__setitem__,那么在底层就对应PyList_SetItem,获取值__getitem__对应PyList_GetItem。有兴趣的话可以看一下底层的api,比较固定。比如我们后面使用C为python编写扩展模块的时候,经常会把python中的对象和C中对象互相转换,如果是C中的对象转换成python中的对象的话就是PyXxx_FromXxx,python中的对象转换成C中的对象就是PyXxx_AsXxx。前面的是python的结构体类型,后面的是C语言类型。
比如python中的int转成C中的double,python中的int底层是PyLongObject,转成double就是PyLong_AsDouble,如果是C中的double转成python中的int,那么就是PyLong_FromDouble。再比如python中的float,float在底层是一个PyFloatObject,那么python中的float转成C中的double就是PyFloat_AsDouble,同理反过来就是PyFloat_FromDouble。再比如python中的str转成C中的宽字符:PyUnicode_AsWideChar,C中的字符串转成python的str:PyUnicode_FromString。可以看到这些api都比较固定,所以不光python的api比较优美,底层的api也是如此。
int
PyList_SetItem(PyObject *op, Py_ssize_t i,
PyObject *newitem)
{ //参数为:PyObject *、索引、PyObject *
//我们看到l[0] = "xx"这种形式,那么l就是这里的PyObject *,0就是这里i
//而且我们还看到newitem也是个指针,没什么好奇怪的,都说了python中的变量都是指针
//尽管这里是一个常量,还是可以看做是拿到这个常量的地址
//一个二级指针
PyObject **p;
//类型检查
if (!PyList_Check(op)) {
Py_XDECREF(newitem);
PyErr_BadInternalCall();
return -1;
}
//索引检查,必须小于元素的个数,元素有n个,那么最大索引为n-1
//但是我们发现小于0也报错,其实在python中小于0是不报错的,因为可以从后往前
//其实实际上会先将i进行一个转化
if (i < 0 || i >= Py_SIZE(op)) {
Py_XDECREF(newitem);
PyErr_SetString(PyExc_IndexError,
"list assignment index out of range");
return -1;
}
//ob_item表示数组的首地址
//ob_item + i直接获取数组中索引为i的元素的指针
//当然数组里面存储的本身也是一个指针,所以这里的p是一个二级指针
p = ((PyListObject *)op) -> ob_item + i;
//直接将*p,也就是数组中索引为i的元素(一级指针)设置为newitem(一级指针)
//这样该元素也会指向newitem所指向的内存
Py_XSETREF(*p, newitem);
return 0;
}如果我们对之前的列表执行l[2]?= 100这个操作的话,那么内存布局就会如下
插入元素
插入元素的效率是比较低的,因为当前列表是一段连续的存储空间,在索引为i的地方插入一个元素,就意味着索引为i-1后面的所有元素都要依次向后移动一个位置。
int
PyList_Insert(PyObject *op, Py_ssize_t where, PyObject *newitem)
{
//类型检查
if (!PyList_Check(op)) {
PyErr_BadInternalCall();
return -1;
}
//底层又调用ins1
return ins1((PyListObject *)op, where, newitem);
}
static int
ins1(PyListObject *self, Py_ssize_t where, PyObject *v)
{
/*参数self:PyListObject *
参数where:索引
参数v:插入的值,这是一个PyObject *指针,因为list里面存的都是指针
*/
//i:后面for循环遍历用的,n则是当前列表的元素个数
Py_ssize_t i, n = Py_SIZE(self);
//指向指针数组的二级指针
PyObject **items;
//如果v是NULL,错误的内部调用
if (v == NULL) {
PyErr_BadInternalCall();
return -1;
}
//列表的元素个数不可能无限增大,最大个数为PY_SSIZE_T_MAX,当达到这个PY_SSIZE_T_MAX时,会报出内存溢出错误
//但是一般当你还没创建到PY_SSIZE_T_MAX个对象时,你内存就已经玩完了
if (n == PY_SSIZE_T_MAX) {
PyErr_SetString(PyExc_OverflowError,
"cannot add more objects to list");
return -1;
}
//调用list_resize,判断是否调整列表容量
//当然如果容量够的话,是不会扩容的,只有当容量不够的时候才会扩容
if (list_resize(self, n+1) < 0)
return -1;
//确定插入点
//这里可以看到如果where小于0,那么我们就加上n,也就是当前列表的元素个数
//比如有6个元素,那么我们where=-1,加上6,就是5,显然就是insert在最后一个索引的位置上
if (where < 0) {
where += n;
//如果吃撑了,写个-100,加上元素的个数还是小于0
if (where < 0)
//那么where=0,就在开头插入
where = 0;
}
//如果where > n,那么就索引为n的位置插入,
//可元素个数为n,最大索引是n-1啊,对,所以此时就相当于append
if (where > n)
where = n;
//拿到原来的二级指针,指向一个指针数组
items = self->ob_item;
//然后让不断遍历,把索引为i的值赋值给索引为i+1,既然是在where处插入
//那么where之前的就不需要动了,到where处就停止了
for (i = n; --i >= where; )
items[i+1] = items[i];
//增加v指向对象的引用计数,因为它作为列表的一个元素了
Py_INCREF(v);
//将where处的值设置成v,一个PyObject *指针,就是我们设置的值的指针
items[where] = v;
return 0;
}我们看到python中list对象的insert做的事情还是比较多的,尤其是索引方面,真的做了好多处理,生怕你出错,底层帮你做了很多的事情,无论指定的位置是哪里,有没有越界都不会报错。事实上python中的很多地方都做了这样的处理,比如:一个对象要想转为整型,内部必须实现__int__方法,如果没有那么会去寻找__index__方法。再比如转化为bool类型,会去寻找内部的__bool__方法,没有的话会去找__len__方法。再比如一个对象要想被for循环,那么首先会去寻找__iter__方法,如果没有那么会退而求其次去寻找__getitem__。所以python就像一个老母亲一样,生怕你有任何闪失(报错),背后不停地做工作为你保驾护航。而C则是完全相信你,你想做什么都可以我不管,但是自由的同时也要承担所有责任。
删除元素
删除元素,我们可以通过remove,那么底层是如何实现的呢?
static PyObject *
list_remove(PyListObject *self, PyObject *value)
{
//删除值,对于底层来说,就是删除数组中值对应的指针。
//所以value仍然是PyObject *类型
//i,for循环遍历用的
Py_ssize_t i;
//从0开始,直到不小于ob_size
for (i = 0; i < Py_SIZE(self); i++) {
//将指针数组里面的每一个元素和value进行比较
int cmp = PyObject_RichCompareBool(self->ob_item[i], value, Py_EQ);
//如果cmp大于0,表示元素和value匹配
if (cmp > 0) {
//调用list_ass_slice将其删除
if (list_ass_slice(self, i, i+1,
(PyObject *)NULL) == 0)
Py_RETURN_NONE;
return NULL;
}
else if (cmp < 0)
return NULL;
}
//否则报错,x不再list中。
PyErr_SetString(PyExc_ValueError, "list.remove(x): x not in list");
return NULL;
}
//另外这个list_ass_slice其实起到的是替换的作用,只不过也可以充当删除
//从源码中可以看出把i: i+1部分的元素给删了
/*
l = [1, 2, 3, 4]
l[0: 1] = []
print(l) # [2, 3, 4]
*/既然是删除,那么和insert一样。全局都会进行移动,比如我把第一个元素删了,那么第二个元素要顶在第一个元素的位置,第n个元素要顶在第n-1个元素的位置上。
python中的其它对象
我们不可能把所有的对象都介绍完,因此下面再来挑几个看看它们的结构体定义。
PyFloatObject
typedef struct {
PyObject_HEAD
double ob_fval;
} PyFloatObject;
//我们看到python的浮点数在底层是用一个double存储的
//所以python中所有的浮点数一个都占24字节Py_False和Py_True
PyAPI_DATA(struct _longobject) _Py_FalseStruct, _Py_TrueStruct;
#define Py_False ((PyObject *) &_Py_FalseStruct)
#define Py_True ((PyObject *) &_Py_TrueStruct)
//我们知道python中False和True实际上就是一个0和1,毕竟bool继承int嘛
//在底层它们也是一个PyLongObject
//python中False占24字节,因为它是int,值为0,而且我们前面说了,如果值为0,那么digit这个数组是空的
//True的值为1,digit需要一个元素来存储,所以大小为28字节PyComplexObject
typedef struct {
double real;
double imag;
} Py_complex;
typedef struct {
PyObject_HEAD
Py_complex cval;
} PyComplexObject;
//python中的复数是使用两个double存储的
//所以python中的所有复数都占32字节PyTupleObject
typedef struct {
PyObject_VAR_HEAD
PyObject *ob_item[1];
} PyTupleObject;
//一个PyObject_VAR_HEAD,一个数组
//所以字节数为24 + 8 * 元组内元素个数PyDictObject
typedef struct _dictkeysobject PyDictKeysObject;
typedef struct {
PyObject_HEAD
//字典中的元素个数
Py_ssize_t ma_used;
//字典版本,全局唯一,字典的每一次变化都会生成一个新的版本号
uint64_t ma_version_tag;
//存储key或者value
PyDictKeysObject *ma_keys;
//存储value或者为NULL
PyObject **ma_values;
} PyDictObject;
typedef Py_ssize_t (*dict_lookup_func)
(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject **value_addr);
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
Py_ssize_t dk_size;
dict_lookup_func dk_lookup;
Py_ssize_t dk_usable;
Py_ssize_t dk_nentries;
char dk_indices[];
};
//dict的逻辑很复杂,并且python中dict是通过哈希表来实现的
//这个表分为结合表和分离表
//如果是结合表,那么ma_values为NULL,key和value对应的指针都存在ma_keys中
//如果分离表,那么key存储在ma_keys中,value存储在ma_values中
//另外我们知道python中的哈希表是通过空间换时间,所以我们无法通过元素的个数来判断一个字典占多少内存
//根据PyDictObject,我们只能得到它的额外的内存是48个字节。PySetObject
typedef struct {
PyObject *key;
Py_hash_t hash;
} setentry;
typedef struct {
PyObject_HEAD
//active态和dummy态的元素个数
Py_ssize_t fill;
//active态的元素个数
Py_ssize_t used;
//关于active态和dummy态,我们说哈希表在删除一个元素的时候,并不是直接将这个元素删除
//而是将active态的元素设置为dummy态,具体可以参考python的哈希表
//哈希表的长度:mask + 1,它是2的整数倍
Py_ssize_t mask;
//哈希表的指针,哈希表的元素叫做entry,包含一个值的指针以及一个哈希值
setentry *table;
//hash值,集合是可变的,所以这个参数只对frozenset有用
Py_hash_t hash; /* Only used by frozenset objects */
//用于pop
Py_ssize_t finger;
//设置的哈希表,初始化有8个空间。PySet_MINSIZE是一个宏,值为8
//也就是说当我们创建一个空的集合,里面实际上能容纳8个元素
setentry smalltable[PySet_MINSIZE];
//弱引用
PyObject *weakreflist; /* List of weak references */
} PySetObject;
//我们说由于哈希表里面空间是未知的,所以不好计算大小
//但是对于集合,已经告诉我们初始化会申请8个slots,那么对于一个初始化的集合我们还是可以计算出它的大小的
//我们看到除了setentry smalltable[PySet_MINSIZE];,其他的每一个成员都是8个字节,PyObject_HEAD是16字节
//所以总共是72字节,所以一个PySetObject的额外部分占72字节。而我们说setentry是一个结构体,这个结构体两个成员一个8字节,所以是16字节
//而初始化申请8个slots,所以是8 * 16 = 128个字节,那么加一起就是200字节我们在python的层面上演示一下
s = set()
print(s.__sizeof__()) # 200
s.add(1)
s.add(2)
s.add(3)
s.add(4)
print(s.__sizeof__()) # 200
s.add(5)
print(s.__sizeof__()) # 712
"""
我们看到确实是200,然后不断的add元素。
我们知道hash表会扩容的,而且为了避免哈希值冲突,当空间剩余不到三分之一的时候就会扩容
因为容量越小,冲突的可能性就越大。那么哈希搜索的时候,就会不断地发生二次探查
所以哈希表就是这种通过空间换时间的数据结构
所以我们看到开始容量为8,但是当塞到第5个元素的时候,哈希表扩容了。此时大小为712,那么代表能容纳(712 - 72) // 16 = 40个元素
"""PyGenObject
typedef struct {
PyObject_HEAD
//栈帧对象,如果这个生成器已经结束,那么gi_frame可能为NULL
struct _frame *gi_frame;
//生成器是否处于运行状态。我们知道创建一个生成器的时候,还处于未被激活的状态。
char gi_running;
//生成器的字节码
PyObject *gi_code;
//弱引用
PyObject *gi_weakreflist;
//生成器的名字
PyObject *gi_name;
//也是生成器的名字,但它是全限定名,那么它和name有什么区别呢?
/*
我们知道在python中,一个函数、类啊也有__name__和__qualname__,那么这两者的区别是什么呢
class A:
def foo(self):
pass
print(A.__name__, A.__qualname__) # A A
print(A.foo.__name__, A.foo.__qualname__) # foo A.foo
*/
PyObject *gi_qualname;
//设置异常栈状态
_PyErr_StackItem gi_exc_state;
} PyGenObject;python中还存在很多对象,比如函数:PyFunctionObject、栈帧:PyFrameObject、模块:PyModuleObject、类里面的一个方法:PyMethodObject。但是我们不可能全部看完,最后再看两个对象:PyLong_Type、PyType_Type。我们到目前为止看的都是相当于python中内建类型的实例对象,那么int、str、dict这些类本身也是一个对象啊,那么它们长什么样子呢?我们知道type创建所有类,它是要看的,至于其它的我们随便挑一个就行,都是类似的,这里选int。
//我们看到PyLong_Type已经被实例化出来了
//很好理解,因为在python中int是可以直接用的,所以当然要提前初始化好
PyTypeObject PyLong_Type = {
//这个PyVarObject_HEAD_INIT是一个带参数的宏
//从名字也能看出来这是初始化一个PyVarObject,我们看到我们传入了&PyType_Type
//所以type(int)的结果为<class 'type'>
PyVarObject_HEAD_INIT(&PyType_Type, 0)
//名字
"int", /* tp_name */
//创建该类型的实例对象时分配内存空间大小的信息
offsetof(PyLongObject, ob_digit), /* tp_basicsize */
//同上
sizeof(digit), /* tp_itemsize */
//PyLongObject对象的析构操作
long_dealloc, /* tp_dealloc */
//PyLongObject对象的打印操作
0, /* tp_print */
//PyLongObject对象的反射操作,getattr
0, /* tp_getattr */
//PyLongObject对象的反射操作,setattr
0, /* tp_setattr */
//PyLongObject对象的翻转操作
0, /* tp_reserved */
//PyLongObject对象的repr方法
long_to_decimal_string, /* tp_repr */
//关键来了,指向一个数组的指针,这个数组里面存储了大量的函数指针
//这每一个指针都指向了具体的函数,比如四则运算啊、左移、右移、取模啊
//就是整型所支持的函数
&long_as_number, /* tp_as_number */
//同样是一个指针,指向的数组里面存储了一个序列所支持的函数操作的指针,比如索引取值等等
0, /* tp_as_sequence */
//指针,指向的数组里面存储了一个映射所支持的函数操作的指针
0, /* tp_as_mapping */
//int对象的哈希值
(hashfunc)long_hash, /* tp_hash */
//call方法,int肯定是没有的,因为a = 3,不可能再通过a()的方式进行调用
//但是我们猜测type是肯定有的,因为对象加()就等于执行其类型对象的__call__方法
0, /* tp_call */
//str方法
long_to_decimal_string, /* tp_str */
//查找属性,按照实例、类的方式
PyObject_GenericGetAttr, /* tp_getattro */
//设置
0, /* tp_setattro */
//作为缓存
0, /* tp_as_buffer */
//设置类的属性
//Py_TPFLAGS_DEFAULT表示默认行为,Py_TPFLAGS_BASETYPE则是允许被继承
Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE |
Py_TPFLAGS_LONG_SUBCLASS, /* tp_flags */
//注释
long_doc, /* tp_doc */
//遍历操作
0, /* tp_traverse */
//清空操作
0, /* tp_clear */
//富比较
long_richcompare, /* tp_richcompare */
//弱引用
0, /* tp_weaklistoffset */
//iter方法
0, /* tp_iter */
//next
0, /* tp_iternext */
//成员函数
long_methods, /* tp_methods */
0, /* tp_members */
long_getset, /* tp_getset */
//继承的基类
0, /* tp_base */
//int类的属性字典
0, /* tp_dict */
//描述符
0, /* tp_descr_get */
0, /* tp_descr_set */
//创建的实例是否存在属性字典,如果tp_dictoffset为0,那么将不存在属性字典
//所以python中的整型对象是不存在属性字典的,不然内存占的太大
0, /* tp_dictoffset */
//初始化函数
0, /* tp_init */
//申请空间的函数
0, /* tp_alloc */
//new函数
long_new, /* tp_new */
//析构函数
PyObject_Del, /* tp_free */
};我们看到里面的东西还是很多的,但是很多我们不需要关注,并且我们看到了有的字段是0,这代表它不支持相应的操作,可是有些操作明明是支持的呀,所以这目前创建出来的对象还不是完整的,比如里面tp_dict,这是int的属性字典,只是目前没有,但是虚拟机在初始化的时候,会依次将int支持的操作填进tp_dict中,当然还会通过其它的操作,来使得int这个类变得完整。至于它是怎么做的,这个涉及到了虚拟机的执行流程,我们暂时不扯这么远。而且我们看到里面有一个long_as_number,我们说它指向了一个数组,我们看看这个数组存储了什么?
static PyNumberMethods long_as_number = {
(binaryfunc)long_add, /*nb_add*/
(binaryfunc)long_sub, /*nb_subtract*/
(binaryfunc)long_mul, /*nb_multiply*/
long_mod, /*nb_remainder*/
long_divmod, /*nb_divmod*/
long_pow, /*nb_power*/
(unaryfunc)long_neg, /*nb_negative*/
(unaryfunc)long_long, /*tp_positive*/
(unaryfunc)long_abs, /*tp_absolute*/
(inquiry)long_bool, /*tp_bool*/
(unaryfunc)long_invert, /*nb_invert*/
long_lshift, /*nb_lshift*/
(binaryfunc)long_rshift, /*nb_rshift*/
long_and, /*nb_and*/
long_xor, /*nb_xor*/
long_or, /*nb_or*/
long_long, /*nb_int*/
0, /*nb_reserved*/
long_float, /*nb_float*/
0, /* nb_inplace_add */
0, /* nb_inplace_subtract */
0, /* nb_inplace_multiply */
0, /* nb_inplace_remainder */
0, /* nb_inplace_power */
0, /* nb_inplace_lshift */
0, /* nb_inplace_rshift */
0, /* nb_inplace_and */
0, /* nb_inplace_xor */
0, /* nb_inplace_or */
long_div, /* nb_floor_divide */
long_true_divide, /* nb_true_divide */
0, /* nb_inplace_floor_divide */
0, /* nb_inplace_true_divide */
long_long, /* nb_index */
};我们是不是看到了熟悉的东西,这不就是python的魔法方法嘛,long_as_number里面定义了一个整型对象时所支持的操作。
我们再来看看PyType_Type
PyTypeObject PyType_Type = {
//我们看到了什么,它,它居然把PyType_Type传进去了。
//所以我们说type是所有类的元类,它连自己都没放过
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"type", /* tp_name */
sizeof(PyHeapTypeObject), /* tp_basicsize */
sizeof(PyMemberDef), /* tp_itemsize */
(destructor)type_dealloc, /* tp_dealloc */
0, /* tp_print */
0, /* tp_getattr */
0, /* tp_setattr */
0, /* tp_reserved */
(reprfunc)type_repr, /* tp_repr */
0, /* tp_as_number */
0, /* tp_as_sequence */
0, /* tp_as_mapping */
0, /* tp_hash */
//所以我们说type一定有__call__方法
(ternaryfunc)type_call, /* tp_call */
0, /* tp_str */
(getattrofunc)type_getattro, /* tp_getattro */
(setattrofunc)type_setattro, /* tp_setattro */
0, /* tp_as_buffer */
Py_TPFLAGS_DEFAULT | Py_TPFLAGS_HAVE_GC |
Py_TPFLAGS_BASETYPE | Py_TPFLAGS_TYPE_SUBCLASS, /* tp_flags */
type_doc, /* tp_doc */
(traverseproc)type_traverse, /* tp_traverse */
(inquiry)type_clear, /* tp_clear */
0, /* tp_richcompare */
offsetof(PyTypeObject, tp_weaklist), /* tp_weaklistoffset */
0, /* tp_iter */
0, /* tp_iternext */
type_methods, /* tp_methods */
type_members, /* tp_members */
type_getsets, /* tp_getset */
0, /* tp_base */
0, /* tp_dict */
0, /* tp_descr_get */
0, /* tp_descr_set */
offsetof(PyTypeObject, tp_dict), /* tp_dictoffset */
type_init, /* tp_init */
0, /* tp_alloc */
type_new, /* tp_new */
PyObject_GC_Del, /* tp_free */
(inquiry)type_is_gc, /* tp_is_gc */
};python中的对象我们就看到这里,哇,扯得真多啊。毕竟编写扩展模块,这些知识还是要有的,而且我们下面还会继续扯python源码方面的知识,毕竟使用C编写python的扩展模块,必须要有python源码方面的知识。
以上是关于使用C语言为python编写动态模块--从底层深度解析python中的对象以及变量的主要内容,如果未能解决你的问题,请参考以下文章