使用C语言为python编写动态模块--解析python中的对象如何在C语言中传递并返回
Posted traditional
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用C语言为python编写动态模块--解析python中的对象如何在C语言中传递并返回相关的知识,希望对你有一定的参考价值。
楔子
编写扩展模块,需要有python源码层面的知识,我们之前介绍了python中的对象。但是对于编写扩展模块来讲还远远不够,因为里面还需要有python中模块的知识,比如:如何创建一个模块、如何初始化python环境等等。因此我们还需要了解一些前奏的知识,如果你的python基础比较好的话,那么我相信你一定能看懂,当然我们一开始只是介绍一个大概,至于细节方面我们会在真正编写扩展模块的时候会说。
关于使用C为python编写扩展模块,我前面还有一篇博客,强烈建议先去看那篇博客,对你了解Python底层会很有帮助。因为使用C来编写python可以直接import的模块,需要严格遵守python规定的api,而这些api是和python解释器源码保持一致的,所以我们才需要大量python源码的知识。
编写扩展模块前奏曲
好啦,我们看看编写一个扩展模块需要了解哪些东西:
初始化一个模块://这个XXX非常重要,这个是你最终生成的扩展模块的名字 PyInit_XXX(void); //模块初始化入口创建一个模块PyModule_Create(PyModuleDef *); //创建模块模块信息//一个结构体,通过这个结构体就可以定义一个用于生成模块的对象,里面不同的字段存储了未来生成的模块的各种信息 PyModuleDef XXX; //模块的信息有很多,比如都会有一个公共的部分,正如所有对象都有PyObject这个结构体一样 PyModuleDef_Base m_base; //这便是一个模块的公共信息,另外python中也提供了类似PyObject_HEAD的宏 #define PyModuleDef_HEAD_INIT PyModuleDef_Base m_base;//我们可以使用PyModuleDef_HEAD_INIT来代替 //模块肯定要有名字,这个名字要和上面的PyInit_XXX中的XXX保持一致 const char *m_name; //除此之外,模块还有一个文档注释,对,就是我们看到的__doc__ const char *m_doc; //模块的独立空间,但是我们一般不会使用,所以直接设置为-1即可 Py_ssize_t m_size; // -1 //一个模块里面是不是要定义大量的函数啊,所以还有一个数组,数组存放了大量的结构体 //每一个函数都是一个PyMethodDef结构体,是的,PyMethodDef也是一个结构体 //这个结构体里面肯定要保存了函数的各种信息、比如名字、doc、以及最关键的、真正指向具体的函数的指针 //这个m_methods就是存储PyMethodDef的数组的首地址 PyMethodDef *m_methods;//一个数组的首地址 //在python中PyModuleDef 结构体后面还有四个NULL,也就说一个完整的PyModuleDef对象应该长这个样子 PyModuleDef module = { PyModuleDef_HEAD_INIT, "模块名", "注释", -1, m_methods, //一个数组的首地址 NULL, NULL, NULL, NULL }; //因此在C中定义一个PyModuleDef对象就按照上面的逻辑模块的函数信息//我们上面说了,一个模块里面会包含很多结构体,这些结构体就是python中的函数 //因为python中的函数会有很多信息,所以底层对应的是一个结构体 PyMethodDef xxx; //一个结构体类型,里面存储了函数的各种信息 //函数和模块一样也是有名字的 const char *ml_name; //当然啦,肯定还有一个指针,这个指针指向的才是真正的函数 //这些函数都是一个PyCFunction PyCFunction *ml_methd; //函数还有参数类型: //METH_VARARGS:存在*args //METH_KEYWORDS:存在**kwargs //METH_NOARGS:不接受参数 //METH_O:接收一个参数 int ml_flags; //函数注释 const char *ml_doc; //因此在底层定义一个python中的函数,那么PyMethodDef对象长这个样子 PyMethodDef f = { "函数名", (PyCFunction)func, //我们在C中定义的函数,这里会得到一个指针,我们记得转换成PyCFunction,但是不转也不会有问题,最好还是转一下 METH_O, //函数类型 "函数注释" }; //下面就是最关键的函数了,这个返回一个PyObject *,至少要接收一个PyObject * static PyObject * func1(PyObject *self, PyObject *args) { } //如果是带有默认参数的话,就是 static PyObject * func2(PyObject *self, PyObject *args, PyObject *dictionary) { }
以上是一些前奏知识,先有一个概念,细节我们会在编写代码的时候通过注释来介绍,通过编写代码很快就能明白。我们说C编写完之后,肯定要编译成python的扩展模块,那么如果编译呢?
from distutils.core import *
setup(name="egg_info中的元信息显示的模块名",
# 注意:我们在编译完之后,会有一个egg文件,里面显示了模块的元信息,这个是egg文件里面的信息
verison="1.0",
# 接收多个Extension("模块名", ["C文件"])
ext_modules=[Extension("hanser", ["C文件"])]
)假设这个文件叫做setup.py,那么打包成扩展库就可以通过python setup.py install来实现。
编写一个简单的扩展模块
下面我们来编写一个简单的扩展模块,生成的扩展模块的名字我们就叫hanser吧,也就是最终可以让python解释器通过import hanser来导入。至于我们定义的C文件叫什么名字都无所谓,我们叫做a.c吧,简单粗暴一些。
//编写python扩展模块,需要引入Python.h这个头文件
//这个头文件,在python安装目录的include目录下,编译的时候会自动寻找
#include "Python.h"
//我们先来定义几个函数,只需要知道有这么些函数就行,每一个函数都要返回一个PyObject *
//而且至少要接收一个PyObject *self,但是不好意思对于python来说这个函数是没有参数的,这个self是必须的
static PyObject *
my_func1(PyObject *self)
{
//函数返回一个PyObject *,我们说python中所有对象在底层对应的结构体都包含了PyObject,所以我们返回一个整型、字符串都是可以的
//这里返回一个整型,比较简单。但是直接return 100;可以吗?我们说100是C中的整型,但不是python中的整型
//所以我们需要转一下,我们在上一篇博客中介绍了python中的对象和C中的对象是如何进行转化的,如果不知道规则可以去看一下
return PyLong_FromLong(100);
//返回python中int,此时对象的内存由python管理,此时就跟在python中创建一个整型是类似的
}
static PyObject *
my_func2(PyObject *self, PyObject *a)
{
//加上100
long _a = PyLong_AsLong(a);
a = PyLong_FromLong(_a + 100);
return a;
}
//4.第四个步骤(1和2和3在下面)
/*
定义一个结构体数组,类型为PyMethodDef,里面存储了结构体,这个结构体里面存放了函数的名字、注释、指向了函数的指针
数组名字叫什么无所谓
*/
static PyMethodDef module_functions[] = {
//这个里面就可以创建了
{
"my_func1", //函数名称
(PyCFunction)my_func1, //函数指针,所以我们需要定义一些函数
METH_NOARGS, //函数参数标识,这里没有参数
"this is a function named my_func1", //函数文档注释
},
//一个模块可以有很多函数
{
"my_func2",
(PyCFunction)my_func2,
METH_O,
"this is a function named my_func2",
},
//当函数(结构体)定义完了,最后要有{NULL, NULL}
{NULL, NULL}
};
//3.第三个步骤
/*
定义一个生成模块的对象吧,还记得在C中怎么定义吗?对的,通过PyModuleDef
我们定义的变量叫什么无所谓,但是一般都保持一致,所以这里我们也叫hanser
但是不叫hanser也无所谓,为了区分演示,我们这里就叫别的名字,就叫HANSER吧,改成大写
*/
static PyModuleDef HANSER = {
//记得,要有一个头部
PyModuleDef_HEAD_INIT,
//然后是模块名
"hanser",
//模块的注释,或者说是文档说明,如果不需要的话,写成NULL
"this is a module named hanser",
//然后是模块的空间,即使那个m_size,我们说这个不需要关心,直接写成-1即可
-1,
//然后是函数、准确的说应该是结构体,数组的地址了
module_functions,
//别忘了下面的四个NULL
NULL,
NULL,
NULL,
NULL
};
//1.第一个步骤:
/*
扩展库入口函数
这是一个宏,python的源代码我们知道是使用C来编写的
但是编译的时候为了支持C++的编译器也能编译,于是需要通过extern "C"定义函数
然后这样C++编译器在编译的的时候就会按照C的标准来编译函数
这个宏就是干这件事情的,主要和python中的函数保持一致
没必要太深究,写上就行
*/
PyMODINIT_FUNC
//2.第二个步骤
/*
模块初始化入口,PyInit_XXX(void),XXX是我们定义的模块名,这里叫hanser
*/
PyInit_hanser(void)
{
//打印一句话吧,我们的Python.h中已经引入了stdio.h这个头文件了,所以可以直接打印
printf("%s
", "PyInit_hanser");
//创建python中的模块,将使用PyModuleDef定义的模块对象的指针传递进去,然后返回得到python中的模块
return PyModule_Create(&HANSER);
}from distutils.core import *
setup(
# 打包之后会有一个egg_info,表示该模块的元信息信息,name就表示打包之后的egg文件名
# 但它并不是我们的模块名,这两个名字不一样也可以,但是我们一般都会写一样的,这样才知道你是哪个模块的
# 不信我们改一下,改成hanser1
name="hanser1",
version="10.22", # 版本号
author="古明地觉", # 作者
author_email="东方地灵殿", # 作者邮箱
# 关键来了,这里面接收一个类Extension,类里面传入两个参数,第一个参数还是我们的模块名,必须和PyInit_XXX中的XXX保持一致,否则报错
# 我们发现貌似好像指定了好多的名字,总之一句话:PyInit_XXX中的XXX、我们定义PyModuleDef对象中的m_name、以及这里的Extension里面的第一个参数要保持一致
# 它们就是模块名
# 第二个参数还是一个列表,表示用到了哪些C文件,因为扩展模块对应的C文件不一定只有一个
ext_modules=[Extension("hanser", ["a.c"])]
)我们的py文件名就叫做1.py,然后我们在控制台输入python 1.py?install。
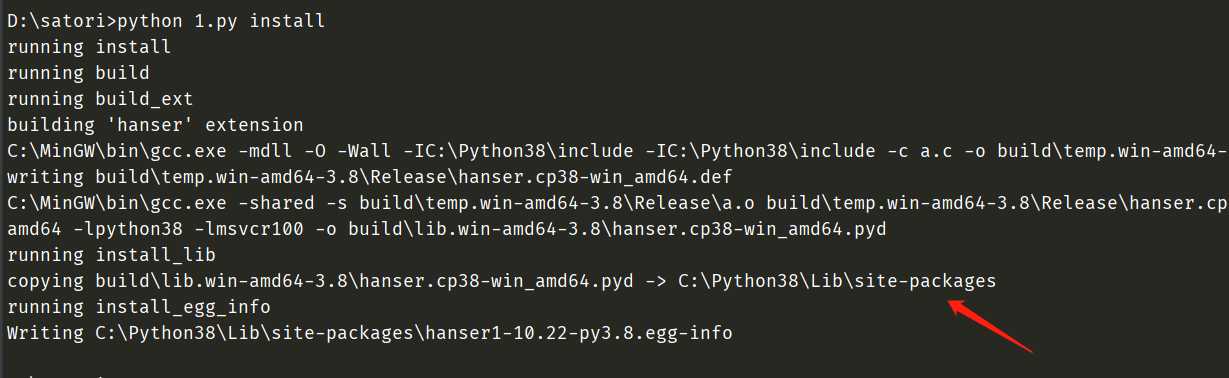
我们看到打包成功,并且它还自动的帮我们移到了site-packages里面,我们来看看。
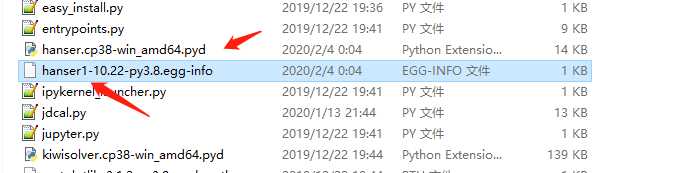
我们看到了一个hanser.pyd文件,至于中间的部分就是解释器版本,然后我们下面的egg-info,我们注意到这是hanser1,我们再打开看看。
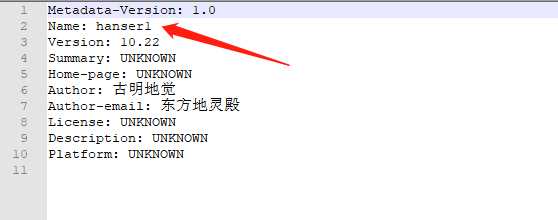
我们看到里面的Name就是我们在setup函数中指定的name,我们起名为hanser1,我们说那个name是生成的egg-info的名字、或者说里面存储的元信息显示的名字,但它不是模块名。但即便如此,也不要改成其他的名字,因为egg-info就是描述模块的元信息的,然后你egg-info的名字不就代表了你要描述哪个模块的元信息吗?要是把名字改成其他的,容易造成困惑。
所以我们看到就比较讨厌,里面需要指定的名字太多了。但是虽然多,我们还是那句话记住一点:PyInit_XXX的XXX、PyModuleDef定义的模块中的m_name、Extension中的第一个参数、还有setup中name参数都保持一致即可、至于名字是什么,你要生成的扩展模块叫什么、它们就叫什么。至于其它的变量名就没有要求了,假设我们要生成的模块名叫yousa。那么:
PyInit_yousam_name:yousaPyMethodDef xx = { ..., "yousa", ... }setup(name="yousa", ext_modules=[extension("yousa", ["xx.c"])])
我们说,编译好的扩展模块直接自动拷贝到site-packages中了,那么我们是可以直接import的。除此之外,还在当前目录中生成了build目录,我们看到了hanser.pyd,那个也是可以直接导入的。
import hanser
print(hanser.my_func1())
print(hanser.my_func2(20))
"""
100
120
PyInit_hanser
"""
# 我们在PyInit_hanser中打印了一句话,在导入模块的时候也打印了出来
# 别看它是最后打印的,其实在我import hanser的时候就会打印
# 只不过因为缓冲区的原因,它最后输出的最后再看一个神奇的东西,我们知道在pycharm这样的智能编辑器中,通过Ctrl加左键可以调到指定模块的指定位置。
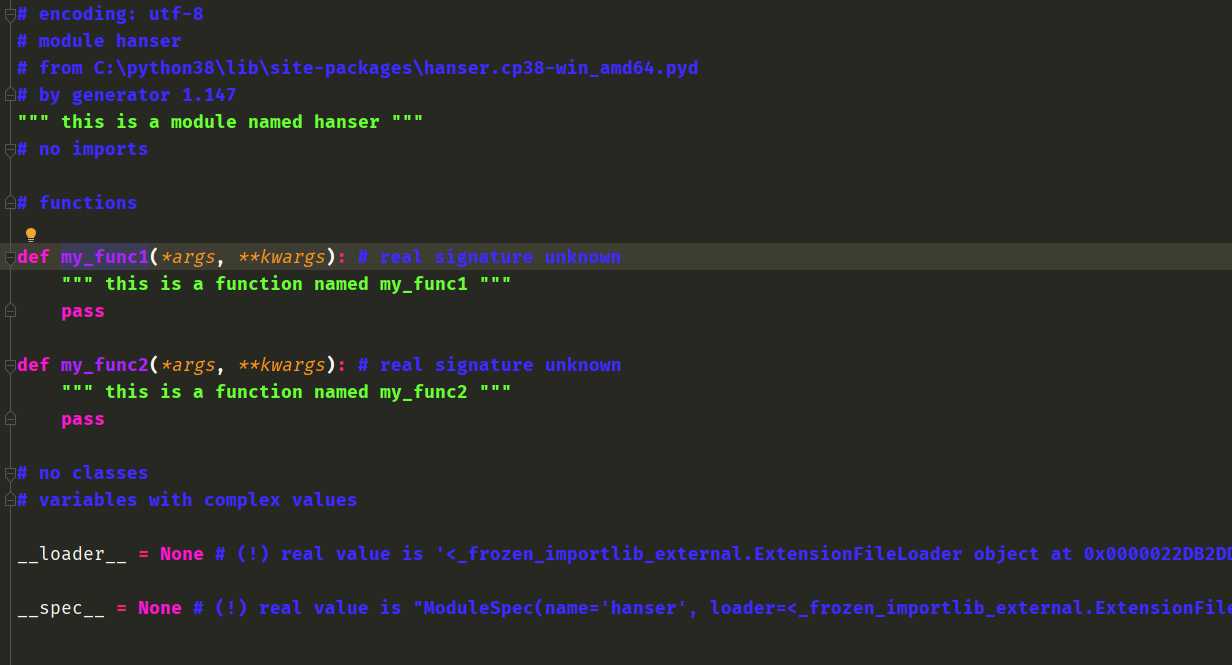
神奇的一幕出现了,我们点击进去居然还能跳转,其实我们在编译成扩展模块移动到site-packages中,pycharm就自动生成了。我们看到模块注释、函数的注释跟我们在C文件中指定的一样。
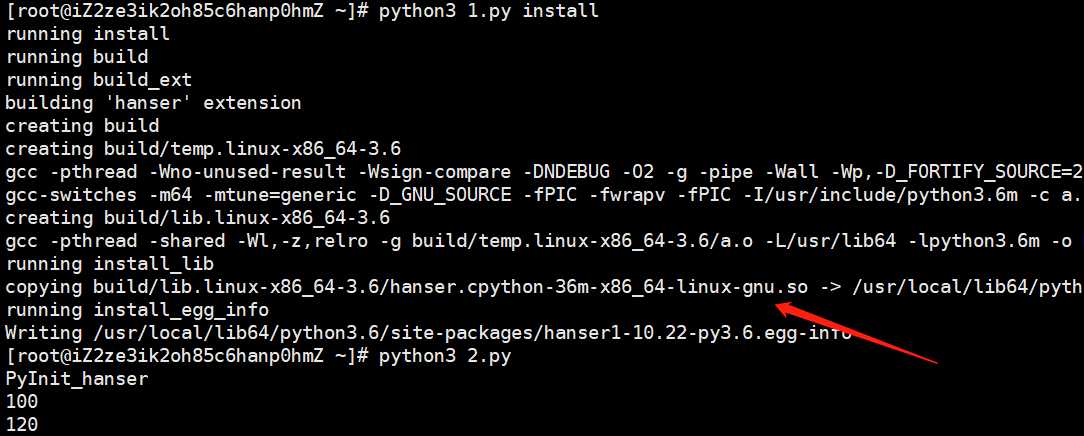
我们把代码放到linux上也是可以完美编译、执行的,此时的printf("%s
", PyInit_hanser)是先打印的,不过这才是正常结果。因此此时我们就编写了一个简单的扩展模块,下面来总结一下流程。
编写扩展模块流程总结
第一步:include "Python.h",必须要引入这个头文件,这个头文件中还引入了C中的一些标准库,具体都引入了哪些库我们可以查阅。当然如果不确定但又懒得看,我们还可以手动再引入一次,反正include同一个头文件只会引入一次。第二步:理论上这不是第二步,但是按照编写代码顺序我们就认为它是第二步吧,对,就是按照我们上面写的代码从上往下撸。这一步你需要编写函数,这个函数就是C语言中定义的函数,这个函数返回一个PyObject *,至少要接收一个PyObject *,我们一般叫它self,这第一个参数你可以看成是必须的,无论我们传不传其他参数,这个参数是必需要有的。所以如果只有这一个参数,那么我们就认为这个函数不接收参数,因为我们在调用的时候没有传递。static PyObject * f1(PyObject *self) { } static PyObject * f2(PyObject *) { } static PyObject * f3(PyObject *) { } //假设我们定义了这三个函数吧,三个函数都不接受参数 //至于接收复杂参数,比如python中的扩展参数*args、**kwargs怎么传递 //我们后面会详细介绍第三步:定义一个PyMethodDef类型的数组,这个数组也是我们后面的PyModuleDef对象中的一个参数,这个数组名字叫什么就无所谓了。至于PyMethodDef,它接收参数如下。另外我们可以单独使用PyMethodDef创建对象,然后将变量写到数组中,也可以直接在数组中创建,如果是直接在数组中创建的话,那么就不需要再使用PyMethodDef定义了,直接在{}里面写成员信息即可。static PyMethodDef module_functions[] = { { //函数名,你在C中定义的函数名和这里的字符串指定的名字要一致 "f1", //函数指针,最好使用PyCFunction转一下,可以确保不出问题。 //如果不转,我自己测试没有问题,但是编译时候会给警告,最好还是按照标准,把指针的类型转换一下 //转换成python底层识别的PyCFunction (PyCFunction)f1, METH_NOARGS, //参数类型,这里不接收参数,至于怎么接收*args和**kwargs的参数,后面说 "函数f1的注释" }, {"f2", (PyCFunction)f2, METH_NOARGS, "函数f2的注释"}, {"f3", (PyCFunction)f3, METH_NOARGS, "函数f3的注释"}, //别忘记,下面的{NULL, NULL},不要问我为什么,python源码就是这么写的 {NULL, NULL} }第四步:定义PyModuleDef对象,这个变量的名字叫什么也没有要求。static PyModuleDef m = { PyModuleDef_HEAD_INIT, //头部信息 //模块名,这个是有讲究的,你要编译的扩展模块叫啥,这里就写啥 //假设叫yousa吧,那么这里就写yousa "yousa", "模块的注释", -1, //模块的空间,这个是给子解释器调用的,我们不需要关心,直接写-1即可 module_functions, //然后是我们上面定义的数组名,里面放了一大堆的PyMethodDef结构体实例 //然后是四个NULL,还是不要问我为什么,源码就是这么写的,我们这么写也没错 NULL, NULL, NULL, NULL }第五步:写上一个宏,其实把它单独拆分出来,有点小题大做了。PyMODINIT_FUNC //一个宏,主要是保证函数按照C的标准,不用在意,写上就行第六步:按理说这是第二步的,不过无所谓啦。创建一个模块的入口函数,我们说编译的扩展模块叫yousa,那么这个函数名就要这么写PyInit_yousa(void) { //我们上面打印了一句话,但是生产中是没有必要的,所以直接根据上面定义的PyModuleDef实例,得到python中的模块 //PyModule_Create就是用来创建python中的模块的,直接将PyModuleDef定义的对象的指针扔进去 //便可得到python中的模块,然后直接返回即可。 return PyModule_Create(&m); }第七步:定义一个py文件,假设叫xx.py,那么在里面写上如下内容,然后python xx.py install即可from distutils.core import * setup( # 这是生成的egg文件名,也是里面的元信息中的Name name="yousa", # 版本号 version="10.22", # 作者 author="古明地觉", # 作者邮箱 author_email="东方地灵殿", # 当然还有其它参数,作为元信息来描述模块,比如description:模块介绍。有兴趣的话可以看函数的注释,或者根据已有的egg文件自己查看 # 下面是扩展模块,Extension("yousa", ["C源文件"]) # 我们说Extension里面的第一个参数也必须是你的扩展模块的名字,并且必须要和PyInit_XXX以及PyModuleDef中m_name保持一致 # 至于第二个参数就是一个列表,你需要用到哪些C源文件。 # 而且我们看到这个Extension也在一个列表里面,因为我们也可以传入多个Extension同时生成多个扩展模块。但是一般我们是写好一个生成一个,你也可以一次性写多个,然后只编译一次。 ext_modules=[Extension("hanser", ["a.c"])]
难点
我们看到编写一个扩展模块是有套路的,只要把上面的流程记好就没问题。难点在哪里呢?其实难点主要在函数的编写上面,比如python和C之间的类型互转,再比如我们后期传递*args,这在底层是一个PyTupleObject,我们还需要调用PyTupleObject的api来进行元素的解包。所以难点就在于函数的编写上面,因为要大量使用python底层的api。
再比如两个字符串相加,那么python中直接通过+就可以实现了,但是在底层你需要调用PyUnicode_Concat函数,因为python的底层就是这么干的,所以你也要这么干。所以我在上一篇博客中就说过,编写扩展模块需要有python源码的知识,因为你需要大量使用python底层的api,也许在python中对于*args,你可以很简单的就操作了,但是在底层你可能就需要多做一些事情。因此我一直强调要有python源码方面的知识,只有这样才能编写出复杂的扩展模块,如果仅仅是传递简单地数字、字符串,那编写扩展模块的意义何在呢?
因此可以多看看python底层的api,我之前也说过,python中api和底层的api是比较类似的,模式比较固定。比如我们对列表进行元素的修改,在底层就是PyList_SetItem,获取元素就是PyList_GetItem,因此如果不会的话可以去查一查。我们说源码的Include文件是放一些对象的定义,至于这些对象支持哪些操作都放在Objects目录下,而Python目录则是存放一些和虚拟机执行流程相关的。然后根据使用python的经验来猜测底层对应哪些函数,直接Ctrl+F5通过关键字查询,或者直接百度、谷歌也可以。当然我在下面,也会尽可能多介绍一些api。
与PyObject的再度重相逢
我们在上一篇中介绍了PyObject,我们说这里面存放了引用计数和类型,并且python中所有对象底层对应的结构体都嵌套了PyObject,因此python中的所有对象都有引用计数和类型。并且python的对象在底层,都可以看成是PyObject的一个扩展,都可以把类型转成PyObject。
PyObject *
PyLong_FromLong(long ival)
{
PyLongObject *v;
...
return (PyObject *)v;
}我们看到这个函数是把C中long转成PyLongObject,但是我们发现在返回的时候将PyLongObject?*转成了PyObject?*,因此我们定义函数的时候明明接收的是int,但是我们却不定义成PyLongObject?*,而是定义成PyObject?*,因为python底层的好多api接收都是PyObject?*。如果在函数执行的时候需要指定明确的类型,那么再转回来即可。
我们扯到PyObject上面来,还有一个原因,那就是引用计数。不过python专门定义了几个宏,我们来看一下:
#define Py_REFCNT(ob) (((PyObject*)(ob))->ob_refcnt)
#define Py_TYPE(ob) (((PyObject*)(ob))->ob_type)
#define Py_SIZE(ob) (((PyVarObject*)(ob))->ob_size)Py_REFCNT:拿到对象的引用计数;Py_TYPE:拿到对象的类型;Py_SIZE:拿到对象的ob_size,也就是变长对象里面的元素个数。
除此之外,python还提供了两个宏:Py_INCREF和Py_DECREF来用于引用计数的增加和减少。
//引用计数增加很简单,就是找到ob_refcnt,然后++
#define Py_INCREF(op) ( _Py_INC_REFTOTAL _Py_REF_DEBUG_COMMA ((PyObject *)(op))->ob_refcnt++)
//但是减少的话,做的事情稍微多一些
//其实主要就是判断引用计数是否为0,如果为0直接调用_Py_Dealloc将对象销毁
//_Py_Dealloc也是一个宏,会调用对应类型对象的tp_dealloc,也就是析构方法
#define Py_DECREF(op) do { PyObject *_py_decref_tmp = (PyObject *)(op); if (_Py_DEC_REFTOTAL _Py_REF_DEBUG_COMMA --(_py_decref_tmp)->ob_refcnt != 0) _Py_CHECK_REFCNT(_py_decref_tmp) else _Py_Dealloc(_py_decref_tmp); } while (0)python向扩展模块传递多个参数
我们说PyMethodDef定义的结构体有一个属性:ml_flags,这是一个int类型,它代表的函数的参数类型。
METH_VARARGS:传递多个位置参数METH_KEYWORDS:传递关键字参数METH_NOARGS:不接收参数METH_O:接收一个参数
我们说如果指接收一个参数,那么使用METH_O即可,如果接收多个参数呢?那么就使用METH_VARARGS,那么根据python的经验我们知道会得到一个元组,所以我们下面就要学习如何在C中对一个元组进行解包。另外, 如果只接收一个参数,我们还是可以把参数类型写成METH_VARARGS的,只不过此时的元组只有一个元素,一般情况下为了保证代码的通用性,我们都会写成METH_VARARGS。
我们说,如果是多个参数,那么得到的是一个元组,我们需要将参数从元组中解析出来。所使用的函数就是:int PyArg_ParseTuple(PyObject *args, const char *format, ...),我们注意到format是一个格式,类似于printf,里面肯定是一些占位符,那么都支持哪些占位符呢?
s:将const char*转成python中的str或者None,使用utf-8编码y:将const char*转成python中的bytes或者None,使用utf-8编码u:将const wchar_t*转成python中unicode,编码为utf-16或者ucs4i:将C中的int转为python中intb:将C中的char转为python中intl:将C中的long转为python中int
? 关于int,种类比较多,可以自己查看
f:将C中的float转成python的floatd:将C中的double转成python的floatO:将PyObject *转成python的object
至于其他的占位符,有兴趣可以自己搜索,并不一定所有的占位符都会用到。下面我们就来编写代码来实践一下, 此时的代码就不会每一行都有大量的注释了,如果是之前写过的就不写了,但是新出现的还是会详细解释的。
#include "Python.h"
static PyObject *
my_func1(PyObject *self, PyObject *args)
{
//目前我们定义了一个PyObject *args,如果传递一个参数,那么这个args就是对应的一个参数
//如果接收多个参数,还是只需要定义一个*args即可,只不过此时的*args是一个PyTupleObject,我们需要将多个参数解析出来
//此时我们这个函数是接收两个int,然后相加
int a, b;
//下面我们需要使用PyArg_ParseTuple进行解析,因为我们接收两个参数
//这个函数返回一个整型,如果失败会返回0,成功返回非0
//我们在python中传递过来的就是PyLongObject,这里会把a和b当成PyLongObject去解析
//然后把python传递过来的值交给a和b,但是a和b本质上还是一个int,只不过它们拿到了python传递过来的值
if (!PyArg_ParseTuple(args, "ii", &a, &b)){
//失败返回NULL,后面我们会介绍如何在底层返回一个异常
return NULL;
}
//返回相加的结果
return PyLong_FromLong(a + b);
}
static PyMethodDef module_functions[] = {
{
"my_func1",
(PyCFunction)my_func1,
METH_VARARGS, //这里要把参数类型改成METH_VARARGS
"this is a function named my_func1",
},
{NULL, NULL}
};
static PyModuleDef HANSER = {
PyModuleDef_HEAD_INIT,
"hanser",
"this is a module named hanser",
-1,
module_functions,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_hanser(void)
{
return PyModule_Create(&HANSER);
}
这里编译的过程我们就不显示了,跟之前是一样的。并且为了方便,我们的模块名就不改了,还叫hanser。但是编译之后的pyd文件内容已经变了,不过需要注意的是,我们说编译之后会有一个build目录,然后会自动把里面的pyd文件拷贝到site-packages中,如果你修改了代码,但是模块名没有变的话,那么编译之后的文件名还和原来一样。如果一样的话,那么它发现已经存在相同文件了,就不会再拷贝了。因此两种做法:要么你把模块名给改了,这样编译会生成新的模块。要么编译之前记得把上一次编译生成的build目录先删掉,我们推荐第二种做法,不然site-packages目录下会出现一大堆我们自己定义的模块。
import hanser
try:
print(hanser.my_func1())
except Exception as e:
# 我们看到,由于我们在解析的时候写了两个i,那么python解释器知道需要传递两个参数
# 这里这里报错了,当然后面我们也会自己在底层返回异常
print(e) # function takes exactly 2 arguments (0 given)
try:
print(hanser.my_func1("xx", 123))
except Exception as e:
# 还是那句话,我们解析的时候写的是两个i,那么解释器知道需要传递的都是整型
print(e) # an integer is required (got type str)
# 成功执行
print(hanser.my_func1(10, 25)) # 35类型检查和返回异常
在python中,当我们传递的类型不对会报错。那么在底层我如何才能检测传递过来的参数是不是想要的类型呢?可以使用PyXxx_Check,比如检测是不是float,那么就是PyFloat_Check。那么检测其他的类型,我想你一定知道如何举一反三。
如何返回一个异常呢?返回异常之前,我们需要知道python中的异常在底层对应什么?规则也很简单,比如TypeError,那么在底层就对应PyExc_TypeError,也就是说在前面加上一个PyExc即可。异常有了如何设置呢?有两种方式:PyErr_SetString和PyErr_Format
//我们这里就只把函数实现贴上去,其它的就不贴了, 因为是一样的
static PyObject *
my_func1(PyObject *self, PyObject *args)
{
//我们说args可以接收一个参数,那么该参数就是args
//记得下面的PyMethodDef实例的参数类型改成METH_O,表示接收一个参数
if (!PyFloat_Check(args)){
//我们说Py_TYPE是一个宏可以拿到对应的类型的指针,然后通过->tp_name就能够拿到类型名
//比如:PyLongObject *args, 那么Py_TYPE(args)就是&PyLong_Type,调用->tp_name拿到的就是字符串"int"
PyErr_Format(PyExc_TypeError, "参数传递错误,我们需要float,但是你传了%s
", Py_TYPE(args)->tp_name);
//如果不需要占位符,那么通过PyErr_SetString即可。接收一个异常类型和描述异常的字符串
return NULL;
}
//给传来的值加上一个3.5
double a = PyFloat_AsDouble(args);
a = a + 3.5;
return PyFloat_FromDouble(a);
}import hanser
try:
print(hanser.my_func1(1))
except Exception as e:
print(e) # type error,we need a float, but you pass a int
# 正常打印
print(hanser.my_func1(1.)) # 4.5PyUnicodeObject的传递
下面我们来看看python中的字符串如何返回。
static PyObject *
my_func1(PyObject *self, PyObject *args)
{
//我们下面是的函数参数类型是METH_VARARGS,说明这是个元组,那么元组为空也是可以的
//但是如果是METH_O,那么就必须传递一个参数了
wchar_t *s = L"古明地觉1234";
//这里我们直接返回,PyUnicode_FromWideChar表示将宽字符转成PyUnicodeObject,但是除了宽字符还需要有一个长度
int len = wcslen(s) + 1; //宽字符计算要使用wcslen,头文件是wchar.h,但是Python.h中已经引入了,由于�所以要多加个1
return PyUnicode_FromWideChar(s, len);
}import hanser
print(hanser.my_func1()) # 古明地觉1234然后试试如何传递字符串
#include "Python.h"
#include <locale.h>
static PyObject *
my_func1(PyObject *self, PyObject *args)
{
//为了支持各种符号,记得加上这一句
setlocale(LC_COLLATE, "en_US.UTF-8");
//定义函数,接收两个字符串,然后合并在一起
wchar_t *s1;
wchar_t *s2;
//我们看到这是两个指针,即便如此我们依旧需要传递地址,那么空间谁来分配
//不用想,肯定是在PyArg_ParseTuple中就分配了,而且这个空间是指向python内部的空间
//这里使用占位符u,如果python传递的是纯ascii字符串的话,那么也可以用s,但是为了支持中文以及其它符号,所以这里使用u
PyArg_ParseTuple(args, "uu", &s1, &s2);
//将两个字符串合并在一起,我们可以先转成PyObject *,然后使用PyUnicode_Concat合并
//也可以直接在C中先将两个宽字符合并在一起,然后再转成PyObject *,这里我们选择后一种
//计算长度,因为�,所以多需要一个空间
int len = wcslen(s1) + wcslen(s2) + 1;
wchar_t s[len];
wcscat(s, s1);
wcscat(s, s2);
return PyUnicode_FromWideChar(s, len);
}
static PyMethodDef module_functions[] = {
{
"my_func1",
(PyCFunction)my_func1,
METH_VARARGS,
"this is a function named my_func1",
},
{NULL, NULL}
};
static PyModuleDef HANSER = {
PyModuleDef_HEAD_INIT,
"hanser",
"this is a module named hanser",
-1,
module_functions,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_hanser(void)
{
return PyModule_Create(&HANSER);
}
import hanser
print(hanser.my_func1("嘿嘿", "哈哈")) # 嘿嘿哈哈
print(hanser.my_func1("啊~雪莉", "我想死你了(吸溜?(? ???ω??? ?)?)")) # 啊~雪莉我想死你了(吸溜?(? ???ω??? ?)?)控制多个参数的类型
现在我们知道怎么传递参数了,并且还会定义异常。但是我们仔细想一下,我们在使用PyArg_ParseTuple解析的时候,我们怎么知道占位符应该有多少个呢?假设用户参数传递少传了或者多传了,那么解析就出问题了。因此如果用户传递的参数个数不对,应该直接报出参数个数错误。
这是一方面,假设我需要三个参数,第一个参数要求是int、第二个要求是str、第三个要求是float。如果用户是按照这种逻辑传递的还好办,如果它传递的类型错误了,我们还按照对应的模式来解析肯定会出错。所以有一种办法是都解析成PyObject,还记得占位符吗?对的,使用大写的字母O。一般我们都会通过PyObject来进行解析。
#include "Python.h"
static PyObject *
my_func1(PyObject *self, PyObject *args)
{
//接收三个参数
int ob_size = Py_SIZE(args);
if (ob_size != 3){
PyErr_Format(PyExc_TypeError, "function my_func1 need 3 arguments, but got %d", ob_size);
return NULL;
}
//创建3个PyObject *
PyObject *obj1;
PyObject *obj2;
PyObject *obj3;
//创建的是指针,还是传入指针,所以传入的相当于是二级指针
//因为我们说python中的变量对应底层都是指针,这样才会给PyObject *类型的obj1、obj2、obj3赋值
//怎么赋值,创建对应的PyObject对象,然后将PyObject对象的指针给obj1、obj2、obj3
PyArg_ParseTuple(args, "OOO", &obj1, &obj2, &obj3);
//我们说三个参数分别接收int、str、float,那么把它们的类型取出来,依次比较
//使用的方法是strcmp,如果相等返回0,否则返回非0,
int arg1 = strcmp(Py_TYPE(obj1) -> tp_name, "int") == 0;
int arg2 = strcmp(Py_TYPE(obj2) -> tp_name, "str") == 0;
int arg3 = strcmp(Py_TYPE(obj3) -> tp_name, "float") == 0;
if (!arg1){
PyErr_Format(PyExc_TypeError, "arg1 need a int,but you pass a %s", Py_TYPE(obj1) -> tp_name);
} else if (!arg2){
PyErr_Format(PyExc_TypeError, "arg2 need a str,but you pass a %s", Py_TYPE(obj2) -> tp_name);
} else if(!arg3){
PyErr_Format(PyExc_TypeError, "arg3 need a float,but you pass a %s", Py_TYPE(obj3) -> tp_name);
} else {
return PyUnicode_FromWideChar(L"参数类型传递正确", 9);
}
return NULL;
}
static PyMethodDef module_functions[] = {
{
"my_func1",
(PyCFunction)my_func1,
METH_VARARGS,
"this is a function named my_func1",
},
{NULL, NULL}
};
static PyModuleDef HANSER = {
PyModuleDef_HEAD_INIT,
"hanser",
"this is a module named hanser",
-1,
module_functions,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_hanser(void)
{
return PyModule_Create(&HANSER);
}import hanser
try:
print(hanser.my_func1())
except Exception as e:
print(e) # function my_func1 need 3 arguments, but got 0
try:
print(hanser.my_func1(1))
except Exception as e:
print(e) # function my_func1 need 3 arguments, but got 1
try:
print(hanser.my_func1(1, 2))
except Exception as e:
print(e) # function my_func1 need 3 arguments, but got 2
try:
print(hanser.my_func1("", "", ""))
except Exception as e:
print(e) # arg1 need a int,but you pass a str
try:
print(hanser.my_func1(1, "", ""))
except Exception as e:
print(e) # arg3 need a float,but you pass a str
try:
print(hanser.my_func1(1, "", 1.)) # 参数类型传递正确
except Exception as e:
print(e)传递关键字参数
传递关键字参数的话,那么我们可以通过key=value的方式来实现,那么在C中我们如何解析呢?既然支持关键字的方式,那么是不是也可以实现默认的参数,就是我们不传会使用默认值呢?答案是支持的,我们知道解析位置参数是通过PyArg_ParseTuple,那么解析关键字参数是通过PyArg_ParseTupleAndKeywords
//函数原型
int PyArg_ParseTupleAndKeywords(PyObject *args, PyObject *kw, const char *format, char *keywords[], ...) 我们看到相比原来的PyArg_ParseTuple,多了一个kw和一个char*类型的数组,具体怎么用我们在编写代码的时候说。
#include "Python.h"
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
//我们说函数既可以通过位置参数、还可以通过关键字参数传递,那么函数的参数类型就要变成METH_VARARGS | METH_KEYWORDS
//假设我们定义了三个参数,name、age、place,这三个参数可以通过位置参数传递、也可以通过关键字参数传递
char *name = ""; //姓名
int age = 17; //年龄
char *place = "东方地灵殿"; //居住地
//可能有人注意了,我们之前使用的是wchar_t表示宽字符
//但是使用char *也可以支持中文,至少在python层面是支持的,那么我们就使用char吧
//使用wchar_t会很麻烦,既然是char *,那么我们的占位符就不用u了,而是使用s
//告诉python解释器,参数的名字,注意:这里面字符串的顺序就是函数定义的参数顺序
//也是keys后面的变量顺序,其实变量名字叫什么无所谓,但是类型要和format中对应的占位符匹配,只是为了一致我们会起相同的名字
//注意结尾要有一个NULL,否则会报出段错误。
char *keys[] = {"name", "age", "place", NULL}; //这个NULL很重要
//解析参数,我们看到format中本来应该是sis的,但是中间出现了一个|
//这就表示|后面的参数是可以不填的,如果不填会使用我们上面给出的默认值
//因此这里name就是必填的,因为它在|的前面,而age和place可以不填,如果不填就用我们上面给出的默认值
//keys就是定义的参数的名字,后面把参数的指针传进去
if (!PyArg_ParseTupleAndKeywords(args, kw, "s|is", keys, &name, &age, &place)){
return NULL;
}
char ret[100];
//格式化字符串
sprintf(ret, "你的名字是:%s, 年龄是:%d, 居住地是:%s", name, age, place);
//这里不再从宽字符来转了,应该是FromString,就是从C中字符串转成python中的字符串
//而且这个函数只需要字符数组,不需要再指定字符的个数了,很方便
return PyUnicode_FromString(ret);
}
static PyMethodDef module_functions[] = {
{
"my_func1",
(PyCFunction)my_func1,
METH_VARARGS | METH_KEYWORDS, //参数类型要改成这个
"this is a function named my_func1",
},
{NULL, NULL}
};
static PyModuleDef HANSER = {
PyModuleDef_HEAD_INIT,
"hanser",
"this is a module named hanser",
-1,
module_functions,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_hanser(void)
{
return PyModule_Create(&HANSER);
}import hanser
try:
# 我们在C中写的是s|is,表示后面的两个参数如果不填是默认的
# 填了就是我们指定的
print(hanser.my_func1("古明地觉")) # 你的名字是:古明地觉, 年龄是:17, 居住地是:东方地灵殿
except Exception as e:
print(e)
try:
# 也可以手动指定关键字
print(hanser.my_func1(name="古明地恋")) # 你的名字是:古明地恋, 年龄是:17, 居住地是:东方地灵殿
except Exception as e:
print(e)
try:
# 我们说name是必须传递的
print(hanser.my_func1())
except Exception as e:
print(e) # Required argument 'name' (pos 1) not found
try:
# xxx显然不在char *key[]中
print(hanser.my_func1("古明地觉", xxx=123))
except Exception as e:
print(e) # 'xxx' is an invalid keyword argument for this function
try:
# 同理我们可以手动指定age
print(hanser.my_func1("古明地恋", age=15))
except Exception as e:
print(e) # 你的名字是:古明地恋, 年龄是:15, 居住地是:东方地灵殿
try:
# 也可以全部使用关键字参数指定
print(hanser.my_func1(name="椎名真白", age=17, place="樱花庄")) # 你的名字是:椎名真白, 年龄是:17, 居住地是:樱花庄
except Exception as e:
print(e)
try:
# 多传递一个参数呢?也会提示我们参数传递错误
print(hanser.my_func1("椎名真白", 17, "樱花庄", 123))
except Exception as e:
print(e) # function takes at most 3 arguments (4 given)
try:
# 参数类型不对,也会提示我们,因为我们在占位符中指定的是sis
# 第三个占位符是s,不是i,因此传递的123就不符合类型,所以python也会提示我们参数传递的不对
print(hanser.my_func1("椎名真白", 17, 123))
except Exception as e:
print(e) # argument 3 must be str, not int我们就是实现了支持关键字参数的函数,我们说使用PyArg_ParseTupleAndKeywords的时候,里面写上了args和kw,这表示既支持位置参数、也支持关键字参数。至于顺序就是代码中的顺序,我们看到如果参数传递的个数不正确,python会自动提示你。
因此为了保证python中传参的习惯,我们会选择使用METH_VARARGS?|?METH_KEYWORDS这种方式,表示两种都支持。而且使用这种方式最大的两个好处就是:传递的参数的个数和函数接收的个数不相同,那么python会直接告诉你参数传递个数有问题,不需要我们再通过ob_size来判断了;还有参数类型必须和占位符中指定的类型匹配,否则也会直接提示我们第几个参数类型错误,就不用再通过占位符全部指定为O、获取PyObject *,然后再拿到对应类型的tp_name来一个一个判断了。
返回布尔类型和None
我们说函数都必须返回一个PyObject *,如果这个函数没有返回值,那么在python中实际上返回的是一个None,但是我们不能返回NULL,None和NULL是两码事。在扩展函数中,如果返回NULL就表示这个函数执行的时候,不符合某个逻辑,我们需要终止掉,不能再执行下去了。这是在底层,但是在python的层面,你需要告诉使用者为什么不能执行了,或者说底层的哪一行代码不满足条件,因此这个时候我们会在return NULL之前需要手动设置一个异常,这样在python代码中就会报错,才知道为什么底层函数退出了。当然有时候会自动帮我们设置,比如上面的参数解析错误。
那么在底层如何返回一个None呢?既然要返回我们就需要知道它的结构是什么。
# 首先在python中,None也是有类型的
print(type(None)) # <class 'NoneType'>
# 这个NoneType在底层对应的是_PyNone_Type
# 至于None在底层对应的结构体是_Py_NoneStruct,所以我们返回的时候应该返回这个结构体的指针
# 不过官方不推荐直接使用,而是给我们定义了一个宏
# #define Py_None (&_Py_NoneStruct),我们直接返回Py_None即可。
"""
不光是None,我们说还有True和False
True和False对应的结构体是:_Py_FalseStruct, _Py_TrueStruct,它们本质上是PyLongObject
python也不推荐直接返回,也是定义了两个宏
#define Py_False ((PyObject *) &_Py_FalseStruct)
#define Py_True ((PyObject *) &_Py_TrueStruct)
推荐我们使用Py_False和Py_True
"""下面我们来试一下:
#include "Python.h"
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
//接收一个名为age的int,范围要求大于0,否则报错
int age = 18;
//这里即便只有一个参数,为了能够支持python函数的传递方式,我们会一直使用PyArg_ParseTupleAndKeywords来解析
char *keys[] = {"age", NULL}; //还是那句话别忘记NULL
//age如果不传,默认是18,所以占位符要设置成|i
if (!PyArg_ParseTupleAndKeywords(args, kw, "|i", keys, &age)){
//解析出错直接返回,否则程序会继续往下走
//而参数解析出了问题,python会自动报出错误,这个不需要我们关心
//所以直接return一个NULL即可
return NULL;
}
if (age <= 0){
//这个时候不符合我们逻辑而结束程序,就需要我们手动设置一个异常了
//至于像参数解析、参数类型,如果不符合指定的占位符,python会帮我们返回异常信息
//但是像这种与我们的逻辑不符,我们在结束之前肯定要设置异常,不然莫名退出了,别人也不知道哪里出问题了
PyErr_SetString(PyExc_ValueError, "age must be greater than 0");
//或者设置的更详细一些,还可以这么写
// PyErr_Format(PyExc_ValueError, "age must be greater than 0, but got %d", age);
//让函数退出,不往下执行了
return NULL;
} else if (age < 14) {
//年龄太小不行,会死刑的
//返回False,坚决表名立场
return Py_False;
} else if (age < 18) {
//这个就看情况啦,兴许只是三年呢?
//返回None,表示我也不知道会咋样
return Py_None;
} else if (age < 30) {
//这个就没问题了吧
return Py_True;
} else {
//坚决表名立场,年纪太大
return Py_False;
}
}
static PyMethodDef module_functions[] = {
{
"my_func1",
(PyCFunction)my_func1,
METH_VARARGS | METH_KEYWORDS, //参数类型要改成这个
"this is a function named my_func1",
},
{NULL, NULL}
};
static PyModuleDef HANSER = {
PyModuleDef_HEAD_INIT,
"hanser",
"this is a module named hanser",
-1,
module_functions,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_hanser(void)
{
return PyModule_Create(&HANSER);
}
import hanser
try:
# 我们不传会使用默认值
print(hanser.my_func1()) # True
except Exception as e:
print(e)
try:
# 类型错误
print(hanser.my_func1(""))
except Exception as e:
print(e) # an integer is required (got type str)
try:
# 参数个数错误
print(hanser.my_func1(15, ""))
except Exception as e:
print(e) # function takes at most 1 argument (2 given)
try:
# 传递了不存在的参数
print(hanser.my_func1(name=15))
except Exception as e:
print(e) # 'name' is an invalid keyword argument for this function
try:
# 这个时候参数解析就不会出问题了,因为-1是一个int
# 但是它不符合我们的逻辑,因此底层函数退出,但是这时候我们就需要手动设置一个异常了
# 来告诉使用者,为什么函数退出了
print(hanser.my_func1(-1))
except Exception as e:
print(e) # age must be greater than 0
try:
# age < 14,返回False
print(hanser.my_func1(age=13))
except Exception as e:
print(e) # False
try:
print(hanser.my_func1(16))
except Exception as e:
print(e) # None
try:
print(hanser.my_func1(age=18))
except Exception as e:
print(e) # True
try:
print(hanser.my_func1(age=35))
except Exception as e:
print(e) # False
PyTupleObject
传递PyTupleObject
下面我们就传递元组了,我们说像int、str这些在C的层面上是可以直接解析的,因为C中原生支持这些类型,比如:int、long、char *等等。但是像python中的元组、列表、字典、集合啊等等,在C中并没有原生的数据结构来支持。因此对于这些对象的解析,我们统统会使用O这个占位符,转成PyObject *,然后通过宏Py_TYPE获取类型,然后再通过->tp_name,获取它到底是一个什么对象,是tuple啊、list啊、还是dict什么的。
还是先剧透一些api。
Py_TupleSize:获取python传递过来的元组内的元素个数Py_TupleNew:接收一个整型,表示创建一个能容纳指定个数(PyObject *指针)的元组PyTuple_Check:检测是否为一个PyTupleObjectPy_TupleSetItem:设置元素Py_TupleGetItem:获取元素
下面我们来定义一个函数,接收一个只能存放int的元组,然后把里面的元素全部相加,然后返回。
#include "Python.h"
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
//创建一个元组,此时指针为NULL
PyObject *t = NULL;
//变量类型,要是通过先定义再赋值的方式,那么这里最好写const char *
//因为通过tp_name返回的也是一个const char *,尽管我们写成char *也没问题,但是编译会出警告,就让人不舒服
//这里type是一个指针,指向字符数组的首个元素的地址,这里表示指针指向的内容不能变,也就是对应的字符数组的首个元素不能变
//但是指针本身是可以变的,它想指向谁就指向谁,当然在做的各位C的水平肯定比我强,这里就不献丑了。
const char *type;
//元组的元素个数
int counts;
// 用于遍历的索引
int i;
//元组内的每一个元素
//都是一个PyObject *
PyObject *value;
//总和,如果传递的元组为空,那么总和为0
//python中sum(())或者sum([])也是这么做的
int sum = 0;
char *keys[] = {"t", NULL};
if (!PyArg_ParseTupleAndKeywords(args, kw, "O", keys, &t)){
return NULL;
}
//获取变量类型
type = Py_TYPE(t) -> tp_name;
//这是一种判断方式,还可以使用PyTuple_Check来检测传递过来的是不是一个元组
if (strcmp(type, "tuple") != 0){
PyErr_Format(PyExc_TypeError, "a tuple is required, but got %s", type);
return NULL;
}
//获取元素个数,还可以通过Py_SIZE(t) -> ob_size来获取,还记得吗?
//当时我们介绍了三个宏,Py_REFCNT、Py_TYPE、Py_SIZE,不记得了回头看看
//这里返回的类型其实是一个Py_ssize_t,我们使用int也是一样的
counts = PyTuple_Size(t);
for (i=0;i<counts;i++){
//获取对应元素,并检测是否为python中的int
value = PyTuple_GetItem(t, i);
if (!PyLong_Check(value)){
//不是int,则报错
PyErr_Format(PyExc_ValueError, "the value of index %d is not int, but %s", i, Py_TYPE(value) -> tp_name);
return NULL;
}
sum += PyLong_AsLong(value);
}
//结果返回
return PyLong_FromLong(sum);
}
static PyMethodDef module_functions[] = {
{
"my_func1",
(PyCFunction)my_func1,
METH_VARARGS | METH_KEYWORDS,
"this is a function named my_func1",
},
{NULL, NULL}
};
static PyModuleDef HANSER = {
PyModuleDef_HEAD_INIT,
"hanser",
"this is a module named hanser",
-1,
module_functions,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_hanser(void)
{
return PyModule_Create(&HANSER);
}
import hanser
try:
print(hanser.my_func1())
except Exception as e:
print(e) # Required argument 't' (pos 1) not found
try:
print(hanser.my_func1((1, 2, "", 4)))
except Exception as e:
print(e) # the value of index 2 is not int, but str
try:
print(hanser.my_func1([1, 2, 3, 4]))
except Exception as e:
print(e) # a tuple is required, but got list
try:
print(hanser.my_func1((1, 3, 5, 7))) # 16
except Exception as e:
print(e)
try:
print(hanser.my_func1(tuple(range(101)))) # 5050
except Exception as e:
print(e)返回PyTupleObject
知道怎么传递了,那么下面我们返回一个元组。
#include "Python.h"
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
//这次不需要参数,但是我们的参数类型不用改
//这个类型是通用的,如果不接收参数,那么对应的元组或者字典就会空
//因此如果传入参数是不允许的话,那么你可以获取args和kw的ob_size进行检测一下
//如果不为零,那么返回异常并return NULL
//创建一个元组,容量为4
PyObject *t = PyTuple_New(4);
char *words[] = {"我永远", "喜欢", "satori", "酱~~"};
int i;
for (i=0;i<4;i++){
PyTuple_SetItem(t, i, PyUnicode_FromString(words[i]));
}
return t;
}
static PyMethodDef module_functions[] = {
{
"my_func1",
(PyCFunction)my_func1,
METH_VARARGS | METH_KEYWORDS,
"this is a function named my_func1",
},
{NULL, NULL}
};
static PyModuleDef HANSER = {
PyModuleDef_HEAD_INIT,
"hanser",
"this is a module named hanser",
-1,
module_functions,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_hanser(void)
{
return PyModule_Create(&HANSER);
}
import hanser
print(hanser.my_func1()) # ('我永远', '喜欢', 'satori', '酱~~')PyListObject
传递和返回
PyListObject的传递和返回和PyTupleObject几乎是一样的,只不过PyListObject可以修改罢了,所以传递和返回我们就放在一起介绍了。
还是剧透几个api,和上面的PyTupleObject一样,只需要把Tuple换成List即可,我们这里就不写了。
#include "Python.h"
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *l1 = NULL;
char *keys[] = {"l1", NULL};
PyArg_ParseTupleAndKeywords(args, kw, "O", keys, &l1);
if (!PyList_Check(l1)){
PyErr_Format(PyExc_TypeError, "need a list, but got %s", Py_TYPE(l1) -> tp_name);
return NULL;
}
//拿到原来list对象的元素个数
Py_ssize_t counts = PyList_Size(l1);
//申请对应的空间
PyObject *l2 = PyList_New(counts);
//我们将list对象倒序返回
int i;
for (i=0; i<counts;i++){
//将l1的第i个元素,放在l2的counts-1-i的位置上
PyList_SetItem(l2, counts-1-i, PyList_GetItem(l1, i));
}
return l2;
}
static PyMethodDef module_functions[] = {
{
"my_func1",
(PyCFunction)my_func1,
METH_VARARGS | METH_KEYWORDS, //参数类型要改成这个
"this is a function named my_func1",
},
{NULL, NULL}
};
static PyModuleDef HANSER = {
PyModuleDef_HEAD_INIT,
"hanser",
"this is a module named hanser",
-1,
module_functions,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_hanser(void)
{
return PyModule_Create(&HANSER);
}
import hanser
print(hanser.my_func1([1, 2, "嘿嘿", "哈哈"])) # ['哈哈', '嘿嘿', 2, 1]添加、插入、删除
我们说PyListObject对象是支持动态修改的,在python中可以进行append、insert、remove。那么它们对应的底层接口是什么呢,我们来看一下。
PyList_Append:在尾部添加一个元素PyList_Insert:在中间插入一个元素list_remove:删除指定的元素,但是我们发现这是小写的。因为python并没有给我们开放这个api,我们能使用的api都是大写的,基本上都是以PyXxx开头的。因此这个方法我们可以参考源码手动实现。PyList_SetSlice:删除指定切片的元素
#include "Python.h"
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *l1 = NULL;
char *keys[] = {"l1", NULL};
PyArg_ParseTupleAndKeywords(args, kw, "O", keys, &l1);
if (!PyList_Check(l1)){
PyErr_Format(PyExc_TypeError, "need a list, but got %s", Py_TYPE(l1) -> tp_name);
return NULL;
}
//假设传递有5个元素的list对象, [1, 2, 3, 4, 5]
//将第3个元素删除,那么直接将索引为2:3的部分设置为NULL即可,记得要转成PyObject *
PyList_SetSlice(l1, 2, 3, (PyObject *)NULL); // 变成[1, 2, 4, 5]
//再尾部添加一个python的字符串
PyList_Append(l1, PyUnicode_FromString("古明地觉")); // 变成[1, 2, 4, 5, "古明地觉"]
//在索引为1的地方插入一个float
PyList_Insert(l1, 1, PyFloat_FromDouble(3.14)); // 变成[1, 3.14, 2, 4, 5, "古明地觉"]
//删除值为5的元素
//以下是源码的实现方式,我们做了一点点修改
//因为list_remove这个方法没有开放给我们,在listobject.c中没有PyList_Remove这个方法
Py_ssize_t i;
for (i = 0; i < Py_SIZE(l1); i++) {
//循环循环遍历每一个元素,比较是否相等
//这个是富比较,接收两个值,以及一个操作(Py_LT, Py_LE, Py_EQ, Py_NE, Py_GT, Py_GE)
//相等返回1,否则返回0
//注意:这里的l1是PyObject *,我们想调用ob_item的话,那么需要转成PyListObject *
//但是类型转换的优先级比,.xx、->xxx、[index]的优先级低,所以要加上小括号
int cmp = PyObject_RichCompareBool(((PyListObject *)l1)->ob_item[i], PyLong_FromLong(5), Py_EQ);
//cmp > 0,说明找到对应元素了,然后执行删除操作
if (cmp > 0) {
//实际上PyList_SetSlice底层调用的是list_ass_slice,而list_ass_slice并没有开放给我们使用
PyList_SetSlice(l1, i, i+1, (PyObject *)NULL);
//删除完毕之后跳出循环
break;
}
//我们看到这里居然没有{},这算是C语言的一个特点吧
//如果条件不满足,那么if条件的下面一行代码不会执行,注意只是下面的一行代码
//我们说cmp理论上要么为1、要么为0,如果小于0,说明富比较那里出错了
//比如:我们定义一个类A,然后重写__eq__方法,在里面raise一个异常,那么A的实例对象在比较的时候就会引发异常
else if (cmp < 0)
return NULL;
}
//如果i和Py_SIZE(l1)相等,证明走到头了,说明不存在指定的元素
if (i == Py_SIZE(l1)){
PyErr_SetString(PyExc_ValueError, "list.remove(x): x not in list");
return NULL;
}
//操作执行完毕之后返回,因为list修改是在原地操作的
//所以这里返回一个None,注意不是NULL,因为返回NULL意味着报错了
//返回None,我们知道可以通过return Py_None,但是python还给我们提供了一个宏
//我们直接写Py_RETURN_NONE;表示return Py_None
Py_RETURN_NONE;
}
static PyMethodDef module_functions[] = {
{
"my_func1",
(PyCFunction)my_func1,
METH_VARARGS | METH_KEYWORDS, //参数类型要改成这个
"this is a function named my_func1",
},
{NULL, NULL}
};
static PyModuleDef HANSER = {
PyModuleDef_HEAD_INIT,
"hanser",
"this is a module named hanser",
-1,
module_functions,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_hanser(void)
{
return PyModule_Create(&HANSER);
}import hanser
l = [1, 2, 3, 4, 5]
print(hanser.my_func1(l)) # None
print(l) # [1, 3.14, 2, 4, '古明地觉']
try:
hanser.my_func1([1, 2, 3])
except Exception as e:
print(e) # list.remove(x): x not in listPyDictObject
下面我们来看看PyDictObject怎么在C中进行操作,老规矩还是来看看有哪些api。
解析字典:PyArg_ParseTuple(args, "O", &dic)查看是不是PyDictObject:PyDict_Check(dic)查看键值对个数:PyDict_Size(dic)查看所有的key:PyDict_Keys(dic),会返回一个PyListObject *,里面是PyObject *查看所有的value:PyDict_Values(dic),会返回一个PyListObject *,里面是PyObject *查看所有的item:PyDict_Items(dic),会返回一个PyListObject *,里面是PyTupleObject *迭代遍历:PyDict_Next(dic, Py_ssize_t *pos, PyObject **keys, PyObject **values)查看字典是否包含某个key:PyDict_Contains(dic, key)获取某个key对应的value:PyDict_GetItem(dic, key),key为PyObject *获取某个key对应的value:PyDict_GetItemString(dic, key),key为char *,所以这个api只适用于key为str的类型的设置key、value:PyDict_SetItem(dic, key, value)删除一个key:PyDict_DelItem(dic, key),key不存在会抛异常
好吧,具体怎么操作就不演示了,可以自己尝试一下。
引用计数和内存管理
我们目前都没有涉及到内存管理的操作,我们说python中的对象都是申请在堆区的,这个是不会自动释放的。
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = PyUnicode_FromString("你好呀~~~");
return Py_None;
}这个函数不需要参数,如果我们写一个死循环不停的调用这个函数,你会发现内存的占用蹭蹭的往上涨。就是因为这个PyUnicodeObject是申请在堆区的,此时内部的引用计数为1,尽管C中函数的变量存储在栈区,函数执行完毕变量s被销毁了,但是s是一个指针,这个指针被销毁了是不假,但是它指向的内存并没有被销毁。
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = PyUnicode_FromString("你好呀~~~");
Py_DECREF(s);
return Py_None;
}因此我们需要手动调用Py_DECREF这个宏,来将s指向的PyUnicodeObject的引用计数减1,这样引用计数就为0了,至于到底是否被回收,就看我们在python中是否有变量去接收,如果有,那么引用计数会再次加1,于是就不会被回收。不过有一个特例,那就是当这个指针作为返回值的时候,我们不需要手动减去引用计数,因为会自动减。
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = PyUnicode_FromString("你好呀~~~");
//如果我们把s给返回了,那么我们就不需要调用Py_DECREF了
//因为一旦作为返回值,那么会自动减去1
//所以我们前面说C中的对象是由python来管理的,准确的说应该是作为返回值的指针指向的对象是由python来管理的
return s;
}不过这里还存在一个问题,那就是我们在C中返回的是python传过来的
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = NULL;
char *keys[] = {"s", NULL};
PyArg_ParseTupleAndKeywords(args, kw, "O", keys, &s);
//传递过来一个PyObject *,然后原封不动的返回
//此时你会发现在python中,创建一个变量,然后传递到my_func1中
//再进行打印就会发生段错误,因为对应的内存已经被回收了
//如果能正常打印,说明在python中这个变量的引用计数不为1,可能是小整数对象池、或者有多个变量引用,那么就创建一个大整数或者其他的变量多调用几次。
//因为作为返回值,每次调用引用计数都会减1
//或者调用之前和调用之后分别使用sys.getrefcount函数查看引用计数的变化
return s;
}因为s指向的内存不是在C中调用api创建的,而是python创建然后传递过来、解析出来的,也就是说这个s在解析之后已经指向了一块合法的内存。但是内存中的对象的引用计数是没有变化的,虽说有新的变量(这里的s)指向它了,但是这个s是C中的变量不是python中的变量,因此你可以认为它的引用计数是没有变化的。
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
//假设创建一个PyListObject
PyObject *l1 = PyList_New(2);
//这个是将l1赋值给l2,但是不好意思,这两位老铁指向的PyListObject的引用计数还是1
PyObject *l2 = l1;
return s;
}因此我们说,如果在C中创建一个PyObject的话,那么它的引用计数只会是1,因为对象被初始化了,引用计数默认是1。至于传递无论你在C中将创建PyObject返回的指针赋值给了多少个变量,它们指向的PyObject的引用计数都会是1。因为这些变量是C中的变量,不是python中的。
因此我们的问题就很好解释了,我们说当一个PyObject *作为返回值的时候,它指向的对象的引用计数会减去1,那么当python传递过来一个PyObject *指针的时候,由于它作为了返回值,因此引用计数会减1。因此当你在python中调用扩展函数结束之后,这个变量指向的内存可能就被销毁了。
如果你在python传递过来的指针没有作为返回值,那么怎么引用计数是不会发生变化的,但是一旦作为了返回值,引用计数会自动减1,因此我们需要手动的加1
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = NULL;
char *keys[] = {"s", NULL};
PyArg_ParseTupleAndKeywords(args, kw, "O", keys, &s);
//这样就没有问题了。
Py_INCREF(s);
return s;
}因此我们可以得出如下结论:
如果在C中,创建一个PyObject *var,并且var已经指向了合法的内存,比如调用PyList_New、PyDict_New等等api返回的PyObject *,总之就是已经存在了PyObject,那么如果var没有作为返回值,我们必须手动地将var指向的对象的引用计数减1,否则这个对象就会在堆区一直待着不会被回收。可能有人问,如果PyObject *var2 = var,我将var再赋值给一个变量呢?那么只需要对一个变量进行Py_DECREF即可,当然对哪个变量都是一样的,因为在C中变量的传递不会导致引用计数的增加。如果C中创建的PyObject *作为返回值而存在了,那么会自动将指向的对象的引用计数减1,因此此时该指针指向的内存就由python来管理了,就相当于在python中创建了一个对象,我们不需要关心。最后关键的一点,如果C中返回的指针指向的内存是python中创建好的,假设我们在python中创建了一个对象,然后把指针传递过来了,但是我们说这不会导致引用计数的增加,因为赋值的变量是C中的变量。如果C中用来接收参数的指针没有作为返回值,那么引用计数在扩展函数调用之前是多少、调用之后还是多少。一旦作为了返回值,我们说引用计数会自动减1,因此假设你在调用扩展函数之前引用计数是3,那么调用之后你会发现引用计数变成了2。为了防止段错误,一旦作为返回值,我们需要在返回之前手动地将引用计数加1。
我们来看几个例子:
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = NULL;
char *keys[] = {"s", NULL};
PyArg_ParseTupleAndKeywords(args, kw, "O", keys, &s);
//假设这个s是一个PyDictObject *
if (!PyDict_Contains(s, PyUnicode_FromString("name"))){
//如果s不包含name这个key,终止函数,当然这里就不设置异常了
return NULL;
}
return Py_None;
}如果写死循环,调用这个函数会怎么样?答案是内存的使用会不断增加,为什么?就是因为在检测的时候,我们写了PyUnicode_FromString("name"),这个对象是申请在堆区,我们并没有释放,因此每调用一次函数都会创建这样一个PyUnicodeObject对象,于是会导致内存使用不断增加。正确写法应该是这样:
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = NULL;
char *keys[] = {"s", NULL};
PyArg_ParseTupleAndKeywords(args, kw, "O", keys, &s);
PyObject *k = PyUnicode_FromString("name");
if (!PyDict_Contains(s, k)){
return NULL;
}
//先创建,然后再减去引用计数,这样就不会发生内存泄露了
Py_DECREF(k);
//可能有人问这个s怎么办?我们这个s指向的内存是python中创建的,它不会导致引用计数的变化
//而一旦函数结束,这个指针就被销毁了,因此指针也不会占用空间
//至于它指向的内存到底如何,就完全取决于python中的代码是怎么写的。
//因此我们python中的变量怎么过来的,就怎么回去,不会影响。
//前提是我们不能够返回这个s,而一旦返回了s,那么会自动的将s指向的对象的引用计数减1
//因此如果返回了s,我们还需要手动地调用Py_INCREF将s指向的对象的引用计数加1
//当然了,至于用C的类型创建的变量,像什么int啊、char *啊,这些就不用说了
//随着函数的结束会将指针连带指向的内存一块被销毁,我们关心的是PyObject *指向的内存,因为它是在堆区的
//栈区的变量我们不需要关心
return Py_None;
}再比如:
static PyObject *
my_func1(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = NULL;
char *keys[] = {"s", NULL};
PyArg_ParseTupleAndKeywords(args, kw, "O", keys, &s);
PyObject *k = PyUnicode_FromString("name");
if (!PyDict_Contains(s, k)){
return NULL;
}
PyObject *v = PyDict_GetItem(s, k);
Py_DECREF(k);
return Py_None;
}我们这里获取了字典s中键为k的value,并用v来接收。那么此时会不会发生内存泄露?答案是不会的,因为我们减去了k的引用计数。至于v,那么这个v指向的对象是谁创建的呢?显然是python中已经创建好的,因为获取的就是python中字典对应的值,如果我们再使用Py_DECREF(v);减去引用计数,那么反而有点"偷鸡不成蚀把米"的感觉,因为这有可能导致python中对应的value指向的内存被回收。
在不作为返回值的情况下:如果一个变量指向的内存是C中创建的,那么记得使用Py_DECREF将引用计数减1;如果是python中创建的,那么不需要做任何事情在作为返回值的情况下:如果一个变量指向的内存是C中创建的,那么不需要做任何事情;如果是python中创建的,那么记得使用Py_INCREF将引用计数加1。
ok,就这么简单。
以上是关于使用C语言为python编写动态模块--解析python中的对象如何在C语言中传递并返回的主要内容,如果未能解决你的问题,请参考以下文章