1、从列表和字典危机入手,深入了解列表、字典、字符串的底层实现。
2、掌握解析语法和条件表达式。
3、了解生成器、迭代器和装饰器的实现。
一、数据类型的底层实现
1.1 列表
1.1.1、错综复杂的复制
浅拷贝
list_1 = [1, [22, 33, 44], (5, 6, 7), {"name": "Sarah"}]
# list_3 = list_1 # 错误
list_2 = list_1.copy() # 或者list_1[:] list(list_1) 均可实现浅拷贝,但此时lsit_1和list_2均指向的是同一地址
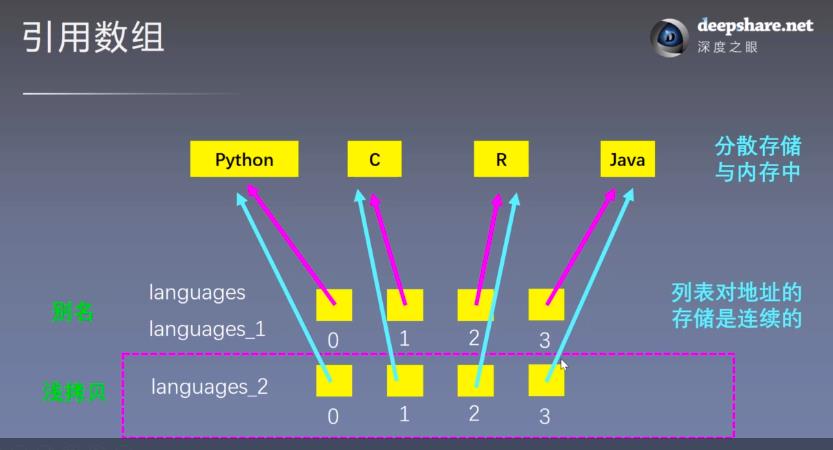
列表的底层实现
引用数组的概念:列表内的元素可以分散的存储在内存中,列表存储的是这些元素的地址
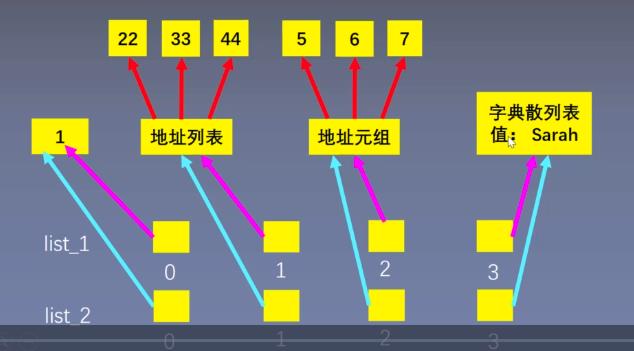
- 新增元素
list_1 = [1, [22, 33, 44], (5, 6, 7), {"name": "Sarah"}]
# list_2 = list_1.copy() # 或者list_1[:] list(list_1) 均可实现浅拷贝
list_2 = list(list_1)
list_1.append(100)
list_2.append("n")
print("list_1: ", list_1)
print("list_2: ", list_2)
"""
list_1: [1, [22, 33, 44], (5, 6, 7), {\'name\': \'Sarah\'}, 100]
list_2: [1, [22, 33, 44], (5, 6, 7), {\'name\': \'Sarah\'}, \'n\']
"""
- 修改元素
list_1[0] = 10
list_2[0] = 20
print("list_1: ", list_1)
print("list_2: ", list_2)
"""
list_1: [10, [22, 33, 44], (5, 6, 7), {\'name\': \'Sarah\'}]
list_2: [20, [22, 33, 44], (5, 6, 7), {\'name\': \'Sarah\'}]
"""
- 对列表型元素进行操作
list_1[1].remove(44)
list_2[1] += [55, 66]
print("list_1: ", list_1)
print("list_2: ", list_2)
"""
list_1: [1, [22, 33, 55, 66], (5, 6, 7), {\'name\': \'Sarah\'}]
list_2: [1, [22, 33, 55, 66], (5, 6, 7), {\'name\': \'Sarah\'}]
"""
- 对元组型元素进行操作
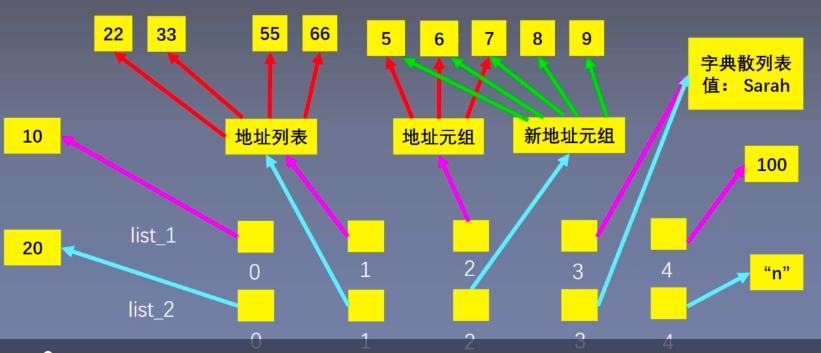
list_2[2] += (8, 9)
print("list_1: ", list_1)
print("list_2: ", list_2)
"""
list_1: [1, [22, 33, 44], (5, 6, 7), {\'name\': \'Sarah\'}]
list_2: [1, [22, 33, 44], (5, 6, 7, 8, 9), {\'name\': \'Sarah\'}]
"""
**注意:元组是不可变,一旦有新的元素增加进来就会是新的地址元组**
- 对字典型元素进行操作
list_1[-1]["age"] = 18
print("list_1: ", list_1)
print("list_2: ", list_2)
"""
list_1: [1, [22, 33, 44], (5, 6, 7), {\'name\': \'Sarah\', \'age\': 18}]
list_2: [1, [22, 33, 44], (5, 6, 7), {\'name\': \'Sarah\', \'age\': 18}]
"""
深拷贝
深拷贝是将所有层级的相关元素全部复制,完全分开,避免了上述问题
import copy
list_1 = [1, [22, 33, 44], (5, 6, 7), {"name": "Sarah"}]
# list_2 = list_1.copy() # 或者list_1[:] list(list_1) 均可实现浅拷贝
list_2 = copy.deepcopy(list_1)
list_1[-1]["age"] = 18
list_2[1].append(55)
print("list_1: ", list_1)
print("list_2: ", list_2)
"""
list_1: [1, [22, 33, 44], (5, 6, 7), {\'name\': \'Sarah\', \'age\': 18}]
list_2: [1, [22, 33, 44, 55], (5, 6, 7), {\'name\': \'Sarah\'}]
"""
1.2 字典
字典的查找速度非常的快
1.2.1 字典的底层实现
通过稀疏数组来实现值的存储与访问
字典的创建过程:
- ① 创建一个散列表(稀疏数组 N >> n)
- ② 通过hash()计算键的散列值
- ③ 根据计算的散列值确定其在散列表中位置,在该位置上存入值。极个别时候,散列值会发生冲突,则内部有相应的解决冲突的办法
键值对的访问过程: - ① 计算要访问的键的散列值
- ② 根据计算的散列值,通过一定规则,确定其在散列表中的位置
- ③ 读取该位置上存储的值,如果存在,则返回该值,如果不存在,则报错KeyError
小结: - ① 字典数据类型,通过空间换时间,实现了快速的数据查找,也就注定了字典的空间利用率低下
- ② 因为散列值对应位置的顺序与键在字典中显示的顺序可能不同,因此表现出来字典是无序的
1.3 紧凑的字符串
通过紧凑数组实现字符串的存储:数据在内存中是连续存放的,效率更高,节省空间。
1.4 是否可变
不可变类型:数字、字符串、元组。
在生命周期中保持不变:
- 换句话说,改变了就不是它自己了(id变了)
- 不可变对象的 += 操作 实际上创建了一个新的对象
注意:元组并不是总是不可变的,元组中如果存储了可变元素,则其就是可变的,例如:(1,[2])
可变类型:列表、字典、集合
- id 保持不变,但是里面的内容可以变
- 可变对象的 += 操作 实际在原对象的基础上就地修改
1.5 列表操作的例子
【例1】删除列表内的特定元素
- 法1 存在运算删除法:每次存在运算,都要从头对列表进行遍历、查找、效率低
alist = ["d", "d", "2", "3", "d", "4"]
s = "d"
while True:
if s in alist:
alist.remove(s)
else:
break
print(alist)
"""
[\'2\', \'3\', \'4\']
"""
- 方法2:一次性遍历元素执行删除
alist = ["d", "d", "2", "3", "d", "4"]
s = "d"
for s in alist:
if s === "d":
alist.remove(s) # 删除列表中第一次出现的该元素
print(alist)
"""
[\'2\', \'3\', \'d\', \'4\']
"""
解决方法:使用负向索引
alist = ["d", "d", "2", "3", "d", "4"]
s = "d"
for i in range(-len(alist), 0):
if alist[i] == "d":
alist.remove(alist[i]) # 删除列表中第一次出现的该元素
print(alist)
"""
[\'2\', \'3\', \'4\']
"""
【例2】多维列表的创建
ls = [[0]*10]*5
ls
ls[0][0] = 1
"""
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
[[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
"""
2 更加简洁的语法
2.1 解析语法
解析语法的基本结构——以列表解析为例(也称为列表推导)
[expression for value in iterable if condition]
三要素:表达式、可迭代对象、if条件(可选)
执行过程:
(1) 从可迭代对象中拿出一个元素
(2) 通过if条件(如果有的话),对元素进行筛选,若通过筛选,则把元素传递给表达式,若为通过,则进入下一次迭代
(3) 将传递给表达式的元素,直至迭代元素迭代结束,则返回新创建的列表
等价于如下表达式:
result = []
for value in iterale:
if condition:
result.append(expression)
【例】求20以内奇数的平方
squares = []
for i in range(1, 21):
if i % 2 == 1:
squares.append(i**2)
print(squares)
# 解析语法表达
squares = [i**2 for i in range(1, 21) if i % 2 == 1]
支持多变量
x = [1, 2, 3]
y = [4, 5, 6]
results = [i*j for i, j in zip(x, y)]
print(results)
"""
[4, 10, 18]
"""
支持循环嵌套
colors = [\'black\', \'red\']
sizes = [\'S\', \'M\', \'L\']
tshirts = ["{} {}".format(color, size) for color in colors for size in sizes]
print(tshirts)
"""
[\'black S\', \'black M\', \'black L\', \'red S\', \'red M\', \'red L\']
"""
其他解析语法的例子
- 解析语法构造字典(字典推导)
squares = {i: i**2 for i in range(10)}
for k,v in squares.items():
print(k, " : ", v)
"""
0 : 0
1 : 1
2 : 4
3 : 9
4 : 16
5 : 25
6 : 36
7 : 49
8 : 64
9 : 81
"""
- 解析语法构造集合(集合推导)
squares = {i**2 for i in range(10)}
print(squares)
"""
{0, 1, 64, 4, 36, 9, 16, 49, 81, 25}
"""
- 生成器表达式
squares = (i**2 for i in range(10))
条件表达式
expr1 if condition else expr2
x = n if n>= 0 else -n
三大神器
生成器
生成器采用惰性计算,无需一次性存储海量数据,一边执行一边计算,只计算每次需要的值,实际上一直在执行next()操作,直到无值可取
生成器表达式
海量数据无需存储,无需显示存储的全部数据,节省内存
sum((i for i in range(101))) #0-100的和
生成器函数——yield
在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行
# 求斐波那契数列
def fib(max):
ls = []
n, a, b = 0, 1, 1
while n < max:
ls.append(a)
a, b = b, a+b
a = n + 1
return ls
迭代器
可以被next()函数调用并不断返回下一个值,直至没有数据可取的对象成为迭代器:Iterator
- 可迭代对象:可直接作用与for循环的对象统称为可迭代对象(Iterable)
- 列表、元组、字符串、字典、集合、文件都是可迭代对象
可以使用isinstance()判断一个对象是否是Iterable对象
from collections import Iterable
print(isinstance([1, 2, 3], Iterable)) # True
- (1)生成器是迭代器
生成器不但可以用于for循环,还可以被next()函数调用,直到没有数据可取,抛出StopIteration
from collections import Iterable
squares = (i**2 for i in range(5))
print(isinstance(squares, Iterable))
print(next(squares))
print(next(squares))
print(next(squares))
print(next(squares))
print(next(squares))
print(next(squares))
"""
True
0
1
4
9
16
StopIteration
"""
(2) 列表、元组、字符串、字典、集合不是迭代器,可以通过Iter(Iterable)创建迭代器
print(isinstance(iter([1, 2, 3]), Iterator))
for item in iterable 等价于:①先通过iter()函数获取可迭代对象Iterable的迭代器②然后对获取到的迭代器不断调用next()方法来获取下一个值并将其赋值给item③当遇到StopIteration的异常后循环结束
(3) zip enumerate等itertool里的函数是迭代器
from collections import Iterable,Iterator
x = [1, 2]
y = ["a", "b"]
for i in zip(x, y):
print(i)
print(isinstance(zip(x, y), Iterator))
numbers = [1, 2, 3, 4]
print(enumerate(numbers))
print(isinstance(enumerate(numbers), Iterator))
"""
(1, \'a\')
(2, \'b\')
True
<enumerate object at 0x7f017c6f12d0>
True
"""
(4)文件是迭代器
(5)迭代器是可耗尽的
(6)range()不是迭代器,可以将range()称为懒序列,单并不包含任何内存中的内容,而是通过计算来回答问题
装饰器
函数对象
函数对象是Python中的第一类对象,可以将函数赋值给变量;对该变量进行调用,可实现原函数的功能,可以将函数作为参数进行传递
def square(x):
return x**2
print(type(square)) # square是function类的一个实例
pow_2 = square # 可理解为给这个函数起了一个别名
print(pow_2(4)) # 16
高阶函数
高阶函数满足以下条件之一的函数称之为高阶函数:
- 接受函数作为参数
- 或者返回一个函数
def square(x):
return x**2
def pow_2(fun):
return fun
f = pow_2(square)
f(8)
嵌套函数
在函数内部定义一个函数,就是嵌套函数
def outer():
print("outer is running")
def inner():
print("inner is running")
inner()
outer()
闭包
闭包延伸了作用域的函数。如果一个函数定义在另一个函数的作用域内,并且引用了外层函数的变量,则该函数称为闭包。
闭包是由函数及其相关的引用环境组合而成的实体(即:闭包=函数+引用环境)
def outer():
x = 1
z = 10
def inner():
y = x+100
return y, z
return inner()
f = outer() # f实际上包含了inner函数本身outer函数的环境
print(f)
一旦在内层函数重新定义了相同名字的变量,则变量成为局部变量。
nonlocal允许内嵌的函数来修改闭包变量
def outer():
x = 1
def inner():
# nonlocal x
x = x+100 # x在内部函数中重新定义成为局部变量,找不到x,报错
return x
return inner()
一个简单的装饰器
嵌套函数实现
import time
def timer(func):
def inner():
print("inner run")
start = time.time()
func()
end = time.time()
print("{} 函数运行用时{:.2f}秒".format(func.__name__, (end-start)))
return inner()
def f1():
print("f1 run")
time.sleep(1)
f1 = timer(f1)
f1()
"""
inner run
f1 run
f1 函数运行用时1.00秒
"""
语法糖
import time
def timer(func):
def inner():
print("inner run")
start = time.time()
func()
end = time.time()
print("{} 函数运行用时{:.2f}秒".format(func.__name__, (end-start)))
return inner()
@timer # f1 = timer(f1) # 包含inner()和timer()的环境,如传递过来的参数func
def f1():
print("f1 run")
time.sleep(1)
f1()
装饰有参函数和被装饰函数有返回值的情况
import time
def timer(func):
def inner(*argc, **kwargs):
print("inner run")
start = time.time()
res = func(*argc, **kwargs)
end = time.time()
print("{} 函数运行用时{:.2f}秒".format(func.__name__, (end-start)))
return res
return inner()
@timer # f1 = timer(f1) # 包含inner()和timer()的环境,如传递过来的参数func
def f1(n):
print("f1 run")
time.sleep(n)
return "wake up"
res = f1(2)
print(res)
带参数的装饰器
- 需求:有时需要统计绝对时间,有时需要统计绝对时间的2倍
import time
def timer(method):
def outer(func):
def inner(*argc, **kwargs):
print("inner run")
if method == "origin":
print("origin_inner run")
start = time.time()
res = func(*argc, **kwargs)
end = time.time()
print("{} 函数运行用时{:.2f}秒".format(func.__name__, (end - start)))
elif method == "double":
print("double_inner run")
start = time.time()
res = func(*argc, **kwargs)
end = time.time()
print("{} 函数运行用时{:.2f}秒".format(func.__name__, (end - start)))
return res
return inner()
@timer(method="origin") # f1 = timer(f1) # 包含inner()和timer()的环境,如传递过来的参数func
def f1(n):
print("f1 run")
time.sleep(n)
return "wake up"
@timer(method="double")
def f2(n):
print("f2 run")
time.sleep(n)
return "wake up"
res = f1(2)
print(res)
装饰器一装饰就执行,不必等调用
原函数的属性会被掩盖掉
import time
def timer(func):
def inner():
print("inner")
start = time.time()
end = time.time()
print("{} 函数运行用时{:.2f}秒".format(func.__name__, (end - start)))
return inner
@timer #f1 = timer(f1)
def f1():
time.sleep(1)
print("f1 run")
print(f1.__name__) #inner
@wraps使得被装饰的函数依然有原来的属性
import time
from functools import wraps
def timer(func):
@wraps(func)
def inner():
print("inner")
start = time.time()
end = time.time()
print("{} 函数运行用时{:.2f}秒".format(func.__name__, (end - start)))
return inner
@timer #f1 = timer(f1)
def f1():
time.sleep(1)
print("f1 run")
print(f1.__name__) #f1