python爬取百度百科(根据爬取的热词自动匹配相应解释)且将数据存入数据库中
Posted 吴林祥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬取百度百科(根据爬取的热词自动匹配相应解释)且将数据存入数据库中相关的知识,希望对你有一定的参考价值。
import requests
from lxml import etree
import time, json, requests
import pymysql
header = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36\',
\'cookie\': \'BAIDUID=AB4524A16BFAFC491C2D9D7D4CAE56D0:FG=1; BIDUPSID=AB4524A16BFAFC491C2D9D7D4CAE56D0; PSTM=1563684388; MCITY=-253%3A; BDUSS=jZnQkVhbnBIZkNuZXdYd21jMG9VcjdoanlRfmFaTjJ-T1lKVTVYREkxVWp2V2RlSVFBQUFBJCQAAAAAAAAAAAEAAACTSbM~Z3JlYXTL3tGpwOTS9AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACMwQF4jMEBed; pcrightad9384=showed; H_PS_PSSID=1454_21120; delPer=0; PSINO=3; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; __yjsv5_shitong=1.0_7_a3331e3bd00d7cbd253c9e353f581eb2494f_300_1581332649909_58.243.250.219_d03e4deb; yjs_js_security_passport=069e28a2b81f7392e2f39969d08f61c07150cc18_1581332656_js; Hm_lvt_55b574651fcae74b0a9f1cf9c8d7c93a=1580800784,1581160267,1581268654,1581333414; BK_SEARCHLOG=%7B%22key%22%3A%5B%22%E7%96%AB%E6%83%85%22%2C%22%E6%95%B0%E6%8D%AE%22%2C%22%E9%9D%9E%E6%AD%A3%E5%BC%8F%E6%B2%9F%E9%80%9A%22%2C%22mapper%22%5D%7D; Hm_lpvt_55b574651fcae74b0a9f1cf9c8d7c93a=1581334123\'
}
lis=[]
f = open("output.txt", "r", encoding=\'utf-8\', errors=\'ignore\')
for line in f:
info = {}
line1 = line.split(\' \')[0]
url = "https://baike.baidu.com/item/" + str(line1)
info[\'name\']=line1
info[\'pinlv\']=line.split(\' \')[1]
r = requests.get(url, headers=header)
html = r.content.decode("utf-8")
html1 = etree.HTML(html)
content1 = html1.xpath(\'//div[@class="lemma-summary"]\')
if len(content1) == 0:
content1 = \'无解释\'
info[\'content\'] = content1
else:
content2 = content1[0].xpath(\'string(.)\').replace(\' \', \'\').replace(\'\\n\', \'\')
info[\'content\'] = content2
info[\'url\'] = url
lis.append(info)
print(lis[0])
print(len(lis))
db = pymysql.connect(host=\'127.0.0.1\', port=3306, user=\'root\', password=\'root\', db=\'reci\')
cursor = db.cursor()
for i in range(len(lis)):
cols = ", ".join(\'`{}`\'.format(k) for k in lis[i].keys())
print(cols) # \'`name`, `age`\'
val_cols = \', \'.join(\'%({})s\'.format(k) for k in lis[i].keys())
print(val_cols) # \'%(name)s, %(age)s\'
sql = "insert into recifenxi(%s) values(%s)"
res_sql = sql % (cols, val_cols)
print(res_sql) # \'insert into users(`name`, `age`) values(%(name)s, %(age)s)\'
cursor.execute(res_sql, lis[i]) # 将字典a传入
db.commit()
结果
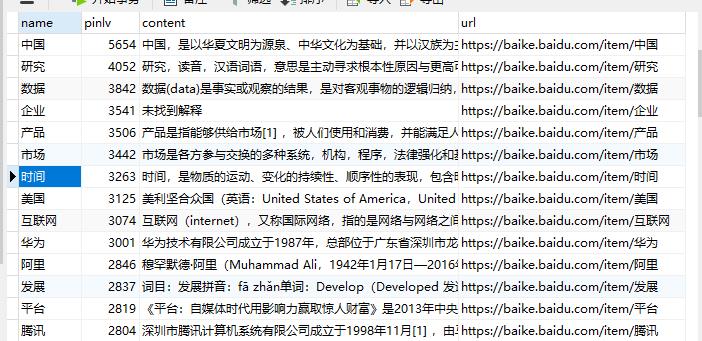
以上是关于python爬取百度百科(根据爬取的热词自动匹配相应解释)且将数据存入数据库中的主要内容,如果未能解决你的问题,请参考以下文章