运用Python模块和包
Posted 躬耕南阳
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了运用Python模块和包相关的知识,希望对你有一定的参考价值。
1 引言
为了能够在Python项目中高效地运用Python模块和包,我们需要进一步地来了解它们是如何在Python项目中进行定义、使用和工作的。
2 Python模块和包
Python模块和包的基本使用方法前面已经有所提及,现在小结如下:
1. 首先导入Python模块,然后便可使用该模块中定义的函数、类、变量及其它定义量。具体方法如下所示:
import my_module my_module.do_something() print(my_module.variable)
2. 首先导入包中的模块,然后便可使用模块中定义的函数、类、变量及其它定义量。具体方法如下所示:
import my_package_my_module my_package_my_module.do_something()
当然,也有其它可替代的模块导入方法,并能够让代码看起来更简洁,具体方法如下:
from my_package import my_module my_module.do_something()
Python模块的导入方法是多种多样的,我们会在后续介绍更多的模块导入方法以便在不同场合中选择使用。
3 嵌套包
就像文件夹里能继续包含文件夹一样,Python包里面也能继续创建Python包。
例如,在名为my_package的包里面含有另一个名为my_sub_package包,结构如下图所示:
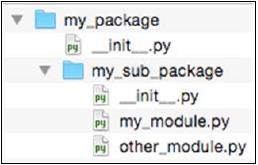
按照这个逻辑,你可以在包里面嵌套无数层包,这在Python语法中是允许的。但从现实层面上考虑,嵌套过多层级的包并不是一个十分友好的做法。
同时也不可否认的是,各级包的树形结构嵌套大大有利于我们组织大型复杂的项目,清晰的展示项目各部分间的逻辑结构,如下图所示:

4 模块的初始化
我们知道当模块被导入后,包含其中的所有定义内容即可被用户调用。这是因为,Python在调入模块的同时该模块中的所有代码将被编译运行。
用一个例子来详细说明其工作原理,创建一个名为test的模块并敲入如下代码:
def ta(): print("test a") def tb(): print("test b") my_var = 0 print("importing test module")
打开Python终端解释器并导入test模块,可见命令行将显示importing test module,这就证明Python在导入模块的同时对包含在模块中的所有代码进行了编译运行。
基于Python这个特点,我们可以通过把模块的初始化代码直接放在模块里面。这样,模块在被导入的同时可自动完成对模块的初始化操作。
值得注意的是,当有多个模块都需要导入同一个模块时,实际上只要有一个模块执行导入操作后,剩余模块即可使用该模块中所定义内容。
其原理同样是基于Python上述特点,这也使得在上述情况中无需多次导入相同模块,以简化代码。
5 初始化函数
前面提到的初始化方法一般为隐式初始化(implicit initialization),特点是将初始化代码分布于模块之中。
相对应地,把初始化代码全部封装在一个初始化函数init()中的方法,称为显式初始化(explicit initialization)。
隐式初始化不能够清晰的表达出该模块是否已经经过初始化以及初始化的具体内容,而显式初始化则恰能避免这个缺点。
因此,在Python编程中鼓励用户优先使用显式初始化方法,以提高代码的可读性。
举例作详细说明,在前面定义的test模块中,我们可将初始化内容my_var=0的声明封装在模块中的初始化函数里,如下所示:
def init(): global my_var my_var = 0
虽然这看起来有些冗余,但是这样能够显式地进行初始化,当然,这也就要求你在使用模块前需要在主项目中调用test.init()以完成初始化操作。
此外,显式初始化方法还能够控制多个模块的初始化顺序,以避免可能存在的冲突及实现特定的初始化顺序要求。
6 包的初始化
我们知道包的初始化是通过将初始化代码封装在包中的一个专门_init_.py源文件中,如下图所示:

Python导入包或包中的某一个模块的同时,该源文件中的初始化代码将被编译运行。
你或许会疑问,包中需要初始化的模块已经在模块内部实现了,为何还要对包进行初始化操作呢?
答案是包的初始化文件_init_.py在包一级即可被用户直接访问,例如你在_init_.py文件中定义了如下代码:
def say_hello(): print("hello")
那么,你可以在主项目中直接通过下面所示方法调用该函数:
import my_packgae my_package.say_hello()
不像把该函数定义在模块中,需要在模块一级才能调用该函数,大大方便了用户。但是,从Python编程习惯而言,把代码添加到包初始化文件中来实现并不是一个好的做法。
因为当用户浏览你的源代码时希望你把代码放在各个功能模块中,方便用户的阅读。同时,包的初始化文件只有一个,当你把大量代码都添加进该文件后,将使得代码的组织变得十分困难。
对此,有一个解决的方法,即把定义的代码放进包中的模块里,然后在初始化文件中再导入这些代码,如下所示:
from test_package.test_module import say_hello
这样既满足了将代码实现放在模块中,又能在包一级直接调用该函数。这是一个非常有用的技巧,特别是当你的包很复杂时,这可以让你更方便地获取你定义的函数、类等。
这些import导入声明也能够让用户知晓你的包需要用到哪些定义的函数和类,某种程度上相当于一个函数、类的引用索引和清单。
综上所述,当你需要在初始化文件中放代码时,最好是将源代码放在包中模块里,然后在初始化文件中用导入代码的方式来实现。
7 import导入原理及方式
7.1 import导入原理
当我们在Python中创建全局变量或函数时,Python解释器会将变量或函数的名称添加到所谓的命名空间中。
例如,当你在命令行输入print("globals()")后,终端将会以字典的形式显示当前定义的所有全局变量和函数的名称。
实际上,在Python中运用import即是将相应的模块或者模块中的函数添加到命名空间中以便用户能够使用。
7.2 import导入方式
目前为止,我们介绍了以下两种import使用方法:
- import <something>
- from <somewhere> import <something>
第一种import方法不会对一次导入的模块数量有所限制,Python允许你通过此种方法一次导入多个模块,如下所示:
import string, datetime, random, math
同样地,你也可以从包或模块中一次导入多个模块或函数,如下所示:
from math import pi, radians, sin
当导入模块或函数的数量较大需要换行时,可进行如下操作:
from math pi, radians, sin, cos, \\ tan, hypot, asin, acos, atan, atan2
或者通过如下操作:
from math import (pi, radians, sin, cos, tan, hypot, asin, acos, atan, atan2)
导入模块或函数的同时也可以更改模块或函数的名称,如下所示:
import math as math_ops
这时模块math将以math_ops作为自己的名称被添加到全局命名空间中并被用户调用。
导入模块或函数同时更改模块或函数的名称有如下好处:
- 冗长的模块或函数名称得到简化;
- 避免命名冲突,如下所示。
from package1 import utils as utils1 from package2 import utils as utils2
当然,第二种导入方法也可更改模块或函数名称,如下所示:
from reports import customers as customer_report from database import customers as customer_data
最后,使用通配符导入可以将模块或包中的定义内容一次性全部导入, 如下所示:
from math import *
这将会把math模块中的全部定义内容都添加到全局命名空间中,如果你导入的是一个包,此操作会将包中_init_.py文件中全部定义内容都导入。
默认条件下,模块或包中没有以下划线开头的都能够被通配符导入方法导入进来,此规定将保证私有变量不会被导入进来。
在导入复杂树形结构的包时,前面介绍的导入方法将变得不易使用。这里介绍另一种导入方法---相对导入法(relative import),
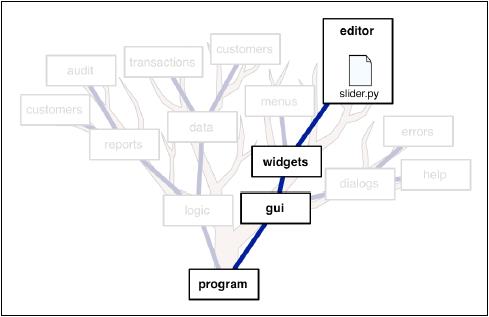
例如我们需要导入上图中slider.py时,用之前介绍的方法如下所示:
from program.gui.widgets.editor import slider
这虽然能够正确的导入slider,但是调入过程十分繁杂。于是,相对导入法便派上了用场。
当一个模块需要导入位于同一包中的另一个模块时,如下图中utils需要导入slider,可用如下所示语句实现:
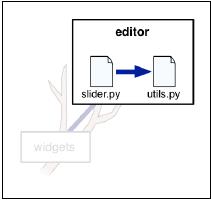
from . import slider
符号"."表示utils模块所在包位置,并用此符号代替包的名称。
类似地,如下图中位于widgets中的controls模块需要导入位于其子包中的slider模块时,可用如下方法:
from .editor import slider
上面语句告知Python在当前位置寻找一个名为editor的包,并从此包中导入名为slider的模块。
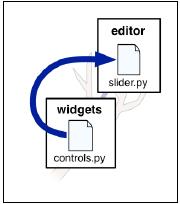
相反地,若如下图所示位于子包editor中的slider模块需要导入位于widgets包中的controls模块,则实现语句如下:

from .. import controls
一个“.”符号代表当前位置,两个“..”符号代表从当前位置向上升一级包,即当前包的父包。
以此类推,你可以用三个“...”符号实现从当前位置向上升两级包,即当前包的父包的父包……
当然,你也可以将上述方法进行组合使用以实现访问不同层级的包,如下例所示:
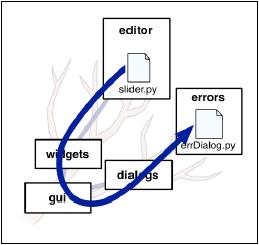
from ...dialogs.errors import errDialog
运用相对导入法(relative import)的好处有如下:
- 简化导入声明(import statement)并提高其可读性;
- 当别人在你写的包中互相引用各模块时,无需知晓包的位置即可实现对模块的引用。
7.3 自定义导入内容
前面提到在默认条件下,模块或包中以下划线开头的将不会被通配符导入方法导入进来,这就使得私有变量不会被导入进来。
那么,当你想更改这一规定以能够不加限制的导入任何变量,又如何做呢?
引入一个名为_all_.的Python专有变量,下面介绍此变量的工作原理:
A = 1 B = 2 C = 3 _all_ = ["A", "B"]
当导入这个模块后,你会发现仅有变量A和B被导入,尽管模块中还定义有变量C,而变量C被忽略则是因为它未被包含进_all_ 列表里面。
类似地,当导入包时,可以在包中_init_.py文件里的_all_ 列表包含需要导入的模块和子包名称,如下所示:
_all_ = ["module1", "module2", "sub-package"]
这时,当你导入此包后,你会发现只有模块module1和module2以及子包sub-package被自动导入。
当你在没有自定义_all_变量情况下,你可以通过查看此变量列表中包含的元素来了解导入模块或包中哪些部分代码是可以被外部使用的。
7.4 循环依赖
当你处理多个模块时,你可能会面临如下所示情形,常称为循环依赖(CIrcular Dependencies)。
# module_1.py from module_2 import fun2 def funl(items): ... ... # module_2.py from module_1 import fun1 def fun2(items): ... ...
上面示例表明,模块1与模块2相互导入了有关定义内容,如果你尝试运行同时包含有这两个模块的项目时,你会发现无论是在模块1被导入还是在模块2被导入时,都会出现下面错误提示:
ImportError: cannot import name fun1(fun2)
循环依赖现象意味着你的代码设计出现了问题,必须重新构建代码模块结构,以避免此现象的出现,如新创建第三个模块等。
7.5 命令行中运行模块
前面提到,在Python主项目中通常有如下所示结构:
def main(): ... if _name_ == "_main_": main()
当用户运行项目时,Python解释器便会自动将全局变量_name_的值设为"_main_",故在此结构下,运行项目即会执行main()函数。
下面一个例子来说明其工作原理,定义一个模块test,如下所示:
def double(n): return n * 2 if __name__ == "__main__": print("double(3) = ", double(3))
当你运行test模块后,你会发现解释器会显示double(3)=6,即验证了上述工作原理的正确性。
此外,用户还可利用此特点直接在命令行中调用以实现模块的某些定义功能,例如定义一个名为funkycase.py的模块,并敲入如下代码:
def funky_case(s): letters = [] capitalize = False for letter in s: if capitalize: letters.append(letter.upper()) else: letters.append(letter.lower()) capitalize = not capitalize return "".join(letters)
上面定义代码实现将字符串中第2、4.……位字符大写的功能,按前面所述方法,可以对此模块进行调用测试。不过,这里我们介绍一些新的内容。
首先,在上面定义的模块中添加如下代码:
import sys
...
if __name__ == "__main__": if len(sys.argv) != 2: print("You must supply exactly one string!") else: s = sys.argv[1] print(funky_case(s))
这里,需要简要介绍一下上面代码中的sys.argv[ ],它是一个系统内部定义的列表,第一个元素即sys.argv[0]存储的是代码本身的内容,从其列表第二个元素开始存储的是外部用户输入的参数。
故上面代码实现了获取外部用户输入参数并调用定义函数funky_case()的功能。这二者的结合,不仅使定义的模块如之前所述能够被其他模块和主项目所调用,而且还能够被用户在命令行中作为独立的项目调用运行。
不过这里要注意一点,当你创建一个模块并如上述一样需要在命令行中调用时,如果你在模块里面使用了相对导入方法,则会出现attempted relative import of non-package error的错误。
原因是当模块在命令行中被调用时,模块并不知道自己所在包的所在位置。但是如果你只需要在命令行中运行,并没有参数输入,则可通过如下所示命令来避免这个错误:
python -m funkycase.py
当你有参数需要输入时,你就必须选用其他导入方法替代模块中的相对导入法以避免上述错误的出现。
8 小结
未完待续……
本文章属于原创作品,欢迎大家转载分享,禁止修改文章的内容。尊重原创,转载请注明来自:躬耕南阳 https://www.cnblogs.com/yangmi511/
以上是关于运用Python模块和包的主要内容,如果未能解决你的问题,请参考以下文章