从问题说开去
接口又返回了乱码咋办呢?
看现象, 查原因
$: curl http://127.0.0.1:8000
{"code": "00", "message": "\\u6570\\u636e\\u7c7b\\u578b\\u9519\\u8bef", "data": {}}
- 贴到浏览器窗口看

- ipython打开贴上去看
In [3]: {"code": "00", "message": "\\u6570\\u636e\\u7c7b\\u578b\\u9519\\u8bef", "data"
...: : {}}
Out[3]: {\'code\': \'00\', \'message\': \'数据类型错误\', \'data\': {}}
说明浏览器和ipython都可以解码


后端怎么给前端准备数据的?
//正常 后端json.dumps返回数据, 设置response的请求头application/json
data = {
"code": "00",
"message": "数据类型错误",
"data": {},
}
josn.dumps(data) # 这种即会造成上面出现的乱码现象.
//后端修复:
josn.dumps(data, ensure_ascii=false)
If ``ensure_ascii`` is false, then the return value can contain non-ASCII
characters if they appear in strings contained in ``obj``. Otherwise, all
such characters are escaped in JSON strings.
因为data中有非ascii,所以确定都是ascii项为false
为什么会乱码?
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。
因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
前端返得到那些乱码是什么
\\u#### 表示一个Unicode编码的字符, 6570为unicode码点
"\\u6570"
python3中b\'\\xe4\\xb8\\xad\\xe6\\x96\\x87\' 又是什么东西
b\'\\xe4\\xb8\\xad\\xe6\\x96\\x87\' # 带b的表示bytes类型数据
bytes是一种比特流,它的存在形式是01010001110这种.
如上表示,\\x表示转义, 用十六进制展示.
str使用utf8编码成下面的了
>>> s = "中文"
>>> s
\'中文\'
>>> type(s)
<class \'str\'>
>>> b = bytes(s, encoding=\'utf-8\')
>>> b
b\'\\xe4\\xb8\\xad\\xe6\\x96\\x87\' #\\x 代表是十六进制
>>> type(b)
<class \'bytes\'>
str使用unicode编码成下面的了
In [15]: bytes(s, encoding=\'unicode_escape\')
Out[15]: b\'\\\\u4e2d\\\\u6587\'
关于unicode如何映射到utf8编码的转换规则, 可以看上面链接.
python3 str和bytes转换
# py3默认用utf8, 解决py2默认用ascii对中文不友好的坑.
>>> import sys
>>> sys.getdefaultencoding()
\'utf-8\'
>>>
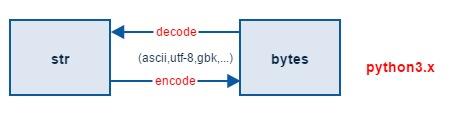
encode 负责字符到字节的编码转换。默认使用 UTF-8 编码准换。
In [16]: s = "毛台"
In [17]: s.encode()
Out[17]: b\'\\xe6\\xaf\\x9b\\xe5\\x8f\\xb0\'
In [19]: s.encode("gbk")
Out[19]: b\'\\xc3\\xab\\xcc\\xa8\'
decode 负责字节到字符的解码转换,通用使用 UTF-8 编码格式进行转换。
In [21]: b\'\\xe6\\xaf\\x9b\\xe5\\x8f\\xb0\'.decode()
Out[21]: \'毛台\'
n [22]: b\'\\xc3\\xab\\xcc\\xa8\'.decode("gbk")
Out[22]: \'毛台\'
获取字符的unicode编码: ord(),和chr()
In [12]: chr(0x4e25)
Out[12]: \'严\'
In [13]: ord(\'严\')
Out[13]: 20005