Python3+SQLAlchemy+Sqlite3实现ORM教程
Posted lewo的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3+SQLAlchemy+Sqlite3实现ORM教程相关的知识,希望对你有一定的参考价值。
一、安装
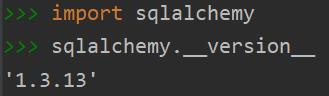
Sqlite3是Python3标准库不需要另外安装,只需要安装SQLAlchemy即可。本文sqlalchemy版本为1.3.13
pip install sqlalchemy
二、ORM操作
除了第一步创建引擎时连接URL不一样,其他操作其他mysql等数据库和sqlite都是差不多的。
2.1 创建数据库连接格式说明
sqlite创建数据库连接就是创建数据库,而其他mysql等应该是需要数据库已存在才能创建数据库连接;建立数据库连接本文中有时会称为建立数据库引擎。
2.1.1 sqlite创建数据库连接
以相对路径形式,在当前目录下创建数据库格式如下:
# sqlite://<nohostname>/<path> # where <path> is relative: engine = create_engine(\'sqlite:///foo.db\')
以绝对路径形式创建数据库,格式如下:
#Unix/Mac - 4 initial slashes in total engine = create_engine(\'sqlite:////absolute/path/to/foo.db\') #Windows engine = create_engine(\'sqlite:///C:\\\\path\\\\to\\\\foo.db\') #Windows alternative using raw string engine = create_engine(r\'sqlite:///C:\\path\\to\\foo.db\')
sqlite可以创建内存数据库(其他数据库不可以),格式如下:
# format 1 engine = create_engine(\'sqlite://\') # format 2 engine = create_engine(\'sqlite:///:memory:\', echo=True)
2.1.2 其他数据库创建数据库连接
PostgreSQL:
# default engine = create_engine(\'postgresql://scott:tiger@localhost/mydatabase\') # psycopg2 engine = create_engine(\'postgresql+psycopg2://scott:tiger@localhost/mydatabase\') # pg8000 engine = create_engine(\'postgresql+pg8000://scott:tiger@localhost/mydatabase\')
MySQL:
# default engine = create_engine(\'mysql://scott:tiger@localhost/foo\') # mysql-python engine = create_engine(\'mysql+mysqldb://scott:tiger@localhost/foo\') # MySQL-connector-python engine = create_engine(\'mysql+mysqlconnector://scott:tiger@localhost/foo\') # OurSQL engine = create_engine(\'mysql+oursql://scott:tiger@localhost/foo\')
Oracle:
engine = create_engine(\'oracle://scott:tiger@127.0.0.1:1521/sidname\') engine = create_engine(\'oracle+cx_oracle://scott:tiger@tnsname\')
MSSQL:
# pyodbc engine = create_engine(\'mssql+pyodbc://scott:tiger@mydsn\') # pymssql engine = create_engine(\'mssql+pymssql://scott:tiger@hostname:port/dbname\')
2.2 创建数据库连接
我们以在当前目录下创建foo.db为例,后续各步同使用此数据库。
在create_engine中我们多加了两样东西,一个是echo=Ture,一个是check_same_thread=False。
echo=Ture----echo默认为False,表示不打印执行的SQL语句等较详细的执行信息,改为Ture表示让其打印。
check_same_thread=False----sqlite默认建立的对象只能让建立该对象的线程使用,而sqlalchemy是多线程的所以我们需要指定check_same_thread=False来让建立的对象任意线程都可使用。否则不时就会报错:
sqlalchemy.exc.ProgrammingError: (sqlite3.ProgrammingError) SQLite objects created in a thread can only be used in that same thread. The object was created in thread id 35608 and this is thread id 34024. [SQL: \'SELECT users.id AS users_id, users.name AS users_name, users.fullname AS users_fullname, users.password AS users_password \\nFROM users \\nWHERE users.name = ?\\n LIMIT ? OFFSET ?\'] [parameters: [{}]] (Background on this error at: http://sqlalche.me/e/f405)
示例:
import sqlalchemy
sqlalchemy.create_engine("sqlite:///test.db?check_same_thread=False", echo=True)
2.3 定义映射
先建立基本映射类,后边真正的映射类都要继承它
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()
然后创建真正的映射类,我们这里以一下User映射类为例,我们设置它映射到users表。ORM中表是不需要先存在的,反而是后续要通过映射类来创建表,这一点是需要明确的。
from sqlalchemy import Column, Integer, String # 定义映射类User,其继承上一步创建的Base class User(Base): # 指定本类映射到users表 __tablename__ = \'users\' # 指定id映射到id字段; id字段为整型,为主键 id = Column(Integer, primary_key=True) # 指定name映射到name字段; name字段为字符串类形, name = Column(String(20)) fullname = Column(String(32)) password = Column(String(32)) # object 基类也存在该方法,这里重写该方法 # _repr_方法默认返回该对象实现类的“类名+object at +内存地址”值 def __repr__(self): return "<User(name=\'%s\', fullname=\'%s\', password=\'%s\')>" % ( self.name, self.fullname, self.password)
2.4 创建数据表
# 查看映射对应的表 User.__table__ # 创建数据表 Base.metadata.create_all(engine)
创建打印的语句, 跟echo=True有关系:
student 2020-02-23 16:54:47,279 INFO sqlalchemy.engine.base.Engine SELECT CAST(\'test plain returns\' AS VARCHAR(60)) AS anon_1 2020-02-23 16:54:47,279 INFO sqlalchemy.engine.base.Engine () 2020-02-23 16:54:47,279 INFO sqlalchemy.engine.base.Engine SELECT CAST(\'test unicode returns\' AS VARCHAR(60)) AS anon_1 2020-02-23 16:54:47,279 INFO sqlalchemy.engine.base.Engine () 2020-02-23 16:54:47,281 INFO sqlalchemy.engine.base.Engine PRAGMA main.table_info("student") 2020-02-23 16:54:47,281 INFO sqlalchemy.engine.base.Engine () 2020-02-23 16:54:47,281 INFO sqlalchemy.engine.base.Engine PRAGMA temp.table_info("student") 2020-02-23 16:54:47,281 INFO sqlalchemy.engine.base.Engine () 2020-02-23 16:54:47,281 INFO sqlalchemy.engine.base.Engine CREATE TABLE student ( id INTEGER NOT NULL, name VARCHAR(20), PRIMARY KEY (id) ) 2020-02-23 16:54:47,281 INFO sqlalchemy.engine.base.Engine () 2020-02-23 16:54:47,293 INFO sqlalchemy.engine.base.Engine COMMIT Process finished with exit code 0
2.5 建立会话
增查改删(CRUD)操作需要使用session进行操作
from sqlalchemy.orm import sessionmaker # engine是2.2中创建的连接 Session = sessionmaker(bind=engine) # 创建Session类实例 session = Session()
2.6 增(向users表中插入记录)
# 创建User类实例 ed_user = User(name=\'ed\', fullname=\'Ed Jones\', password=\'edspassword\') # 将该实例插入到users表 session.add(ed_user) # 一次插入多条记录形式 session.add_all( [User(name=\'wendy\', fullname=\'Wendy Williams\', password=\'foobar\'), User(name=\'mary\', fullname=\'Mary Contrary\', password=\'xxg527\'), User(name=\'fred\', fullname=\'Fred Flinstone\', password=\'blah\')] ) # 当前更改只是在session中,需要使用commit确认更改才会写入数据库 session.commit()
2.7 查(查询users表中的记录)
2.7.1 查实现
query相当前select xxx from xxx部分。
filter_by相当于where部分,外另可用filter。他们的区别是filter_by参数为sql形式,filter参数为python形式。
# 指定User类查询users表,查找name为\'ed\'的第一条数据 our_user = session.query(User).filter_by(name=\'ed\').first() print(our_user) # 比较ed_user与查询到的our_user是否为同一条记录 print(ed_user is our_user)
更多查询语句见:https://docs.sqlalchemy.org/en/latest/orm/tutorial.html#querying
不过要注意该链接Common Filter Operators节中形如equals的query.filter(User.name == \'ed\'),在真正使用时都得改成session.query(User).filter(User.name == \'ed\')形式,不然只后看到报错“NameError: name \'query\' is not defined”。
2.7.2 参数传递问题
我们上边的sql直接是our_user = session.query(User).filter_by(name=\'ed\').first()形式,但到实际中时User部分和name=‘ed’这部分是通过参数传过来的,使用参数传递时就要注意以下两个问题。
首先,是参数不要使用引号括起来。比如如下形式是错误的(使用引号),将报错sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) no such column
table_and_column_name = "User" filter = "name=\'ed\'" our_user = session.query(table_and_column_name).filter_by(filter).first()
其次,对于有等号参数需要变换形式。如下去掉了引号,对table_and_column_name没问题,但filter = (name=\'ed\')这种写法在python是不允许的
table_and_column_name = User # 下面这条语句不符合语法 filter = (name=\'ed\') our_user = session.query(table_and_column_name).filter_by(filter).first()
对参数中带等号的这种形式,现在能想到的只有使用filter代替filter_by,即将sql语句中的=号转变为python语句中的==。正确写法如下:
table_and_column_name = User filter = (User.name==\'ed\') our_user = session.query(table_and_column_name).filter(filter).first()
2.8 改(修改users表中的记录)
# 要修改需要先将记录查出来 mod_user = session.query(User).filter_by(name=\'ed\').first() # 将ed用户的密码修改为modify_paswd mod_user.password = \'modify_passwd\' # 确认修改 session.commit()
2.9 删(删除users表中的记录)
# 要删除需要先将记录查出来 del_user = session.query(User).filter_by(name=\'ed\').first() # 打印一下,确认未删除前记录存在 del_user # 将ed用户记录删除 session.delete(del_user) # 确认删除 session.commit() # 遍历查看,已无ed用户记录 for user in session.query(User): print(user)
2.10 直接执行SQL语句
虽然使用框架规定形式可以在一定程度上解决各数据库的SQL差异,比如获取前两条记录各数据库形式如下。
# mssql/access select top 2 * from table_name; # mysql select * from table_name limit 2; # oracle select * from table_name where rownum <= 2;
但框架存消除各数据库SQL差异的同时会引入各框架CRUD的差异,而开发人员往往就有一定的SQL基础,如果一个框架强制用户只能使用其规定的CRUD形式那反而增加用户的学习成本,这个框架注定不能成为成功的框架。直接地执行SQL而不是使用框架设定的CRUD不应当是一种低级的操作应当是一种被鼓厉的标准化行为。
# 正常的SQL语句 sql = "select * from users" # sqlalchemy使用execute方法直接执行SQL records = session.execute(sql)
参考:
以上是关于Python3+SQLAlchemy+Sqlite3实现ORM教程的主要内容,如果未能解决你的问题,请参考以下文章