Python爬虫连载10-Requests模块Proxy代理
Posted 心悦君兮君不知-睿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫连载10-Requests模块Proxy代理相关的知识,希望对你有一定的参考价值。
一、Request模块
1.HTTP for Humans,更简洁更友好
2.继承了urllib所有的特征
3.底层使用的是urllib3
4.开源地址:https://github.com/requests/requests
5.中文文档:https://requests.readthedocs.io/zh_CN/latest/
6.先安装这个包:pip install requests
7.get请求
(1)requests.get()
(2)requests.request("get",url)
(3)可以带有headers和params参数
8.get返回内容
import requests #两种请求 url = "http://www.baidu.com/s?" rsp = requests.get(url) # print(rsp.text) #使用get请求 rsp = requests.request("GET",url) # print(rsp.text) #拿到的结果都是一样的 """ 使用参数headers和params来研究返回结果 """ kw = { "wd":"python中文文档" } headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36" } rsp=requests.get(url,params=kw,headers=headers) print(rsp.text) print("=========================") print(rsp.content) print("=========================") print(rsp.url) print(rsp.encoding) print(rsp.status_code)
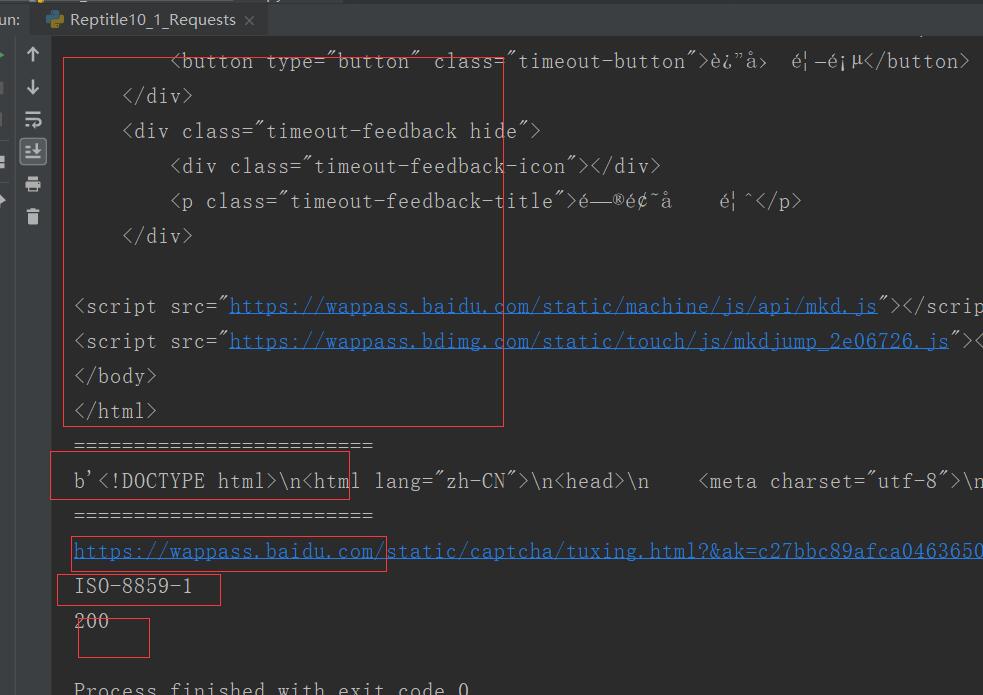
二、post
data,headers要求使用dict
import requests from urllib import parse import json url = "http://www.baidu.com/s?" data = { "kw":"girl" } # data = parse.urlencode(data).encode("utf-8") headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36" } rsp = requests.post(url,data=data,headers=headers) print(rsp.text) # print(rsp.json())
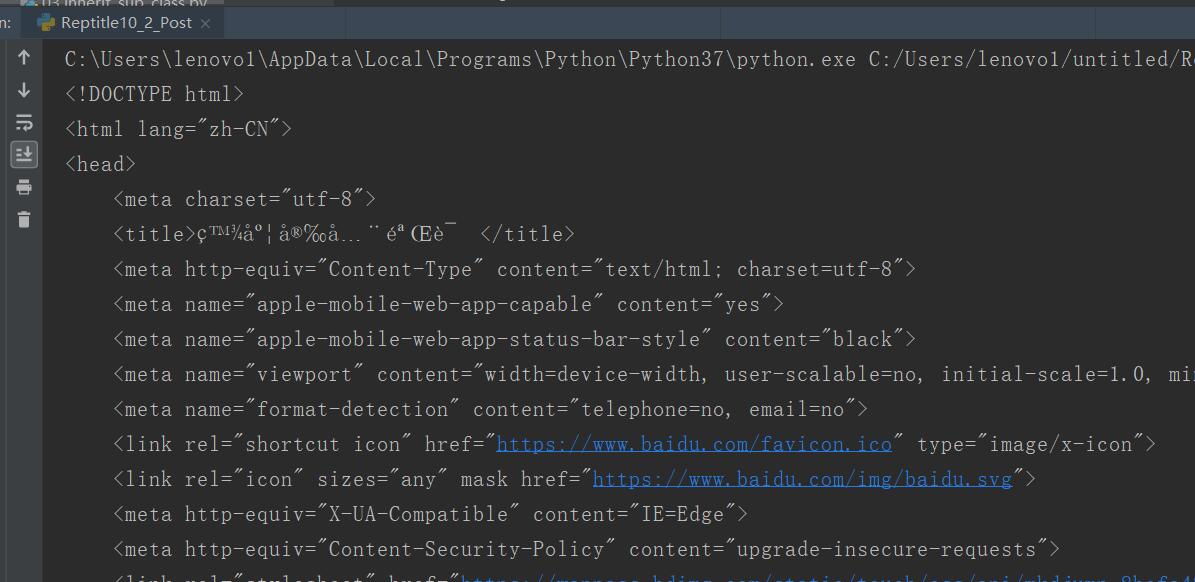
三、proxy代理
1.代理有可能会报错,如果使用人数多,考虑到安全问题,可能会被强行关闭
2.用户验证
(1)代理验证:可能需要HTTP basic Auth
proxy = {"http":"china:123456@192.168.1.123:458"}
#格式为 用户名:密码@代理地址:端口地址
rsp = requests.get("http://baidu.com",proxies=proxy)
(2)web客户端验证
如果遇到web客户端验证,需要添加auth=(用户名,密码)
auth = {"test","123456"}#授权信息
rsp = requests.get("http://www.baidu.com",auth=auth)
四、源码
Reptitle10_1_Requests.py
Reptitle10_2_Post.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptitle10_1_Requests.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptitle10_2_Post.py
2.CSDN:https://blog.csdn.net/weixin_44630050
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料

以上是关于Python爬虫连载10-Requests模块Proxy代理的主要内容,如果未能解决你的问题,请参考以下文章