python第三篇 python基础之函数,递归,内置函数
Posted 445431158yf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python第三篇 python基础之函数,递归,内置函数相关的知识,希望对你有一定的参考价值。
-
一 数学定义的函数与python中的函数
- 1.函数的好处:代码重用,保持一致性,易维护性,可扩展性
- 2.什么是过程?就是没有返回值的函数值,函数返回值:1.若没有返回值,返回None(没有return);2.有返回值时,直接返回值;
-
总结:
返回值数=0:返回None
返回值数=1:返回object
返回值数>1:返回tuple
-
3.1形参和实参
- a.形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元,因此,形参只在函数内部有效,函数调用结束返回主调用函数不能再使用该形参变量
- b.实参可以是常量,变量,表达式,函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传给形参,因此应预先用赋值,输入等方法使参数获得确定的值。
- c.函数只要遇到第一个return就直接返回(函数就结束)
- d.位置参数(标准调用:实参与形参位一一位置对应,缺一不行,多一也不行)
- e.关键字参数(位置无需固定,无需一一对应,缺一不行,多一也不行)
- f.位置参数和关键字参数混合使用,位置参数必须在关键字参数左边,例:1:test(1,2,z=6),例2:test(1,2,z=6,y=4)会报错,一一对应,不能有覆盖值
- g.默认参数,例1:def handle(x,type="my")
- h.动态参数:
动态参数顾名思义就是可以动态的去扩展函数参数的数量!
例子:1 (多个单个变量,整合成元组)
参数组:*列表,**字典 例:def test(x,*args,**kwargs) -
def func(*args):
print args# 执行方式一
func(11,33,4,4454,5)
#输出结果:11,33,4,4454,5# 执行方式二
li = [11,2,2,3,3,4,54]
func(li)
#输出结果:([11,2,2,3,3,4,54])
#如果想输入的列表,不想让列表称谓元组里的仅一个元素而是让列表的元素成为元组的元素加*即可
func(*li)
#输出结果:(11,2,2,3,3,4,54)
#############################################################
1、接受多个参数
2、内部自动构造元组
3、序列,*,避免内部构造元组 - 例子:2(整合为字典变量)
-
def func(**kwargs): print args # 执行方式一 func(name=‘luotianshuai‘,age=18) # 执行方式二 li = {‘name‘:‘luotianshuai‘, age:18, ‘gender‘:‘male‘} func(**li) - 例子:3(整合了*args,**args)
- 二.为何使用函数
-
#发邮件的案例: import smtplib from email.mime.text import MIMEText from email.utils import formataddr def email(message): msg = MIMEText("邮件报警测试", ‘plain‘, ‘utf-8‘) msg[‘From‘] = formataddr(["shuaige",‘shuaige@test.com‘]) #发件人和发件邮箱 msg[‘To‘] = formataddr(["帅哥",‘451161316@qq.com‘]) msg[‘Subject‘] = message #这里我调用了参数 server = smtplib.SMTP("smtp.test.com", 25) server.login("shuaige@126.com", "pwdnq.buzhidao") server.sendmail(‘shuaige@126.com‘, [‘451161316@qq.com‘,], msg.as_string()) server.quit() if __name__ == u‘__main__‘: cpu = 100 disk = 500 ram = 50 for i in range(1): if cpu > 90: alert = u‘CPU出问题了‘ #这里设置了一个变量 email(alert) #这里调用函数的时候引用了上面的变量,当执行函数的时候形参讲会被替换掉,message=‘CPU出问题了‘ 发送邮件! if disk > 90: alert = u‘硬盘出问题了‘ email(alert) if ram> 80: alert = u‘内存出问题了‘ email(alert) -
背景提要
-
三 函数和过程
-
四 函数参数
-
五 局部变量和全局变量
- 1.当全局变量和局部变量同名时,在定义局部变量的子程序内,局部变量起作用,在其他地方全局变量起作用
- 2.能将变量私有化的只有函数
- 3.如果函数的内容无global关键字,优先读取局部变量,能够读取全局变量,无法对全局变量进行重新赋值,但是对于可变类型,可以对内部元素进行操作
- 4.如果函数的内容有global关键字,变量本质上就是全局的那个变量,可读取可赋值
- 函数中无global关键字:1.有声明局部变量,读取局部变量;2.没有声明局部变量,对于可变类型,可以对内部元素进行操作;
- 函数中有global关键字:1.有声明局部变量,其实就是修改了全局的变量;2.没有声明局部变量,就是对全局变量修改和赋值;
- ps:全局变量全部大写,局部变量全部小写
- A.nonlocal 指定上一级变量 B.globals获取所有的全局变量 C.locals 获取所有的局部变量
-
六 前向引用之‘函数即变量‘
- 1.风湿理论:函数即变量,只要定义了,内存中即存在,函数体当做普通字符串存储
-
七 嵌套函数和作用域
- 作用域:与调用方式无关,执行只与定义有关(作用域在定义函数时就已经固定住了,不会随着调用位置的改变而改变)
-
八 递归调用
- 递归:在函数内部可调用其他函数,若一个函数在内部调用自身本身,这个函数就叫递归函数
- 函数碰到return则终止或者结束条件
- 递归特性:
- 1.必须有一个明确的结束条件;
- 2.每次进入更深一层递归时,问题规模相比上一次递归应该有所减少;
- 3.递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层帧,由于栈的大小不是无限的,所以递归调用的次数过多,会导致栈溢出)
-
九 匿名函数
-
lambda表达式
-
lambda x(形参):x+1(返回值),函数名=lambda 形参:功能(不写函数名也可以,将简单函数书写成匿名函数)
-
十 函数式编程
- 编程的方法论:面向过程,没有返回值的函数就是过程,面向过程:找到解决的问题入口,按照一个固定的流程去模拟解决问题的流程
- 函数式编程:函数式=编程语言定义的函数+数学意义的函数
- 高阶函数:1.把函数当作参数传给另外一个函数(return.foo(bar());2.返回值包含函数(返回值可以是自己或者是其他任何函数(return bar(函数),eg:return test(),return一个函数返回值)
- 尾调用:一定在最后一步调用函数
-
十一 内置函数
- PS:迭代器只能迭代一次
-
map()
- map装一个列表,依次处理列表每个元素,最终得到的依旧是一个列表,与原来的列表顺序一致,只是列表中每个元素被处理了一遍
- 遍历序列,对序列中每个元素进行操作,最终获取新的序列。
- Python包含 6 中内建的序列,包括列表、元组、字符串、Unicode字符串、buffer对象和xrange对象。
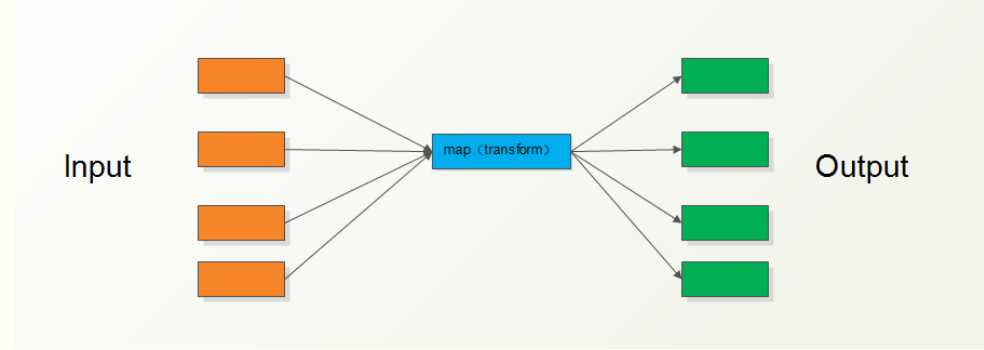
‘‘‘例子1‘‘‘ li = [11,22,33] def func1(arg): return arg + 1 #这里乘除都可以 new_list = map(func1,li) #这里map调用函数,函数的规则你可以自己指定,你函数定义成什么他就做什么操作! print new_list 输出结果:[12, 23, 34] ‘‘‘例子2‘‘‘ li = [‘shuaige‘,‘nihao‘,] def func1(arg): return ‘%s test string‘ % arg #或者使用+进行拼接万恶的+能不用最好不用他会在内存中开辟新的空间! new_strlist = map(func1,li) print new_strlist 输出结果:[‘shuaige test string‘, ‘nihao test string‘] ‘‘‘例子3‘‘‘ li = ‘abcdefg‘ def func1(arg): return ‘%s test string‘ % arg new_list = map(func1,li) print new_list #结果:[‘a test string‘, ‘b test string‘, ‘c test string‘, ‘d test string‘, ‘e test string‘, ‘f test string‘, ‘g test string‘] map例子使用lambda表达式:
-
li = [11,22,33,44,55] new_li = map(lambda a:a + 100,li) print new_li #输出结果: [111, 122, 133, 144, 155] #多个列表操作: l1 = [11,22,33,44,55] l2 = [22,33,44,55,66] l3 = [33,44,55,66,77] print map(lambda a1,a2,a3:a1+a2+a3,l1,l2,l3) #输出结果: [66, 99, 132, 165, 198] #这里需要注意如果使用map函数列表中的元素必须是相同的才可以!否则就会报下面的错误! #TypeError: unsupported operand type(s) for +: ‘int‘ and ‘NoneType‘,如果看下面 l1 = [11,22,33,44,55] l2 = [22,33,44,55,66] l3 = [33,44,55,66,] #l3的数据少一个,如果元素里的元素为空那么他调用的时候这个元素就是None lambda表达式
-
reduce()
- 可以把完整序列合并/压缩到一起得到一个值
- 处理一个序列,然后把序列进行合并操作
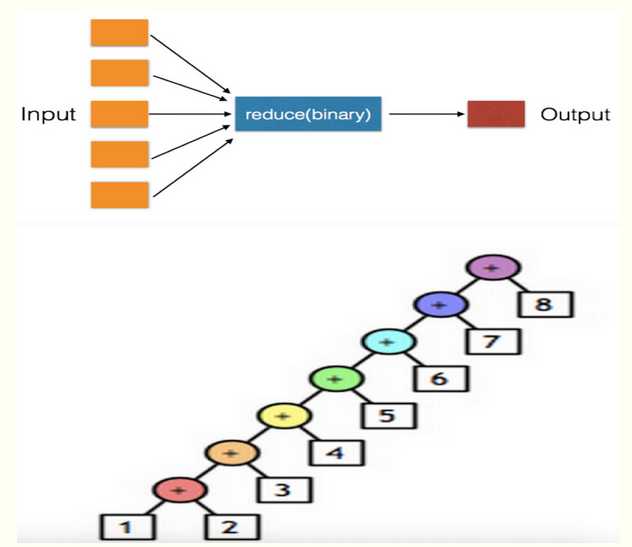
例子:
-
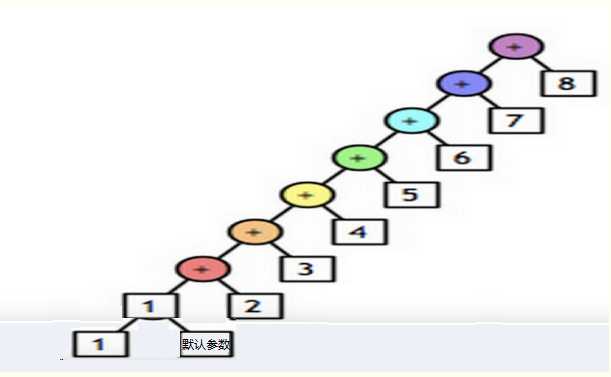
from functools import reduce
li = [1,2,3,4,5,6,7,8] result = reduce(lambda a1,a2:a1+a2,li) #累乘、除、加、减 print result # reduce的第一个参数,函数必须要有两个参数,因为他是两两进行操作 # reduce的第二个参数,要循环的序列 # reduce的第三个参数,初始值 #初始值 li = [1,2,3,4,5,6,7,8] result = reduce(lambda a1,a2:a1+a2,li,100000) #累乘、除、加、减 print result默认参数:
-
-
filter()
- 把列表中所有的值都筛选一遍,最后得到一个列表
- 遍历序列中每个元素,判断每个元素得到布尔值为True,则留下来
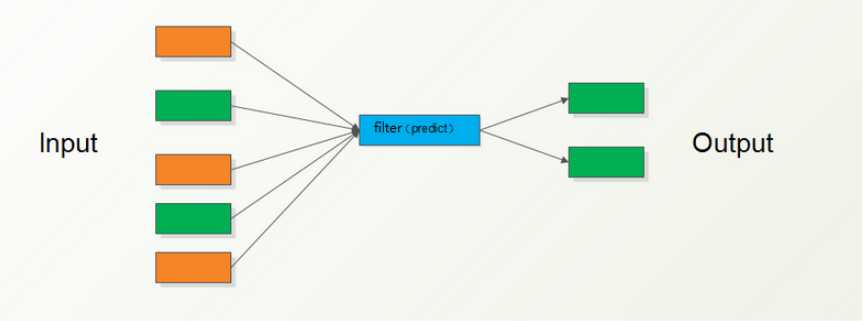
例子:
-
li = [11,22,33,44,55,66,77,88] print filter(lambda a:a>33,li) 输出结果:[44, 55, 66, 77, 88] movie_people=["hellp_sb","tres_sb","yeyhd"] print(list(filter(lambda n:not n.endwith(“sb”),movie_people)))
-
lambda()
- 其他的部分内置函数
-
abs() #取绝对值 all() #把序列中每个元素取出作布尔运算 #所有的元素为真才是真,否则为假(传入为空,返回为Ture) any()#把序列中每个元素取出作布尔运算 #所有的元素为真才是真,否则为假(传入为空,返回为False) #十进制转二进制 bin( ) #十进制转十六进制 Oct() #十进制转八进制 hex() #字符串转字节 bytes() #用什么解码就要用什么编码 name="你好“ print(bytes(name,encoding="utf-8"))#编码 print(bytes(name.encoding("utf-8").decode("utf-8")) #ASCII码不能编码中文, print(char(9)) #dir 打印某个对象下的所有方法 #divmod应用在分页中,例子:总共有10条数据,每页3条数据,那要分几页,余一则要分成4页 divmod(10,3)====输出结果:(3,1) #eval 将字符串中的数据结果提取出来; dic_str="{"name","alex"}" eval(dic_str) 输出结果:{"name","alex"} #eval 把字符串中的表达式进行运算; express="1+2*(3/3-1)-2" express="1+2*(3/3-1)-2" eval(express) 输出结果:-1.0 #可hash的数据类型即可变的数据类型 #不可hash的数据类型即不可变的数据类型 hash() #判断数据类型是TRUE isinstance() #打印局部变量 locals() #打印全局变量 globals() #zip()的用法 print(list(zip("a","b","c"),(1,2,3)) p={"name":"alex","age"=18,"gender":"None"} print(list(zip(p.keys(),p.values()) #max() dic={"name":"alex","age"=18,"gender":"None"} print(max(dic)) #默认比较的是字典的key #比较的是字典的key,但是不知道是哪个key对应的 print(max(dic.values(0)) #结合zip使用 print(max(zip(dic.values(),dic.keys()) #max函数处理的是可迭代对象,相当于一个for循环取出每个元素进行比较,注意:不同类型之间不能进行比较 #2.每个元素之间进行比较,是从每个元素的第一个位置依次比较,如果这一个位置分出大小,后面则无需比较了,直接得出这2个元素的大小。 #reversed()反转 #sorted 排序就是比较大小,不同类型之间不能比较大小 dic={"name":"alex","age"=18,"gender":"None"} print(sorted(zip(dic.values(),dic.keys())
-
高阶函数
- 参考https://www.cnblogs.com/linhaifeng/articles/6113086.html#_label1博客
- 参考https://www.cnblogs.com/luotianshuai/category/751190.html博客
以上是关于python第三篇 python基础之函数,递归,内置函数的主要内容,如果未能解决你的问题,请参考以下文章