Python爬虫连载14-动态HTMLPhantomJS和Chromedriver
Posted 心悦君兮君不知-睿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫连载14-动态HTMLPhantomJS和Chromedriver相关的知识,希望对你有一定的参考价值。
一、动态HTML
1.爬虫跟反爬虫
2.动态HTML连载
(1)JavaScript
(2)jQuery
(3)Ajax
(4)DHTML
(5)Python采集动态数据
从JavaScript代码入手采集;Python第三方库运行JavaScript,直接采集你在浏览器中看到的页面
二、Selenium + PhantomJS
1.Selenium:web自动化测试工具
(1)自动加载页面;(2)获取数据;(3)截屏
(4)官方文档:http://selenium-python.readthedocs.io/index.html
2.PhantomJS
(1)基于WebKit的无界面的浏览器
(2)官方网站:http://phantomjs.org/download.html
3.Selenium库有一个WebDriver的API
4.WebDriver可以跟页面上的元素进行各种交互,用它可以来进行爬取
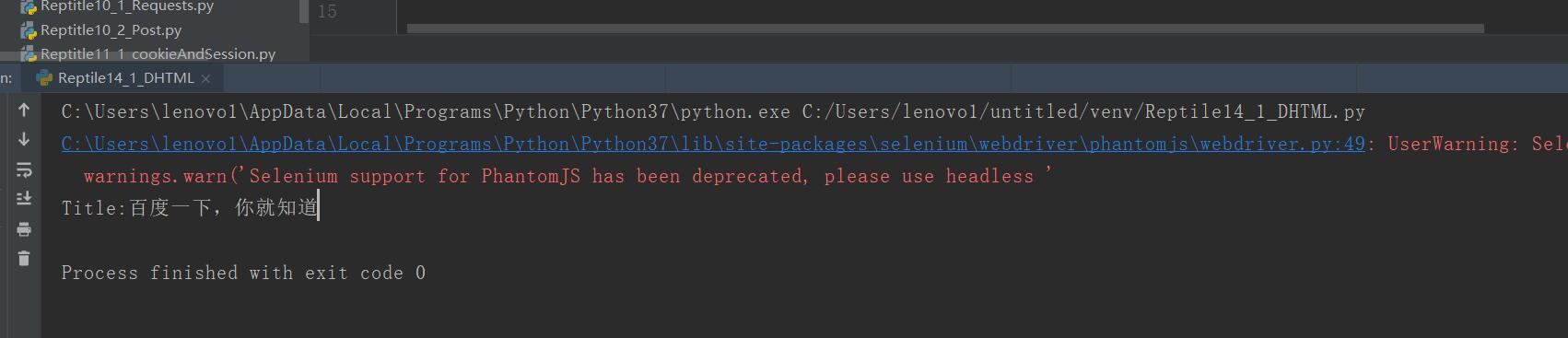
"""
通过webdriver操作模拟进行查找
"""
from selenium import webdriver
import time
#通过keys模拟键盘
from selenium.webdriver.common.keys import Keys
#操作哪个浏览器就对哪个浏览器建立一个实例
#自动按照环境变量查找相应的浏览器
driver = webdriver.PhantomJS()#这个就是浏览器的实例
#如果浏览器没有相应的环境浏览器,需要指定浏览器位置
driver.get("http://www.baidu.com")#去访问这个网站,然后获取返回的数据
#通过函数查找title标签
print("Title:{0}".format(driver.title))
5.Chrome + Chromedriver
下载Chrome:下载和安装
Chromdriver安装
五、源码
Reptile14_1_DHTML.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile14_1_DHTML.py
2.CSDN:https://blog.csdn.net/weixin_44630050
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料

以上是关于Python爬虫连载14-动态HTMLPhantomJS和Chromedriver的主要内容,如果未能解决你的问题,请参考以下文章