Python3----下载小说代码
Posted 我是谁9
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python3----下载小说代码相关的知识,希望对你有一定的参考价值。
前言
该文章主要分析编写爬虫小说的思路,文章代码使用语言Python3.7
2020-03-20
天象独行
第一部分:面对过程编程
1;首先我们确定目标,我们将要从网页:“https://www.biqukan.com/38_38836”下载小说“沧元图”。这里我们先设定URL以及请求头(后面会进行调整,让程序与人进行交互),且程序所需要的库:
from urllib import request from bs4 import BeautifulSoup import _collections import re import os
\'\'\' *********************************** 获取下载连接 *********************************** \'\'\' url = \'https://www.biqukan.com/38_38836/\' head = {\'User-Agent\':\'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19\',}
2;看到整个网页,我们发现这个界面是有很多目录,那么我们输入按键“F12”去查看前段代码。发现代码中属性“href”表示这是资源的具体路径,那这个时候,我们想到,可以通过Python 3 模块urllib 发出请求,正则表达式来提取内容的方式来提取我们所需要的内容:目录名称以及资源路径。具体查看如下代码:
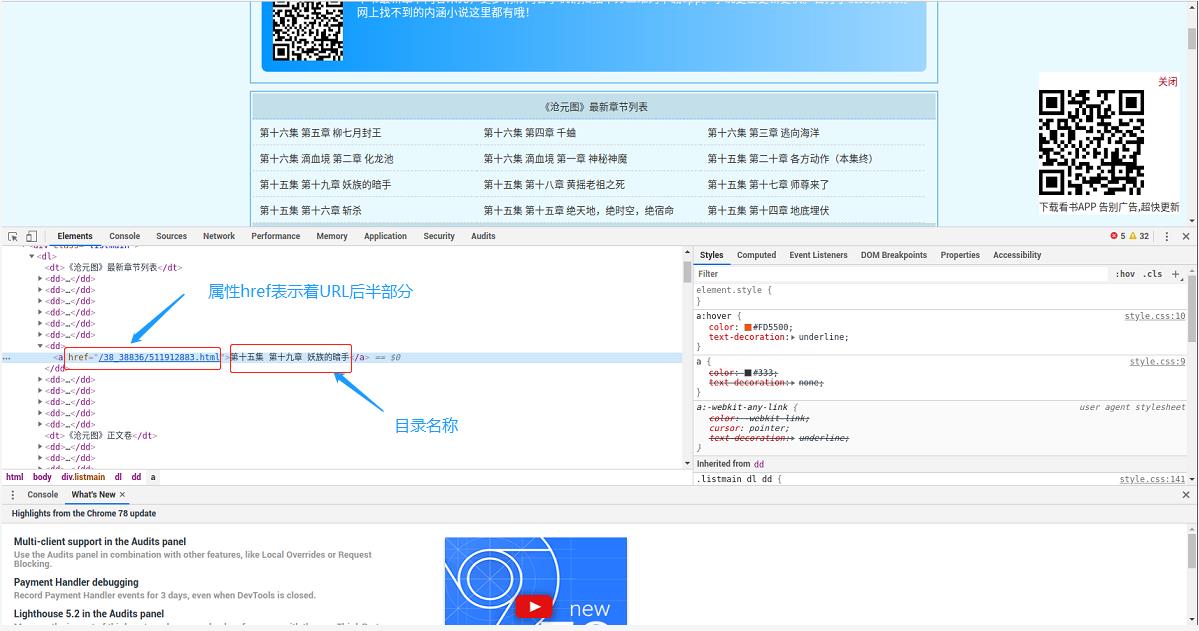
charter = re.compile(u\'[第弟](.+)章\', re.IGNORECASE) target_req = request.Request(url=url,headers=head) #发送请求 #print("request.req的返回对象:",type(target_req)) #print("++++++++++++++++++++++++++++++++++++++++++") target_response = request.urlopen(target_req) #打开response包 #print("request.response的返回对象:",type(target_response)) #print("++++++++++++++++++++++++++++++++++++++++++") \'\'\' 打开read()用gbk编码编译 \'\'\' target_html = target_response.read().decode(\'gbk\',\'ignore\') #print("request.html的返回对象:",type(target_html)) #print("++++++++++++++++++++++++++++++++++++++++++") listmain_soup = BeautifulSoup(target_html,\'lxml\') #使用“lxml”编译 #print(listmain_soup.ul.li) #print("listmain_soup的返回对象:",type(listmain_soup)) #print("++++++++++++++++++++++++++++++++++++++++++") #chapters 状态是列表 chapters = listmain_soup.find_all(\'div\',class_= \'listmain\') #在下载的页面当中通过方法find_all 将页面中指定位置提取出来。 #print(chapters) #print(type(chapters)) #print("++++++++++++++++++++++++++++++++++++++++++") #help(listmain_soup.find_all) download_soup = BeautifulSoup(str(chapters),\'lxml\') #将页面使用“lxml”编译 #print(download_soup) #a = str(download_soup.dl.dt).split("》")[0][5:] #print(a) #novel_name = str(download_soup.) novel_name = str(download_soup.dl.dt).split("》")[0][5:] #提取小说名称 flag_name = "《" + novel_name + "》" + "正文卷" #print(flag_name) #print(len(download_soup.dl)) #章节数目numbers numbers = (len(download_soup.dl) - 1) / 2 - 8 #print(numbers) download_dict = _collections.OrderedDict() begin_flag = False numbers = 1 #print(download_soup.dl.children) #Beautiful Soup 通过tag的.children生成器,可以对tag的子节点进行循环 #get属性的值 for child in download_soup.dl.children: #print(dir(child)) #如果tag只有一个 NavigableString 类型子节点,那么这个tag可以使用 .string 得到子节点: if child != \'\\n\': if child.string == u"%s" % flag_name: begin_flag = True if begin_flag == True and child.a != None: download_url = "https://www.biqukan.com" + child.a.get(\'href\') download_name = child.string #print(download_name) names = str(download_name).split(\'章\') #print(names) name = charter.findall(names[0] + \'章\') #print(name) if name: download_dict[\'第\' + str(numbers) + \'章 \' + names[-1]] = download_url numbers += 1 #print(novel_name + \'.txt\' , numbers,download_dict) #print(download_url)
3;这个时候我们成功将文章名称以及下载地址提取出来。结果如下图:
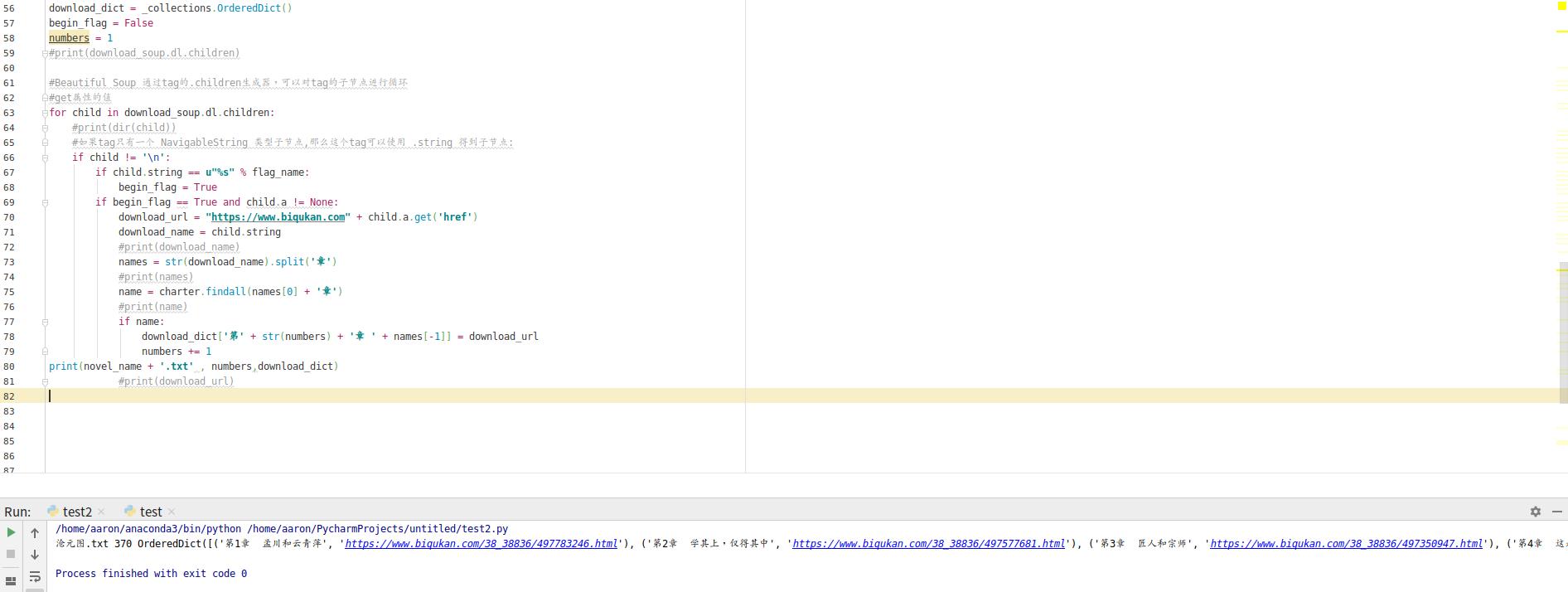
4;接下来,我们通过for 循环来逐一提取出文件名称以及下载地址,并且逐一下载进入文件。详细查看如下代码:
\'\'\' *************************************** 提取下载地址,提取下载内容 *************************************** \'\'\' #print(download_dict[\'第1章 孟川和云青萍\']) print("下载开始>>>>") for key,value in download_dict.items(): name_key = key path = \'/home/aaron/桌面/novel\' + \'//\' + name_key download_req_key = request.Request(url=value,headers=head) download_response_value = request.urlopen(download_req_key) download_html = download_response_value.read().decode(\'gbk\',\'ignore\') soup_texts_value = BeautifulSoup(download_html,\'lxml\') texts = soup_texts_value.find_all(id = \'content\', class_ = \'showtxt\') \'\'\' 函数解析: 1;text 提取文本 2;replace()方法把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。 \'\'\' texts = BeautifulSoup(str(texts),\'lxml\').div.text.replace(\'app2();\' , \'\') texts = texts.encode() #print(type(texts)) file = os.open(path,os.O_CREAT|os.O_RDWR|os.O_APPEND) os.write(file,texts) #os.close(file) print("%s 下载完成" ,name_key)
5;程序运行结果:
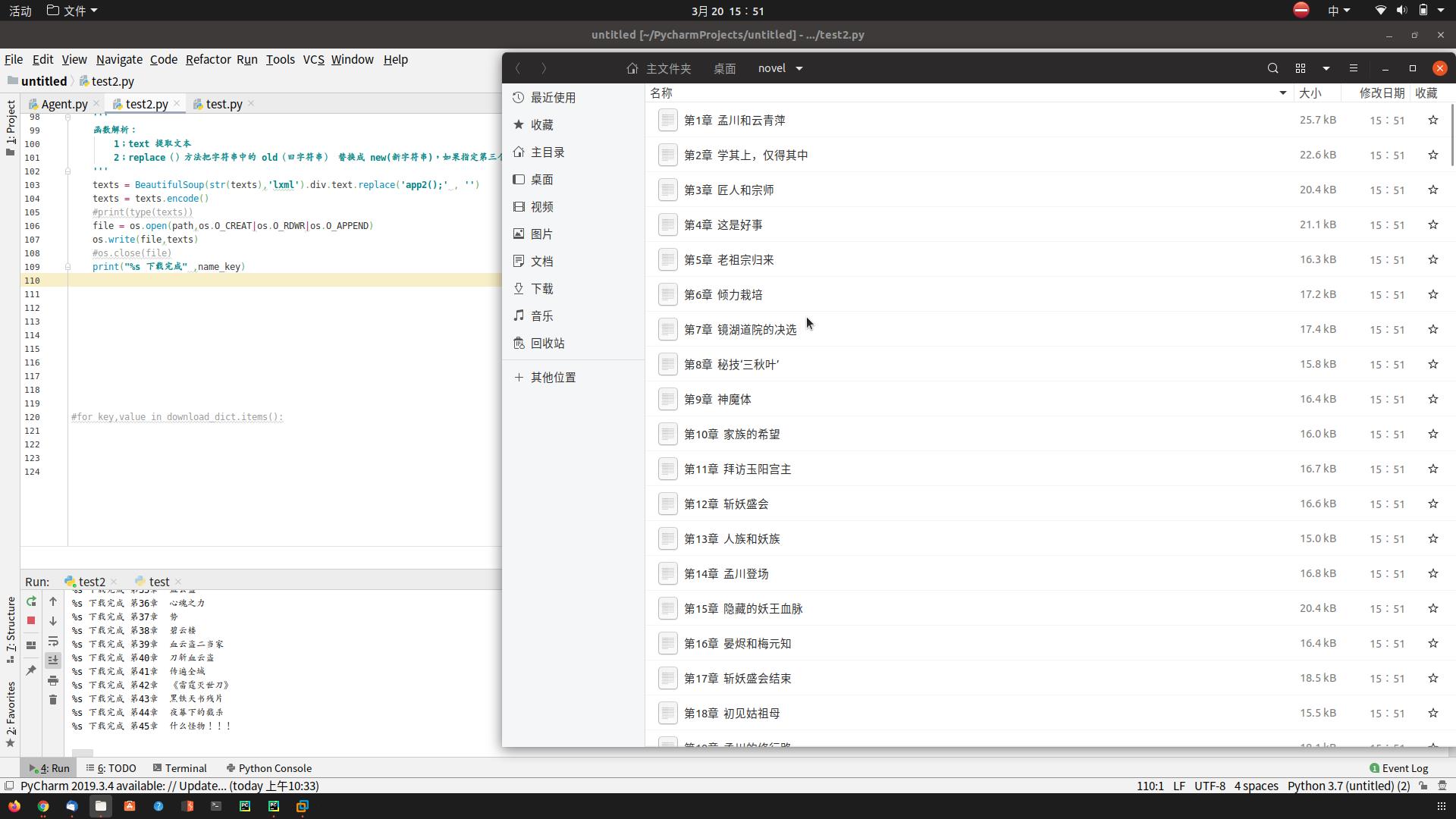
第二部分:面对对象思想
1;上面程序已经完成了任务,但是这样的代码没有交互,也没有这么方便阅读,那么我们将代码稍微调整一下。首先,我们将必要的,可重复的使用的功能都放在函数里面调用。如下:
# -*- coding:UTF-8 -*- from urllib import request from bs4 import BeautifulSoup import _collections import re import os \'\'\' 类:下载《笔趣看》网小说: url:https://www.biqukan.com/ \'\'\' class download(object): def __init__(self,target): self.target_url = target self.head = {\'User-Agent\':\'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19\',} \'\'\' 方法:获取下载链接 Parameters: 无 Returns: 1;文件名称 2;下载信息地址 3;小说名称 \'\'\' def download_url(self): download_req = request.Request(url=self.target_url, headers = self.head) download_response = request.urlopen(download_req) download_html = download_response.read().decode(\'gbk\',\'ignore\') \'\'\' 1;目前HTML已经使用url库发送了请求,接下来使用lxml编译,这么做是让我们更好的去提取网页当中我们需要的内容 \'\'\' listmain_soup = BeautifulSoup(download_html,\'lxml\') \'\'\' 2;我们通过BeautifulSoup方法,使用\'lxml\'编译,接下来我们我们来提取文件名称 \'\'\' chapters = listmain_soup.find_all(\'div\',class_ = \'listmain\') download_soup = BeautifulSoup(str(chapters),\'lxml\') \'\'\' 3;提取文件名称 \'\'\' novel_name = str(download_soup.dl.dt).split("》")[0][5:] \'\'\' 4;设定for循环所需要的参数 \'\'\' flag_name = \'《\' + novel_name + \'》\' + \'正文卷\' begin_flag = False #设定开始运行下载的位置 download_dict = _collections.OrderedDict() #设定有序字典,用来存放文件名称和下载链接地址 numbers = 1 # 设定章节内容 \'\'\' 4;利用for循环来提取出文件名称以及下载地址 \'\'\' for child in download_soup.dl.children: if child != \'\\n\': #排除空格 if child.string == u"%s" % flag_name: #设定开始下载位置 begin_flag = True if begin_flag == True and child.a != None: #符合有下载链接地址的条件才会下载 download_url = "https://www.biqukan.com" + child.a.get(\'href\') # get() 用来提取属性内容 download_name = child.string \'\'\' 5;重新修改文件名称 \'\'\' names = str(download_name).split(\'章\') name = charter.findall(names[0] + \'章\') \'\'\' 6;将文件名称以及下载链接放入字典当中 \'\'\' if name: download_dict[\'第\' + str(numbers) + \'章 \' + names[-1]] = download_url numbers += 1 return novel_name + \'.txt\' , numbers , download_dict \'\'\' 函数说明:爬文章内容 Parameters: url Retruns: soup_text \'\'\' def Downloader(self,url): download_req = request.Request(url=self.target_url, headers = self.head) download_response = request.urlopen(download_req) download_html = download_response.read().decode(\'gbk\',\'ignore\') soup_texts = BeautifulSoup(download_html,\'lxml\') texts = soup_texts.find_all(id=\'content\', class_=\'showtxt\') soup_text = BeautifulSoup(str(texts), \'lxml\').div.text.replace(\'app2();\', \'\') return soup_text \'\'\' 函数说明:将爬去的文件内容写入文件 \'\'\' def writer(self,name,path,text): write_flag = True #设定文件写入的位置 \'\'\' 1;使用with循环打开文件,并且注入到“f”当中 \'\'\' with open(path,\'a\',encoding=\'utf-8\') as f: f.write(name + \'\\n\\n\') for each in text: if each == \'h\': write_flag = False if write_flag == True and each != \' \': f.write(each) if write_flag == True and each == \'\\r\': f.write(\'\\n\') f.write(\'\\n\\n\') if __name__ == "__main__": target_url = str(input("请输入小说目录下载地址:\\n")) d = download(target=target_url) name , numbers, url_dict = d.download_url() if name in os.listdir(): os.remove(name) index =1 print("《%s》下载中:" % name[:-4]) for key,value in url_dict.items(): d.writer(key,name,d.Downloader(value)) sys.stdout.write("已下载:%.3f%%" % float(index / numbers) + \'\\r\') sys.stdout.flush() index += 1 print("《%s》下载完成!" % name[:-4])
以上是关于Python3----下载小说代码的主要内容,如果未能解决你的问题,请参考以下文章
Python3网络爬虫:使用Beautiful Soup爬取小说