python并发编程--进程--其他模块-从菜鸟到老鸟
Posted 少年阿斌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python并发编程--进程--其他模块-从菜鸟到老鸟相关的知识,希望对你有一定的参考价值。
concurrent模块
1、concurrent模块的介绍
concurrent.futures模块提供了高度封装的异步调用接口ThreadPoolExecutor:线程池,提供异步调用ProcessPoolExecutor:进程池,提供异步调用
ProcessPoolExecutor 和 ThreadPoolExecutor:两者都实现相同的接口,该接口由抽象Executor类定义。
2、基本方法
使用_base.Executor
concurrent.futures.thread.ThreadPoolExecutor #线程池 concurrent.futures.process.ProcessPoolExecutor #进程池 #构造函数 def __init__(self, max_workers=None, mp_context=None, initializer=None, initargs=()):
submit(fn, *args, **kwargs):异步提交任务
使用submit函数来提交线程需要执行任务(函数名和参数)到线程池中,并返回该任务的句柄(类似于文件、画图),注意submit()不是阻塞的,而是立即返回。
map(func, *iterables, timeout=None, chunksize=1)
取代for循环submit的操作
shutdown(wait=True):相当于进程池的pool.close()+pool.join()操作- wait=True,等待池内所有任务执行完毕回收完资源后才继续
- wait=False,立即返回,并不会等待池内的任务执行完毕
- 但不管wait参数为何值,整个程序都会等到所有任务执行完毕
note:submit和map必须在shutdown之前
pool.submit()返回的对象是
concurrent.futures._base.Future类
add_done_callback(self,fn) cancel(self) cancelled(self) done(self) exception(self,timeout=None) result(self,timeout=None) running(self) set_exception(self,exception) set_result(self,result) set_running_or_notify_cancel(self)
result(timeout=None):取得结果,通过submit函数返回的任务句柄,使用result()方法可以获取任务的返回值,查看内部代码,发现这个方法是阻塞的- done()方法判断该任务是否结束
add_done_callback(fn):回调函数
3、进程池和线程池
池的功能:限制进程数或线程数.
什么时候限制: 当并发的任务数量远远大于计算机所能承受的范围,即无法一次性开启过多的任务数量 我就应该考虑去限制我进程数或线程数,从保证服务器不崩.
3.1 进程池
from concurrent.futures import ProcessPoolExecutor import os import time def task(i): print("第"+str(i)+"个在执行任务id:"+str(os.getpid())) time.sleep(1) if __name__ == \'__main__\': start=time.time() pool = ProcessPoolExecutor(4) # 进程池里又4个进程 for i in range(5): # 5个任务 pool.submit(task,i)# 进程池里当前执行的任务i,池子里的4个进程一次一次执行任务 pool.shutdown() print("耗时:",time.time()-start)

3.2 线程池
from concurrent.futures import ThreadPoolExecutor from threading import currentThread import time def task(i): print("第"+str(i)+"个在执行任务id:"+currentThread().name) time.sleep(1) if __name__ == \'__main__\': start = time.time() pool = ThreadPoolExecutor(4) # 进程池里又4个线程 for i in range(5): # 5个任务 pool.submit(task,i)# 线程池里当前执行的任务i,池子里的4个线程一次一次执行任务 pool.shutdown() print("耗时:",time.time()-start)

其他:done() 、 result()
3.4列表+as_compelete模拟先进先出
对于线程,这样可以模拟执行与结果的先进先出。
但是对于进程会报错。
import time from concurrent.futures import ProcessPoolExecutor,as_completed,ThreadPoolExecutor def get_html(i): times=1 time.sleep(times) print("第 NO.{i} get page {times} finished".format(i=i,times=times)) return "第 NO.{i} ".format(i=i) start=time.time() executor = ThreadPoolExecutor(max_workers=2) # executor = ProcessPoolExecutor(max_workers=2) #进程池会导致后面的all_task报错 all_task = [executor.submit(get_html,(i)) for i in range(5)] for future in as_completed(all_task): data = future.result() print("in main:get page {} success".format(data)) print(\'主进程结束--耗时\',time.time()-start)
结果:


第 NO.0 get page 1 finished 第 NO.1 get page 1 finished in main:get page 第 NO.0 success in main:get page 第 NO.1 success 第 NO.2 get page 1 finished in main:get page 第 NO.2 success 第 NO.3 get page 1 finished in main:get page 第 NO.3 success 第 NO.4 get page 1 finished in main:get page 第 NO.4 success 主进程结束--耗时 3.0034666061401367
3.4 Map的用法
可以将多个任务一次性的提交给进程、线程池。---备注进程是也不行的,也会报错。
使用map方法,不需提前使用submit方法,map方法与python标准库中的map含义相同,都是将序列中的每个元素都执行同一个函数。
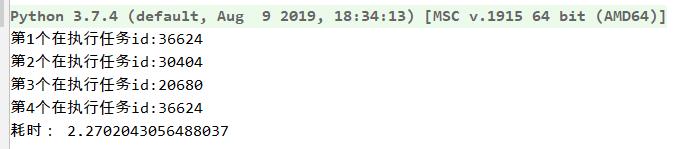
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import os,time,random def task(i): print("第"+str(i)+"个在执行任务id:"+str(os.getpid())) time.sleep(1) if __name__ == \'__main__\': start=time.time() pool=ProcessPoolExecutor(max_workers=3) #也可以换成ThreadPoolExecutor pool.map(task,range(1,5)) #map取代了for+submit pool.shutdown() print("耗时:",time.time()-start)
考虑到结果返回值:
import time from random import random from concurrent.futures import ProcessPoolExecutor,as_completed,ThreadPoolExecutor def get_html(i): times=1+random()/100 time.sleep(times) print("第 NO.{i} get page {times}s finished".format(i=i,times=times)) return "第 NO.{i} ".format(i=i) start=time.time() executor = ThreadPoolExecutor(max_workers=2) # executor = ProcessPoolExecutor(max_workers=2) #进程池会导致后面的executor.map报错 res=executor.map(get_html, range(5)) # for future in res: #直接返回结果,不需要get print("in main:get page {} success".format(future)) print(\'主进程结束--耗时\',time.time()-start)

3.5 同步调用,顺序返回
因为我们在循环中每次循环都要调用或这说提交任务,并等待结果。所以其实进程之间是串行的。所以是同步的方式。
from concurrent.futures import ProcessPoolExecutor from multiprocessing import current_process import time n = 1 def task(i): global n time.sleep(1) print(f\'{current_process().name} 在执行任务{i}\') n += i return f\'得到 {current_process().name} 任务{i} 的结果\' if __name__ == \'__main__\': start=time.time() pool = ProcessPoolExecutor(2) # 进程池里又4个线程 pool_lis = [] for i in range(5): # 20个任务 future = pool.submit(task,i)# 进程池里当前执行的任务i,池子里的4个线程一次一次执行任务 pool_lis.append(future.result()) #等待我执行任务得到的结果,如果一直没有结果,则阻塞。这里会导致我们所有任务编程了串行 # 在这里就引出了下面的pool.shutdown()方法 pool.shutdown(wait=True) # 关闭了池的入口,不允许在往里面添加任务了,会等带所有的任务执行完,结束阻塞 for res in pool_lis: print(res) print(n)# 这里肯定是拿到0的 print("主进程---耗时",time.time()-start) # 可以用join去解决,等待每一个进程结束后,拿到他的结果
结果:
SpawnProcess-2 在执行任务0 SpawnProcess-1 在执行任务1 SpawnProcess-2 在执行任务2 SpawnProcess-1 在执行任务3 SpawnProcess-2 在执行任务4 得到 SpawnProcess-2 任务0 的结果 得到 SpawnProcess-1 任务1 的结果 得到 SpawnProcess-2 任务2 的结果 得到 SpawnProcess-1 任务3 的结果 得到 SpawnProcess-2 任务4 的结果 1 主进程---耗时 5.575225830078125
3.5 异步调用,顺序返回
from concurrent.futures import ProcessPoolExecutor from multiprocessing import current_process import time n = 1 def task(i): global n time.sleep(1) print(f\'{current_process().name} 在执行任务{i}\') n += i return f\'得到 {current_process().name} 任务{i} 的结果\' if __name__ == \'__main__\': start=time.time() pool = ProcessPoolExecutor(2) # 进程池里又4个线程 pool_lis = [] for i in range(5): # 20个任务 future = pool.submit(task,i)# 进程池里当前执行的任务i,池子里的4个线程一次一次执行任务 # print(future.result()) # 这是在等待我执行任务得到的结果,如果一直没有结果,这里会导致我们所有任务编程了串行 # 在这里就引出了下面的pool.shutdown()方法 pool_lis.append(future) pool.shutdown(wait=True) # 关闭了池的入口,不允许在往里面添加任务了,会等带所有的任务执行完,结束阻塞 for p in pool_lis: print(p.result()) print(n)# 这里肯定是拿到0的 print("主进程---耗时",time.time()-start) # 可以用join去解决,等待每一个进程结束后,拿到他的结果
结果:
SpawnProcess-1 在执行任务0 SpawnProcess-2 在执行任务1 SpawnProcess-1 在执行任务2 SpawnProcess-2 在执行任务3 SpawnProcess-1 在执行任务4 得到 SpawnProcess-1 任务0 的结果 得到 SpawnProcess-2 任务1 的结果 得到 SpawnProcess-1 任务2 的结果 得到 SpawnProcess-2 任务3 的结果 得到 SpawnProcess-1 任务4 的结果 1 主进程---耗时 3.2690603733062744
3.5 回调函数:
add_done_callback
from multiprocessing import current_process import time from random import random from concurrent.futures import ProcessPoolExecutor def task(i): print(f\'{current_process().name} 在执行{i}\') time.sleep(1+random()) return i # parse 就是一个回调函数 def parse(future): # 处理拿到的结果 print(f\'{current_process().name} 拿到结果{future.result()} 结束了当前任务\') if __name__ == \'__main__\': start=time.time() pool = ProcessPoolExecutor(2) for i in range(5): future = pool.submit(task,i) \'\'\' 给当前执行的任务绑定了一个函数,在当前任务结束的时候就会触发这个函数(称之为回调函数) 会把future对象作为参数传给函数 注:这个称为回调函数,当前任务处理结束了,就回来调parse这个函数 \'\'\' future.add_done_callback(parse) # add_done_callback (parse) parse是一个回调函数 # add_done_callback () 是对象的一个绑定方法,他的参数就是一个函数 pool.shutdown() print(\'主线程耗时:\',time.time()-start)
结果:
SpawnProcess-1 在执行0 SpawnProcess-2 在执行1 SpawnProcess-2 在执行2 MainProcess 拿到结果1 结束了当前任务 SpawnProcess-1 在执行3 MainProcess 拿到结果0 结束了当前任务 SpawnProcess-1 在执行4 MainProcess 拿到结果3 结束了当前任务 MainProcess 拿到结果2 结束了当前任务 MainProcess 拿到结果4 结束了当前任务 主线程耗时: 4.721129417419434
3.6wait
wait方法可以让主线程阻塞,直到满足设定的要求。wait方法接收3个参数,等待的任务序列、超时时间以及等待条件。
等待条件return_when默认为ALL_COMPLETED,表明要等待所有的任务都借宿。
可以看到运行结果中,确实是所有任务都完成了,主线程才打印出main,等待条件还可以设置为FIRST_COMPLETED,表示第一个任务完成就停止等待
from concurrent.futures import ThreadPoolExecutor,wait,ALL_COMPLETED,FIRST_COMPLETED import time #参数times用来模拟网络请求时间 from random import random def get_html(i): times=1+random()*10 time.sleep(times) print("第 NO.{i} get page {times}s finished".format(i=i,times=times)) return "第 NO.{i} ".format(i=i) executor = ThreadPoolExecutor(max_workers=2) urls = range(5) all_task = [executor.submit(get_html,(url)) for url in urls] wait(all_task,return_when=ALL_COMPLETED) print("main")

joblib模块
以上是关于python并发编程--进程--其他模块-从菜鸟到老鸟的主要内容,如果未能解决你的问题,请参考以下文章