ConcurrentHashMap使用案例(单词数量统计)
Posted 哩个啷个波
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ConcurrentHashMap使用案例(单词数量统计)相关的知识,希望对你有一定的参考价值。
前言
- 目标:实现单词数量统计
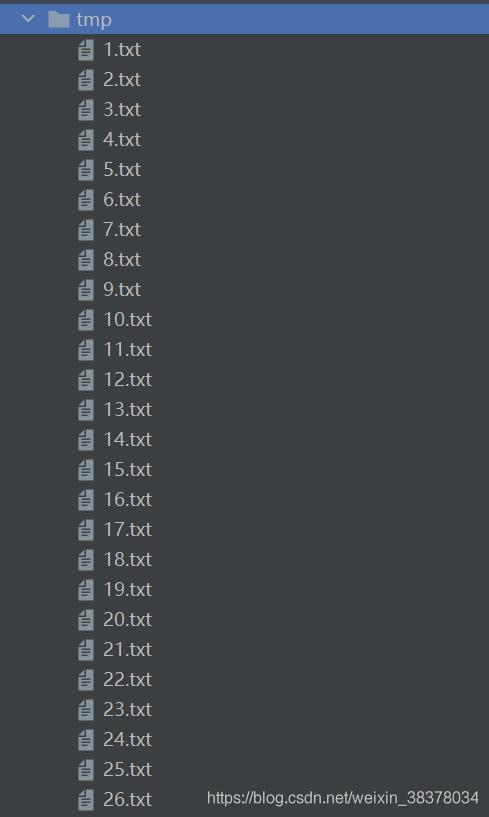
- 过程:首先使用26个英文字母,每个字母200个,将26200个字母打乱顺序存入26个txt文件中。
使用26个线程,每个线程统计一个txt文件的200个字母。26个线程同时操作这一个Map集合。
最终想要得到的结果为:a:200(a被统计了200次),b:200(b被统计了200次)……z:200(z被统计200次)总和26200。 - 实践:使用HashMap进行统计
- 问题:HashMap会出现什么样的结果?
- 如何使用ConcurrentHashMap解决此问题。
1. 案例样本准备
import java.io.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
public class WordCountCreat
static final String ALPHA = "abcedfghijklmnopqrstuvwxyz"; //26个英文字母
public static void main(String[] args) throws IOException
int length = ALPHA.length();//26
int count = 200;
List<String> list = new ArrayList<>(length * count);//26*200
for (int i = 0; i < length; i++) //每个英文字母生成200个加入list
char ch = ALPHA.charAt(i);
for (int j = 0; j < count; j++)
list.add(String.valueOf(ch));
Collections.shuffle(list);//将26*200个字母打乱顺序
for (int i = 0; i < 26; i++) //每200个字母为一组,存入26个txt文件
String path = "tmp/" + (i + 1) + ".txt";
File file = new File(path);
if (!file.isFile())
file.createNewFile();
BufferedWriter writer = new BufferedWriter(new FileWriter(path));
String collect = list.subList(i * count, (i + 1) * count).stream()
.collect(Collectors.joining("\\n"));
writer.write(collect);
writer.close();
生成结果以及每个文件中的内容
2. 使用HashMap
public class WordCountTest
public static void main(String[] args)
demo(
// 创建 map 集合
() -> new HashMap<String, Integer>(),
// 进行计数
(map, words) ->
for (String word : words)
Integer counter = map.get(word);
int newValue = counter == null ? 1 : counter + 1;
map.put(word, newValue);
);
private static <V> void demo(Supplier<Map<String,V>> supplier,
BiConsumer<Map<String,V>, List<String>> consumer)
Map<String, V> counterMap = supplier.get();//获取Map集合
List<Thread> ts = new ArrayList<>();//创建Thread 线程的ArrayList列表
for (int i = 1; i <= 26; i++) //启动26个线程,并发读取26个txt文件
int idx = i;
Thread thread = new Thread(() ->
List<String> words = readFromFile(idx);//读取完成一个txt文件返回200个单词
consumer.accept(counterMap, words);//存入当前Map集合
);
ts.add(thread);
ts.forEach(t->t.start());//启动全部线程
ts.forEach(t->
try
t.join();//调用线程等待26个线程执行结束
catch (InterruptedException e)
e.printStackTrace();
);
System.out.println(counterMap);//26个线程全部执行完成,输出map集合
public static List<String> readFromFile(int i)
ArrayList<String> words = new ArrayList<>();
try (BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream("tmp/"
+ i +".txt"))))
while(true)
String word = in.readLine();
if(word == null)
break;
words.add(word);
return words;
catch (IOException e)
throw new RuntimeException(e);
执行结果
a=198, b=200, c=200, d=197, e=198, f=199, g=198, h=200, i=198, j=199, k=198, l=199, m=199, n=199, o=196, p=199, q=199, r=200, s=200, t=200, u=200, v=199, w=200, x=198, y=199, z=199
可以看到在并发统计单词个数时,没有将所有的字母统计到200。
原因分析
(map, words) ->
for (String word : words)
Integer counter = map.get(word);//读取
int newValue = counter == null ? 1 : counter + 1;
map.put(word, newValue);//写入
在上述代码中,多个线程对共享资源HashMap进行读写操作,产生线程安全问题。
若一个线程map.get("a")获取到a的counter值,而其他线程在当前获取值后,操作map.put("a",newValue)修改了a的counter。则当前线程再次put会产生数据误差。
3. 解决HashMap产生的线程不安全问题
为什么使用ConcurrentHashMap而不直接使用Synchronized关键字?
直接加Synchronized属于粗粒度锁,而ConcurrentHashMap属于细粒度锁,性能更优。
如何使用ConcurrentHashMap改进
() -> new HashMap<String, Integer>()
改为
() -> new ConcurrentHashMap<String, Integer>()
仅仅是将HashMap改为ConcurrentHashMap,会保证并发安全吗?
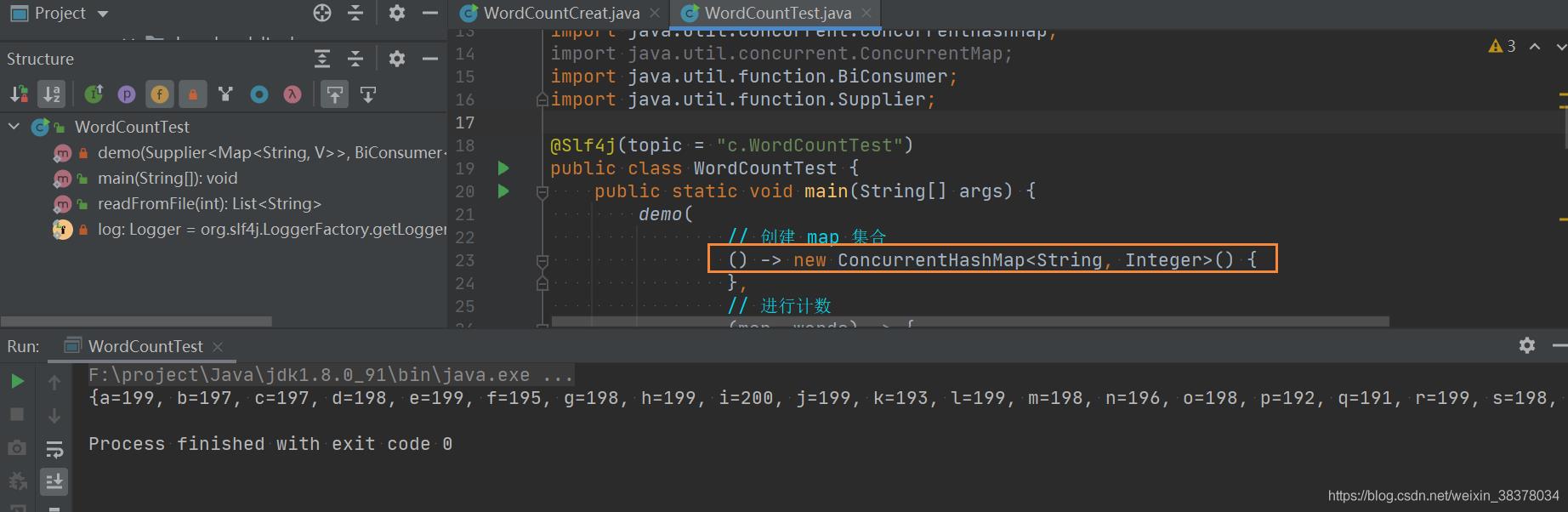
依然会产生数据统计偏差。
问题分析:只将HashMap改为ConcurrentHashMap只保证内部put,get的原子性,不能保证联合起来的原子性。
修改上述代码
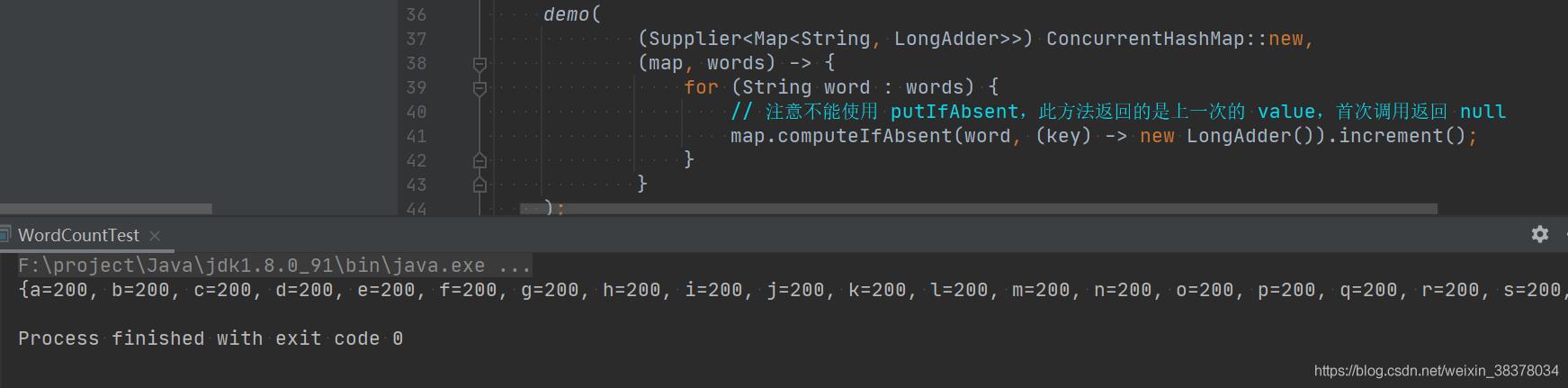
demo(
() -> new ConcurrentHashMap<String, LongAdder>(),
(map, words) ->
for (String word : words)
// 注意不能使用 putIfAbsent,此方法返回的是上一次的 value,首次调用返回 null
map.computeIfAbsent(word, (key) -> new LongAdder()).increment();
);
Map.computeIfAbsent源码
default V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction)
Objects.requireNonNull(mappingFunction);
V v;
if ((v = get(key)) == null)
V newValue;
if ((newValue = mappingFunction.apply(key)) != null)
put(key, newValue);
return newValue;
return v;
如果缺少一个key,则计算生成一个value,将key和value放入map。整个过程被封装为原子性操作,线程安全的
同时使用LongAdder进行线程安全的自增操作。
结果验证
另一方案
demo(
() -> new ConcurrentHashMap<String, Integer>(),
(map, words) ->
for (String word : words)
// 函数式编程,无需原子变量
map.merge(word, 1, Integer::sum);
);
结果验证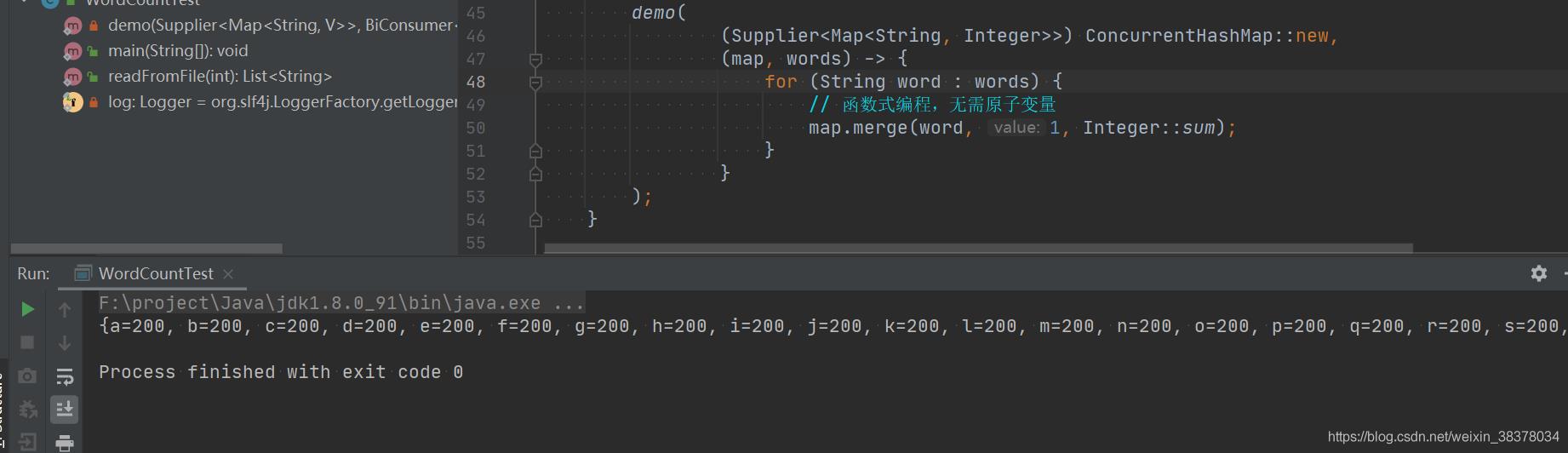
以上是关于ConcurrentHashMap使用案例(单词数量统计)的主要内容,如果未能解决你的问题,请参考以下文章