Cache 与Memory架构及数据交互
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Cache 与Memory架构及数据交互相关的知识,希望对你有一定的参考价值。
Cache 与Memory架构及数据交互
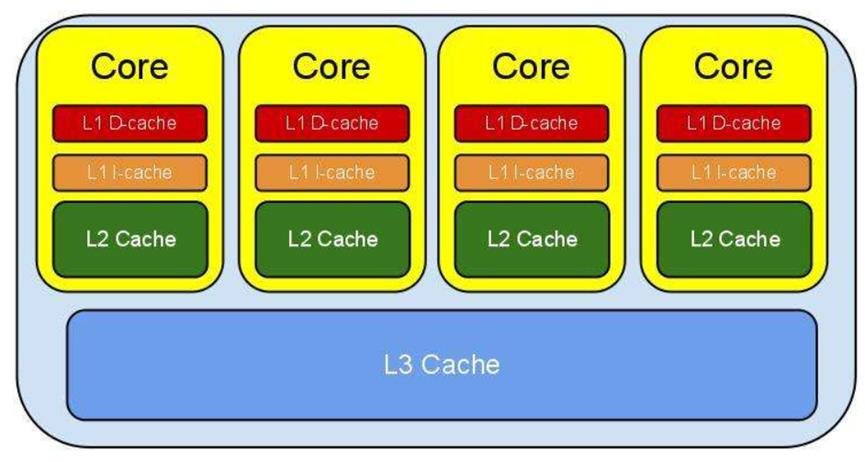
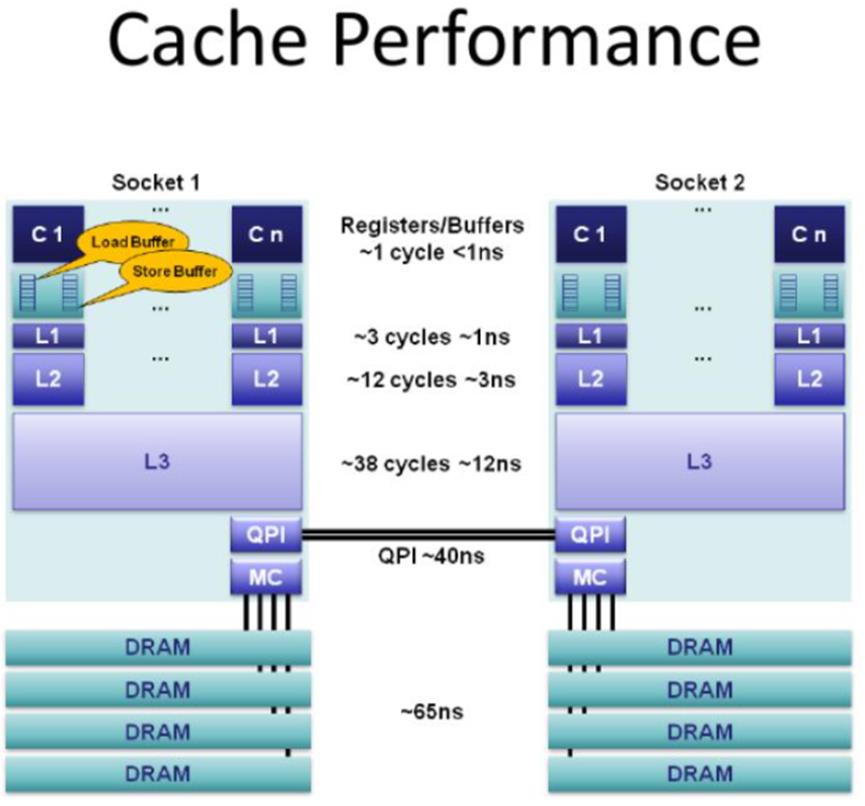
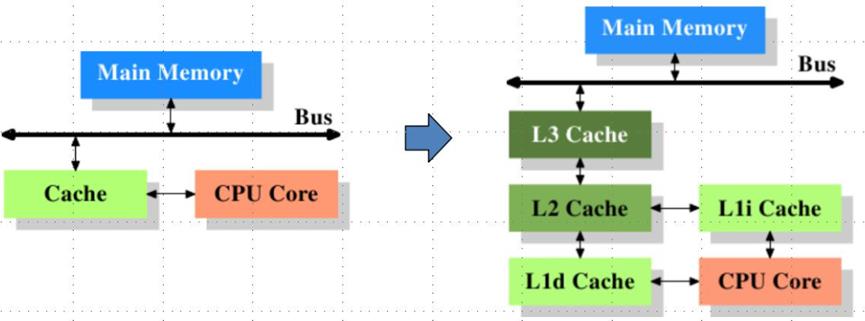
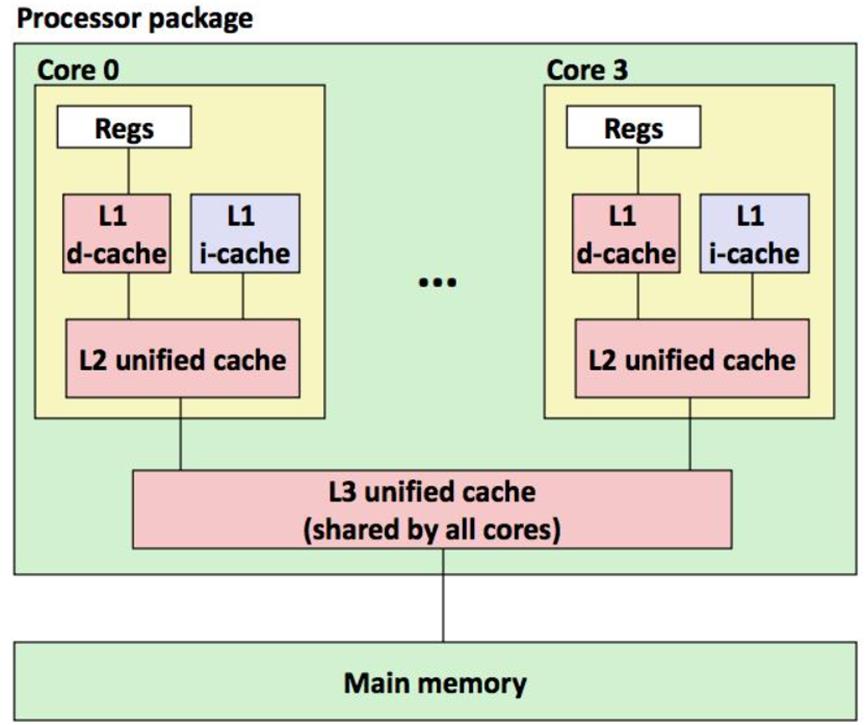
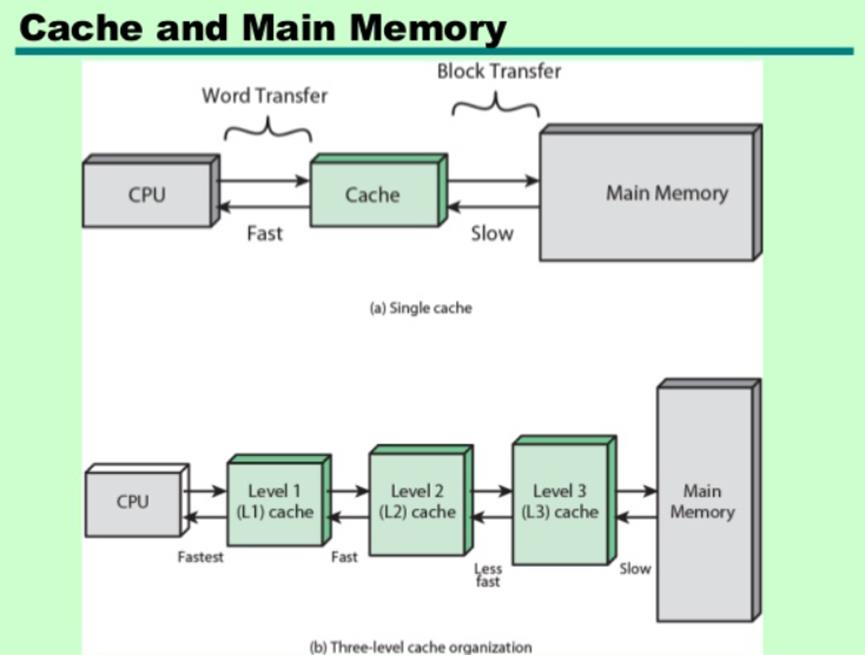
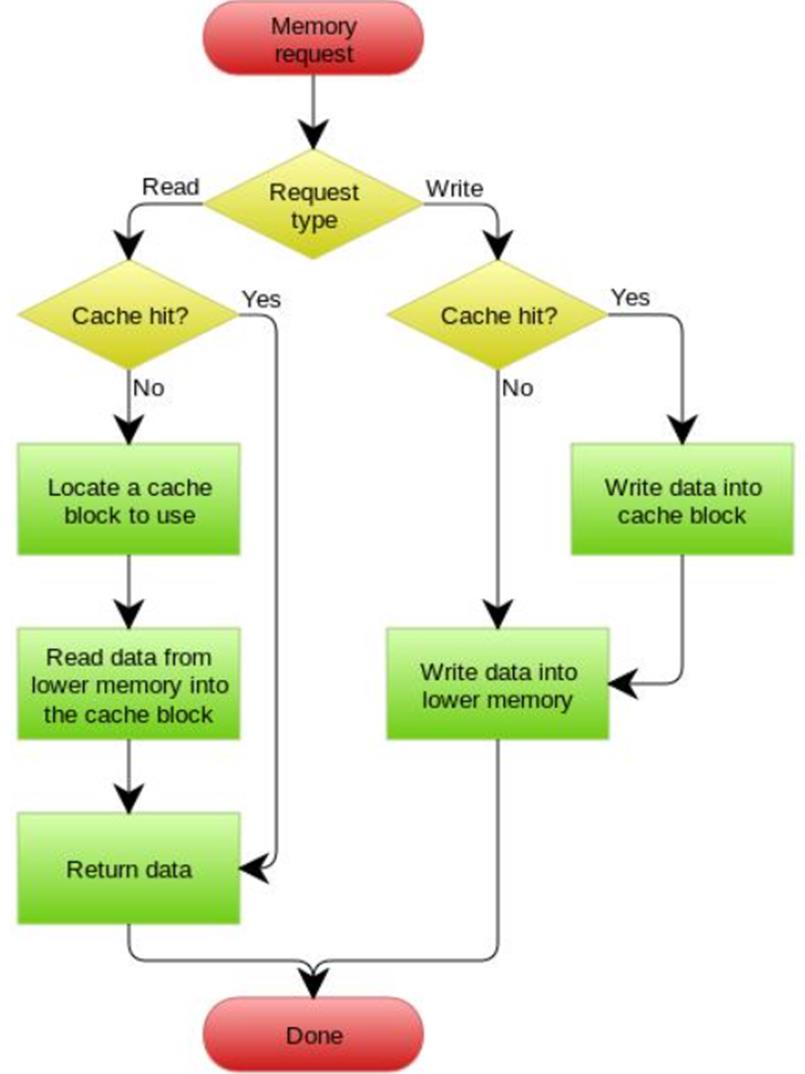
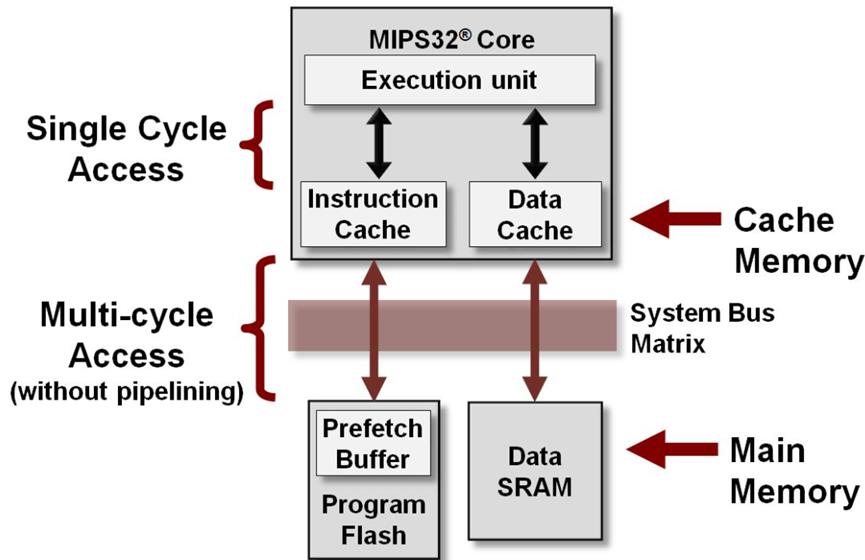
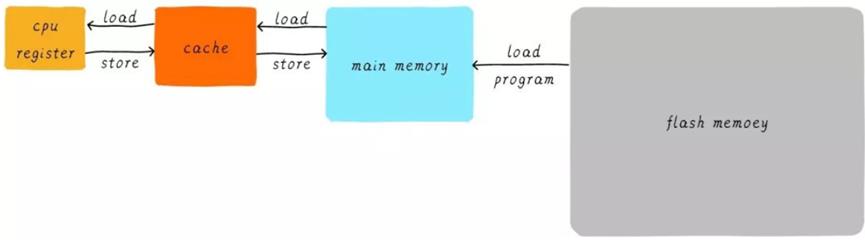
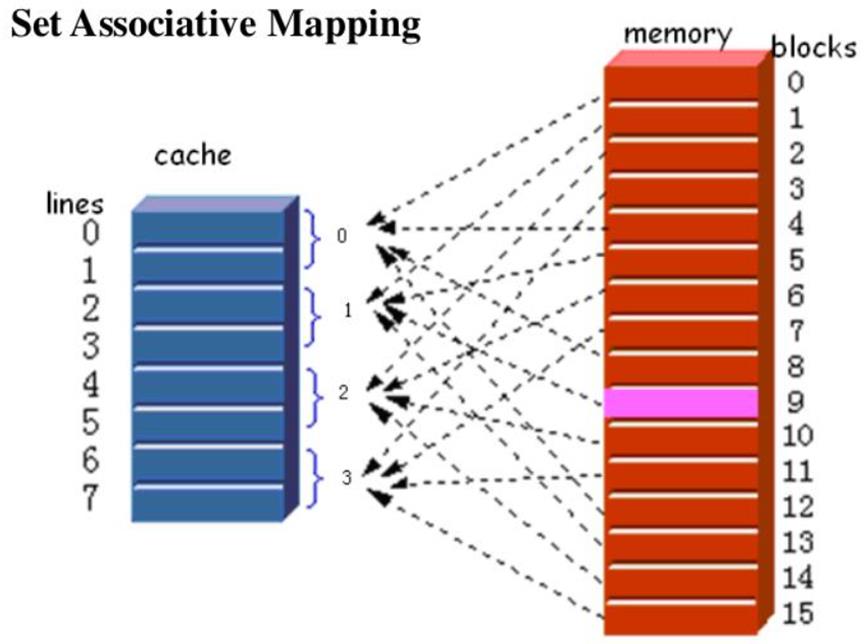
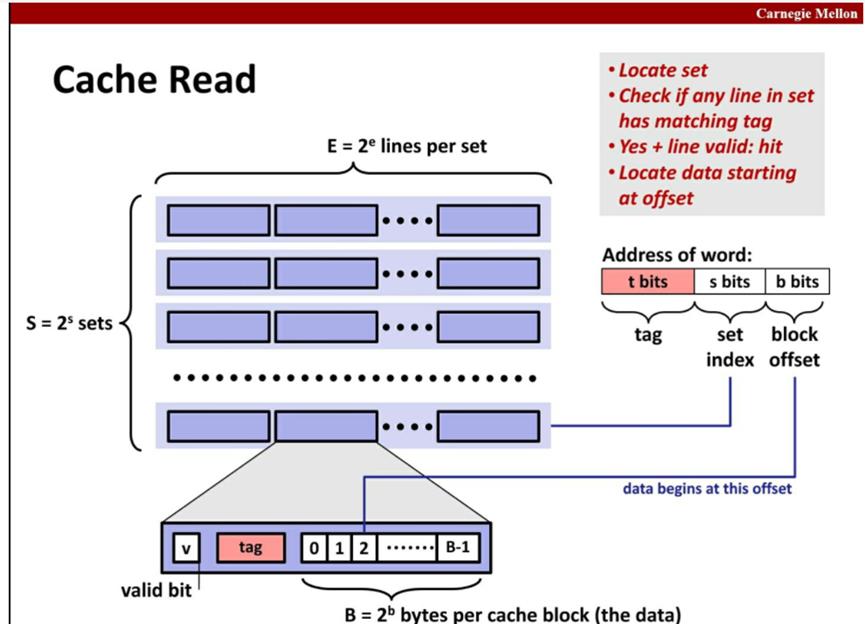
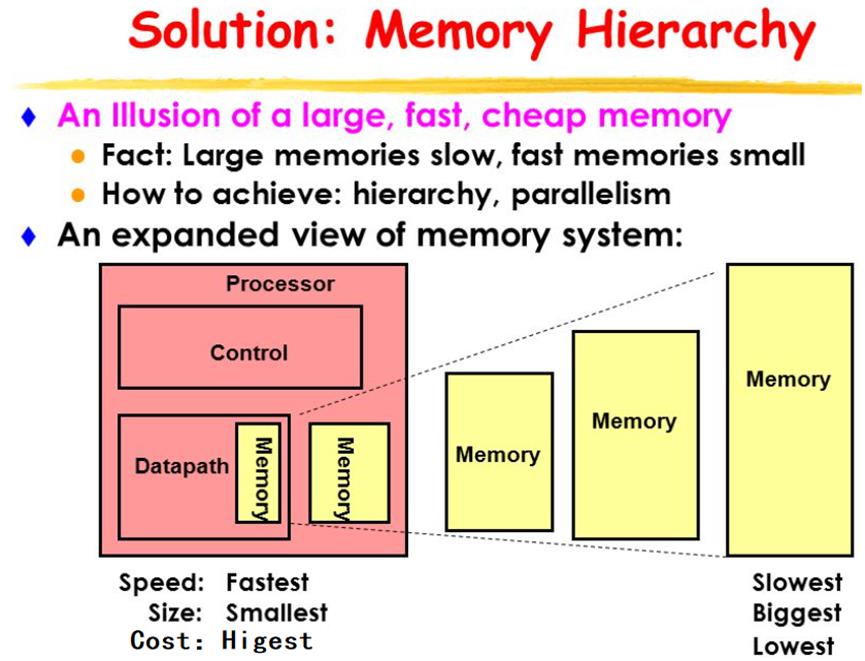
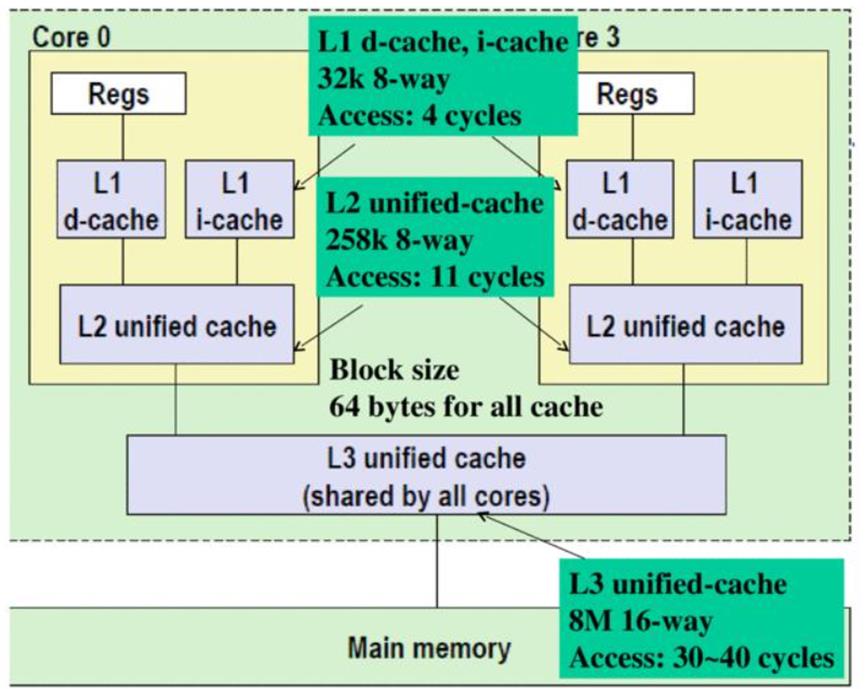
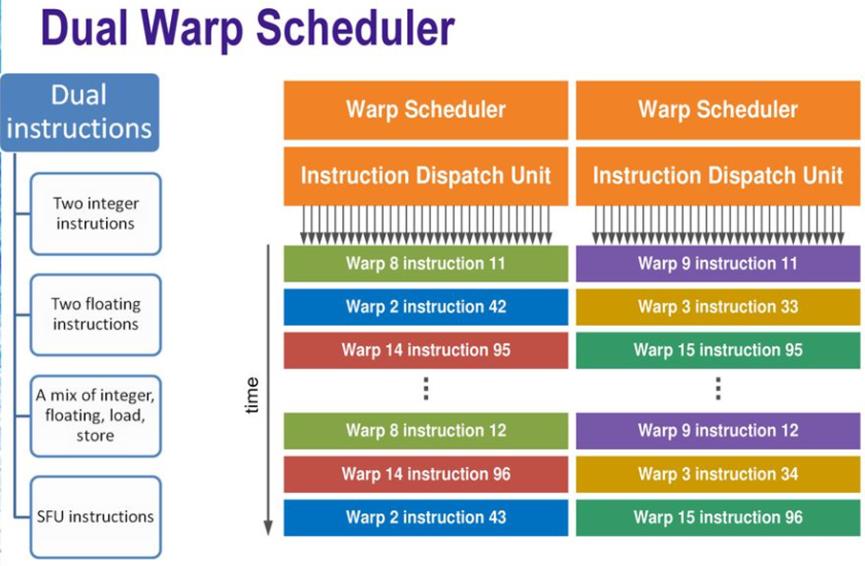
Memory杂谈(DRAM,SRAM)
一个正常的40nm工艺,一个6T(6 transistors)的SRAM面积是150*0.04*0.04= 0.24um2/SRAM。如果需要一个1Mb的SRAM,面积是1M*0.24um2= 0.24mm2,大概0.5mm*0.5mm。
这些熟悉memory的人,手算能力不错!
本着对强者的仰慕,Google了一下memory的rule of thumb,发现真的有这个类似的公式:来自一篇HP的文档
https://www.hpl.hp.com/techreports/2008/HPL-2008-20.pdf
第39页9.11Cell里面,有这么一句话:
For instance the embedded DRAM cells presented in [45] for four different technology nodes – 180/130/90/65nm have areas in the range of 19–26F^2,where F is the feature size of the process. In contrast,a typical SRAM cell would have an area of about 120–150F^2.
估算是差不多合理的。40nm的CMOS工艺,feature size是40nm,一个SRAM的面积大概就是120-150F^2,算的是一样的。
memory的面积居然都如此的标准!
为啥DRAM比SRAM的面积小很多呢?以前VLSI课程里,不同memory的电路图吗?复习一下。
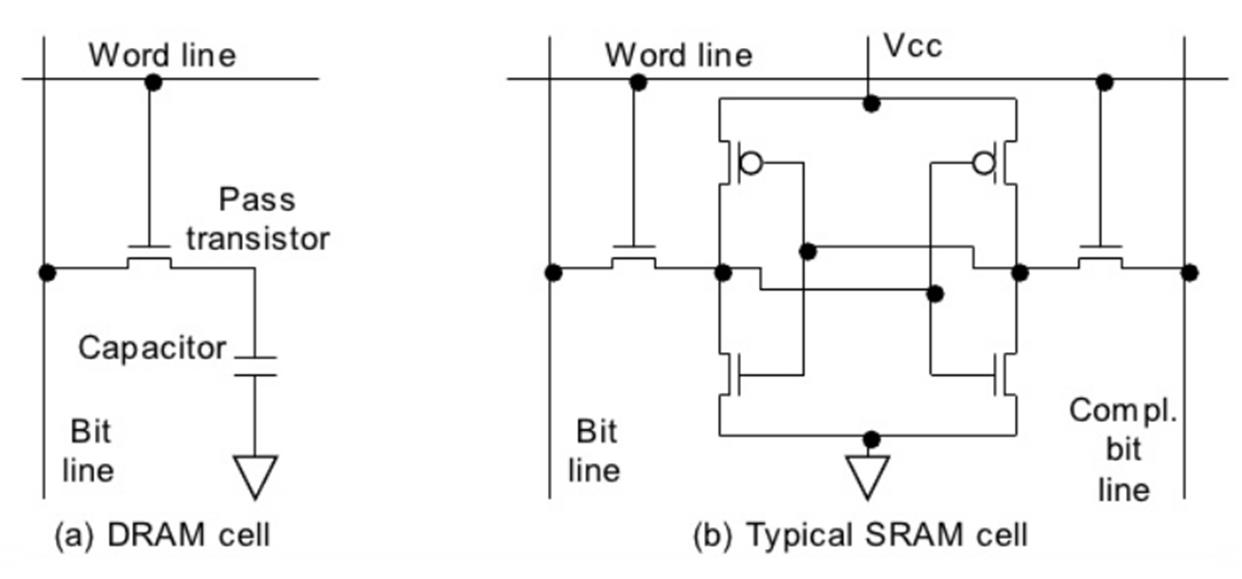
(a) DRAM ; (b) SRAM
上面这个图里,左边是一个DRAM,一个transistor加上一个capacitor,结构相当简单。右图是一个SRAM,中间是交叉连接的两个inverter,组成了一个典型的latch。(latch其实是一个digital的capacitor),左右两个transistor当做了开关,功能和左图DRAM pass transistor差不多。
memory的面积,SOC里放了一个512MB的SRAM,12nm的工艺下,面积是400mm^2.
所以尺寸是20mm*20mm。
继续Google:
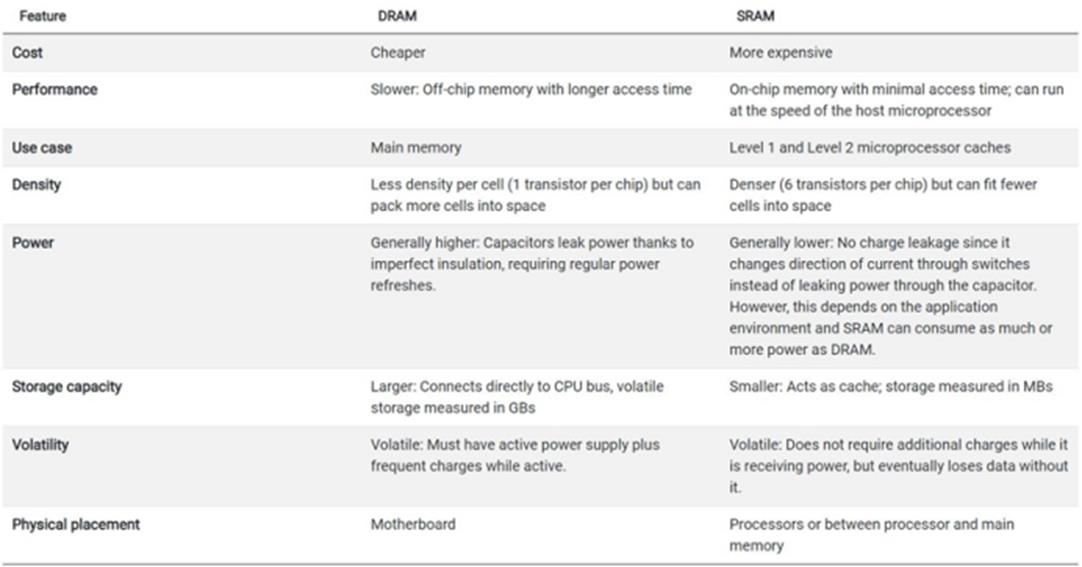
SRAM vs. DRAM in Computers
表格里CPU一般放的是SRAM,不是DRAM。SRAM用了positive feedback的latch,速度显然比类似于模拟电路(一个模拟的开关对电容充电)的DRAM要快很多。
SRAM要6个transistor,DRAM才一个transistor,面积小了很多。如果需要很大的memory,DRAM在节约SOC成本占优了。
有很特别的电容,需要一定的阈值和对抗漏电能力,DRAM的工艺,不是传统logic process,而是特别的 DRAM process。目前,基本上只有三家公司提供DRAM的工艺:美光科技、三星和 SK 海力士。
继续谈成本,Google到了下面这句话:
Logic processes - those used for CPUs - are also more expensive. A logic wafer might cost $3500 vs $1600 for DRAM. Intel\'s logic wafers may cost as much $5k. That\'s costly real estate.
因为SRAM的成本压力,CPU上不会集成大的DRAM,而是把DRAM放在片外。CPU的内部,一般也只有SRAM作为cache,不是主要的memory。
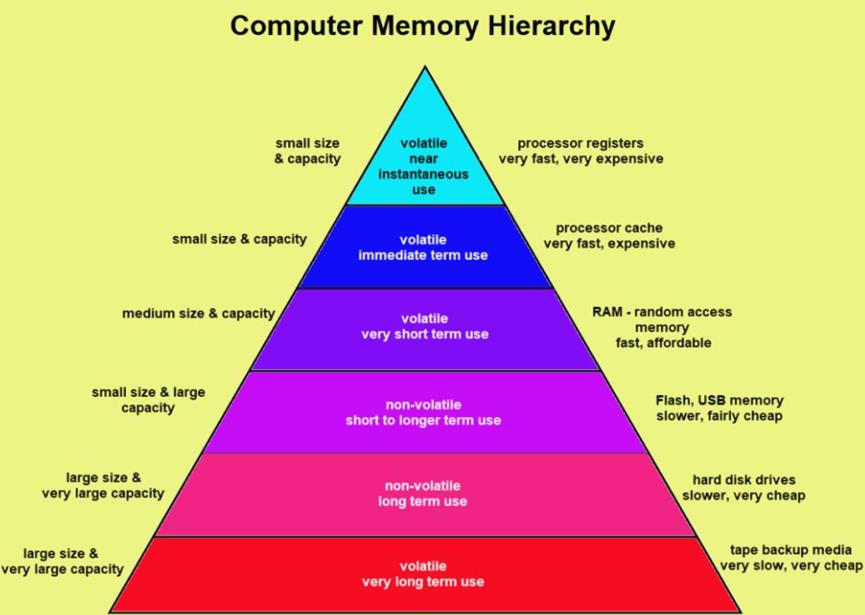
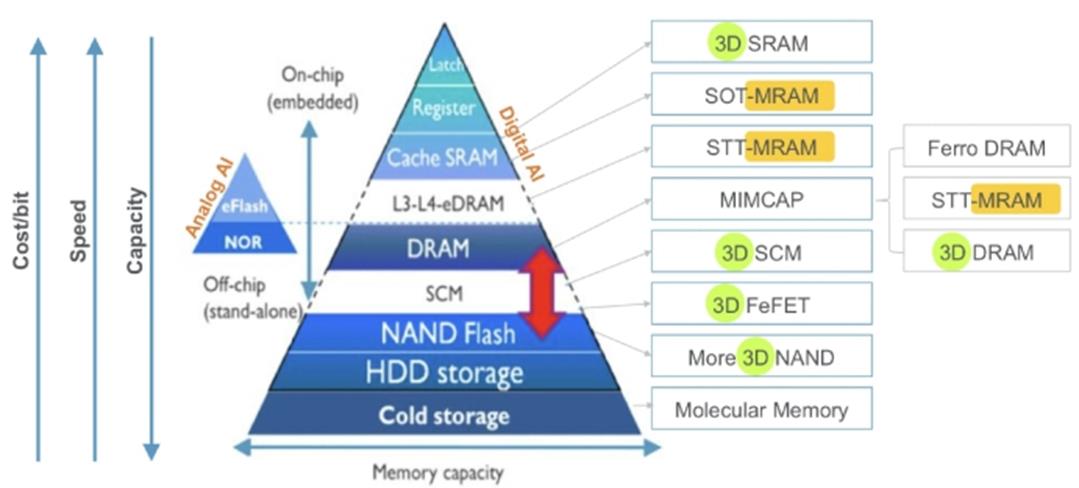
还有一种所谓的Memory Hierarchy。类似金字塔形状的结构,最大程度的优化速度和成本。可以去搜一下不同类型的memory。
最后,谈到CPU和GPU的区别。有一张特别出名的图片:

看CPU和GPU的结构对比。再加深一下对DRAM和SRAM的区分,这张图很能说明一些东西。比如,CPU里面,cache是SRAM,占了相当多的面积,在GPU里面,由于交互信息,不如内部运算的负担大,大部分面积都做基本的计算了。在chip的成本类似的情况下(主要是die area大小差不多的情况),GPU的架构跟CPU还是很不一样的。
看layout,有几层layer的名字跟“SRAM”有关。按照foundry的文档,如果在layout里,加上了layer,运行DRC时,各种rule的要求都会减小,比如,metal间距,从70nm减小到60nm……相关工艺,查阅foundry的design manual。
参考资料
https://zhuanlan.zhihu.com/p/146094598
https://www.zhihu.com/question/285202403/answer/444253962
CPU,GPU,Memory调度

图1. HDD&Memory&CPU调度图
CPU主要就是三部分:计算单元、控制单元和存储单元,其架构如下图所示:
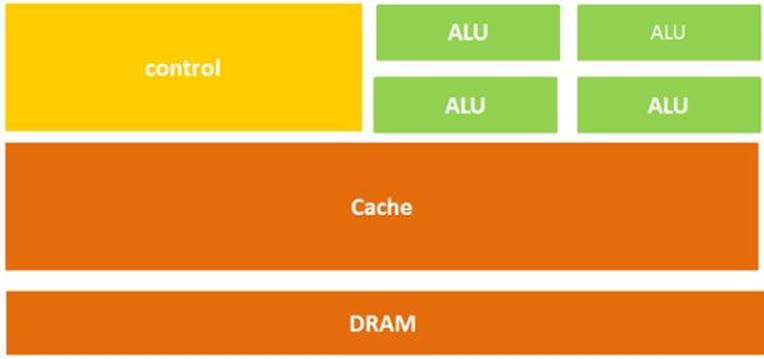
图2. CPU微架构示意图
换一种CPU表示方法:

图3. CPU微架构示意图
从字面上,也很容易理解,上面的计算单元主要执行计算机的算术运算、移位等操作以及地址运算和转换;而存储单元主要用于保存计算机在运算中产生的数据以及指令等;控制单元则对计算机发出的指令进行译码,并且还要发出为完成每条指令所要执行的各个操作的控制信号。
所以在CPU中执行一条指令的过程基本是这样的:指令被读取到后,通过控制器(黄色区域)进行译码被送到总线的指令,并会发出相应的操作控制信号;然后通过运算器(绿色区域),按照操作指令对输入的数据进行计算,并通过数据总线,将得到的数据存入数据缓存器(大块橙色区域)。过程如下图所示:
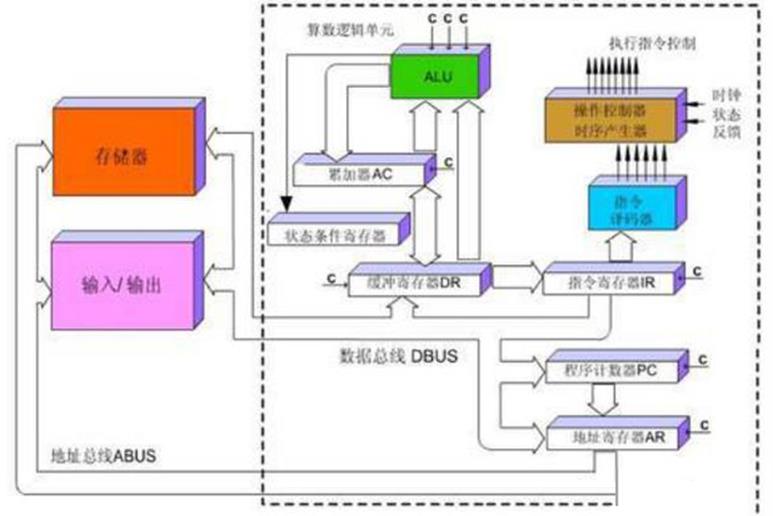
图4. CPU执行指令图
CPU遵循的是冯诺依曼架构,其核心就是:存储计算程序,按照顺序执行。
在上面的这个结构图中,负责计算的绿色区域占的面积似乎太小了,而橙色区域的缓存Cache和黄色区域的控制单元占据了大量空间。
结构决定性质,CPU的架构中需要大量的空间去放置存储单元(橙色部分)和控制单元(黄色部分),相比之下计算单元(绿色部分)只占据了很小的一部分,所以,在大规模并行计算能力上极受限制,而更擅长于逻辑控制。
另外,因为遵循冯诺依曼架构(存储程序,顺序执行),CPU就像是个一板一眼的管家,总是一步一步来做,当做完一件事情才会去做另一件事情,从不会同时做几件事情。但是随着社会的发展,大数据和人工智能时代的来临,对更大规模与更快处理速度的需求急速增加,这位管家渐渐变得有些力不从心。
能不能把多个处理器都放在同一块芯片上,一起来做事,相当于有了多位管家,这样效率不就提高了吗?
GPU便由此而诞生了。
GPU
并行计算
并行计算(Parallel Computing),指同时使用多种计算资源解决计算问题的过程,提高计算机系统计算速度和数据处理能力的一种有效手段。基本思想是用多个处理器来共同求解同一个问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算完成。
并行计算可分为时间上的并行和空间上的并行。
时间上的并行是指流水线技术,比如说工厂生产食品的时候分为四步:清洗-消毒-切割-包装。
如果不采用流水线,一个食品完成上述四个步骤后,下一个食品才进行处理,耗时且影响效率。但是采用流水线技术,就可以同时处理四个食品。这就是并行算法中的时间并行,在同一时间启动两个,或两个以上的操作,大大提高计算性能。
空间上的并行是指多个处理机并发的执行计算,即通过网络将两个以上的处理机连接起来,达到同时计算同一个任务的不同部分,或者单个处理机无法解决的大型问题。
为了解决CPU在大规模并行运算中遇到的困难, GPU应运而生,GPU全称为Graphics Processing Unit,中文为图形处理器,GPU最初是用在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上运行绘图运算工作的微处理器。
GPU采用数量众多的计算单元和超长的流水线,善于处理图像领域的运算加速。但GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。近年来,人工智能的兴起主要依赖于大数据的发展、算法模型的完善和硬件计算能力的提升。其中,硬件的发展归功于GPU的出现。
为什么GPU特别擅长处理图像数据呢?这是因为图像上的每一个像素点,都有被处理的需要,而且,每个像素点处理的过程和方式都十分相似,也就成了GPU的天然温床。
GPU简单架构如下图所示:
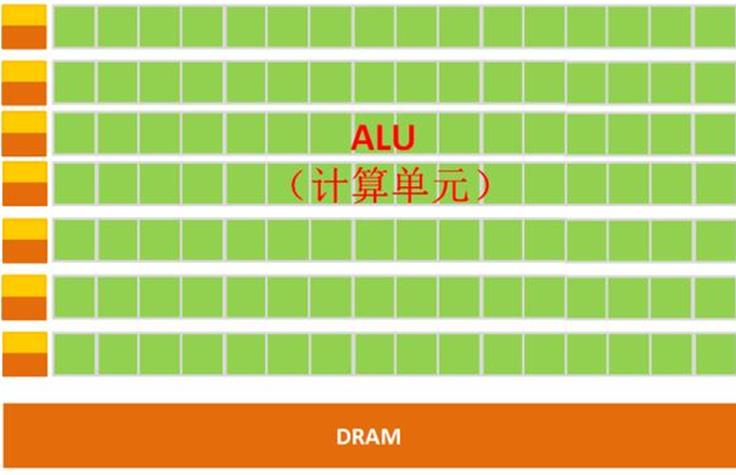
图5. GPU微架构示意图
GPU的构成相对简单,有数量众多的计算单元和超长的流水线,特别适合处理大量的类型统一的数据。
但GPU无法单独工作,必须由CPU进行控制调用才能工作。CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要大量的处理类型统一的数据时,则可调用GPU进行并行计算。
注:GPU中有很多的运算器ALU和很少的缓存cache,缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为线程thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram。
再把CPU和GPU两者放在一张图上看下对比,就非常一目了然了。
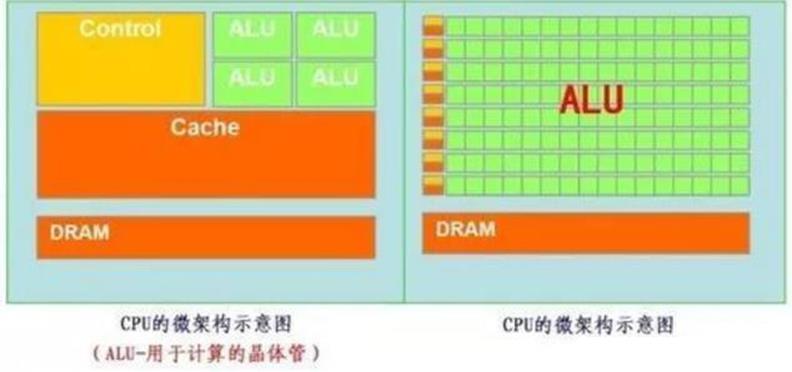
图6. CPU微架构
GPU的工作大部分都计算量大,但没什么技术含量,而且要重复很多很多次。
有个工作需要计算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分,反正这些计算也没什么技术含量,纯粹体力活而已;而CPU就像老教授,积分微分都会算,就是工资高,一个老教授能顶二十个小学生,要是富士康,雇哪个?
GPU就是用很多简单的计算单元去完成大量的计算任务,纯粹的人海战术。这种策略基于一个前提,就是小学生A和小学生B的工作没有什么依赖性,是互相独立的。
但有一点需要强调,虽然GPU是为了图像处理而生的,但是,通过前面的介绍可以发现,它在结构上并没有专门为图像服务的部件,只是对CPU的结构进行了优化与调整,所以,现在GPU不仅可以在图像处理领域大显身手,还被用来科学计算、密码破解、数值分析,海量数据处理(排序,Map-Reduce等),金融分析等需要大规模并行计算的领域。
所以,GPU也可以认为是一种较通用的芯片。
TPU
CPU和GPU都是较为通用的芯片:万能工具的效率永远比不上专用工具。
随着计算需求越来越专业化,希望有芯片可以更加符合自己的专业需求,这时,便产生了ASIC(专用集成电路)的概念。
ASIC是指依产品需求不同而定制化的,特殊规格集成电路,由特定使用者要求和特定电子系统的需要而设计、制造。简单来说,就是定制化芯片。
因为ASIC很“专一”,只做一件事,所以,就会比CPU、GPU等能做很多件事的芯片,在某件事上做的更好,实现更高的处理速度和更低的能耗。但相应的,ASIC的生产成本也非常高。
TPU(Tensor Processing Unit,张量处理器),就是谷歌专门为加速深层神经网络运算能力,研发的一款芯片,其实也是一款ASIC。
人工智能旨,在为机器赋予人的智能,机器学习是实现人工智能的强有力方法。所谓机器学习,即研究如何让计算机自动学习的学科。TPU就是这样一款专用于机器学习的芯片,Google于2016年5月提出的一个针对Tensorflow平台的可编程AI加速器,其内部的指令集在Tensorflow程序变化,或者更新算法时,也可以运行。TPU可以提供高吞吐量的低精度计算,用于模型的前向运算而不是模型训练,且能效(TOPS/w)更高。在Google内部,CPU,GPU,TPU均获得了一定的应用,相比GPU,TPU更加类似于DSP,尽管计算能力略有逊色,但是,其大大降低,计算速度非常的快。然而,TPU,GPU的应用都要受到CPU的控制。
一般公司很难承担为深度学习开发专门ASIC芯片的成本和风险的。
谷歌提供的很多服务,包括谷歌图像搜索、谷歌照片、谷歌云视觉API、谷歌翻译等产品和服务都需要用到深度神经网络。基于谷歌自身庞大的体量,开发一种专门的芯片开始具备规模化应用(大量分摊研发成本)的可能。
如此看来,TPU登上历史舞台也顺理成章了。
原来很多的机器学习以及图像处理算法大部分都跑在GPU与FPGA(半定制化芯片)上面,但这两种芯片都还是一种通用性芯片,所以在效能与功耗上还是不能更紧密的适配机器学习算法,而且Google一直坚信伟大的软件将在伟大的硬件的帮助下更加大放异彩,所以Google便想,我们可不可以做出一款专用机机器学习算法的专用芯片,TPU便诞生了。
据称,TPU与同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。初代的TPU只能做推理,要依靠Google云实时收集数据并产生结果,而训练过程还需要额外的资源;而第二代TPU既可以用于训练神经网络,又可以用于推理。
为什么TPU会在性能上这么牛逼呢?TPU是怎么做到如此之快呢?
(1)深度学习的定制化研发:TPU 是谷歌专门为加速深层神经网络运算能力而研发的一款芯片,其实也是一款 ASIC(专用集成电路)。
(2)大规模片上内存:TPU 在芯片上使用了高达 24MB 的局部内存,6MB 的累加器内存,以及用于与主控处理器进行对接的内存。
(3)低精度 (8-bit) 计算:TPU 的高性能还来源于对于低运算精度的容忍,TPU 采用了 8-bit 的低精度运算,也就是说,每一步操作 TPU 将会需要更少的晶体管。
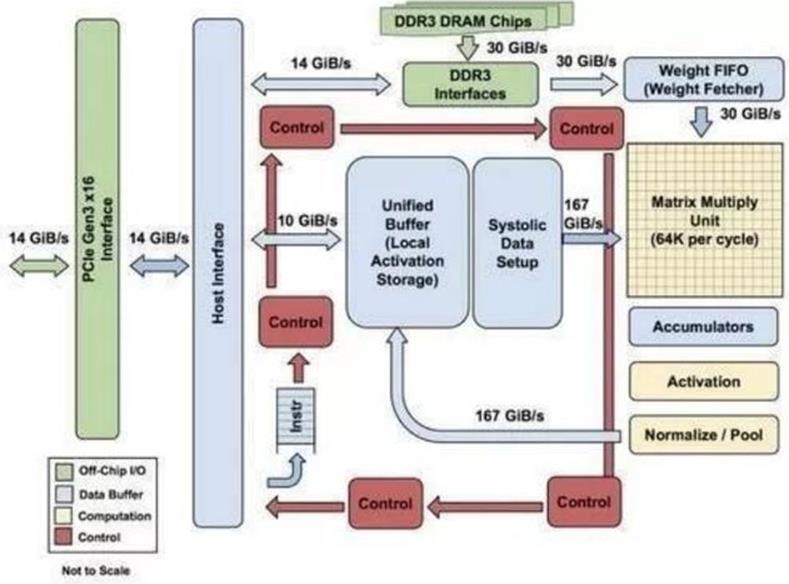
图7. TPU 各模块的框图
TPU在芯片上使用了高达24MB的局部内存,6MB的累加器内存以及用于与主控处理器进行对接的内存,总共占芯片面积的37%。
这表示谷歌充分意识到了片外内存访问是GPU能效比低的罪魁祸首,因此不惜成本的在芯片上放了巨大的内存。相比之下,英伟达同时期的K80只有8MB的片上内存,因此需要不断地去访问片外DRAM。
另外,TPU的高性能还来源于对于低运算精度的容忍。研究结果表明,低精度运算带来的算法准确率损失很小,但是在硬件实现上却可以带来巨大的便利,包括功耗更低、速度更快、占芯片面积更小的运算单元、更小的内存带宽需求等...TPU采用了8比特的低精度运算。
参考链接:
https://images2015.cnblogs.com/blog/430057/201511/430057-20151102143747180-1940496572.jpg
{kind=link}
https://baijiahao.baidu.com/s?id=1706639922409916892&wfr=spider&for=pc
NPU-HiTOC Architecture
* Compared with last version, we update the DRAM parameters to the F38 technology version
- 1. General input
a) Application context
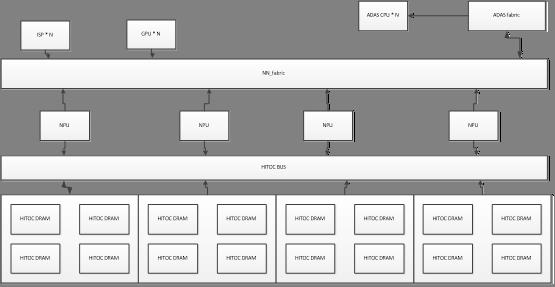
Program (instruction): possible in external DDR
ISP data: direct from ISP and output to HITOC DRAM
GPU data: locate in HIToC
b) Number of HiTOC DRAM units
Taking sunrise project 32*32 = 256 units
The unit parameters:
Each unit: raw addr RA[10:0], col addr CA[6:0], NO BA addr;
Page size 2K words, 256Kbit=64Kbyte per page
Column number 64(2)
Read/write port bitwidth: 128bit, 16 byte
Total unit size: 64*2K*128 = 16Mbit = 2Mbyte
Max readout frequency: 500MHz
tRAS: > 16 cycle@500MHz
tCL: >3 cycle@500MHz
rRP: >3 cycle@500MHz
c) Number of NPU core
Option 1:
Taking sunrise project, assume building NPU core inside IPU. Therefore the number of NPU is equal to the number of IPU.
Advantage: low latency in the wiring of NPU-HiTOC, increasing MAC frequency
Disadvantage: Not flexible, NPU can only designed near IPU. When the IPU utilization is low, the related NPU can not be used for other occupied HiTOC.
Option 2:
Connect HiTOC DRAM cluster controller on the NN_fabric, and also connect NPU cores with NN_fabric.
Advantage: Flexible, NPU number and location can be optimized after simulation.
Disadvantage: increase latency in the wiring of NPU-HiTOC, drop MAC frequency. Need effort to design bandwidth flow in the fabric, esp. using NOC router technologies.
d) Data input
General CNN input format:
NCHW, feature line first
NHWC, feature channel first
Variable definition: 4D Tensor type
- 2. Design target and performance evaluation
NPU/GPU/ISP can work coordinately
Overall CNN performance:
Computation efficiency = clock utilization * MAC utilization
Low power consumption:
Normally power is with the wiring density, and the working frequency
Optimal frequency:
Could be a trade-off between NPU/ISP/GPU wiring and HiTOC DRAM controller
Computation density:
MACs per mm2 wafer
- 3. Proposal for the architecture
3.1 Proposed architecture
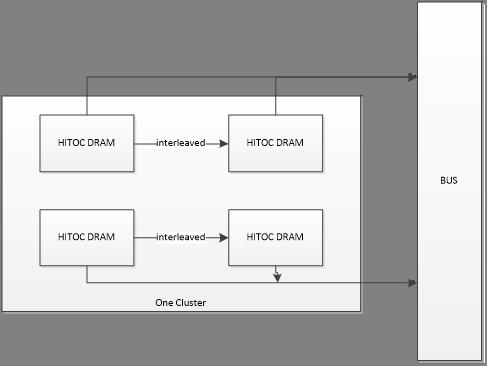
3.2 Group HITOC DRAM into one cluster
3.2.1 The considerations to have best benifit
Two technical skills can be applied in the grouping HITOC DRAMs
Interleaving units into one bigger unit, that will increase bandwidth
Sequentially addressing two units into one bigger unit, that will enable pages in different bank can be closed and opened independently.
Page number opened at one time determines how many program threads are accessing data in the cluster.
1) If considering ISP/NPU/GPU working as reading/writing data at one time, maximum 6 pages should be opened, therefore 6 independent banks is grouped in one cluster.
2) If considering only NPU working for reading and writing, 2 pages should be opened, 2 independent banks are grouped.
3) Minimum two pages is working at same time. Minimum two banks are grouped
The best approach should be optimized by simulation.
3.2.2 An proposal for grouping
At moment we just group 4 units into one cluster by the following style:
1) Group each two units into one interleaved unit, in order to double the output
2) Group two interleaved banks into one cluster, in order to leverage page conflict being minimized
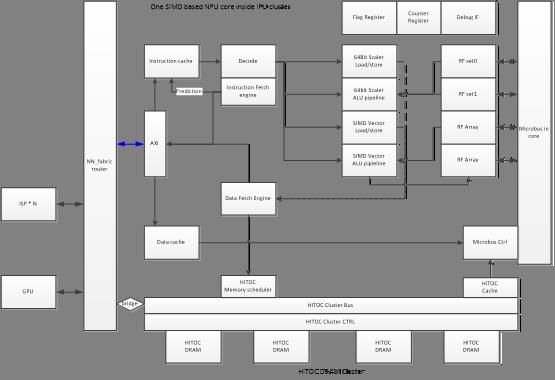
3.3 SIMD based NPU structure
The CNN computation behaves less computation types (MAC taking 90% calculation), high throughout. Therefore using SIMD to save instructions and repeating the similar computation.
All the CNN MAC computation can be partitioned into array computation.
SIMD length will be studied for the best ratio between computation and access time.
3.4 Buffering approach for the MAC computation
Depending on different parameters and types of input data NCHW or NHWC, using input buffering by RF array, or output buffering by RF array could be optimized in the programs and instructions.
- 4. Data structure, partition, and mapping guide
Data type for the computation:
1) Scalar
2) Array
3) 3D tensor
4) 4D tensor
Mapping and shuffling data instruction should be prepared:
To be defined later
- Parameter tuning and emulator
- Operation principle guide
- Place and routing guide
- NPU detail design guide
- System design guide
- Software and tool chain guide
以上是关于Cache 与Memory架构及数据交互的主要内容,如果未能解决你的问题,请参考以下文章