02-Hadoop集群搭建
Posted ◥(ฅºωºฅ)◤
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了02-Hadoop集群搭建相关的知识,希望对你有一定的参考价值。
1. 集群配置
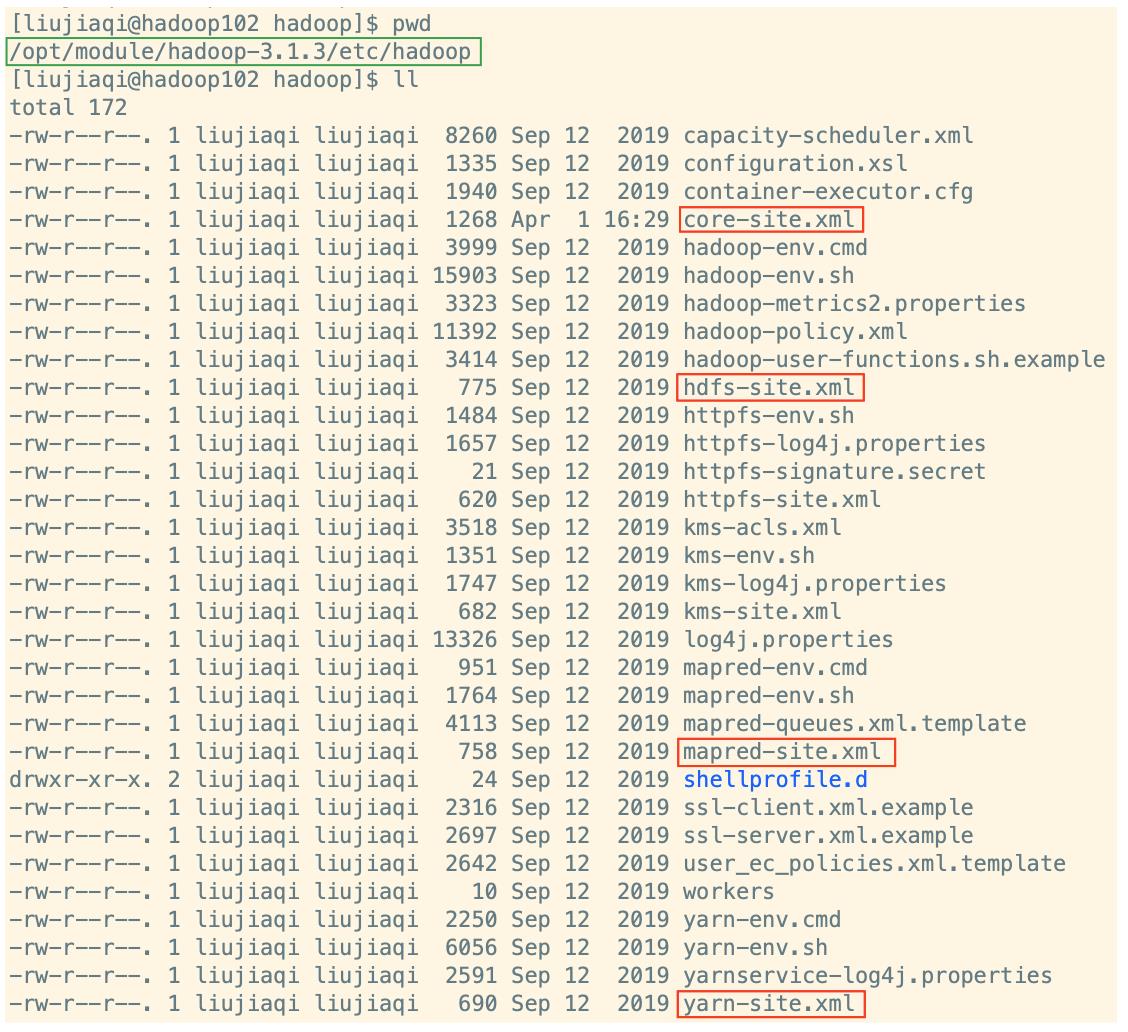
1.1 集群部署规划
- 资源上有抢夺冲突的,尽量不要部署在一起;
- 工作上需要互相配合的,尽量部署在一起。
| \\ | Hadoop102 | Hadoop103 | Hadoop104 |
|---|---|---|---|
| HDFS | NameNode & DataNode | DataNode | 2rdNameNode & DataNode |
| YARN | NodeManager | ResourceManager & NodeManager | NodeManager |
- NameNode 和 SecondaryNameNode 不要安装在同一台服务器;
- ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在同一台机器上。
1.2 安装包目录结构
| 目录 | 说明 |
|---|---|
| bin | Hadoop 最基本的管理脚本和使用脚本的目录,这些脚本是 sbin 目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用 Hadoop。 |
| etc | Hadoop 配置文件所在的目录 |
| include | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是用 C++ 定义的,通常用于 C++ 程序访问 HDFS 或编写 MapReduce 程序。 |
| lib | 该目录包含了 Hadoop 对外提供的编程动态库和静态库,与 include 目录中的头文件结合使用。 |
| libexec | 各个服务对用的 shell 配置文件所在的目录,可用于配置日志输出、启动参数(比如 JVM 参数)等基本信息。 |
| sbin | Hadoop 管理脚本所在的目录,主要包含 HDFS 和 YARN 中各类服务的启动/关闭脚本。 |
| share | Hadoop 各个模块编译后的 jar 包所在的目录,官方自带示例。 |
1.3 修改配置文件
Hadoop 配置文件分两类:默认配置文件和自定义配置文件。
(1)默认配置文件
| 文件名 | 存放位置 |
|---|---|
| core-default.xml | hadoop-common-3.1.3.jar/core-default.xml |
| hdfs-default.xml | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| mapred-default.xml | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
(2)自定义配置文件
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个配置文件存放在 $HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置。
a. core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为tree6x7 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>tree6x7</value>
</property>
</configuration>
b. hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
c. yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 解决 Yarn 在执行程序遇到超出虚拟内存限制 Container 被 kill -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
d. mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改后的文件分发到 hadoop103 和 hadoop104 上。
2. 启动集群
2.1 配置 workers
vim $HADOOP_HOME/etc/hadoop/workers
注意该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
hadoop102
hadoop103
hadoop104
将 workers 同步到其他节点上。
2.2 启动集群
(1)如果集群是第一次启动,需要在 hadoop102 节点格式化 NameNode。
[liujiaqi@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
(2)启动 HDFS
[liujiaqi@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
(3)在配置了 ResourceManager 的节点(hadoop103)上启动 YARN
[liujiaqi@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
(4)通过 jps 查看启动情况
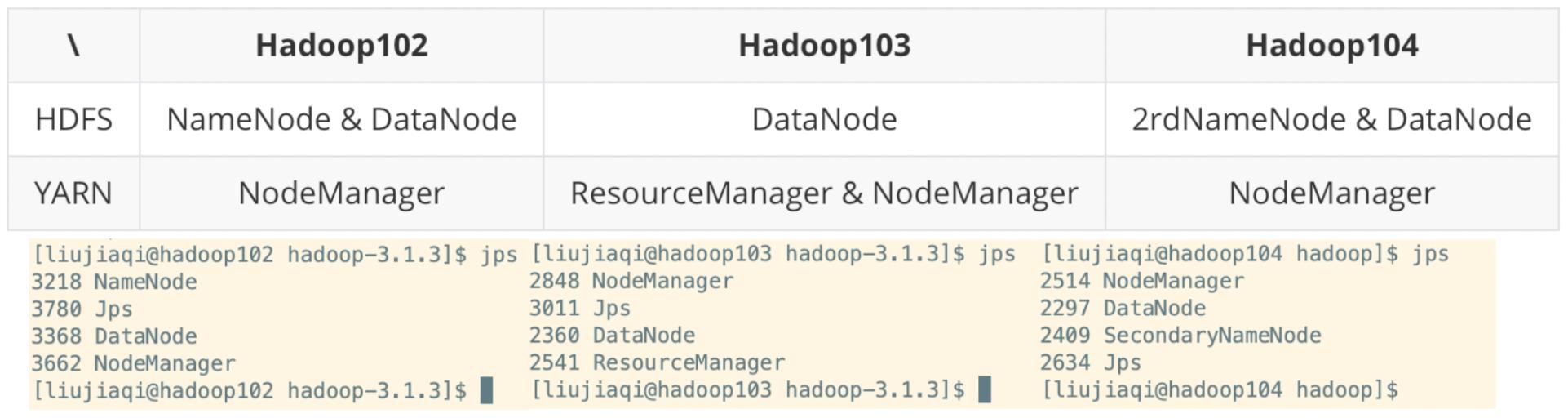
(5)Web 端查看 HDFS 的 NameNode
- 浏览器中输入:http://hadoop102:9870
- 查看 HDFS 上存储的数据信息
(6)Web 端查看 YARN 的 ResourceManager
- 浏览器中输入:http://hadoop103:8088
- 查看 YARN 上运行的 Job 信息
3. 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
(1)在 mapred-site.xml 里增加如下配置,并同步到其他节点;
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
(2)在 hadoop102 启动历史服务器
mapred --daemon start historyserver
(3)查看 JobHistory http://hadoop102:19888/jobhistory
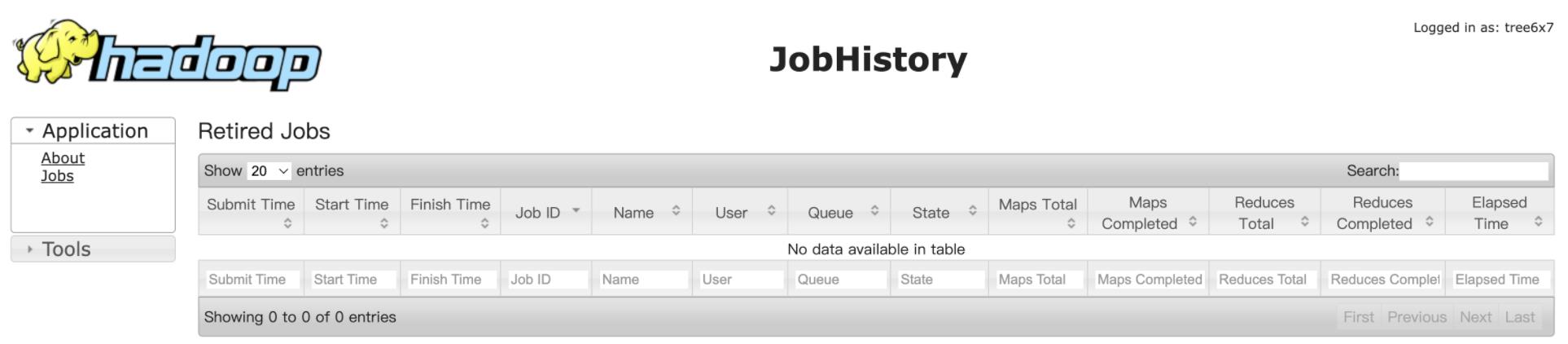
4. 配置日志聚集
日志聚集:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。
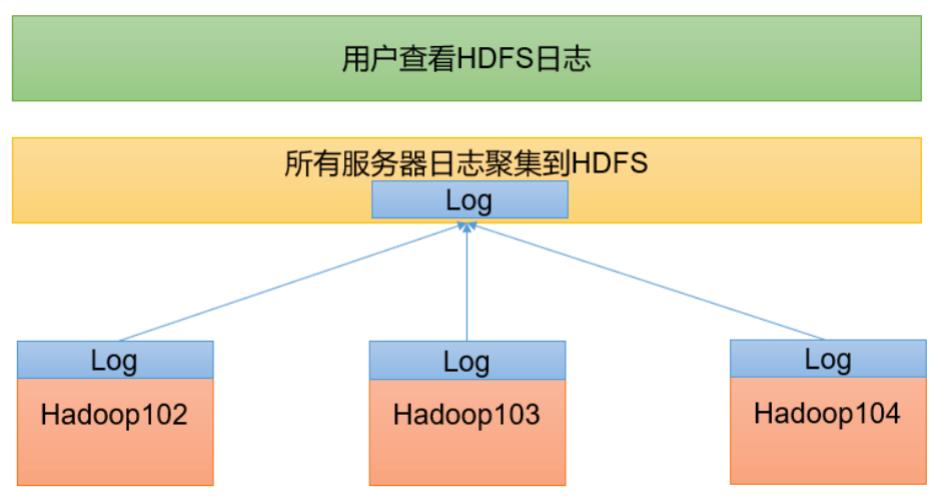
日志聚集功能可以方便的查看到程序运行详情,方便开发调试。
开启日志聚集功能具体步骤如下:
(1)配置 yarn-site.xml,并分发到其他节点;
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
(2)关闭 NodeManager 、ResourceManager 和 HistoryServer
[liujiaqi@hadoop102 hadoop-3.1.3]$ mapred --daemon stop historyserver
[liujiaqi@hadoop103 hadoop-3.1.3]$ ./sbin/stop-yarn.sh
(3)启动 NodeManager 、ResourceManage 和 HistoryServer
[liujiaqi@hadoop102 hadoop-3.1.3]$ mapred --daemon start historyserver
[liujiaqi@hadoop103 hadoop-3.1.3]$ ./sbin/start-yarn.sh
5. 集群启停方式
5.1 原生方式
各个模块分开启动/停止(配置 ssh 是前提):
- 整体启动/停止 HDFS:start-dfs.sh/stop-dfs.sh
- 整体启动/停止 YARN:start-yarn.sh/stop-yarn.sh
各个服务组件逐一启动/停止:
- 分别启动/停止 HDFS:
hdfs --daemon start/stop namenode/datanode/secondarynamenode - 分别启动/停止 YARN:
yarn --daemon start/stop resourcemanager/nodemanager
5.2 自定义脚本
Hadoop 集群启停脚本(包含 HDFS、Yarn、Historyserver):myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input!"
exit ;
fi
case $1 in
"start")
echo "======= Start Hadoop Cluster ======="
echo "=> Start HDFS ..."
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo "=> Start Yarn ..."
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo "=> Start Historyserver ..."
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo "======= Close Hadoop Cluster ======="
echo "=> Close Historyserver ..."
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo "=> Close Yarn ..."
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo "=> Close HDFS ... "
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error!"
;;
esac
查看三台服务器 Java 进程脚本:jpsall
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo ">>>>>>>>>> $host <<<<<<<<<<"
ssh $host jps
done
6. 集群时间同步
- 如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期和公网时间进行校准;
- 如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行任务时间不同步。
【需求】找一个机器作为时间服务器,所有的机器与这台集群时间进行定时的同步,生产环境根据任务对时间的准确程度要求周期同步。测试环境为了尽快看到效果,采用 1 分钟同步一次。
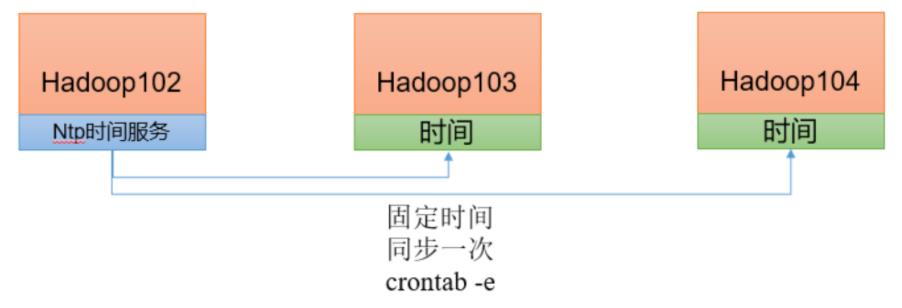
6.1 时间服务器配置
必须 root 用户
(1)查看 hadoop102 的 ntpd 服务状态和开机自启动状态
[root@hadoop102 bin]# su
[root@hadoop102 bin]# yum -y install ntp
[root@hadoop102 bin]# systemctl status ntpd
[root@hadoop102 bin]# systemctl start ntpd
[root@hadoop102 bin]# systemctl is-enabled ntpd
(2)修改 hadoop102 的 /etc/ntp.conf
# 1. 打开这行,授权 192.168.6.0-192.168.6.255 网段上的所有机器可以从这台机器上查询和同步时间;
# Hosts on local network are less restricted.
restrict 192.168.6.0 mask 255.255.255.0 nomodify notrap
# 2. 注掉下面这几行,集群在局域网中,不使用其他互联网上的时间;
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
# server 0.centos.pool.ntp.org iburst
# server 1.centos.pool.ntp.org iburst
# server 2.centos.pool.ntp.org iburst
# server 3.centos.pool.ntp.org iburst
# 3. 追加如下内容
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改 hadoop102 的 /etc/sysconfig/ntpd 文件
# 让硬件时间与系统时间一起同步
SYNC_HWCLOCK=yes
(4)重新启动 ntpd 服务 sudo systemctl enable ntpd
(5)设置 ntpd 服务开机启动 systemctl enable ntpd
6.2 其他服务器配置
(1)关闭所有节点上 ntp 服务和自启动;
(2)在其他机器配置 1 分钟与时间服务器同步一次;
[liujiaqi@hadoop103 ~]$sudo crontab -e
*/1 * * * * /usr/sbin/ntpdate hadoop102
(3)修改任意机器时间 date -s "2021-9-11 11:11:11";
(4)1 分钟后查看机器是否与时间服务器同步 date
7. 补充
7.1 常用端口号说明
| 端口说明 | Hadoop2.x | hadoop3.x |
|---|---|---|
| NameNode 内部通信端口 | 8020 / 9000 | 8020 / 9000 / 9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce 查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
7.2 常见错误及解决方案
DataNode 和 NameNode 进程同时只能有一个工作问题分析
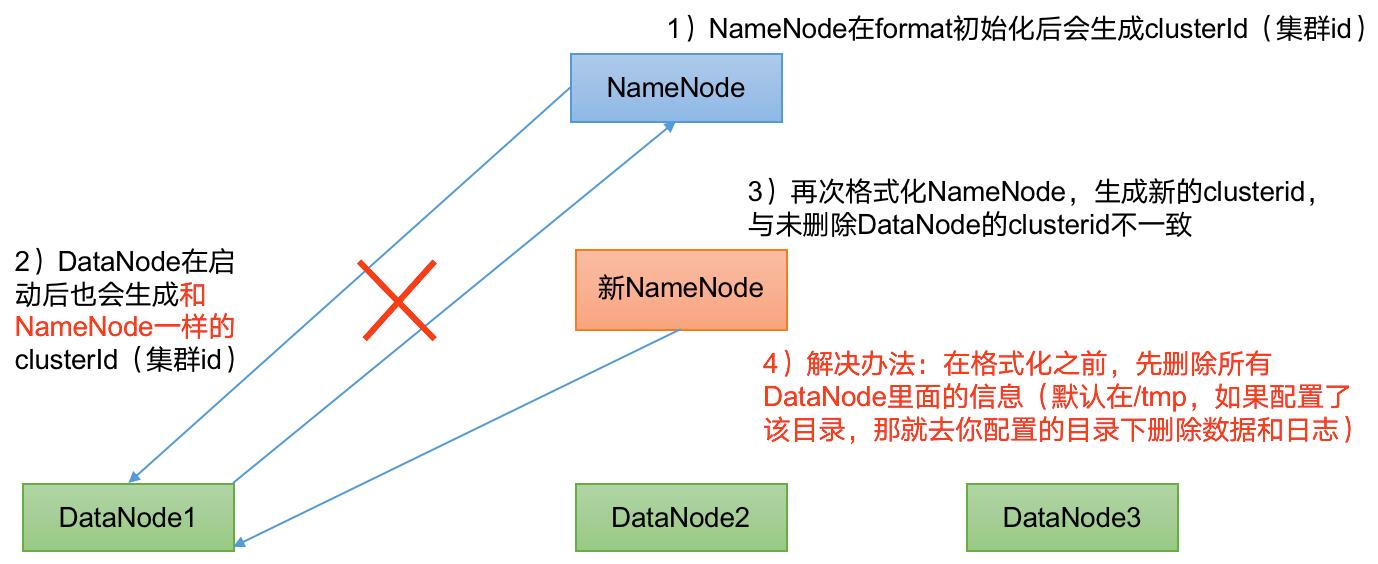
格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停止 NameNode 和 DataNode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化。
INFO client.RMProxy: Connecting to ResourceManager at hadoop10x/x.x.x.x:8032
防火墙没关或者没有启动 YARN。
以上是关于02-Hadoop集群搭建的主要内容,如果未能解决你的问题,请参考以下文章