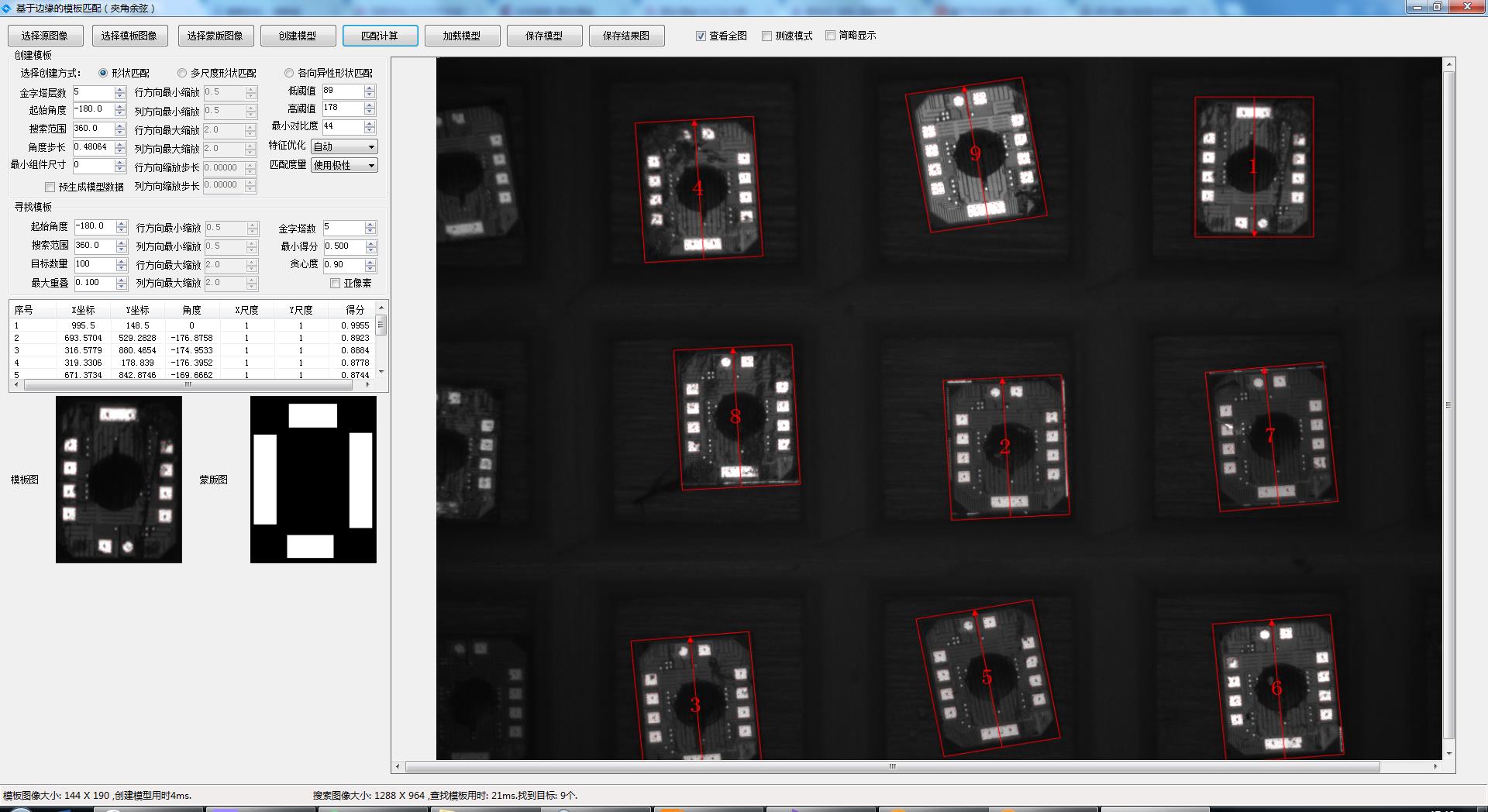
工程应用八终极的基于形状匹配方案解决(小模型+预生成模型+无效边缘去除+多尺度+各项异性+最小组件尺寸)
Posted 只(挚)爱图像处理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了工程应用八终极的基于形状匹配方案解决(小模型+预生成模型+无效边缘去除+多尺度+各项异性+最小组件尺寸)相关的知识,希望对你有一定的参考价值。
我估摸着这个应该是关于形状匹配或者模版匹配的最后一篇文章了,其实大概是2个多月前这些东西都已经弄完了,只是一直静不下来心整理文章,提醒一点,这篇文章后续可能会有多次修改(但不会重新发文章,而是在后台直接修改或者增加),所以有需要的朋友可以随时重复查看。
这次带来的更新也是革命性和带有建设性的,使得该算法向工程化更加迈进了一步。不过严格意义上说和halcon还是有较大的差距的。
能够带来这次的变化和提升,其实也得益于偶尔的一次交流,一个微信好友给我发了一份可以不用配置就可以运行的linemod的代码,因为可以运行,我就有兴趣看其代码的细节,也从中得到了更多的灵感,用于我自己的工程。从这个事情可以得出两个小经验:一个是要多交流,二是一个事情如果当前搞不定,不要一直搞,要有准备的等,说不定哪天就有意外的收获。 就好似我们掉了一个东西,怎么找都找不到,但是有可能突然某一天他就冒出来了。
好,言归正传,后续的文字也不讲究就逻辑性,想到啥说啥。
一、还是打击下linemod的速度
linemod的过程包含了原图的(被查找图,也许很大)梯度角度量化(QuantizedOrientations)、计算响应图(IM_ComputeResponseMaps)、梯度扩散等等过程,这些过程,就是使用特殊的指令集进行优化,对于稍微大一点的图来说,也是相当耗时的,所以对于快速的目标识别来说linemod应该不是很好的方法。
另外,linemod的代码里虽然有金字塔,但是他只是对特征方面用了金字塔,在旋转角度上他确没有进行下采样,也就是说,如果底层金字塔有100个旋转角度,第二层还是100个,第三个也还是100个,以此类对,而不是每层也减半的策略,这个可以从他的addTemplate含数里能看到细节。
二、从linemod中学到一些非常有用的东西。
1、创建模型时,直接旋转0角度时识别的特征作为其他角度的特征,而非旋转图像,然后在识别特征。
在前面所有的文章中,我们创建模型的时候,都是采用的先旋转模版图像,然后再计算特征,并把这些特征保存起来。这样做,可以解决问题,但是带来了两个大的麻烦:首先是创建模型的速度会有影响,特备是对于稍微大一点的模版图,耗时非常吓人。对于形状匹配来说,是有不少场景的模版图特别大的,甚至占到了被查找图的一半以上的。这种情况,早期的方案基本就不能解决问题。 第二个麻烦是,我们存储这些特征也会占用大量的内存,同样对于大模版图,存在内存不够的风险。
这个问题其实很多写模版匹配的朋友都有遇到过,而且早期我也没有好的解决方案,曾经尝试过旋转特征,不过不知道为什么当时得到的结果总是有问题。
那么在linemod里我们发现这样一段代码:
int Detector::addTemplate_rotate(const string& class_id, int zero_id, float theta, cv::Point2f center) std::vector<TemplatePyramid>& template_pyramids = class_templates[class_id]; int template_id = static_cast<int>(template_pyramids.size()); const auto& to_rotate_tp = template_pyramids[zero_id]; TemplatePyramid tp; tp.resize(pyramid_levels); for (int l = 0; l < pyramid_levels; ++l) if (l > 0) center /= 2; for (auto& f : to_rotate_tp[l].features) Point2f p; p.x = f.x + to_rotate_tp[l].tl_x; p.y = f.y + to_rotate_tp[l].tl_y; Point2f p_rot = rotatePoint(p, center, -theta / 180 * CV_PI); Feature f_new; f_new.x = int(p_rot.x + 0.5f); f_new.y = int(p_rot.y + 0.5f); f_new.theta = f.theta - theta; while (f_new.theta > 360) f_new.theta -= 360; while (f_new.theta < 0) f_new.theta += 360; f_new.label = int(f_new.theta * 16 / 360 + 0.5f); f_new.label &= 7; tp[l].features.push_back(f_new); tp[l].pyramid_level = l; cropTemplates(tp); template_pyramids.push_back(tp); return template_id;
其中rotatePoint相关函数如下:
static cv::Point2f rotate2d(const cv::Point2f inPoint, const double angRad) cv::Point2f outPoint; //CW rotation outPoint.x = std::cos(angRad) * inPoint.x - std::sin(angRad) * inPoint.y; outPoint.y = std::sin(angRad) * inPoint.x + std::cos(angRad) * inPoint.y; return outPoint; static cv::Point2f rotatePoint(const cv::Point2f inPoint, const cv::Point2f center, const double angRad) return rotate2d(inPoint - center, angRad) + center;
这个反应了一些问题。首先,linemod现在的结果似乎还比较靠谱,因此,这种直接旋转特征的方法是可行的。其次,这个代码也给我们提供了特征旋转的计算公式,主要到那些sin cos了吧。就是那些公式。注意,这里的旋转获得不仅仅是旋转后特征的坐标位置(可能需要取整),而且特征的本质属性(对于linemod,是量化到0和8之间的角度值,对于我们标准的基于梯度的计算式,则是归一化后的X和Y方向的梯度值)也同步予以获取。
我们对这个做适当的扩展。
第一,我们看到linemod的代码里这种旋转前后的特征数量是没有改变的,也就是说,如果0度模版图有1000个特征,旋转后的其他角度也会有1000个特征。这里其实有个隐藏的问题。因为一般而言,这些特征在0角度时很多的坐标是连续的,当旋转取整后,一定概率上存在取整后的两个坐标是相同的,但是可能仅仅是坐标相同,量化角度和归一化的X和Y方向梯度确不一样,这是个矛盾的东西,一个固定的位置只能有一个特征,因此,遇到这种情况,可能就要进行一定的取舍,在linemod的代码里没有见到这样的内容和处理方案。我的做法时全部旋转后,按照坐标进行一次去重的操作,至于重复的留下哪一个,那就看谁排在前面了。
第二、我们知道0度的时候的特征是有亚像素这个讲法的,也就是说0度特征的坐标位置可以是亚像素的。所以我们用0度亚像素的位置作为旋转的基础,这样可能带来的旋转特征更为准确,这就为自己实现类似于create_shape_model_xld这样的接口提供了可能性。
第三、这个旋转的方案是不带缩放的,为了支持缩放,可以在这个基础上加上X和Y方向的缩放因子,当X和Y方向的缩放因子相同时,就是多尺度匹配,当X和Y方向不相同时,即为各项异性匹配。
第四、还有个问题值得探讨,就是所有金字塔层、所有角度的特征是都由最底层0角度的模版的特征经过缩放旋转生成呢,还是由每层金字塔的0角度特征旋转生成。 个人觉得,还是由每层金字塔的0角度特征旋转生成更为合理。 毕竟这个特征比用基层的特征旋转缩放少了一个缩放,准确度及精度上应该更为靠谱。
第五、上述方案带来的最大好处时,我们不需要旋转模版图,再求这些特征了,因此,速度提升会非常明显,而且本身旋转这些特征的耗时基本可以忽略不计,甚至都可以实时计算。
第六、注意到上面的cropTemplates函数,其具体的代码如下:
static Rect cropTemplates(std::vector<Template>& templates) int min_x = std::numeric_limits<int>::max(); int min_y = std::numeric_limits<int>::max(); int max_x = std::numeric_limits<int>::min(); int max_y = std::numeric_limits<int>::min(); // First pass: find min/max feature x,y over all pyramid levels and modalities // 这里的templates.size()其实就等于金字塔的层数 for (int i = 0; i < (int)templates.size(); ++i) Template& templ = templates[i]; for (int j = 0; j < (int)templ.features.size(); ++j) // 在原始模板图像上对应的位置 int x = templ.features[j].x << templ.pyramid_level; int y = templ.features[j].y << templ.pyramid_level; min_x = std::min(min_x, x); min_y = std::min(min_y, y); max_x = std::max(max_x, x); max_y = std::max(max_y, y); // 以上代码得到了所有模板特征点在原图中的最大和最小位置 if (min_x % 2 == 1) --min_x; if (min_y % 2 == 1) --min_y; // 校正下位置 // Second pass: set width/height and shift all feature positions for (int i = 0; i < (int)templates.size(); ++i) Template& templ = templates[i]; templ.width = (max_x - min_x) >> templ.pyramid_level; templ.height = (max_y - min_y) >> templ.pyramid_level; templ.tl_x = min_x >> templ.pyramid_level; templ.tl_y = min_y >> templ.pyramid_level; for (int j = 0; j < (int)templ.features.size(); ++j) templ.features[j].x -= templ.tl_x; templ.features[j].y -= templ.tl_y; return Rect(min_x, min_y, max_x - min_x, max_y - min_y);
这个的作用就是找到当前所有的特征的最小外接矩形,这个东西其实是个很好的属性,他有个潜在的作用就是可以增加某些特性目标的识别,因为他缩小了旋转后的特征的尺度,相当于变相的增加了识别结果的尺度。所以如果某个模版其有效特征(边缘)在高度或宽度某个方向完全缺失,则即使这个目标在被识别图像的边缘处,也有可能予以识别,比如下面这些目标:

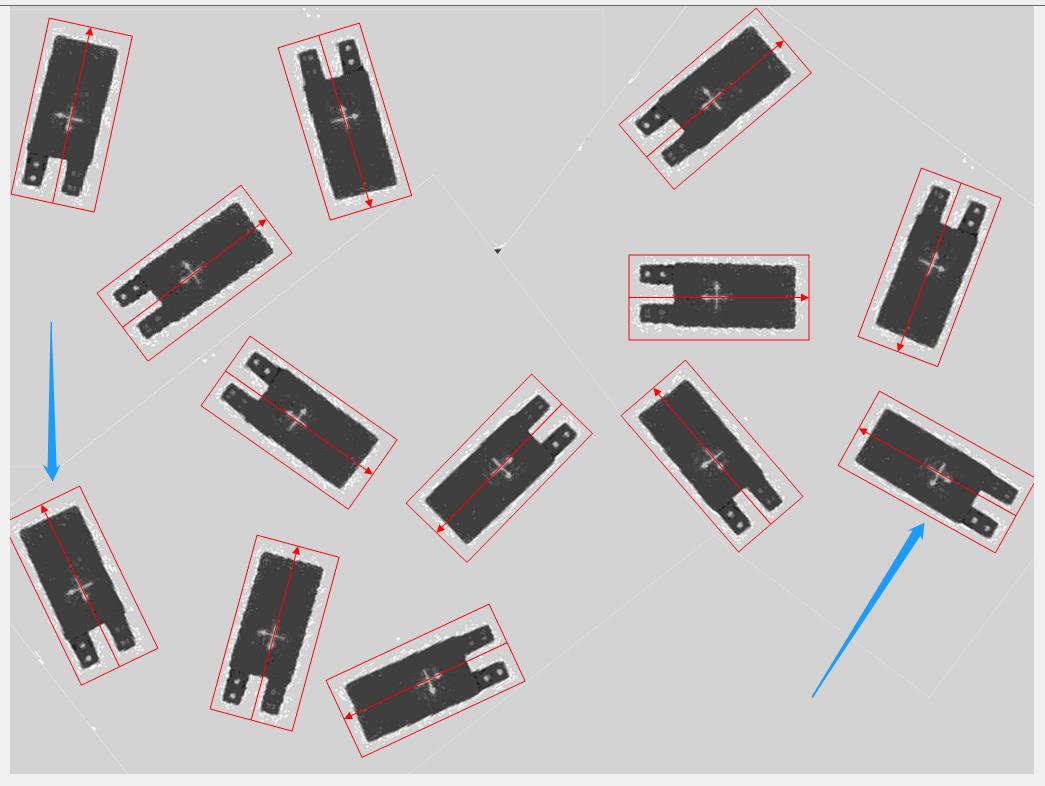
如右图两处蓝色箭头所示,这两处目标实际上是有一部分区域位于了原图之外,但是确实可以识别到,就是因为在模版图的特征提取中,边缘那些纯色的部分不含有有效边缘,在处理时把这部分的区域就去除了,给了这些位于边缘之外的目标可被找到的概率。 但是如果是用NCC,则无论如何也是找不到这两个目标的(或者有明显的偏移)。
这个东西有一个细节需要注意,就是在实现时,由于特征的位置进行了一定的裁剪,所以从金字塔的顶层向下定位的过程中,不能简单的把坐标值乘以2,而必须考虑相关的偏移,这些偏移的数据也应该在创建模型的过程中予以记录,这些编程的技巧也是相当麻烦的过程。
三、多尺度和各项异性匹配中缩放步长的自动确认
前面稍微提及了多尺度和各项异性的匹配,和标准的形状匹配相比,他们实质上是没有太多的变化的。而其中一个非常重要的地方就是缩放步长的自动计算,因为缩放步长设计的不合理,必然会丢失一些重要的节点数据,导致组中的目标无法准确识别。这个东西我们也是借用了halcon一篇专利里的算法,其大概意思如下图所示:
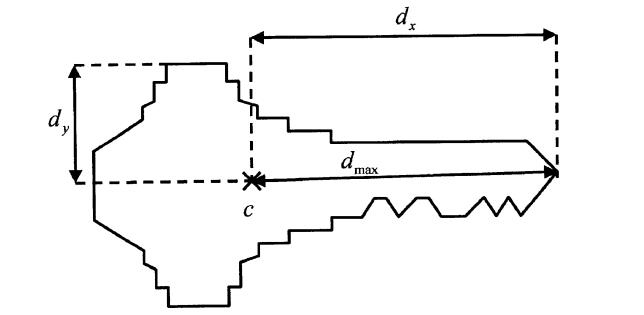
他首先计算所有特征点的X和Y方向的重心(X和Y方向坐标相加求平均值),然后再计算每个特征点和这个重心的距离(绝对值),取最大值的倒数作为缩放步长。这也是非常合理的一个过程。最大的距离表面可以考虑到每一个离散的状态。
我实际测试,一般来说用这个自动计算出的缩放步长是较为合理的,稍微手动修改就存在找不到的现象,而halcon的缩放步长的功能要强大很多。
四、自动对比度的确认
在早期的文章中,我有提到自动对比度可以使用模版图的OSTU二值化阈值法得到,但是实际测试时发现很多图像这样的得到的对比度值非常不合适,会造成目标的丢失。后续有朋友提出应该用模版图的Canny算子的过程中,经过非极大值抑制后的梯度图像,利用Otsu算法算出一个阈值,将其作为一个高阈值TH,高阈值的一半作为低阈值TL。实际证明,这个方式是非常有效的。
五、Halcon里的计算相似度的公式和linemod计算式的关系
实际上,linemod里用到的夹角余弦的计算公式和halcon利用的梯度算式的实质是一样的,借用一个网友的贴图:
夹角余弦:
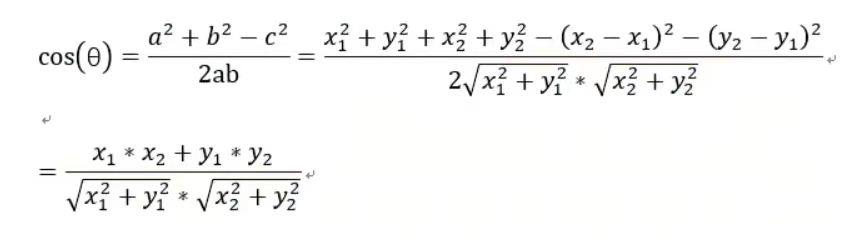
边缘梯度:
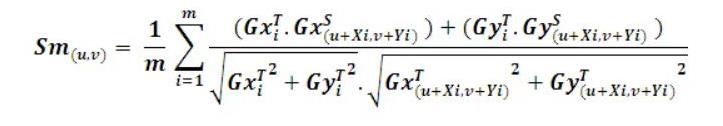
只不过在linemod里,把夹角余弦有离散化到0和7之间了。
六、边缘梯度的计算式里分母的开方和除法是不需要的
当我们都做归一化处理时,我们发现边缘梯度的相似度计算其实根本不需要计算分母里的开平方以及整个除法,只需要分子力的两个乘法和一个加法,这个对计算量来说有很大的提升的。
七、最顶层候选点的选择策略
这个是个很重要的过程,他不仅影响到了算法的速度,而且对结果的准确性也会有直接的关联。早期我是算出每个位置的可能角度的的分支,然后取最大值留下,得到了一副 各位置的综合得分图,然后利用一些局部最大值以及早期说的 满水填充等奇技淫巧(现在看来都是歪门邪道)来得到顶层的候选点,这个在后续的测试中发现会丢失目标。
一个可靠的选择方式是候选点必须满足下面2个特征:
1、 他必须大于最小得分(不同层的最小得分需要适当调整,越往金字塔顶端得分需越小),这可以去掉大部分点。
2、他必须是个局部最大得分点(可以是3*3或者5*5)。
在网络上搜索这方面的资料时,有发现有篇类似的博客有提及到这个算法:基于形状的模板匹配之候选点选择 ,我感觉没有讲到核心,大家也可以参考下。
注意,关于maxoverlap的选项,不建议用在候选点的筛选上,甚至在除了底层外,其他层也不应该用该选项来筛选。
八、最小组件尺寸选项
其实在Halcon的匹配里还隐藏了这个选项,在Contrast 选项里。我们综合比较认为他应该就是一个最小连续边缘的意思,如果某个连续的边缘的个数小于这个尺寸,则不把他作为特征设计,予以剔除,这个选项有两个作用,一个是可以减少一些较小特征或者说是噪音的影响,二是可以提高匹配的速度,如下图所示:


不考虑最小组件尺寸 最小组件尺寸为100
当最小组件尺寸为100时,得到的特征就更为简洁,同时,周边一些不重要的特征予以剔除。
总结: 看似一个简单的算法,要做到极致和完美真的还是不容易,那怕是现在这个样子,离我们传说中的perferct还是以后很大的距离的,有的时候由不得不佩服那些创新的大神们。
针对夹角余弦以及正统的梯度边缘,我分别实现两个不同版本的基于边缘的形状匹配算法,两者似乎也没有太大的性能区别,有兴趣额的朋友可以试下下面的链接:
1、基于梯度边缘的形状匹配。
如果想时刻关注本人的最新文章,也可关注公众号或者添加本人微信: laviewpbt

以上是关于工程应用八终极的基于形状匹配方案解决(小模型+预生成模型+无效边缘去除+多尺度+各项异性+最小组件尺寸)的主要内容,如果未能解决你的问题,请参考以下文章
数据持久化方案解析(八) —— UIDocument的数据存储(一)
使用charls抓包微信小程序的解决方案(终极解决,各种坑不怕,亲测可用,不服来战!)