《Python》re模块补充异常处理
Posted zyling_me
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Python》re模块补充异常处理相关的知识,希望对你有一定的参考价值。
一、re模块
1、match方法
import re # match 验证用户输入的内容 ret = re.match(\'\\d+\', \'hhoi2342ho12ioh11\') print(ret) # None ret = re.match(\'\\d+\', \'342khjlh324jbk234\') print(ret) # <re.Match object; span=(0, 3), match=\'342\'> print(ret.group()) # 342 # match是从开头开始匹配,不符合则返回None
2、split 切割
import re # 切割 split s1 = \'alex|egon|taibai\' print(s1.split(\'|\')) # [\'alex\', \'egon\', \'taibai\'] s = \'alex345egon3056taibai\' # 不保留切割内容 ret = re.split(\'\\d+\', s) print(ret) # [\'alex\', \'egon\', \'taibai\'] # 保留切割内容 ret = re.split(\'(\\d+)\', s) print(ret) # [\'alex\', \'345\', \'egon\', \'3056\', \'taibai\']
3、sub 替换
import re # 替换 sub s = \'alex|egon|taibai\' print(s.replace(\'|\', \'-\')) # alex-egon-taibai s1 = \'alex234egon342taibai\' # 默认全部替换 ret = re.sub(\'\\d+\', \'|\', s1) print(ret) # alex|egon|taibai # 设置替换次数 ret = re.sub(\'\\d+\', \'|\', s1, 1) print(ret) # alex|egon342taibai # 默认全部替换,并返回一个元祖,元祖的第二个值是替换的次数 ret = re.subn(\'\\d+\', \'|\', s1) print(ret) # (\'alex|egon|taibai\', 2) # 设置替换次数,并返回一个元祖,元祖的第二个值是替换的次数 ret = re.subn(\'\\d+\', \'|\', s1, 1) print(ret) # (\'alex|egon342taibai\', 1)
4、compile 编译正则规则
import re # compile 编译正则规则 com = re.compile(\'\\d+\') print(com) # re.compile(\'\\\\d+\') ret = com.search(\'sdf2g23jkgk21k21\') print(ret.group()) # 2 ret = com.findall(\'sdf2g23jkgk21k21\') print(ret) # [\'2\', \'23\', \'21\', \'21\'] ret = com.finditer(\'sdf2g23jkgk21k21\') for i in ret: print(i.group()) # 2 # 23 # 21 # 21
5、finditer 节省空间的方法
import re # finditer 节省空间的方法 ret = re.finditer(\'\\d+\', \'sdf2g23jkgk21k21\') print(ret) # <callable_iterator object at 0x00A6AF10> 迭代器 for i in ret: print(i.group()) # 2 # 23 # 21 # 21
6、分组命名、分组约束
在前端中常见的: <h1>函数</h1>
实际上对于前端语言来说,都是把不同样式的字体放在不同的标签中
import re # 分组命名、分组约束 pattern = \'<(?P<tag>.*?)>.*?</(?P=tag)>\' ret = re.search(pattern, \'<h1>函数</h1>\') print(ret) # <re.Match object; span=(0, 11), match=\'<h1>函数</h1>\'> if ret: print(ret.group()) # <h1>函数</h1> print(ret.group(1)) # h1 print(ret.group(\'tag\')) # h1 pattern = r\'<(.*?)>.*?</\\1>\' ret = re.search(pattern, \'<a>函数</a>\') print(ret) # <re.Match object; span=(0, 9), match=\'<a>函数</a>\'> if ret: print(ret.group()) # <a>函数</a> print(ret.group(1)) # a \'\'\' (?:正则表达式) 表示取消优先显示功能 (?P<组名>正则表达式) 表示给这个组取一个名字 (?P=组名) 表示引用之前组的名字,引用部分匹配到的内容必须和之前那个组中的内容一模一样 \'\'\'
二、异常处理
语法错误:在程序之前就规避掉,不应该留到程序中来进行异常处理
在编译的过程中报错
异常:
在编译阶段没问题,在执行阶段才报错
异常出现之后的现象:程序就不继续执行了
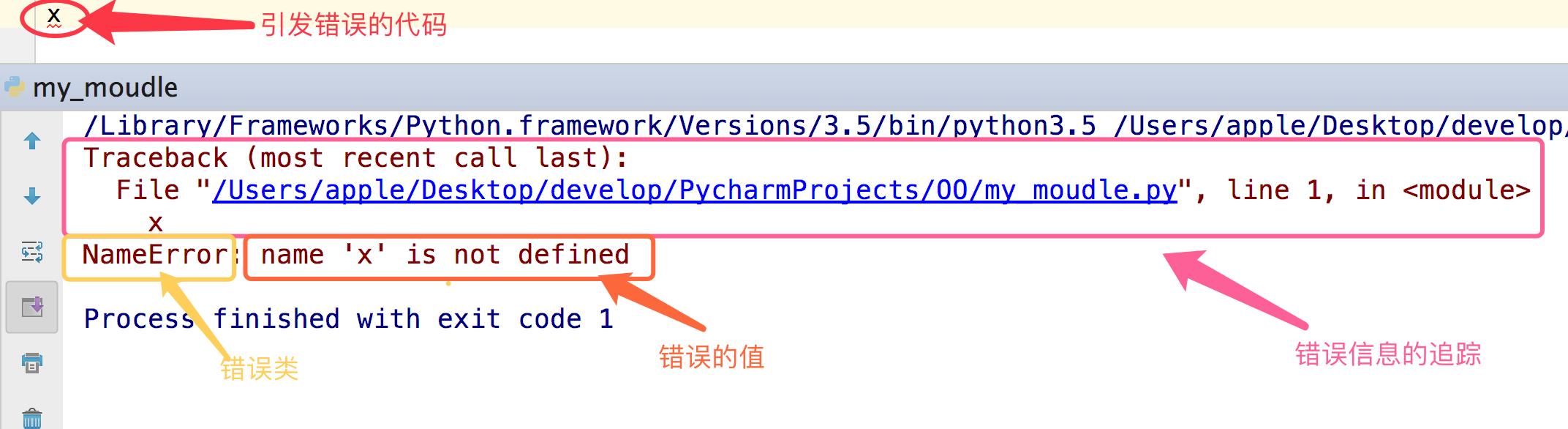
Python的异常种类:
# 常见异常 AttributeError # 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x IOError # 输入/输出异常;基本上是无法打开文件 ImportError # 无法引入模块或包;基本上是路径问题或名称错误 IndentationError # 语法错误(的子类) ;代码没有正确对齐 IndexError # 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5] KeyError # 试图访问字典里不存在的键 KeyboardInterrupt # Ctrl+C被按下 NameError # 使用一个还未被赋予对象的变量 SyntaxError # Python代码非法,代码不能编译(个人认为这是语法错误,写错了) TypeError # 传入对象类型与要求的不符合 UnboundLocalError # 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,导致你以为正在访问它 ValueError # 传入一个调用者不期望的值,即使值的类型是正确的
ArithmeticError
AssertionError
AttributeError
BaseException
BufferError
BytesWarning
DeprecationWarning
EnvironmentError
EOFError
Exception
FloatingPointError
FutureWarning
GeneratorExit
ImportError
ImportWarning
IndentationError
IndexError
IOError
KeyboardInterrupt
KeyError
LookupError
MemoryError
NameError
NotImplementedError
OSError
OverflowError
PendingDeprecationWarning
ReferenceError
RuntimeError
RuntimeWarning
StandardError
StopIteration
SyntaxError
SyntaxWarning
SystemError
SystemExit
TabError
TypeError
UnboundLocalError
UnicodeDecodeError
UnicodeEncodeError
UnicodeError
UnicodeTranslateError
UnicodeWarning
UserWarning
ValueError
Warning
ZeroDivisionError
异常处理:
1、基本语法:
# try: # 被检测的代码块 # except 异常类型: # try中一旦检测到异常,就执行这个位置的逻辑 l = [\'登录\', \'注册\'] try: num = int(input(\'num:\')) print(l[num - 1]) except ValueError: # 输入的不是数字走这里 print(\'输入的不是数字\') except IndexError: # 输入的数字超出范围走这里 print(\'输入的超出范围\') try: num = int(input(\'num:\')) print(l[num - 1]) except (ValueError,IndexError): # 把不同的报错类型写在一起 print(\'输入了错误的内容\')
2、万能异常 Exception
# 万能异常Exception try: l = [] l[3] # IndexError import Index # ModuleNotFoundError open(\'aaaaaa\') # FileNotFoundError 1/0 # ZeroDivisionError dic = {} dic[\'k\'] # KeyError except Exception: print(\'异常了\') # as 语法 try: l = [] l[3] # IndexError import Index # ModuleNotFoundError open(\'aaaaaa\') # FileNotFoundError 1/0 # ZeroDivisionError dic = {} dic[\'k\'] # KeyError except Exception as e: print(e) # list index out of range # 多分支 + 万能异常 l = [\'登陆\',\'注册\'] try: num = int(input(\'num : \')) print(l[num - 1]) except (ValueError,IndexError): # 异常是这两种错误则走这里 print(\'输入了错误的内容\') except Exception as e: # 如果不是上面两种错误则走这里 print(e)
3、异常处理中的其他机制
s1 = \'hello\' try: int(s1) except IndexError as e: print(e) except KeyError as e: print(e) except ValueError as e: print(e) #except Exception as e: # print(e) else: print(\'try内代码块没有异常则执行我\') # 汇报这段代码顺利的执行了:发短信通知,记录到文件中 finally: print(\'无论异常与否,都会执行该模块,通常是进行清理工作\') # 无论如何都要执行 # 收尾工作,打开了一个文件,占用了一个网络资源,打开了一个和数据库的链接 # 可以在这里关闭文件等
4、主动触发异常
try: raise TypeError(\'类型错误\') except Exception as e: print(e) # 类型错误
5、自定义异常
class EvaException(BaseException): def __init__(self,msg): self.msg=msg def __str__(self): return self.msg try: raise EvaException(\'类型错误\') except EvaException as e: print(e) # 类型错误
6、断言
assert 1 == 1 print(\'*\' * 10) # ********** assert 1 == 2 print(\'*\' * 10) # AssertionError
以上是关于《Python》re模块补充异常处理的主要内容,如果未能解决你的问题,请参考以下文章