GPGPU开发几个工具包
Posted 吴建明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GPGPU开发几个工具包相关的知识,希望对你有一定的参考价值。
英伟达 cuDNN
- 适用于所有流行卷积的张量核心加速,包括 2D、3D、分组、深度可分离以及使用 NHWC 和 NCHW 输入和输出进行扩张
- 针对计算机视觉和语音模型优化的内核,包括 ResNet、ResNext、EfficientNet、EfficientDet、SSD、MaskRCNN、Unet、VNet、BERT、GPT-2、Tacotron2 和 WaveGlow
- 支持 FP32、FP16、BF16 和 TF32 浮点格式以及 INT8 和 UINT8 整数格式
- 支持将内存受限操作(如逐点)和归约与数学限制操作(如卷积和矩阵)融合
- 支持具有最新 NVIDIA 数据中心和移动 GPU 的 Windows 和 Linux。

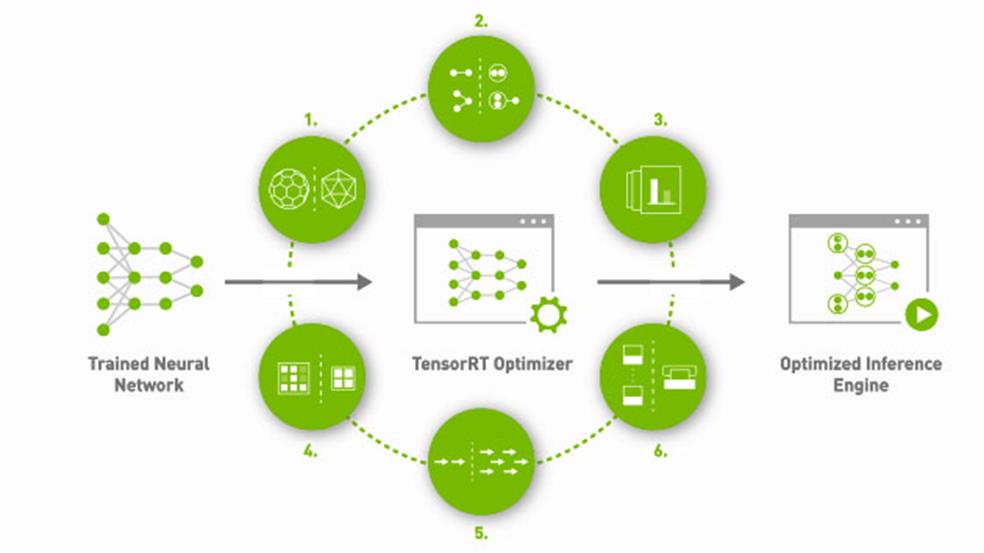
英伟达张量RT

NVIDIA TensorRT 优势

世界领先的推理性能

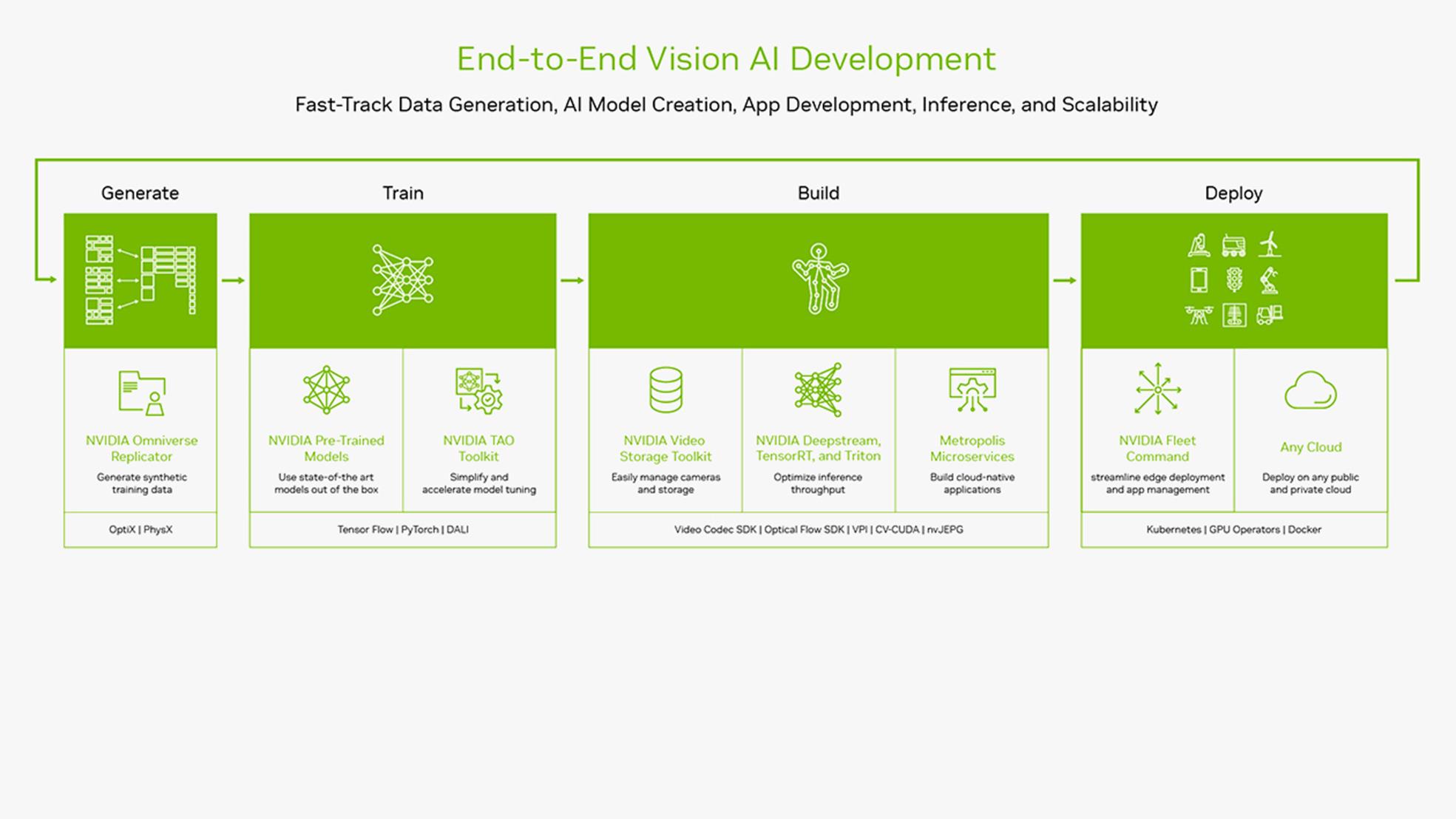
NVIDIA JetPack SDK 是用于构建端到端加速 AI 应用程序的最全面的解决方案。JetPack SDK 支持所有 Jetson 模块和开发人员套件。

DeepStream 也是 NVIDIA Metropolis 不可或缺的一部分,NVIDIA Metropolis 是构建端到端服务和解决方案的平台,可将像素和传感器数据转换为可操作的见解。
DeepStream是为开发人员和企业构建的,为流行的对象检测和分割模型(如最先进的SSD,YOLO,FasterRCNN和MaskRCNN)提供广泛的AI模型支持。您还可以集成自定义函数和库。
DeepStream 为不同的插件引入了新的 REST-API,让您创建灵活的应用程序,这些应用程序可以部署为 SaaS,同时通过直观的界面进行控制。这意味着现在可以使用简单的界面(如网页)添加/删除流并修改“感兴趣区域”。
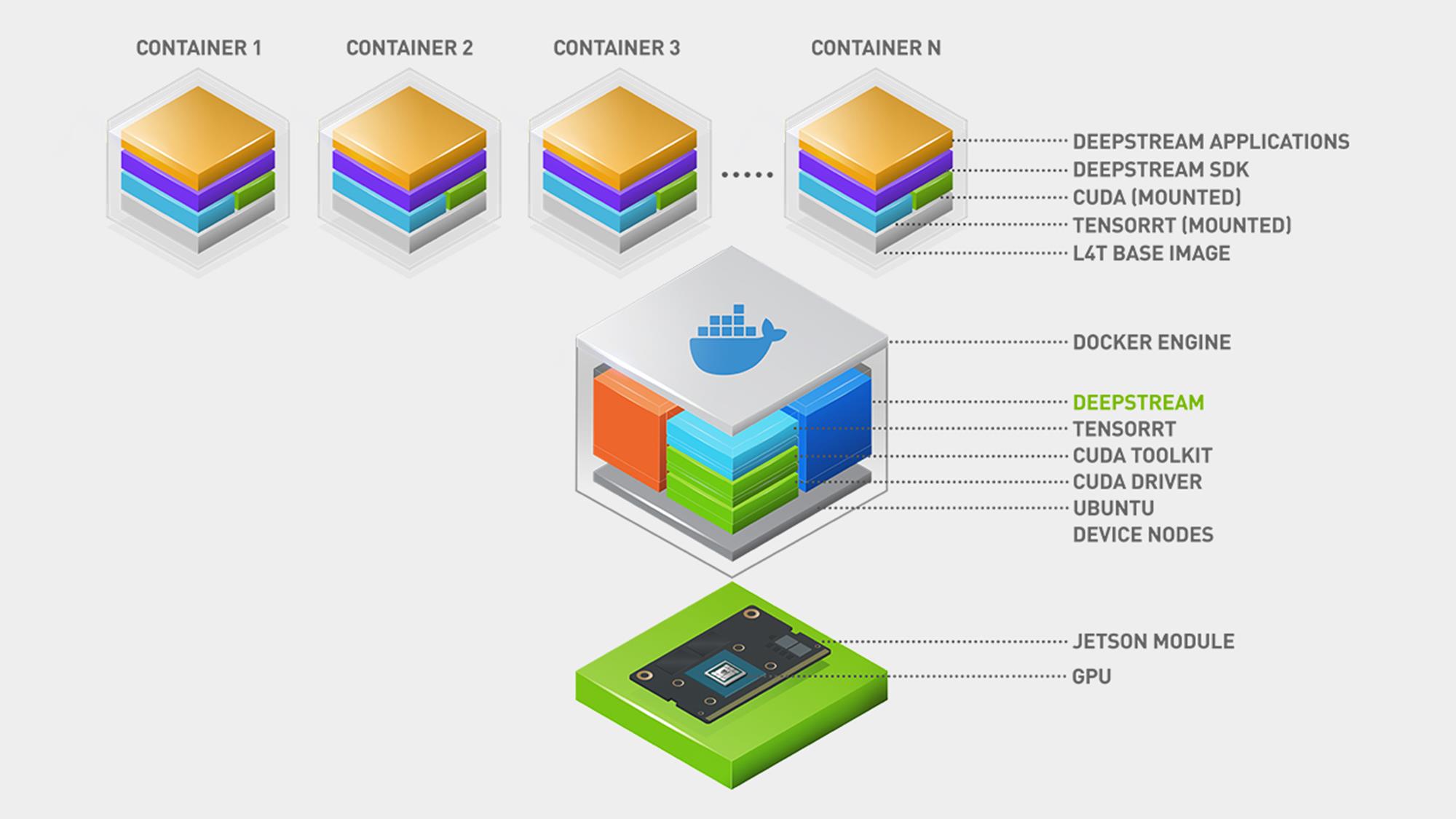
获取云原生
开发人员可以使用 DeepStream 容器生成器工具,使用 NVIDIA NGC 容器构建高性能的云原生 AI 应用程序。生成的容器可以轻松大规模部署,并使用 Kubernetes 和 Helm Charts 进行管理。
获得令人难以置信的灵活性 - 从快速原型设计到完整的生产级解决方案 - 并选择您的推理路径。通过与 NVIDIA Triton™ Inference Server 的原生集成,您可以在原生框架(如 PyTorch 和 TensorFlow )中部署模型以进行推理。使用 NVIDIA TensorRT™ 进行高吞吐量推理,并提供多 GPU、多流和批处理支持选项,也有助于您实现最佳性能。
访问参考应用程序
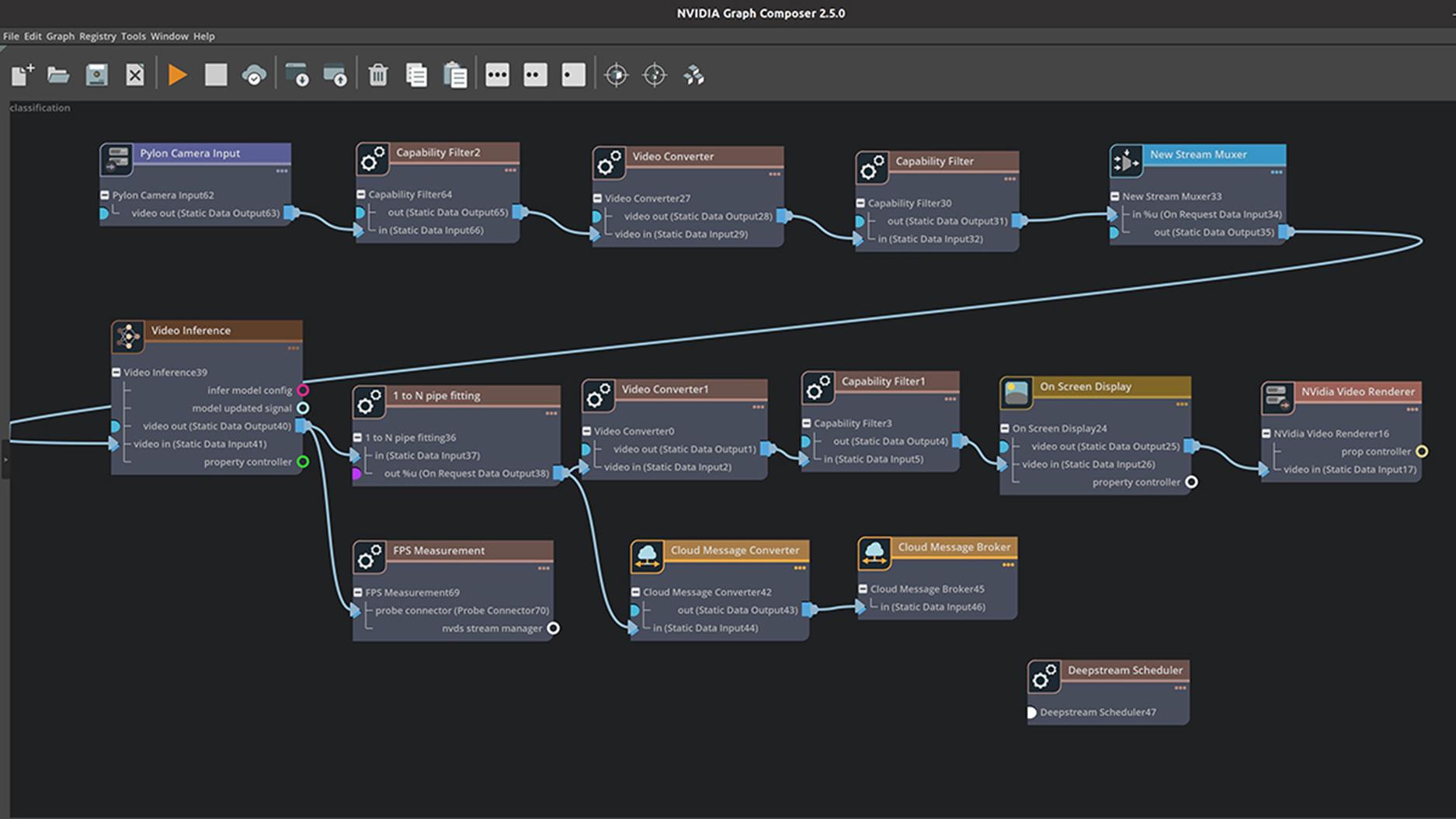
使用图形编辑器
Graph Composer 抽象了创建最新的实时、多流视觉 AI 应用程序所需的大部分底层 DeepStream、GStreamer 和平台编程知识。用户无需编写代码,而是与广泛的组件库进行交互,使用拖放界面配置和连接它们。
NVIDIA AI Enterprise 包含企业支持,可帮助您开发由 DeepStream 提供支持的应用程序,并通过全球企业支持管理 AI 应用程序的生命周期。这有助于确保您的业务关键型项目保持正轨。
|
Jetson Orin NX |
Jetson Orin AGX™ |
T4 |
A2 |
A10 |
A30 |
A100 |
H100 |
L40 |
L4 |
RTX* (A6000) |
|||||||||
|
Application |
Models |
Tracker |
Infer Resolution |
Precision |
GPU |
DLA1 |
DLA2 |
GPU |
DLA1 |
DLA2 |
GPU |
GPU |
GPU |
GPU |
GPU |
GPU |
GPU |
GPU |
GPU |
|
People Detect |
PeopleNet-ResNet34 |
No Tracker |
960x544 |
INT8 |
141 |
65 |
65 |
456 |
130 |
130 |
420 |
233 |
993 |
1440 |
2336 |
3492 |
1969 |
745 |
1432 |
|
People Detect |
PeopleNet-ResNet34 |
NvDCF |
960x544 |
INT8 |
131 |
65 |
65 |
418 |
130 |
130 |
418 |
229 |
957 |
1375 |
2048 |
3196 |
1946 |
738 |
1375 |
|
License Plate Recognition |
TrafficCamNet |
NvDCF |
960x544 |
INT8 |
143 |
- |
- |
379 |
- |
- |
455 |
290 |
1155 |
1301 |
2059 |
2531 |
2323 |
762 |
1482 |
|
3D Body Pose Estimation |
PeopleNet-ResNet34 BodyPose3D |
NvDCF |
960x544 |
INT8 |
32 |
- |
- |
62 |
- |
- |
91 |
59 |
143 |
167 |
187 |
207 |
144 |
169 |
144 |
|
Action Recognition |
ActionRecognitionNet (3DConv) |
No Tracker |
224x224x3x32 |
FP16 |
36 |
- |
- |
122 |
- |
- |
134 |
72 |
1154 |
2598 |
2583 |
3181 |
2304 |
2476 |
1327 |
以上是关于GPGPU开发几个工具包的主要内容,如果未能解决你的问题,请参考以下文章