必备条件:
一台能上404的机子..
过程:
由于也只是初学爬虫,个中技巧也不熟练,写的过程中的语法用法参考了很多文档和博客,我是对于当前搜索页用F12看过去..找到每个本子的地址再一层层下去最后下载图片...然后去根据标签一层层遍历将文件保存在本地,能够直接爬取搜索页下一整页的所有本,并保存在该文件同级目录下,用着玩玩还行中途还被E站封了一次IP,现在再看觉得很多地方还能改进(差就是还有进步空间嘛,不排除失效的可能
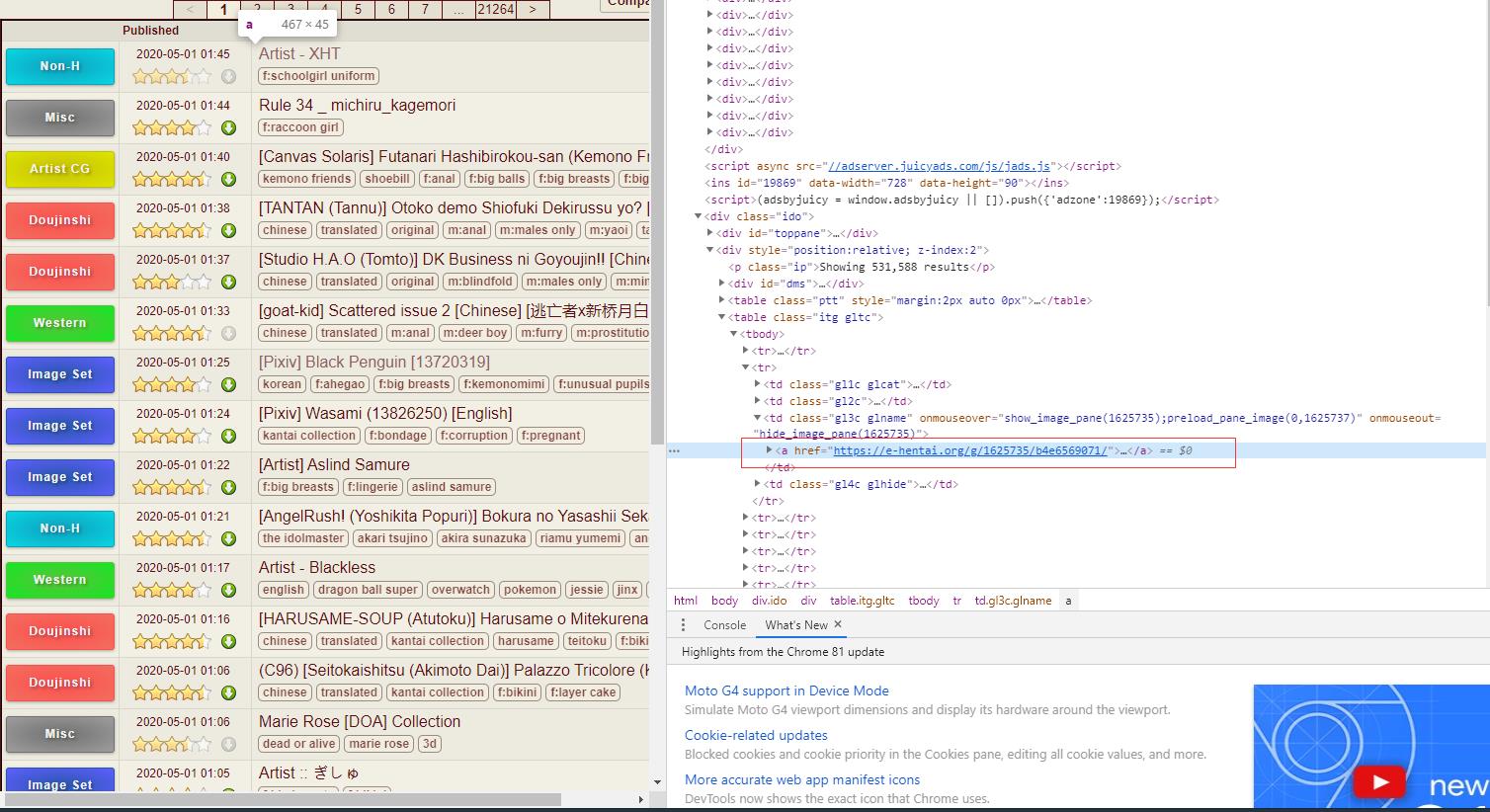
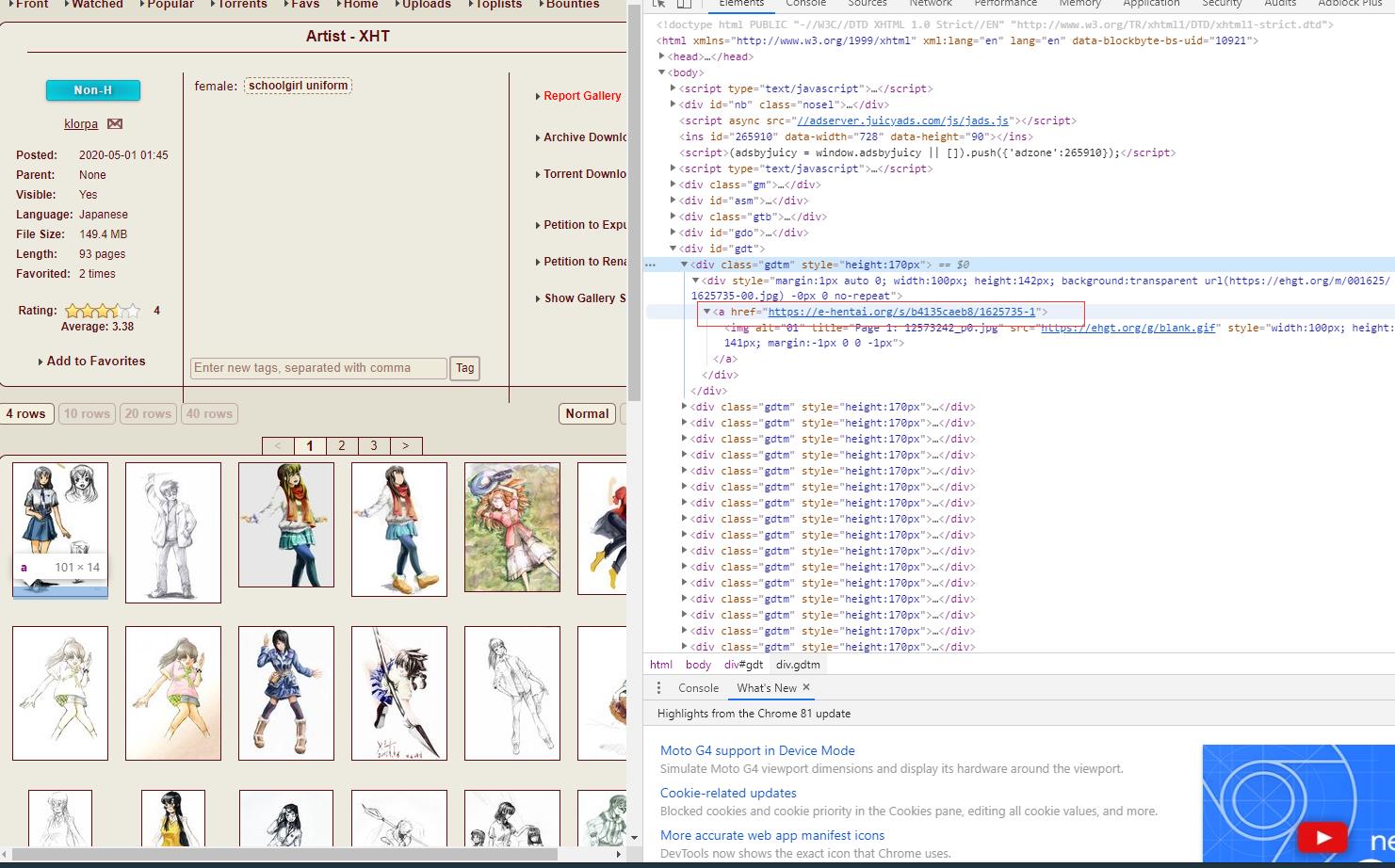
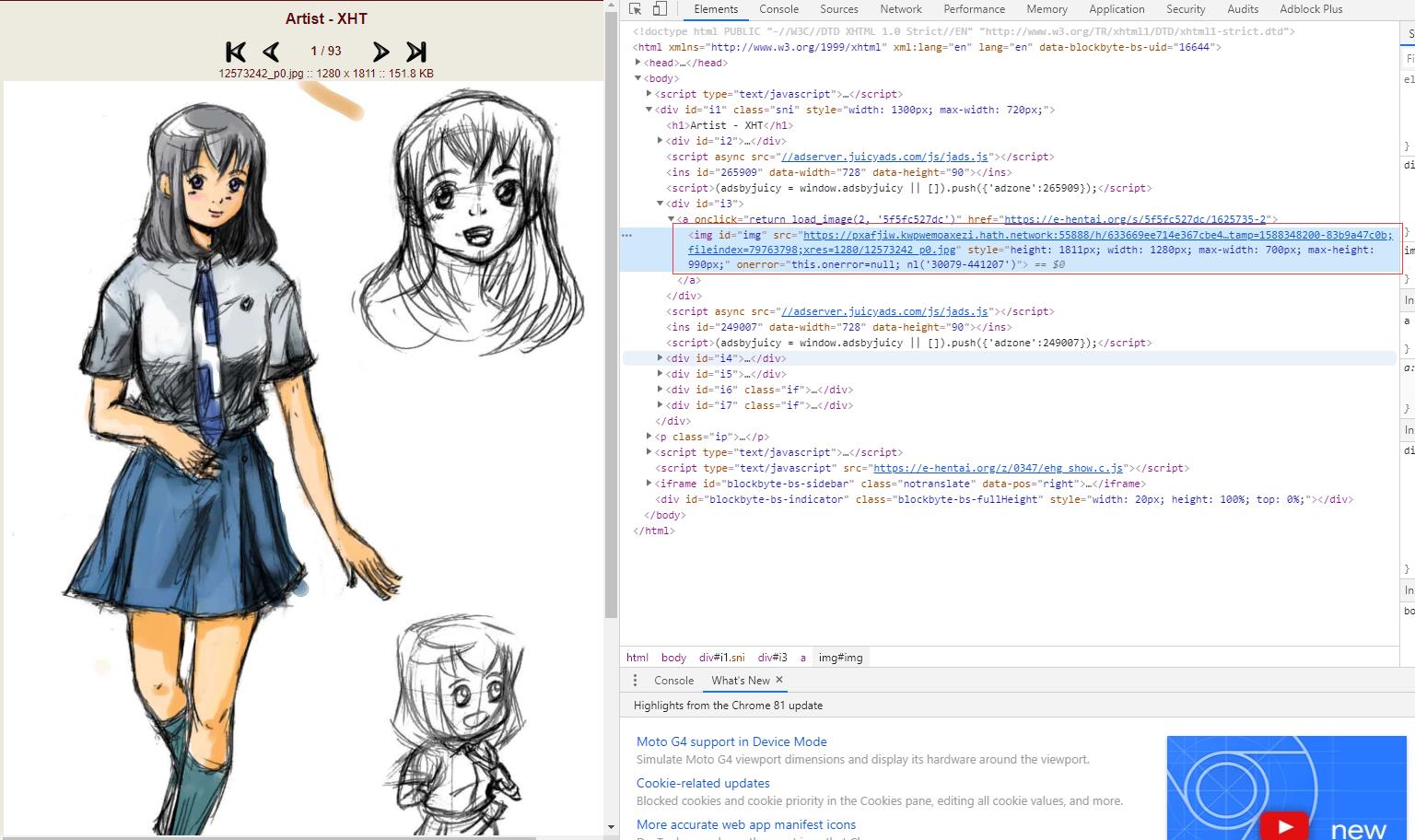
这就是个试验页 别想太多
代码:
from bs4 import BeautifulSoup
import re
import requests
import os
import urllib.request
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36\',
\'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\',
\'Upgrade-Insecure-Requests\': \'1\'}
r = requests.get("https://e-hentai.org/", headers=headers)
soup = BeautifulSoup(r.text, \'lxml\')
divs = soup.find_all(class_=\'gl3c glname\')
# 爬取当前页面的本子网址
for div in divs:
url = div.a.get(\'href\')
r2 = requests.get(url, headers=headers)
soup2 = BeautifulSoup(r2.text, \'lxml\')
manga = soup2.find_all(class_=\'gdtm\')
title = soup2.title.get_text() # 获取该本子标题
# 遍历本子的各页
for div2 in manga:
picurl = div2.a.get(\'href\')
picr = requests.get(picurl, headers=headers)
soup3 = BeautifulSoup(picr.text, \'lxml\')
downurl = soup3.find_all(id=\'img\')
page = 0
for dur in downurl:
# print(dur.get(\'src\'))
# 判断是否存在该文件夹
purl=dur.get(\'src\')
fold_path = \'./\'+title
if not os.path.exists(fold_path):
print("正在创建文件夹...")
os.makedirs(fold_path)
print("正在尝试下载图片....:{}".format(purl))
#保留后缀
filename = title+str(page)+purl.split(\'/\')[-1]
filepath = fold_path + \'/\' + filename
page = page + 1
if os.path.exists(filepath):
print("已存在该文件,不下了不下了")
else:
try:
urllib.request.urlretrieve(purl, filename=filepath)
except Exception as e:
print("error发生:")
print(e)
然后还利用pyinstaller做了一个exe文件
Updata1:
发现忘了考虑各个分页,导致一本本子最多只能爬取四十张图片,而且由于爬取一页的本子数量太多且良莠不齐测试爬虫的时候正好是半夜..还是一个人住,批量爬取时混入了恐怖本子吓得没睡好,现在只从本子打开后的链接进行爬取一本本子,我的写法照理说从分页的链接也能爬取一整本(虽然我没试过试过了确实可以,而且修正了由于标题问题导致爬取失败的bug
# coding:utf-8
# author:graykido
# data=2020.5.3
from bs4 import BeautifulSoup
import re
import requests
import os
import urllib.request
import threading
import time
headers = {
\'User-Agent\': \'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36\',
\'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\',
\'Upgrade-Insecure-Requests\': \'1\'}
#批量处理
urls = []
temp = input(\'请输入要爬取的指定页(输入空白结束):\')
while temp!="":
urls.append(temp)
temp = input(\'输入成功 请继续输入链接或者输入空白结束:\')
for url in urls:
start = time.perf_counter()
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, \'lxml\')
manga = soup.find_all(class_=\'gdtm\')
title = soup.title.get_text() # 获取该本子标题
# 去除非法字符
for ch in \'!"#$%&()*+,-./:;<=>?@\\\\^_‘{|}~ \':
title = title.replace(ch, "")
# 避免因标题过长导致无法储存
if len(title) > 50:
title = title[:50]
pagetag = soup.find(class_=\'ptt\').find_all(\'a\')
mxpage = 0
baseurl = ""
for page in pagetag:
temstr = str(page.get(\'href\'))
temspl = temstr.split(\'?p=\')
if len(temspl) > 1:
mxpage = max(mxpage, int(temspl[1]))
else:
baseurl = page.get(\'href\')
pages = [baseurl]
for i in range(1, mxpage + 1):
pages.append(baseurl + \'?p=\' + str(i))
if mxpage==0:
mxpage = 1
print("正在获取的漫画名:{0:},共计{1:}分页".format(soup.title.get_text(), mxpage))
count = 0
# 遍历各分页
for page in pages:
r = requests.get(page, headers=headers)
soup = BeautifulSoup(r.text, \'lxml\')
manga = soup.find_all(class_=\'gdtm\')
# 遍历分页的各张图片
for div in manga:
picurl = div.a.get(\'href\')
picr = requests.get(picurl, headers=headers)
soup2 = BeautifulSoup(picr.text, \'lxml\')
downurl = soup2.find_all(id=\'img\')
for dur in downurl:
purl = dur.get(\'src\')
fold_path = \'./\' + title
# 判断是否存在该文件夹
if not os.path.exists(fold_path):
print("正在创建文件夹...")
os.makedirs(fold_path)
print("正在尝试下载图片....:{}".format(purl))
# 保留后缀
filename = title + str(count) + \'.\' + purl.split(\'.\')[-1]
filepath = fold_path + \'/\' + filename
count = count + 1
if os.path.exists(filepath):
print("已存在该文件,不下了不下了")
else:
try:
urllib.request.urlretrieve(purl, filename=filepath)
print("已成功")
except Exception as e:
print("error发生:")
print(e)
print(\'————下完收工————\')
end = time.perf_counter()
print("下载总时长:{}秒".format(end - start))
之后的事情:
发现了E站原来有自己的API,虽然他家的API也不太好用,但至少比纯手写爬虫方便一点了
文档