R语言上市公司经营绩效实证研究 ——因子分析聚类分析正态性检验信度检验
Posted 大数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言上市公司经营绩效实证研究 ——因子分析聚类分析正态性检验信度检验相关的知识,希望对你有一定的参考价值。
全文链接:http://tecdat.cn/?p=32747
原文出处:拓端数据部落公众号
随着我国经济的快速发展,上市公司的经营绩效成为了一个备受关注的话题。本文旨在探讨上市公司经营绩效的相关因素,并运用数据处理、图示、检验和分析等方法进行深入研究,帮助客户对我国45家上市公司的16项财务指标进行了因子分析与聚类分析。
分析脉络如下:
- 数据预处理(包括缺失值,异常值,标准化这些)
- 数据图示
- 相关性检验正态性检验
- 做因子分析和聚类分析
查看数据
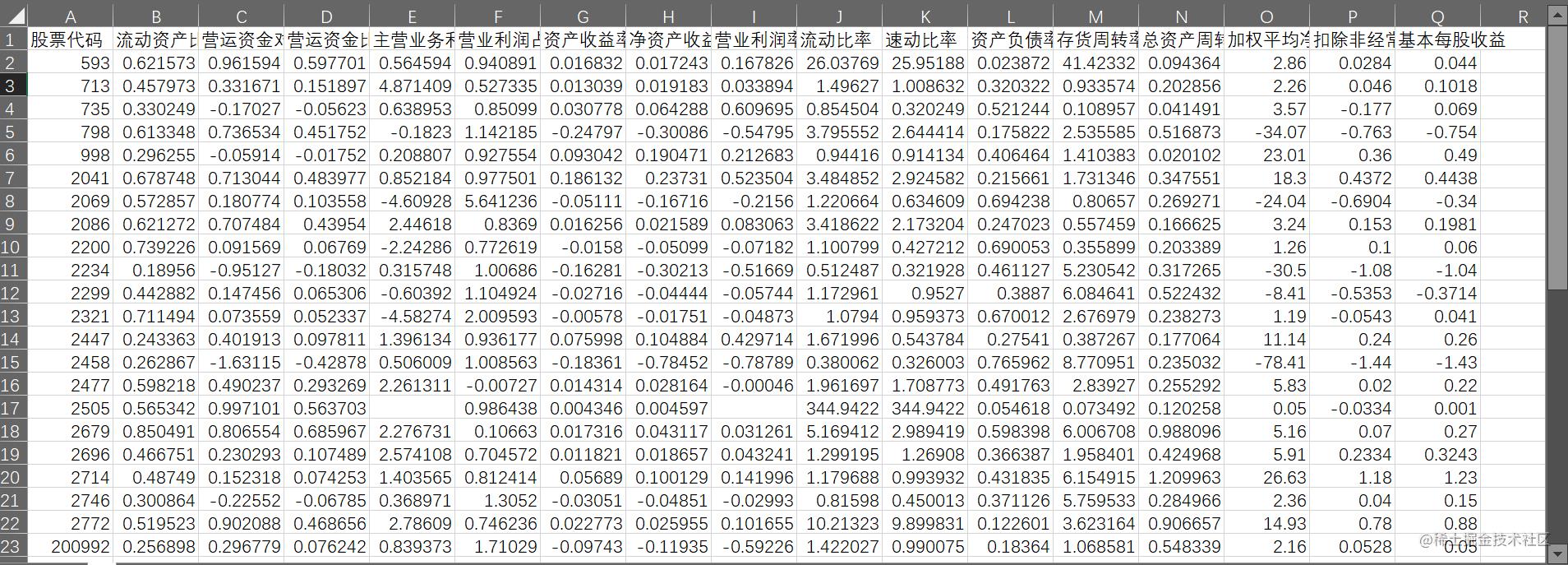
读取到r软件中:
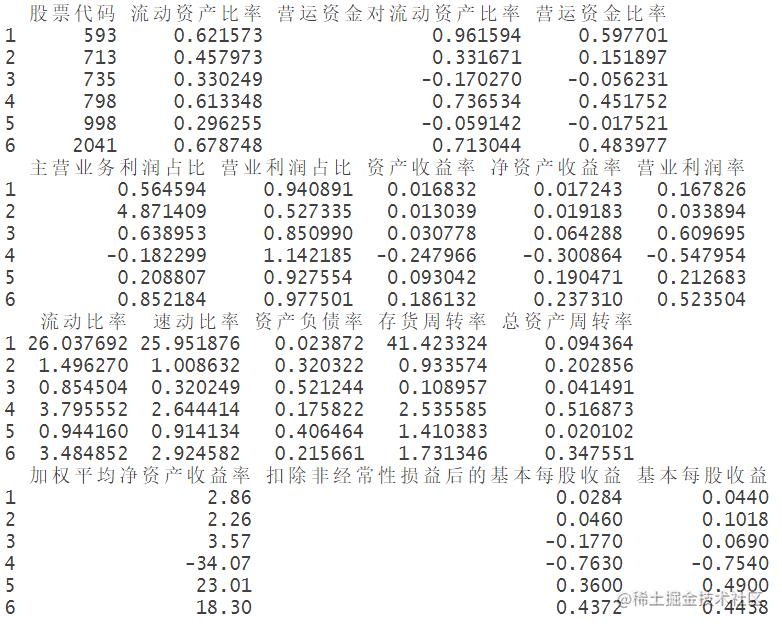
数据预处理(包括缺失值,异常值,标准化
首先,在进行数据分析前,需要对数据进行预处理。数据预处理包括缺失值的处理、异常值的排除、标准化处理等。另外,为了减少数据误差,需要对数据进行标准化处理。
data=na.omit(data)
标准化和可视化
其次,在数据处理完成后,需要对数据进行图示。通过绘制散点图等图示,可以直观地了解各项指标的数值分布和趋势变化。同时,图示也有助于发现数据中的异常点和趋势漂移等问题。
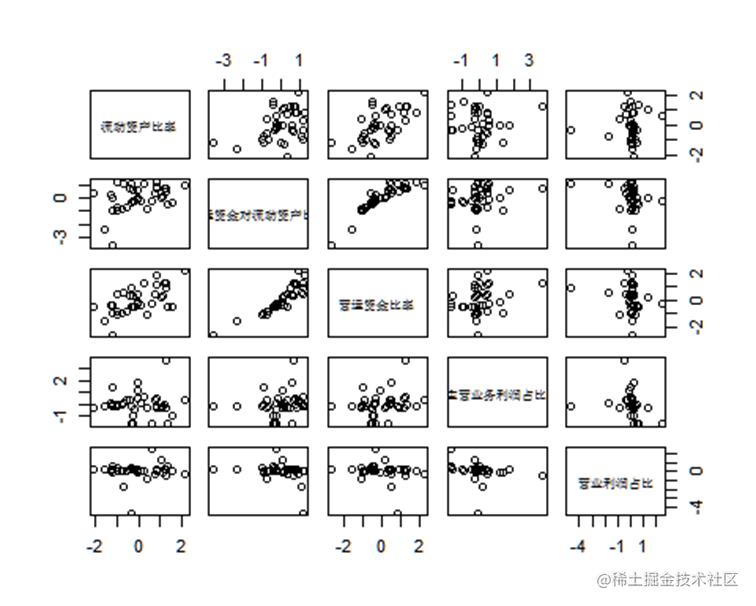

数据的标准化及适用性检验
然后,进行相关性检验和正态性检验等统计方法。相关性检验可以通过计算相关系数的方法来判断各项指标之间的联系程度。而正态性检验则可以通过绘制概率图、矩阵图等方法,来判断数据是否符合正态分布。通过这些检验方法,可以更准确地分析数据,并确定适当的分析方法。
相关性检验


正态性检验
shapiro.test(data[,2])

信度检验结果
信度检验结果是指对某种测量工具(例如问卷、测试等)进行信度检验后得到的结果。信度检验是一种评估测量工具稳定性和一致性的方法,通常使用统计学方法来计算测量工具的内部一致性或者重测信度。通过信度检验,可以确定测量工具的可靠性和准确性,从而确定测量结果的可信度。信度检验结果可以帮助研究者评估测量工具的质量,以确保研究结果的可靠性和有效性。 

KMO检验:
KMO检验是一种用于评估数据是否适合进行因子分析的统计方法。KMO(Kaiser-Meyer-Olkin)检验的主要目的是测量数据集中各个变量之间的相关性,以确定是否存在足够的共性方差,从而确定是否适合进行因子分析。KMO值介于0和1之间,通常认为KMO值大于0.6表示数据适合进行因子分析。如果KMO值低于0.6,则表明数据不适合进行因子分析,需要重新考虑数据收集和分析方法。
kmores=kmo(data\\[,2:17])\\
kmores\\$overall
## [1] 0.5985173
因子分析和聚类分析
接下来,进行因子分析和聚类分析。因子分析旨在寻找出反映上市公司经营绩效的主要因素,并通过统计方法进行因素提取和旋转。而聚类分析则是将样本进行分类,以便于对不同类别的上市公司进行比较分析。
因子分析
因子分析是一种统计方法,用于确定多个变量之间的关系。它将一组相关变量分解为更少的未观察到的变量,称为因子,这些因子可以解释原始变量的方差。因子分析可用于数据降维、变量选择和构建模型等应用。它在社会科学、市场研究和心理学等领域得到广泛应用。 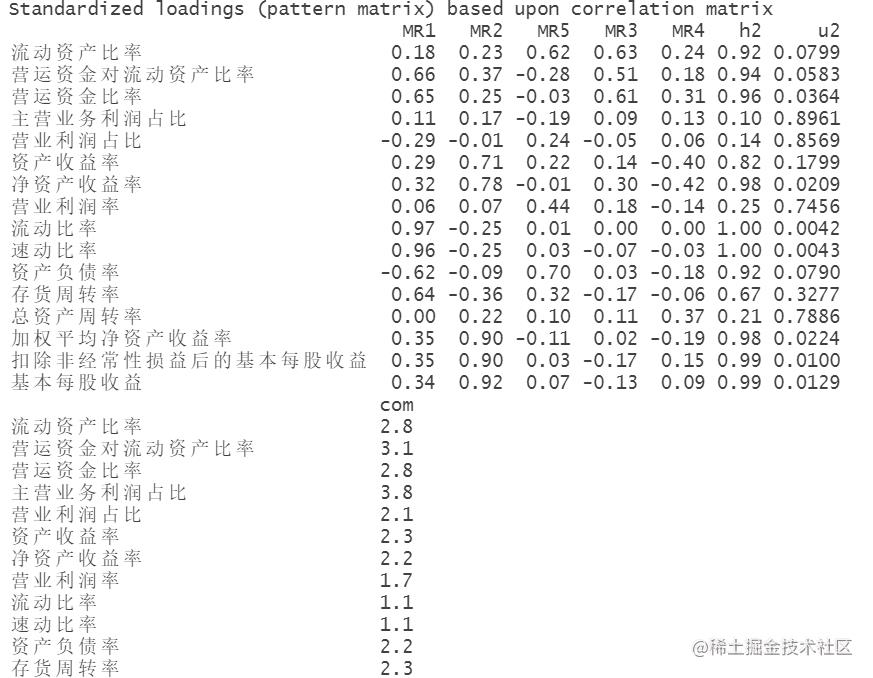

旋转成份矩阵
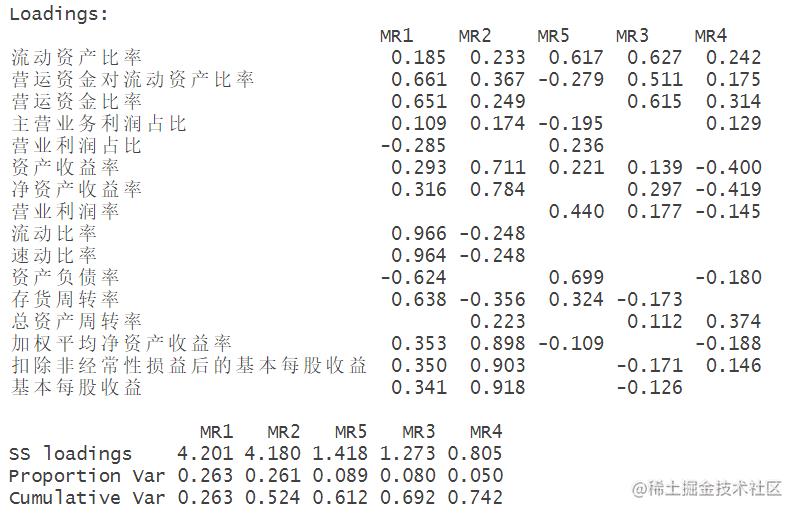
因子得分排名

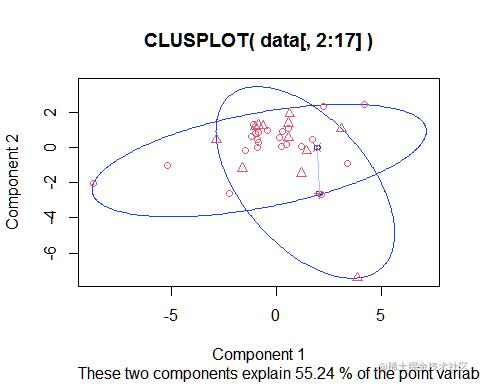
K-means聚类分析上市公司经营绩效
K-means聚类分析是一种常用的无监督学习方法,用于将一组数据分成K个不同的类别。该算法通过迭代的方式将数据点分配到不同的类别中,并且通过计算每个类别的中心点来更新类别的位置。K-means聚类分析的目标是最小化每个数据点到其所属类别中心点的距离平方和,从而使得每个类别内部的数据点尽可能的相似,不同类别之间的数据点尽可能的不同。该算法的优点是简单易懂,计算速度快,适用于大规模数据集的聚类分析。
在上市公司经营绩效的分析中,可以将公司的各项经营指标作为输入数据,通过K-means聚类算法将公司分成若干类别,同一类别内的公司具有相似的经营绩效表现。这样可以帮助投资者或经营者更好地了解市场上不同公司的经营状况,从而做出更明智的投资或经营决策。
memb <- hmod\\$cluster
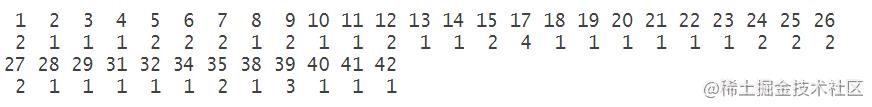
群集成员
cludata

plot(data[,2:17],mem
 综上所述,我国上市公司经营绩效实证研究涉及到数据预处理、图示、检验和分析等多个方面。其中,数据预处理和图示为分析提供了基础和依据,检验和分析则为研究提供了科学性和可靠性保障。通过本文的研究,可以更深入地了解上市公司经营绩效的相关因素,为政府部门和企业提供决策参考。
综上所述,我国上市公司经营绩效实证研究涉及到数据预处理、图示、检验和分析等多个方面。其中,数据预处理和图示为分析提供了基础和依据,检验和分析则为研究提供了科学性和可靠性保障。通过本文的研究,可以更深入地了解上市公司经营绩效的相关因素,为政府部门和企业提供决策参考。

最受欢迎的见解
1.matlab偏最小二乘回归(PLSR)和主成分回归(PCR)
2.R语言高维数据的主成分pca、 t-SNE算法降维与可视化分析
4.R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归
6.r语言中对lasso回归,ridge岭回归和elastic-net模型
R语言估计时变VAR模型时间序列的实证研究分析案例
原文 http://tecdat.cn/?p=3364
加载R包和数据集
上述症状数据集包含在R-package 中,并在加载时自动可用。加载包后,我们将此数据集中包含的12个心情变量进行子集化:
mood_data <- as.matrix(symptom_data$data[, 1:12]) # 变量子集mood_labels <- symptom_data$colnames[1:12] # 变量标签colnames(mood_data) <- mood_labelstime_data <- symptom_data$data_time
对象mood_data是一个1476×12矩阵,测量了12个心情变量:
> dim(mood_data)[1] 1476 12> head(mood_data[,1:7])Relaxed Down Irritated Satisfied Lonely Anxious Enthusiastic[1,] 5 -1 1 5 -1 -1 4[2,] 4 0 3 3 0 0 3[3,] 4 0 2 3 0 0 4[4,] 4 0 1 4 0 0 4[5,] 4 0 2 4 0 0 4[6,] 5 0 1 4 0 0 3
time_data包含有关每次测量的时间戳的信息。数据预处理需要此信息。
head(time_data)date dayno beepno beeptime resptime_s resptime_e time_norm1 13/08/12 226 1 08:58 08:58:56 09:00:15 0.0000000002 14/08/12 227 5 14:32 14:32:09 14:33:25 0.0051648743 14/08/12 227 6 16:17 16:17:13 16:23:16 0.0054705744 14/08/12 227 8 18:04 18:04:10 18:06:29 0.0057820975 14/08/12 227 9 20:57 20:58:23 21:00:18 0.0062857746 14/08/12 227 10 21:54 21:54:15 21:56:05 0.006451726
该数据集中的一些变量是高度偏斜的,这可能导致不可靠的参数估计。在这里,我们通过计算自举置信区间(KS方法)和可信区间(GAM方法)来处理这个问题,以判断估计的可靠性。由于本教程的重点是估计时变VAR模型,因此我们不会详细研究变量的偏度。然而,在实践中,应该在拟合(时变)VAR模型之前始终检查边际分布。
估计时变VAR模型
通过参数lags = 1,我们指定拟合滞后1 VAR模型,并通过lambdaSel =“CV”选择具有交叉验证的参数λ。最后,使用参数scale = TRUE,我们指定在模型拟合之前,所有变量都应缩放为零和标准差1。当使用“1正则化”时,建议这样做,因为否则参数惩罚的强度取决于预测变量的方差。由于交叉验证方案使用随机抽取来定义折叠,因此我们设置种子以确保重现性。
在查看结果之前,我们检查了1476个时间点中有多少用于估算,这在调用控制台中的输出对象时打印的摘要中显示
tvvar_objmgm fit-objectModel class: Time-varying mixed Vector Autoregressive (tv-mVAR) modelLags: 1Rows included in VAR design matrix: 876 / 1475 ( 59.39 %)Nodes: 12Estimation points: 20
估计的VAR系数的绝对值存储在对象tvvar_obj $ wadj中,该对象是维度p×p×滞后×estpoints的数组。
参数估计的可靠性
res_obj <- resample(object = tvvar_obj,data = mood_data,nB = 50,blocks = 10,seeds = 1:50,quantiles = c(.05, .95))
res_obj $ bootParameters包含每个参数的经验采样分布。
计算时变预测误差
函数predict()计算给定mgm模型对象的预测和预测误差。
预测存储在pred_obj $预测中,并且所有时变模型的预测误差组合在pred_obj中:
pred_obj$errorsVariable Error.RMSE Error.R21 Relaxed 0.939 0.1552 Down 0.825 0.2973 Irritated 0.942 0.1194 Satisfied 0.879 0.2015 Lonely 0.921 0.1826 Anxious 0.950 0.0867 Enthusiastic 0.922 0.1698 Suspicious 0.818 0.2479 Cheerful 0.889 0.20010 Guilty 0.928 0.17511 Doubt 0.871 0.26812 Strong 0.896 0.195
可视化时变VAR模型
可视化上面估计的一部分随时间变化的VAR参数:
# 网络图Q <- qgraph(t(mean_wadj), DoNotPlot=TRUE)saveRDS(Q$layout, "Tutorials/files/layout_mgm.RDS")# 选择画图的时间点tpSelect <- c(2, 10, 18)# 设置颜色tvvar_obj$edgecolor[, , , ][tvvar_obj$edgecolor[, , , ] == "darkgreen"] <- c("darkblue")lty_array <- array(1, dim=c(12, 12, 1, 20))lty_array[tvvar_obj$edgecolor[, , , ] != "darkblue"] <- 2for(tp in tpSelect) {qgraph(t(tvvar_obj$wadj[, , 1, tp]),layout = Q$layout,edge.color = t(tvvar_obj$edgecolor[, , 1, tp]),labels = mood_labels,vsize = 13,esize = 10,asize = 10,mar = rep(5, 4),minimum = 0,maximum = .5,lty = t(lty_array[, , 1, tp]),pie = pred_obj$tverrors[[tp]][, 3])}
CIs <- apply(res_obj$bootParameters[par_row[1], par_row[2], 1, , ], 1, function(x) {quantile(x, probs = c(.05, .95))} )# 绘制阴影polygon(x = c(1:20, 20:1), y = c(CIs[1,], rev(CIs[2,])), col=alpha(colour = cols[i], alpha = .3), border=FALSE)}
图显示了上面估计的时变VAR参数的一部分。顶行显示估计点8,15和18的VAR参数的可视化。蓝色实线箭头表示正关系,红色虚线箭头表示负关系。箭头的宽度与相应参数的绝对值成比例。
如果您有任何疑问,请在下面发表评论。
以上是关于R语言上市公司经营绩效实证研究 ——因子分析聚类分析正态性检验信度检验的主要内容,如果未能解决你的问题,请参考以下文章