R语言确定聚类的最佳簇数:3种聚类优化方法|附代码数据
Posted 大数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言确定聚类的最佳簇数:3种聚类优化方法|附代码数据相关的知识,希望对你有一定的参考价值。
原文链接:http://tecdat.cn/?p=7275
最近我们被客户要求撰写关于聚类的研究报告,包括一些图形和统计输出。
确定数据集中最佳的簇数是分区聚类(例如k均值聚类)中的一个基本问题,它要求用户指定要生成的簇数k。
一个简单且流行的解决方案包括检查使用分层聚类生成的树状图,以查看其是否暗示特定数量的聚类。不幸的是,这种方法也是主观的。
我们将介绍用于确定k均值,k medoids(PAM)和层次聚类的最佳聚类数的不同方法。
这些方法包括直接方法和统计测试方法:
- 直接方法:包括优化准则,例如簇内平方和或平均轮廓之和。相应的方法分别称为弯头方法和轮廓方法。
- 统计检验方法:包括将证据与无效假设进行比较。**
除了肘部,轮廓和间隙统计方法外,还有三十多种其他指标和方法已经发布,用于识别最佳簇数。我们将提供用于计算所有这30个索引的R代码,以便使用“多数规则”确定最佳聚类数。
对于以下每种方法:
- 我们将描述基本思想和算法
- 我们将提供易于使用的R代码,并提供许多示例,用于确定最佳簇数并可视化输出。
点击标题查阅往期内容

R语言文本挖掘:kmeans聚类分析上海玛雅水公园景区五一假期评论词云可视化

左右滑动查看更多

01

02

03

04

肘法
回想一下,诸如k-均值聚类之类的分区方法背后的基本思想是定义聚类,以使总集群内变化[或总集群内平方和(WSS)]最小化。总的WSS衡量了群集的紧凑性,我们希望它尽可能小。
Elbow方法将总WSS视为群集数量的函数:应该选择多个群集,以便添加另一个群集不会改善总WSS。
最佳群集数可以定义如下:
- 针对k的不同值计算聚类算法(例如,k均值聚类)。例如,通过将k从1个群集更改为10个群集。
- 对于每个k,计算群集内的总平方和(wss)。
- 根据聚类数k绘制wss曲线。
- 曲线中拐点(膝盖)的位置通常被视为适当簇数的指标。
平均轮廓法
平均轮廓法计算不同k值的观测值的平均轮廓。聚类的最佳数目k是在k的可能值范围内最大化平均轮廓的数目(Kaufman和Rousseeuw 1990)。
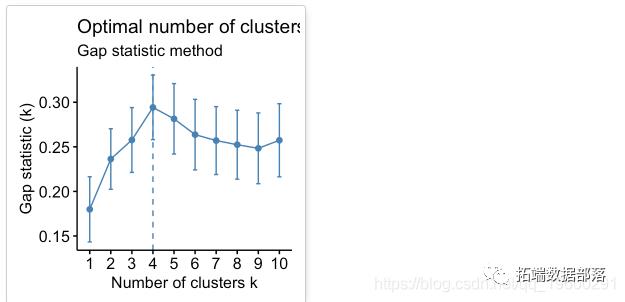
差距统计法
该方法可以应用于任何聚类方法。
间隙统计量将k的不同值在集群内部变化中的总和与数据空引用分布下的期望值进行比较。最佳聚类的估计将是使差距统计最大化的值(即,产生最大差距统计的值)。
资料准备
我们将使用USArrests数据作为演示数据集。我们首先将数据标准化以使变量具有可比性。
r
head(df)
## Murder Assault UrbanPop Rape
## Alabama 1.2426 0.783 -0.521 -0.00342
## Alaska 0.5079 1.107 -1.212 2.48420
## Arizona 0.0716 1.479 0.999 1.04288
## Arkansas 0.2323 0.231 -1.074 -0.18492
## California 0.2783 1.263 1.759 2.06782
## Colorado 0.0257 0.399 0.861 1.86497
Silhouhette和Gap统计方法
简化格式如下:****
下面的R代码确定k均值聚类的最佳聚类数:
r
# Elbow method
fviz_nbclust(df, kmeans, method = "wss") +
geom_vline(xintercept = 4, linetype = 2)+
labs(subtitle = "Elbow method")
# Silhouette method
# Gap statistic
## Clustering k = 1,2,..., K.max (= 10): .. done
## Bootstrapping, b = 1,2,..., B (= 50) [one "." per sample]:
## .................................................. 50

点击标题查阅往期内容

PYTHON链家租房数据分析:岭回归、LASSO、随机森林、XGBOOST、KERAS神经网络、KMEANS聚类、地理可视化

左右滑动查看更多

01
02

03

04

根据这些观察,有可能将k = 4定义为数据中的最佳簇数。
30个索引,用于选择最佳数目的群集
数据:矩阵
- diss:要使用的相异矩阵。默认情况下,diss = NULL,但是如果将其替换为差异矩阵,则距离应为“ NULL”
- distance:用于计算差异矩阵的距离度量。可能的值包括“ euclidean”,“ manhattan”或“ NULL”。
- min.nc,max.nc:分别为最小和最大簇数
- 要为kmeans 计算NbClust(),请使用method =“ kmeans”。
- 要计算用于层次聚类的NbClust(),方法应为c(“ ward.D”,“ ward.D2”,“ single”,“ complete”,“ average”)之一。
下面的R代码为k均值计算 **:
## Among all indices:
## ===================
## * 2 proposed 0 as the best number of clusters
## * 10 proposed 2 as the best number of clusters
## * 2 proposed 3 as the best number of clusters
## * 8 proposed 4 as the best number of clusters
## * 1 proposed 5 as the best number of clusters
## * 1 proposed 8 as the best number of clusters
## * 2 proposed 10 as the best number of clusters
##
## Conclusion
## =========================
## * According to the majority rule, the best number of clusters is 2 .
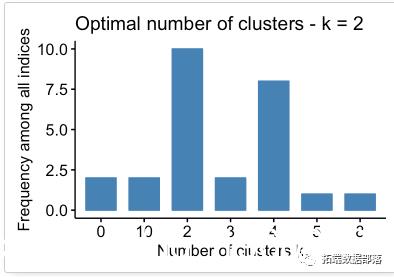
根据多数规则,最佳群集数为2。
点击文末 “阅读原文”
获取全文完整代码数据资料。
本文选自《R语言确定聚类的最佳簇数:3种聚类优化方法》。
点击标题查阅往期内容
PYTHON链家租房数据分析:岭回归、LASSO、随机森林、XGBOOST、KERAS神经网络、KMEANS聚类、地理可视化
【视频】复杂网络分析CNA简介与R语言对婚礼数据聚类社区检测和可视化|数据分享
数据分享|R语言分析上海空气质量指数数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法
R语言文本挖掘:kmeans聚类分析上海玛雅水公园景区五一假期评论词云可视化
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
K-means和层次聚类分析癌细胞系微阵列数据和树状图可视化比较
KMEANS均值聚类和层次聚类:亚洲国家地区生活幸福质量异同可视化分析和选择最佳聚类数
PYTHON实现谱聚类算法和改变聚类簇数结果可视化比较
有限混合模型聚类FMM、广义线性回归模型GLM混合应用分析威士忌市场和研究专利申请数据
R语言多维数据层次聚类散点图矩阵、配对图、平行坐标图、树状图可视化城市宏观经济指标数据
r语言有限正态混合模型EM算法的分层聚类、分类和密度估计及可视化
Python Monte Carlo K-Means聚类实战研究
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
R语言谱聚类、K-MEANS聚类分析非线性环状数据比较
R语言实现k-means聚类优化的分层抽样(Stratified Sampling)分析各市镇的人口
R语言聚类有效性:确定最优聚类数分析IRIS鸢尾花数据和可视化Python、R对小说进行文本挖掘和层次聚类可视化分析案例
R语言k-means聚类、层次聚类、主成分(PCA)降维及可视化分析鸢尾花iris数据集
R语言有限混合模型(FMM,finite mixture model)EM算法聚类分析间歇泉喷发时间
R语言用温度对城市层次聚类、kmean聚类、主成分分析和Voronoi图可视化
R语言k-Shape时间序列聚类方法对股票价格时间序列聚类
R语言中的SOM(自组织映射神经网络)对NBA球员聚类分析
R语言复杂网络分析:聚类(社区检测)和可视化
R语言中的划分聚类模型
基于模型的聚类和R语言中的高斯混合模型
r语言聚类分析:k-means和层次聚类
SAS用K-Means 聚类最优k值的选取和分析
用R语言进行网站评论文本挖掘聚类
基于LDA主题模型聚类的商品评论文本挖掘
R语言鸢尾花iris数据集的层次聚类分析
R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
R语言聚类算法的应用实例
数据分析 第六篇:聚类的评估(簇数确定和轮廓系数)和可视化
在实际的聚类应用中,通常使用k-均值和k-中心化算法来进行聚类分析,这两种算法都需要输入簇数,为了保证聚类的质量,应该首先确定最佳的簇数,并使用轮廓系数来评估聚类的结果。
一,k-均值法确定最佳的簇数
通常情况下,使用肘方法(elbow)以确定聚类的最佳的簇数,肘方法之所以是有效的,是基于以下观察:增加簇数有助于降低每个簇的簇内方差之和,给定k>0,计算簇内方差和var(k),绘制var关于k的曲线,曲线的第一个(或最显著的)拐点暗示正确的簇数。
1,使用sjc.elbow()函数计算肘值
sjPlot包中sjc.elbow()函数实现了肘方法,用于计算k-均值聚类分析的肘值,以确定最佳的簇数:
library(sjPlot) sjc.elbow(data, steps = 15, show.diff = FALSE)
参数注释:
- steps:最大的肘值的数量
- show.diff:默认值是FALSE,额外绘制一个图,连接每个肘值,用于显示各个肘值之间的差异,改图有助于识别“肘部”,暗示“正确的”簇数。
sjc.elbow()函数用于绘制k-均值聚类分析的肘值,该函数在指定的数据框计算k-均值聚类分析,产生两个图形:一个图形具有不同的肘值,另一个图形是连接y轴上的每个“步”,即在相邻的肘值之间绘制连线,第二个图中曲线的拐点可能暗示“正确的”簇数。
绘制k均值聚类分析的肘部值。 该函数计算所提供的数据帧上的k均值聚类分析,并产生两个图:一个具有不同的肘值,另一个图绘制在y轴上的每个“步”(即在肘值之间)之间的差异。 第二个图的增加可能表明肘部标准。
library(effects) library(sjPlot) library(ggplot2) sjc.elbow(data,show.diff = FALSE)
从下面的肘值图中,可以看出曲线的拐点大致在5附近:
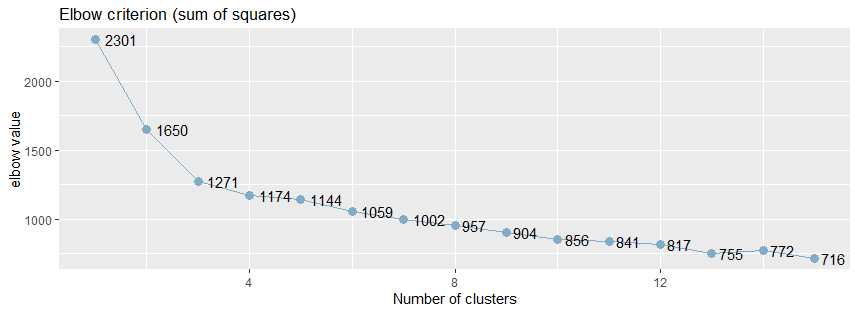
2,使用NbClust()函数来验证肘值
从上面肘值图中,可以看到曲线的拐点是3,还可以使用NbClust包种的NbClust()函数,默认情况下,该函数提供了26个不同的指标来帮助确定簇的最终数目。
NbClust(data = NULL, diss = NULL, distance = "euclidean", min.nc = 2, max.nc = 15, method = NULL, index = "all", alphaBeale = 0.1)
参数注释:
- diss:相异性矩阵(dissimilarity matrix),默认值是NULL,如果diss参数不为NULL,那么忽略distance参数。
- distance:用于计算相异性矩阵的距离度量,有效值是: "euclidean", "maximum", "manhattan", "canberra", "binary", "minkowski" 和"NULL"。如果distance不是NULL,diss(相异性矩阵)参数必须为NULL。
- min.nc:最小的簇数
- max.nc:最大的簇数
- method:用于聚类分析的方法,有效值是:"ward.D", "ward.D2", "single", "complete", "average", "mcquitty", "median", "centroid", "kmeans"
- index:用于计算的指标,NbClust()函数提供了30个指数,默认值是"all",是指除GAP、Gamma、Gplus 和 Tau之外的26个指标。
- alphaBeale:Beale指数的显著性值
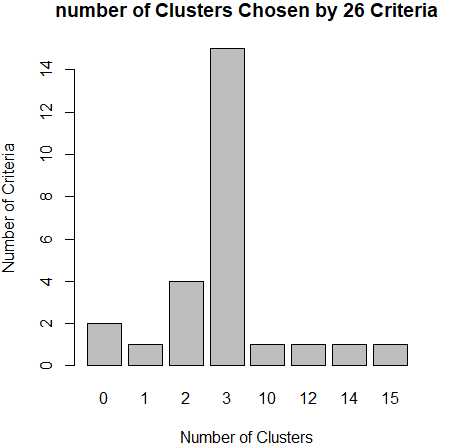
利用NbClust()函数来确定k-均值聚类的最佳簇数:
library(NbClust) nc <- NbClust(data,min.nc = 2,max.nc = 15,method = "kmeans") barplot(table(nc$Best.nc[1,]),xlab="Number of Clusters",ylab="Number of Criteria",main="number of Clusters Chosen by 26 Criteria")
从条形图种,可以看到支持簇数为3的指标(Criteria)的数量是最多的,因此,基本上可以确定,k-均值聚类的簇数目是3。
二,k-中心化确定最佳簇数
k-中心化聚类有两种实现方法,PAM和CLARA,PAM适合在小型数据集上运行,CLARA算法基于抽样,不考虑整个数据集,而是使用数据集的一个随机样本,然后使用PAM方法计算样本的最佳中心点。
通过fpc包中的pamk()函数得到最佳簇数:
pamk(data,krange=2:10,criterion="asw", usepam=TRUE, scaling=FALSE, alpha=0.001, diss=inherits(data, "dist"), critout=FALSE, ns=10, seed=NULL, ...)
参数注释:
- krange:整数向量,用于表示簇的数量
- criterion:有效值是:"asw"(默认值)、 "multiasw" 和 "ch"
- usepam:逻辑值,如果设置为TRUE,那么使用pam算法,如果为FALSE,那么使用clara算法。
- scaling:逻辑值,是否对数据进行缩放(标准化),如果设置为FALSE,那么不对data参数做任何缩放;如果设置为TRUE,那么对data参数通过把(中间)变量除以它们的均方根来完成缩放。
- diss:逻辑值,如果设置为TRUE,表示data参数是相异性矩阵;如果设置为FALSE,那么data参数是观测矩阵。
使用pamk()函数获得PAM或CLARA聚类的最佳簇数:
library(fpc) pamk.best <- pamk(dataset) pamk.best$nc
通过cluster包中的clusplot()函数来查看聚类的结果:
library(cluster)
clusplot(pam(dataset, pamk.best$nc))
三,评估聚类的质量(轮廓系数)
使用数据集中对象之间的相似性度量来评估聚类的质量,轮廓系数(silhouette coefficient)就是这种相似性度量,是簇的密集与分散程度的评价指标。轮廓系数的值在-1和1之间,该值越接近于1,簇越紧凑,聚类越好。当轮廓系数接近1时,簇内紧凑,并远离其他簇。
如果轮廓系数sil 接近1,则说明样本聚类合理;如果轮廓系数sil 接近-1,则说明样本i更应该分类到另外的簇;如果轮廓系数sil 近似为0,则说明样本i在两个簇的边界上。所有样本的轮廓系数 sil的均值称为聚类结果的轮廓系数,是该聚类是否合理、有效的度量。
1,fpc包
包fpc中实现了计算聚类后的一些评价指标,其中就包括了轮廓系数:avg.silwidth(平均的轮廓宽度)
library(fpc) result <- kmeans(data,k) stats <- cluster.stats(dist(data)^2, result$cluster) sli <- stats$avg.silwidth
2,silhouette()函数
包cluster中计算轮廓系数的函数silhouette(),返回聚类的平均轮廓宽度:
silhouette(x, dist, dmatrix, ...)
参数注释:
- x:整数向量,是聚类算法的结果
- dist:相异性矩阵(是dist()函数计算的结果),如果dist参数不指定,那么dmatrix参数必须指定;
- dmatrix:对称性的相异性矩阵,用于代替dist参数,比dist参数更有效率
使用silhouette()计算轮廓系数:
library (cluster) library (vegan) #pam dis <- vegdist(data) res <- pam(dis,3) sil <- silhouette (res$clustering,dis) #kmeans dis <- dist(data)^2 res <- kmeans(data,3) sil <- silhouette (res$cluster, dis)
四,聚类的可视化
聚类的结果,可以试用ggplot2来可视化,还可以使用的一些聚类包中特有的函数来实现:factoextra包,sjPlot包和cluster包
1,cluster包
clusplot()函数
2,sjPlot包
sjc.qclus()函数
3,factoextra包
该包中的两个函数十分有用,一个用于确定最佳的簇数,一个用于可视化聚类的结果。
(1),确定最佳的簇数fviz_nbclust()
函数fviz_nbclust(),用于划分聚类分析中,使用轮廓系数,WSS(簇内平方误差和)确定和可视化最佳的簇数
fviz_nbclust(x, FUNcluster = NULL, method = c("silhouette", "wss",), diss = NULL, k.max = 10, ...)
参数注释:
- FUNcluster:用于聚类的函数,可用的值是: kmeans, cluster::pam, cluster::clara, cluster::fanny, hcut等
- method:用于评估最佳簇数的指标
- diss:相异性矩阵,由dist()函数产生的对象,如果设置为NULL,那么表示使用 dist(data, method="euclidean") 计算data参数,得到相异性矩阵;
- k.max:最大的簇数量,至少是2
例如,使用kmenas进行聚类分析,使用平均轮廓宽度来评估聚类的簇数:
library(factoextra) fviz_nbclust(dataset, kmeans, method = "silhouette")
(2),可视化聚类的结果
fviz_cluster()函数用于可是化聚类的结果:
fviz_cluster(object, data = NULL, choose.vars = NULL, stand = TRUE, axes = c(1, 2), geom = c("point", "text"), repel = FALSE, show.clust.cent = TRUE, ellipse = TRUE, ellipse.type = "convex", ellipse.level = 0.95, ellipse.alpha = 0.2, shape = NULL, pointsize = 1.5, labelsize = 12, main = "Cluster plot", xlab = NULL, ylab = NULL, outlier.color = "black", outlier.shape = 19, ggtheme = theme_grey(), ...)
参数注释:
- object:是聚类函数计算的结果
- data:原始对象数据集
使用fviz_cluster()把聚类的结果显示出来:
km.res <- kmeans(dataset,3) fviz_cluster(km.res, data = dataset)
参考文档:
以上是关于R语言确定聚类的最佳簇数:3种聚类优化方法|附代码数据的主要内容,如果未能解决你的问题,请参考以下文章