Python 超简单爬取新浪微博数据 (高级版)
Posted shannian999
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 超简单爬取新浪微博数据 (高级版)相关的知识,希望对你有一定的参考价值。
新浪微博的数据可是非常有价值的,你可以拿来数据分析、拿来做网站、甚至是*****。不过很多人由于技术限制,想要使用的时候只能使用复制粘贴这样的笨方法。没关系,现在就教大家如何批量爬取微博的数据,大大加快数据迁移速度!
我们使用到的是第三方作者开发的 爬虫 库 weiboSpider(有 工具 当然要用 工具 啦)。这里默认大家已经装好了Python,如果没有的话可以看我们之前的文章: Python详细安装指南 。

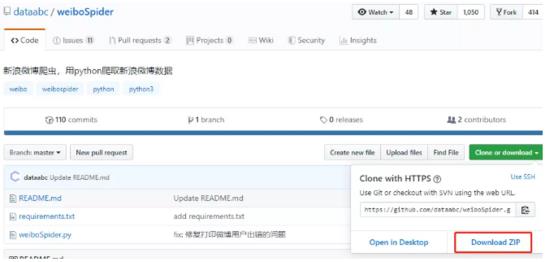
1. 下载项目
进入下方的网址,点击Download ZIP下载项目文件
或者
你有git的话可以在cmd/terminal中输入以下命令安装?
git clone https://github.com/dataabc/weiboSpider.git
复制代码
?2.安装依赖
将该项目压缩包解压后,打开你的cmd/Termianl进入该项目目录,输入以下命令:
pip install -r requirements.txt
复制代码
便会开始安装项目依赖,等待其安装完成即可。
3.设置cookie
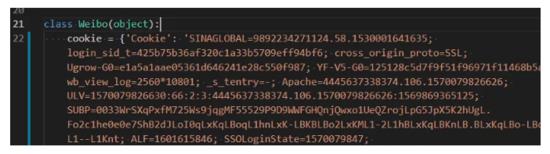
打开weibospider文件夹下的weibospider.py文件,将"your cookie"替换成 爬虫 微博的cookie,具体替换位置大约在weibospider.py文件的22行左右。cookie获取方法:
3.1 登录微博
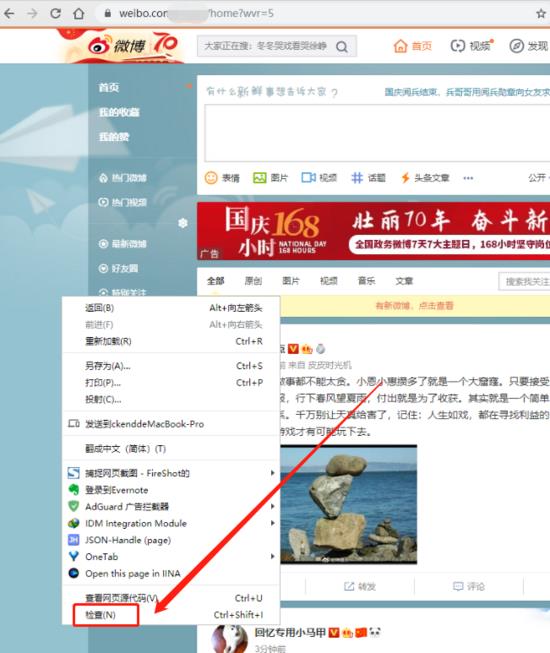
3.2 按F12键或者右键页面空白处—检查,打开开发者 工具
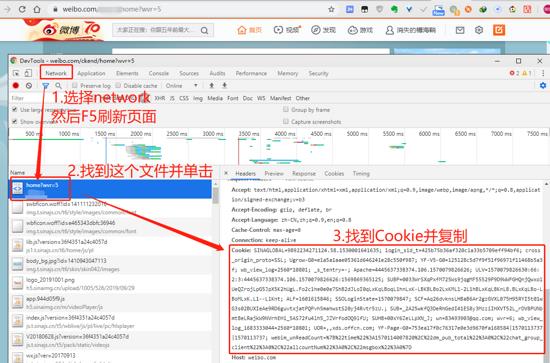
3.3 选择****network — 按F5刷新一下 — 选择第一个文件 — 在右边窗口找到cookie
然后替换大约在weibospider.py文件的22行左右的cookie,如图所示:
替换前:

替换后:
4.设置要爬的用户user_id
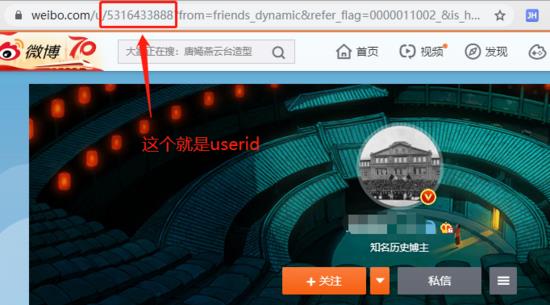
4.1 获取user_id
点开你希望爬取的用户主页,然后查看此时的url:
你会发现有一串数字在链接中,这个就是我们要用到的userID, 复制即可。
4.2 设置要爬取的user_id
打开 config.json 文件,你会看到如下内容:
{
"user_id_list": ["1669879400"],
"filter": 1,
"since_date": "2018-01-01",
"write_mode": ["csv", "txt"],
"pic_download": 1,
"video_download": 1,
"cookie": "your cookie",
"mysql_config": {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "123456",
"charset": "utf8mb4"
}
}
复制代码
下面讲解每个参数的含义与设置方法。
设置user_id_list:user_id_list是我们要爬取的微博的id,可以是一个,也可以是多个,例如:
"user_id_list": ["1223178222", "1669879400", "1729370543"],
上述代码代表我们要连续爬取user_id分别为“1223178222”、 “1669879400”、 “1729370543”的三个用户的微博。
user_id_list的值也可以是文件路径,我们可以把要爬的所有微博用户的user_id都写到txt文件里,然后把文件的位置路径赋值给user_id_list。
在txt文件中,每个user_id占一行,也可以在user_id后面加注释(可选),如用户昵称等信息,user_id和注释之间必需要有空格,文件名任意,类型为txt,位置位于本程序的同目录下,文件内容示例如下:
1223178222 胡歌 1669879400 迪丽热巴 1729370543 郭碧婷
假如文件叫user_id_list.txt,则user_id_list设置代码为:
"user_id_list": "user_id_list.txt",
如果有需要还可以设置Mysql数据 库 和MongoDB数据 库 写入,如果不设置的话就默认写入到txt和csv文件中。
5. 运行 爬虫
打开cmd/terminal 进入该项目目录,输入:
python weibospider.py
复制代码
即可开始爬取数据了,怎么样,是不是超级方便?而且你还可以自定义爬取的信息,比如微博的起始时间、是否写入数据 库 ,甚至能在它代码的基础上增加新的功能!(比如加个cookie池或者代理池之类的)
以上是关于Python 超简单爬取新浪微博数据 (高级版)的主要内容,如果未能解决你的问题,请参考以下文章