[重读经典论文]VIT
Posted 大师兄的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[重读经典论文]VIT相关的知识,希望对你有一定的参考价值。
参考博客:Vision Transformer详解
参考视频:11.1 Vision Transformer(vit)网络详解
基本流程:
- 提取embedding:将原图分为若干patch,使用convnet提取每个patch的特征作为embedding,然后在前面concat一个用来分类的embedding,之后每个patch加上一个位置编码。
- tranformer encode:将上一步的embedding直接喂入堆叠的transformer模块,进行encode操作。
- 提取分类特征:将分类的特征切片,并在后面增加一个mlp网络进行分类。
纯Vit和Hybrid的区别就是前面提取embedding是用一个简单的conv模块还是使用ResNet50(论文中是改造后)的复杂模型。

Vision Transformer(ViT)论文解读与代码复现(基于paddle框架)
文章目录
前言
VIT模型,其开创性的工作是:使用了一种纯粹的transformer结构,正如其论文名称所示:AN IMAGE IS WORTH 16X16 WORDS,其将图片经过embedding处理成一串sequence,经过多个encoder结构与head实现了能够媲美CNN中SOTA模型的效果。

CNN已经统治各大图像任务榜许久,之前有时会认为CNN结构就是最优的结构,但是似乎近期的数据已经打了脸,为什么这样说?paperwithcode的各大图像任务排行榜中(例如分割、检测),基于transformer的模型已经占据各大排行榜榜首甚至前十,真实的数据摆在这里, 我们不禁要问:我们是不是要告别CNN时代了? 这里只是抛出一个疑问,也是编者自己的疑问。
我们这篇文章是分析VIT的,下面正式开始介绍VIT模型。
随着transformer在各大nlp领域挑战RNN,并且伴随着BERT与GPT模型的发布,transformer在大规模的模型中表现出其优秀的下游任务的泛化能力和大规模数据下仍未饱和的“胃口”,慢慢的,CV领域也开始被注意。
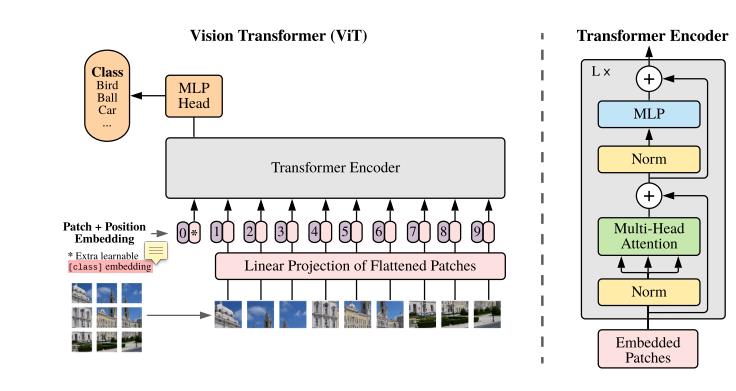
如图所示,相信有过transformer学习经历的朋友直接一眼就可以看出作者模型的架构,这个图简单易懂。VIT由将图片进行patch embedding,也就是将图片分成多个块(patch),然后通过embedding,将每个patch展开为sequence序列。同时作者为了进行分类任务,引入了一个额外的class token,也就是输入序列的0位置的向量,用作分类任务。HEAD由一个多头注意力以及mlp层进行种类预测,整体结构简单明了,让人有一种如沐春风的感觉。
一. 摘要

作者先引出了注意力机制在nlp领域取得的成就,随后出现了一些基于注意力机制与卷积的混合模型,而作者摒弃传统的CNN结构,提出了一种基于纯粹transformer的模型。在实验方面,作者利用在大型数据集上训练并迁移到中小尺度的数据集进行效果验证,其性能能够与当前的SOTA卷积网络模型相媲美,并且需要更少的算力(这里指的是2500天tpu v3的天数,足以见到作者的雄厚财力)
二. 引言
2.1 本部分主要介绍
- transformer在nlp领域的现状,解释了为什么它能够在最近的论文中统治nlp领域,也就是它的优点
- 在图像领域transformer的应用现状,存在仍带有图像的偏置假设,并且难以在现代gpu上加速的问题,引出作者的工作,也就是动机,也算是说明了作者要解决的问题:hybrid结构并不能在cv中胜过全cnn结构,或者说作者想尝试一下纯粹的transformer结构能够在视觉任务中表现出比VNN更好的效果。
- 介绍了作者提出的结构特点,提出并解决了实验过程中的重要问题,即在同等数据集下,VIT的表现总是比CNN结构性能要低一些(如下面英文简摘所示),在最后,作者展示了自己模型的绝佳表现。
When pre-trained on the public ImageNet-21k dataset or the in-house JFT-300M dataset, ViT
approaches or beats state of the art on multiple image recognition benchmarks. In particular,
the best model reaches the accuracy of 88.55% on ImageNet, 90.72% on ImageNet-ReaL, 94.55%
on CIFAR-100, and 77.63% on the VTAB suite of 19 tasks.
2.2 归纳偏置(inductive biases)
作者在文章中,多次提到了归纳偏置,其实也就是在说卷积。在传统卷积中,我们引入了两个假设,也就是引入了先验:
- 平移不变性:训练出来的卷积核在面对同样的图片时,表现或者生成的特征图是相似的,或者说只对图片中某种东西感兴趣。
- 局部性相关性:卷积核在滑动的过程中,相邻的两个生成像素点之间因为权值共享的原因,是相关的。
引入以上两点假设,我们人为的给模型带来了先验知识。因此,作者为了去除这种人为的假设。另一种观点,为了弥补transformer去除归纳偏置带来的性能下降,作者增加大量的训练数据去弥补,其实就是用更多的数据学习这两种归纳偏置,是否有种捡了西瓜丢了芝麻之意,这里见仁见智,作者本身是给我们带来另一种思考的方式。
2.3 相关工作
记住了沐神课堂上一句话:
相关工作这边写的很多,并不会让你的工作显得非常少和简单,反而会让你的论文更加简单易懂。
2.3.1 简要介绍
-
先写transformer在nlp领域的最新进展,然后提出了transformer在图像领域的相关工作及问题:例如将图像按照像素大小直接展开时带来的计算灾难,局部注意力机制,sparse transformer,或者只对单个坐标轴的像素采取注意力等方法,但是这些方法都存在一个问题,难以运用于现代gpu上,因为其预处理步骤太过于繁琐,作者所求,即是简介。
-
提出与自己最相近的相关工作并进行对比:一是前人提出的patch size过小,因此只能应用于小分辨率的图像,二是作者在大型数据集上做预训练,使其能够达到SOTA的效果。
-
写出了另一种思路:hybrid mathod,DETR就是将resnet作为backbone,将特征图作为输入序列。
-
写出最近的一些进展:iGPT。
最后作者分析大型的数据集而不是像standard ImageNet dataset这种标准的数据集,对于模型训练的作用,作者举出了一些目前对于cnn在不同尺度的数据集下的性能表现。
总结来说,作者分析了为什么要提出这种纯粹transformer的结构的原因,另一方面,给出了目前视觉transformer受bert影响而诞生的igpt,最后说明了大型的数据集对于模型性能的重要作用。
三. 方法 & 复现
3.1 图片处理

第一步:原始输入图片为(H, W, C)大小,首先将其进行分割,假设分割成P大小的正方形块:
第二步:N为分割的块数,也是patch的数量,将图片进行展平,也就是展成2Dpatch,N 个 P² * C大小的patch。
第三步:加入位置向量和class token向量,其中位置向量是可学习的参数。
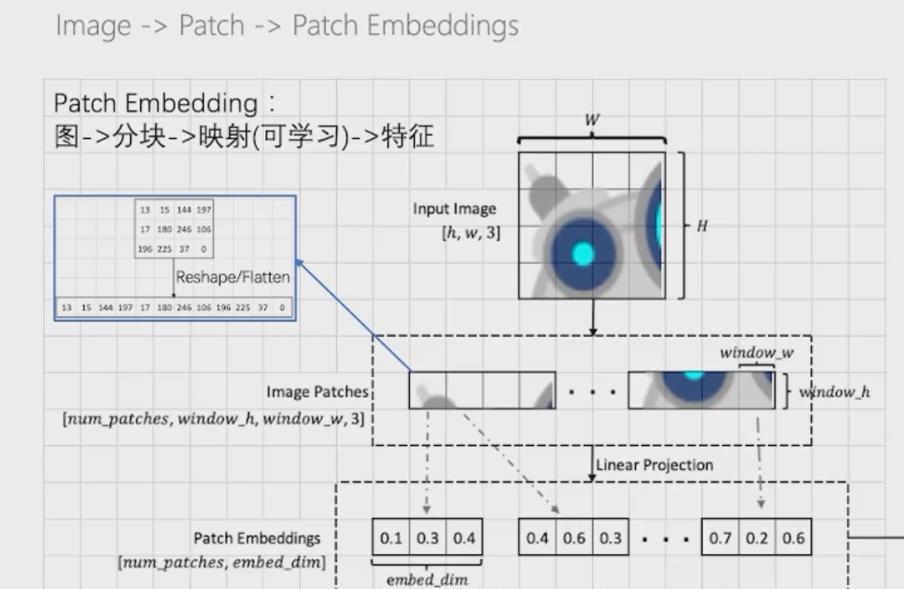
3.1.1 复现(基于paddlepaddle框架)
patch embedding
#patch embedding流程
class PatchEmbedding(nn.Layer):
def __init__(self, image_size=224, patch_size=16, in_channels=3, embed_dim=768, dropout=0.):
super().__init__()
self.embed_dim = embed_dim
n_patches = (image_size // patch_size) * (image_size // patch_size)
self.patch_embedding = nn.Conv2D(in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size)
self.dropout = nn.Dropout(dropout)
# TODO: add class token
self.class_token = paddle.create_parameter(#这里加入可学习的class token向量作为分类等下游任务使用
shape = [1, 1, embed_dim],
dtype = 'float32',
default_initializer = nn.initializer.Constant(0.),
)
# TODO: add position embedding
self.position_embedding = paddle.create_parameter(#加入可学习的位置向量
shape = [1, n_patches + 1, embed_dim],
dtype='float32',
default_initializer=nn.initializer.TruncatedNormal(std=.02)
)
def forward(self, x):
# [n, c, h, w] 原始图片大小:每个batch中含有n张图片,每张为h * w * c
class_token = self.class_token.expand([x.shape[0], 1, self.embed_dim])#由于输入的图片大小是不固定的,所以用expand
#这里进行图片的分割,用卷积达到类似的效果,当stride=kernel_size的时候,生成的就是patch
x = self.patch_embedding(x)
x = x.flatten(2)
x = x.transpose([0, 2, 1])
x = paddle.concat([class_token, x], axis=1)
#加位置向量
x = x + self.position_embedding
return x
完成了上一段,就完成了对图片的编码,至此,我们可以将返回的tensor输入到attention layer中计算。
attention layer
这一段,我们主要复现attention的部分:
#attention部分,将上一段代码返回的patch embedding输入到attention layer中
class Attention(nn.Layer):
"""multi-head self attention"""
def __init__(self, embed_dim, num_heads, qkv_bias=True, dropout=0., attention_dropout=0.):
super().__init__()
self.num_heads = num_heads
self.head_dim = int(embed_dim / num_heads)#计算头数
self.all_head_dim = self.head_dim * num_heads
self.scales = self.head_dim ** -0.5#计算缩放因子,也就是根号下dk
#qkv初始化
self.qkv = nn.Linear(embed_dim,
self.all_head_dim * 3,
bias_attr=False if qkv_bias is True else None
)
#这里的linear层主要是起到mlp最后输出的作用
self.proj = nn.Linear(embed_dim, embed_dim)
self.dropout = nn.Dropout(dropout)
self.attention_dropout = nn.Dropout(attention_dropout)
self.softmax = nn.Softmax(axis=-1)
def transpose_multihead(self, x):#这个函数将x转化为需要的格式
# x: [N, num_patches, all_head_dim] -> [N, n_heads, num_patches, head_dim]
new_shape = x.shape[:-1] + [self.num_heads, self.head_dim]
x = x.reshape(new_shape)
x = x.transpose([0, 2, 1, 3])
return x
def forward(self, x):
# TODO
B, N, _ = x.shape
qkv = self.qkv(x).chunk(3, -1)
q, k, v = map(self.transpose_multihead, qkv)
atten = paddle.matmul(q, k, transpose_y = True)#计算注意力
atten = atten * self.scales#尺度缩放
atten = self.softmax(atten)
out = paddle.matmul(atten, v)#注意力矩阵计算
out = out.transpose([0, 2, 1, 3])
out = out.reshape([B, N, -1])
#out:[b, n, num_heads * head_dim]
out = self.proj(out)
return out
VIT前向部分
class ViT(nn.Layer):
def __init__(self):
super().__init__()
self.patch_embed = PatchEmbedding(224, 7, 3, 16)
layer_list = [EncoderLayer(16) for i in range(5)]#stack五层的encoder,每个的输入维度(embedding)大小是16
self.encoders = nn.LayerList(layer_list)
self.head = nn.Linear(16, 10)#这里是分类层,输入为16维度,输出10维,即一共分为十类
self.avgpool = nn.AdaptiveAvgPool1D(1)#这里是1维的average pool,就是为了把所有的patch输出取平均进行分类
def forward(self, x):
x = self.patch_embed(x) # [n, h*w, c]: 4, 1024, 16
for encoder in self.encoders:
x = encoder(x)#多个encoder叠加
# avg
x = x.transpose([0, 2, 1])#转置[n, h * w, c] 转为[n, c, h * w]
x = self.avgpool(x)#[n, c, 1]
x = x.flatten(1)#[n*c],也就是[16, 1]
x = self.head(x)
return x
综上,完成了从图片的patch embedding到最后的分类结果预测的前向结构复现。
3.2 FINE-TUNING AND HIGHER RESOLUTION:模型微调与高分辨率图像处理
这一部分名字叫:微调与高分辨率,很适合作者所做出的成果,一方面,作者在大数据集上进行预训练并迁移到小数据集达到了benchmark上的sota效果,另一方面,作者还通过调整patch大小(大于前人所用的2×2),来达到消耗较少的计算资源情况下处理高分辨率的图像。

作者提到,如果将VIT训练好的模型应用于下游任务,只需要将预测的HEAD头去掉,然后将VIT后面连接一个D*K的零初始化的前向预测层(D是层数,K是下游任务的类别数量),就可以实现下游任务。同时,VIT能够处理任意长度的序列,序列的长度受到patch大小和内存的限制(patch会暂时放到内存中计算),但是变长会导致预训练好的位置编码无效,需要重新训练。
作者比对了位置编码1D与2D编码(如下图)的异同,通过比较,作者并没有发现两种编码方式所带来的性能差异较大,同时作者认为2D编码会引入图像的归纳偏置问题,背离了作者想摒弃归纳偏置的初衷。
四. 实验

作者与ResNet为代表的纯卷积方法与 Hybrid(混合模型) 做了性能对比实验,同时作者为了说明每种模型对于数据量的需求程度,将其在不同大小的数据集上进行训练并迁移到不同benchmark验证效果,事实证明,其以更低的预训练花费达到了SOTA效果。作者也对自监督式的训练表现出了期望。
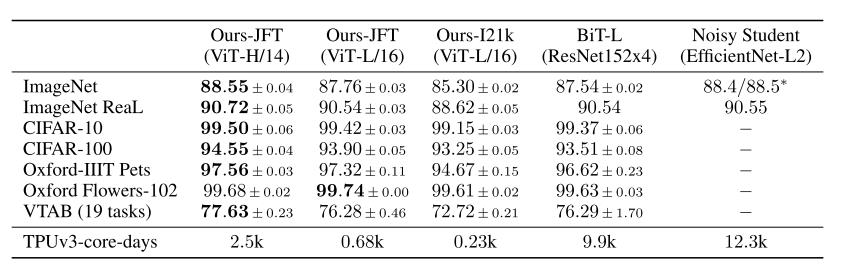
以下为作者设计的三种不同大小的模型,其规模大小和参数大小设置了不同的尺度。
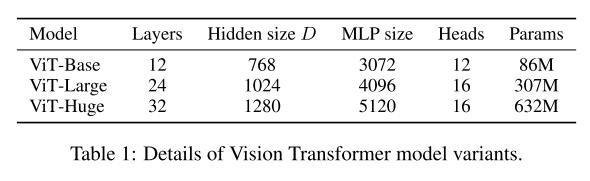
可以看到,在VIT-HUGE版本上,在imagenet作为benchmark中,作者的模型性能超过了ResNet一个多百分点,而需要训练的天数也低于resnet的9.9k。
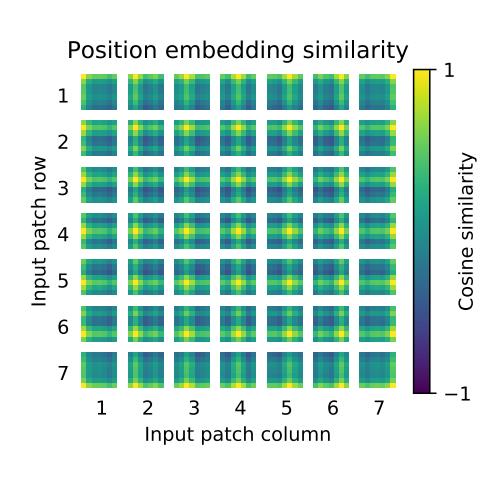
下图是作者为了更加方便理解VIT内部对于图像的处理机制,进行了可视化输出。

下图是作者将学习后的位置编码可视化后的结果(选取了前28个主成分),图像显示,相邻位置的位置编码相似程度更高。
同时,实验显示,如下图所示,越深的层,多头注意力的head对于全局的注意力范围越远,这其实就像cnn,越深的层数,对于特征的抽象程度越高,能看到范围更大的特征,感受野越大。

总结与评价
整体来说,作者提出的transformer在对视觉transformer的贡献上已经可以说是起到了一个里程碑的作用,后面很多的提出的用于各类下游任务的模型都是基于这个结构。
但是模型结构仍然存在以下几点问题:一是由于对图像分块进行检测,虽然降低了计算消耗,提高了对高分辨率图像的处理能力,但是对于小目标检测却较为乏力,这一点在后面的swin transformer提出了有了改进。二是以及训练数据以及算力要求过高的问题,这一点同样在DEIT中进行了改进。
但是这里就像alexnet提出时一样,任何新提出的革命性模型,都要经过提出 - 发现问题 - 改进完善的过程,就像最近占据榜首的swin transformer等,都是在此基础上进行打补丁等的操作。
作者的贡献具体来说主要分为两点:
1.作者相对前面基于视觉transformer的模型,引入patch,避免了引入卷积带来的的归纳偏置,加入了可学习的图像位置编码。
2.作者证明了VIT在大型数据集训练后迁移到小数据集上的可行性,并可以媲美SOTA的CNN结构。
同时作者做出了展望:
1.下游任务:分割,检测等能够进一步展开。
2.对自监督预训练方法的探索。
以上是关于[重读经典论文]VIT的主要内容,如果未能解决你的问题,请参考以下文章