sessiontokenJWT的一文详细介绍
Posted 张颖辉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sessiontokenJWT的一文详细介绍相关的知识,希望对你有一定的参考价值。
一文带你了解Hive详细介绍Hive与传统数据库有什么区别?
前期回顾:
⼤数据是如何产⽣的?大数据的特点是什么?什么是埋点?如何进行数据埋点?【超详细介绍】
一文搞懂什么是数据仓库(Data Warehouse)数据仓库与数据库区别有哪些?什么是元数据?
本期终于要给大家介绍Hive了,为此我还花了好几个小时的写了如何安装Hive的博客,希望大家能喜欢这篇博客。
1 什么是Hive?
首先给大家介绍一下什么是Hive。
Hive是Facebook为了解决海量数据的统计分析,而开发的基于Hadoop的一个数据分析工具(也就证明了Hive没有存储数据的能力,它只有使用数据的能力),而且是将结构化的数据文件映射为一张数据库表(结构化是它对于存储在HDFS上的数据的一个要求,其他的文件是不能映射为Hive表),而且它提供的是类SQL查询功能,所以在数据使用的时候给我们提供了很大的方便。
所以HQL其实就是Hive缩写为H,Query缩写为Q,Language缩写为L。
由于Hive是一个数据仓库工具,没有数据存储功能,它的数据是从HDFS来获得的,但是它又不能直接从HDFS进行数据访问,它是通过MapReduce来实现的,本质上也就是将HQL语句转换为MapReduce的任务,然后来进行数据访问。
将HQL语句转换为MapReduce任务进行运行的流程如下:

在搭建Hive数据仓库时,将相关语句常用的指令操作,比如SELECT、FROM、WHERE以及函数用MapReduce写成模板,并且将这些所有的MapReduce的模板封装到Hive中。这是我们在搭建Hive数据仓库的时候就形成的。
那我们所要做的,如我们是客户,根据业务需求编写相应的SQL语句,它会自动地到Hive封装的这些MapReduce中去匹配。匹配完之后就运行MapReduce程序,生成相应的分析结果,然后反馈给我们。
总之就是做离线数据分析时,Hive要比直接使用MapReduce开发效率更高。
2 为什么使用Hive?
看到这里可能就会朋友疑惑了,为什么Hive要比直接使用MapReduce开发效率更高?
- 首先,直接使用MapReduce面临的问题是学习成本比较高,因为他要学习Java或者是Python,而且MapReduce实现复杂的查询逻辑的时候,开发难度会相对大。那如果我们使用Hive的HQL语句呢,接口采用的是类SQL语法,所以它能启动快速的开发功能,因为掌握SQL语句的人要比掌握Java或者Python的人要多。
- 第二个就是避免了去写MapReduce,减少了开发人员的学习成本。
- 还有一个就是功能扩展比较方便。
3 Hive的优缺点
其实优缺点的话在上文就介绍得七七八八了。
3.1 Hive的优点
- 节省学习成本;
- 在数据处理方面,Hive语句最终会生成MapReduce任务去计算,常用于离线数据分析,对数据实时性要求不高的场景(其实这里就是在说Hive本身的用途,它就是做离线数据分析的);
- 在数据存储方面,它能够存储很大的数据集(实际上它是不存储数据的,这里的“很大的数据集”实际上指的是HDFS),并且它对数据完整性和格式要求不严格(只要是结构化的就可以了);
- 再看延展性。Hive支持用户自定义函数(MySQL、SqlServer也支持),用户可以根据自身需求实现相应函数。
3.2 Hive的缺点
- HQL本身表达能力有限,也就是当我们的逻辑需求特别复杂的时候,我们还是要借助MapReduce;
- Hive操作默认基于MapReduce引擎,而MapReduce引擎与其它的引擎(如spark引擎)相比,特点就是慢、延迟高、不适合交互式查询,所以Hive也有这个缺点(但是注意这里讲的只是默认,是可以更改成其他引擎的)。
4 Hive的架构
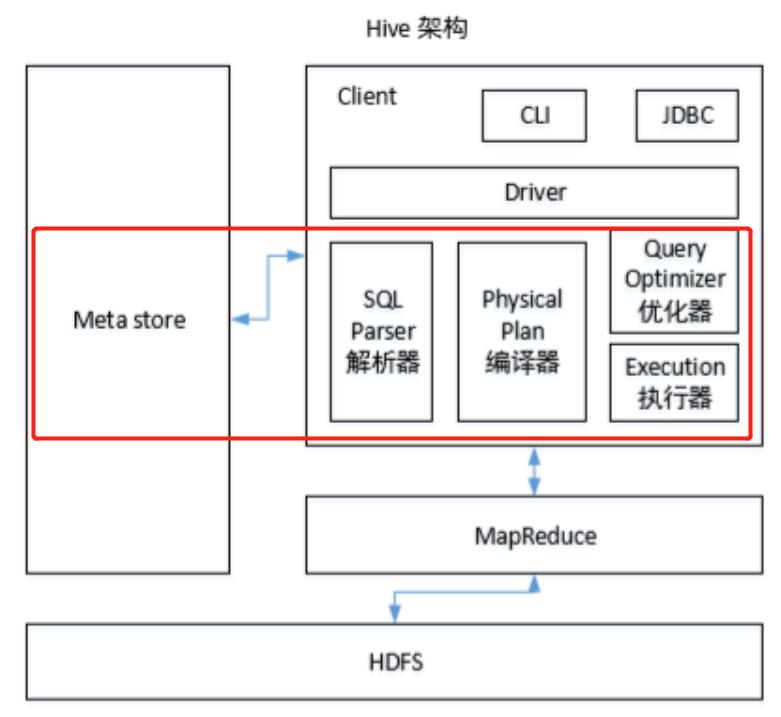
如图,底层的MapReduce还有HDFS,在这里是Hadoop的组件,和Hive没有关系。对于上面的Client部分,属于应用层,和Hive也没有关系。
而图中圈红的才是Hive的部分。
- 左侧的元数据在这里的作用是存储了与HDFS的映射关系。我们在做Hive介绍的时候我们知道Hive是Hadoop的一个数据仓库工具,它可以将结构化的数据映射为一张表,这里结构化的数据是存储在HDFS上的一个数据文件。所以说这里的元数据保存的就是Hive当中的表与HDFS的映射关系。
- 接着来看解析器,它其实就是对我们写的HQL语句进行基本检验(语法检验之类);
- 编译器就是将HQL语句翻译成MapReduce语句(默认MapReduce,可更改),也就是生成逻辑执行计划;
- 优化器会根据编写的语句进行MapReduce的优化。我们知道在在HQL转换为MapReduce的时候,是封装了很多的模板的。而随着Hive的更新迭代,模板是越来越多的,所以是需要优化的;
- 执行器呢,就是把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来说,就是MapReduce/Spark。
再下来看Hive的运行机制。

对于数据仓库来说,用户使用无非就是提取数据然后得到相应的分析结果。
那提取数据的方式呢,由于Hive提供的是类SQL语句,而MySQL提取数据就是SELECT…FROM,所以Hive也是一样。提取后就是将SELECT语句解析成MapReduce程序,然后使用MapReduce框架进行运行,就能给我们返回相应的结果了。
在看图左边。用户创建表(和MySQL一样),然后通过映射关系向导向到HDFS这个数据文件中,所以就有了相应的元数据记录,而有了元数据记录就存储在Hive元数据库中,默认是存储在derby数据库中,不过derby也有一些缺点(有机会再介绍),所以多数情况下存储在MySQL中。大家可以发现,有些公司在搭建Hadoop平台时是有安装MySQL的,其实就是用来存储HIve的元数据。
5 Hive与传统数据库对比
了解了Hive的运行机制后,我们再来了解一下Hive与传统数据库区别在哪?
上上篇博客中我们是有介绍数据仓库和传统数据库的区别,但是是从存储量、特征、面向对象、设计数据量等等来区分的。
那我们来看一下具体的数据仓库,即Hive与传统数据库的区别在哪里。
- Hive 用于海量数据的离线分析。
- Hive 具有sql数据库的外表,但应用场景完全不同,Hive 只适用于批量数据统计分析。
更直观的对比图如下:

- 从查询语句上来说,Hive使用的HQL,传统数据库使用的是SQL;
- 从数据存储来看,Hive是没有存储能力的,它所有的数据都映射道了HDFS上,所以它是基于Hadoop的数据仓库工具,但是传统数据库是有数据存储能力的;
- 从数据更新来看,Hive是不支持数据更改添加的;
- 从执行来看,HIve是基于MapReduce引擎的,而传统数据库是可以直接执行的,没有翻译的步骤;
- 从延迟来看,Hive由于接触的数据量比较大,所以延迟可能会高一些;
- 从规模来看,Hive是数据仓库嘛,自然要大得多;
- 从可拓展性来看,Hive是基于Hadoop这样一个分布式平台的,是集群,可拓展性自然很高啦;
- 从索引来看,虽然索引能提高查询速度,但Hive没有索引,传统数据库有。
6 Hive数据模型
Hive 的数据模型主要有以下四种,如下图所示:
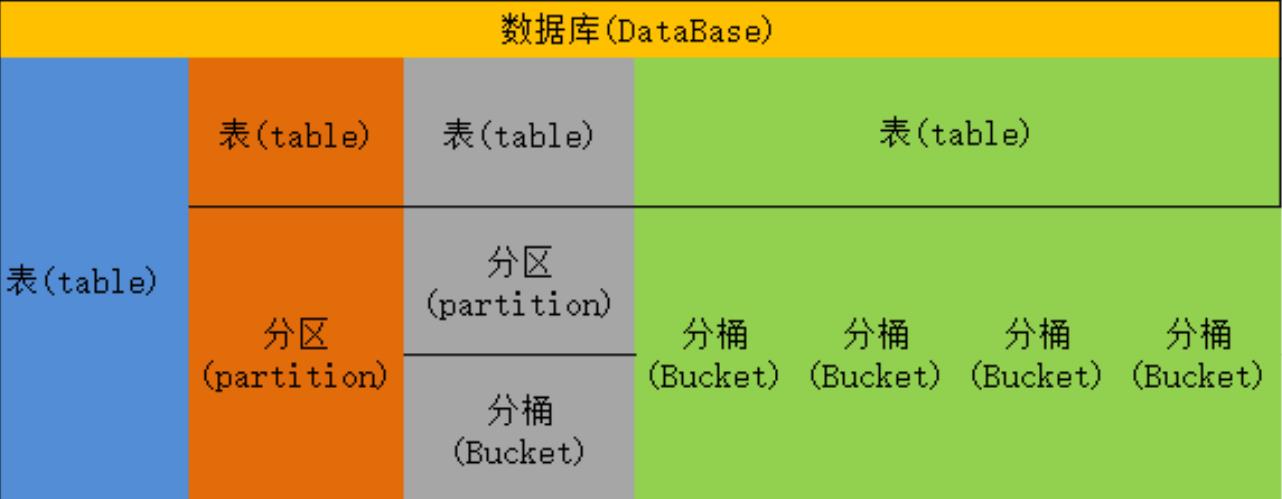
- 单独的一个表;
- 对表进行分区;
- 对表进行分区,再分桶;
- 对表直接分桶。
Hive的分区和MySQL的分区还是有所不同的,主要体现在Hive分区在HDFS的目录结构,后续会再讲。
7 Hive安装
Hive安装前需要安装好JDK和Hadoop,配置好环境变量。
在介绍Hive的架构时我们就知道了元数据存储的位置可以有两种,根据元数据存储介质不同,分为两个版本 。
一个是derby版本,优点是易于安装,但是缺点很严重,如果你在不同路径启动Hive,这样每个Hive会拥有一套自己的元数据,并无法共享,注:每个目录下都会出现(derby.log 及 metastore_db);另一个是mysql版本,它没有derby版本的缺点,但是安装较复杂。
建议还是安装mysql版本的Hive。
在这里,为了不要让大家体会“还没开始就结束”痛苦,我花了五个小时,整理出了全网最详细的图文教程(实话实说,网上的安装教程对Windows太不友好了),面向对象是使用Windows系统的朋友。
Windows下安装Hive MySQL版傻瓜式教程【附安装Hadoop教程】全网最详细的图文教程
学习更多数据分析技能和掌握实战项目,可以关注我的数据分析专栏。
CSDN@报告,今天也有好好学习
以上是关于sessiontokenJWT的一文详细介绍的主要内容,如果未能解决你的问题,请参考以下文章
一文详细了解logback之日志打印FileAppender