面向多告警源,如何构建统一告警管理体系?
Posted 阿里系统软件技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面向多告警源,如何构建统一告警管理体系?相关的知识,希望对你有一定的参考价值。
本文介绍告警统一管理的最佳实践,以帮助企业更好地处理异构监控系统所带来的挑战和问题。
背景信息
在云原生时代,企业IT基础设施的规模越来越大,越来越多的系统和服务被部署在云环境中。为了监控这些复杂的IT环境,企业通常会选择使用异构监控系统,例如Prometheus、Grafana、Zabbix等,以获取更全面的监控数据,以便更好地了解其IT基础设施的运行状况和性能表现。
然而,这种异构监控系统也带来了一些问题,其中最显着的是告警信息的分散。由于不同的监控系统可能会产生不同的告警信息,这些信息可能会分散在各个系统中,导致企业很难全面了解其IT系统的告警状况。这使得响应告警变得更加困难,同时也增加了人工管理的复杂性和工作量。
为了解决这些问题,企业需要一种更加统一和集中的告警管理方案,以确保告警信息能够及时到达正确的人员,以便他们能够快速采取必要的措施来应对潜在的问题。
告警管理的痛点
场景一:企业迁移上云后,云上产品的告警不统一

在一个典型的云原生业务应用部署架构中,通常会使用到如下产品 ACK、ECS、RDS,应用通过Kubernetes部署在阿里云的ECS上并访问云上的RDS。在这个架构中通常会用到如下监控产品来对系统进行监控。
- 通过CloudMonitor对阿里云基础设施ECS和RDS进行监控,当资源出现异常时进行告警。
- 通过Prometheus对Kubernetes以及部署在kubernetes上的Pod进行监控,当Kubernetes出现异常时进行告警。
- 通过ARMS对部署在Kubernetes上的应用进行监控,包括应用直接的调用链。当应用异常时进行告警。
- 通过SLS对应用产生的日志进行监控,当日志出现异常时进行告警。
在这样一个场景下由于用到了多个云产品对整个系统进行监控会导致使用者需要在多个产品上重复配置联系人、通知方式、值班等运维配置。且不同系统之间的告警无法产生有机结合,当一个问题出现时不能快速关联不同告警系统中的相关告警。
场景二:多云、混合云架构下,异构监控系统告警不统一

当企业的应用部署在多云环境或混合云环境下时,监控系统产生的告警可能会更加分散和复杂,给企业的运维工作带来很大的挑战。由于不同的云平台和私有云架构之间的差异,监控数据的采集和处理方式也可能不同,因此,不同监控系统产生的告警信息也可能表现出差异化,这会带来一系列的问题。
首先,不同监控系统产生的告警信息分散在不同的地方,运维人员需要耗费更多的时间和精力去处理这些信息。其次,不同系统产生的告警信息难以统一进行管理和分析,使得问题的诊断和解决更加困难。此外,因为不同系统的告警信息可能存在重复或冲突,管理和处理这些信息也会变得更加复杂。
场景三:自研监控系统、自定义事件告警接入
在应用开发运维过程中,随着系统规模的扩大和复杂度的提高,各个角落中的胶水代码逐渐增多。这些代码虽然是连接不同模块和系统的重要纽带,但一旦出现问题,由于分散在不同的地方,很难立即发现和处理。这就使得企业难以保证系统的高可用性和稳定性。如何灵活的低成本的接入这部分代码产生的告警也成为企业应用运维的痛点之一。
统一告警管理
在构建统一告警管理平台过程中,不同的监控系统对告警定义、处理流程都不一样,往往会存在下面问题:
- 不同系统产生的告警格式不同,接入成本高。
- 不同系统间的告警接入后由于格式不统一,难以统一处理逻辑。
- 不同告警系统对于告警等级的定义不同。
- 不同告警系统对于告警自动恢复的处理方式不同。有的告警系统支持自动恢复,有的不支持。
ARMS告警管理 [ 1] 设计的集成、事件处理流、通知策略等功能专门针对告警统一管理的场景,解决了统一管理过程中遇到的诸多问题。
ARMS告警管理如何接入不同格式的告警?
传统告警通常包括如下一些内容,这种结构化的告警通常只适用于单一告警源。当多个告警源的数据汇总到一起后通常会导致数据结构的冲突。因此ARMS使用了半结构化的数据来存储告警。
阿里云监控告警数据格式:

Zabbix告警数据格式:

Nagios告警数据格式:

半结构化的告警数据结构
[
"labels":
"alertname": "<requiredAlertNames>",
"<labelnames>": "<labelvalues>",
...
,
"annotations":
"<labelnames>": "<labelvalues>",
,
"startsAt": "<rfc3339>",
"endsAt": "<rfc3339>",
"generatorURL": "<generator_url>"
,
...
]
- labels(标签):告警元数据,一组标签唯一标识一个事件,所有标签均相同的事件为同一个事件,重复上报会进行合并,例如:alertname: 告警名称。
- annotations(注释):注释是告警事件的附加描述,注释不属于元数据。例如:message: 告警内容。不同时间点发生的同一个事件他们的标签是相同的,但是注释可以是不同的。比如告警内容的注释可能不同,例如:“主机i-12b3ac3*** CPU使用率持续三分钟大于75%,当前值82%”。
- startsAt(告警开始时间):告警事件开始时间。
- endsAt(告警结束时间):告警事件结束时间。
- generatorUrl(事件URL地址):告警事件URL地址。
如上述代码所示,ARMS参考开源Prometheus告警定义 [ 2] ,使用一个半结构化的数据结构来描述告警。通过高度可扩展的键值对来描述告警,这样就可以非常灵活的对告警内容进行扩展从而接入不同的数据源产生的告警。
任意JSON格式的自定义告警接入能力
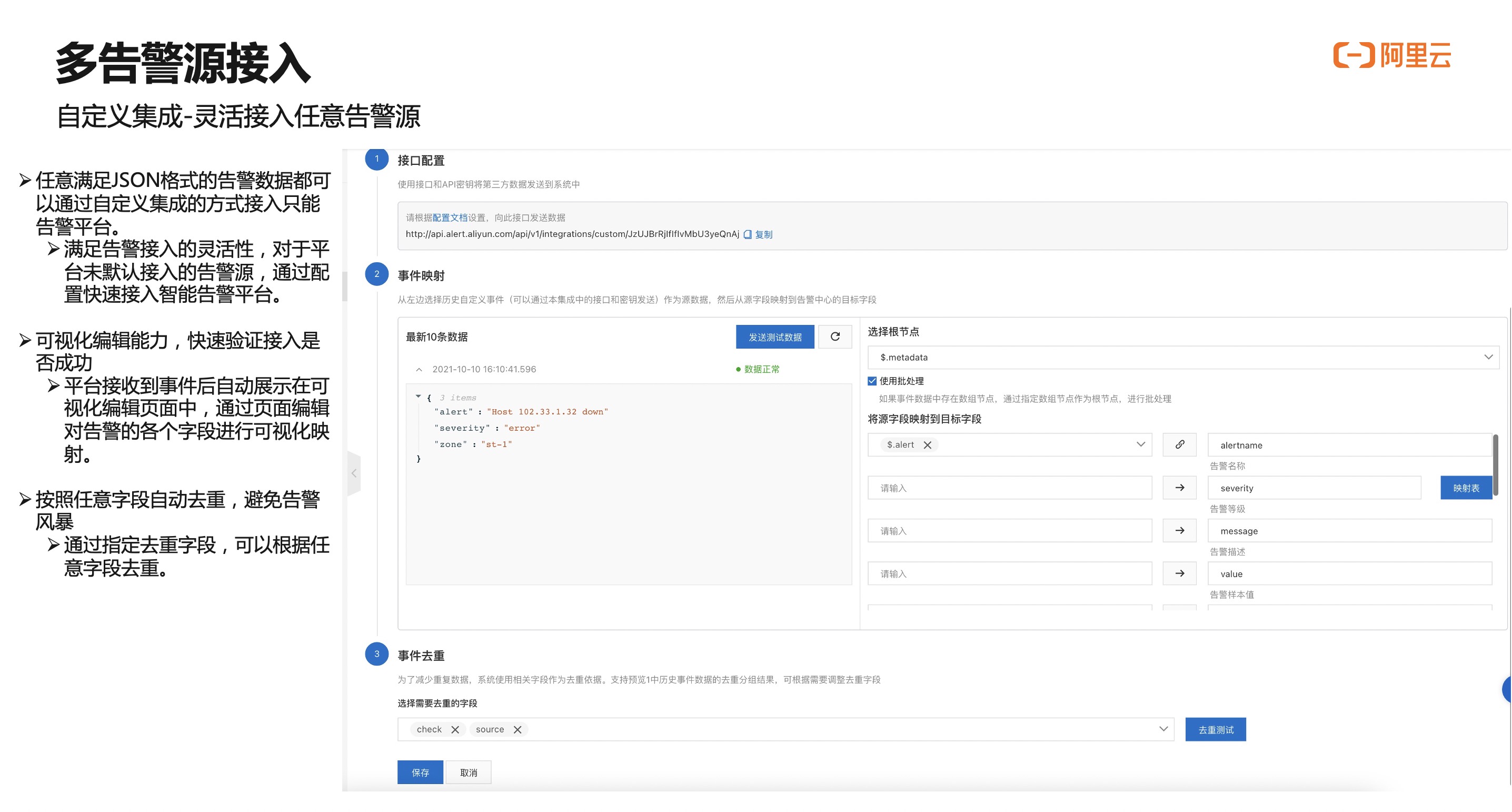
ARMS告警提供了任意一种JSON格式接入的能力(自定义集成 [ 3] )。只要告警数据结构满足JSON格式就能接入。如下图所示,自定义告警接入需要先将告警内的JSON数据上传到ARMS告警中心后,通过页面编辑字段映射的方式将告警内容中的关键信息映射到ARMS告警数据结构中。

ARMS定义了如alertname等关键字段,对于更多的扩展字段,用户可以在集成中通过新增扩展字段的方式进行配置。所有的扩展字段都可以运用到后面的告警处理逻辑中。以下图为例将原始告警报文中的hostname字段映射到扩展的hostname字段,hostip字段映射到扩展的hostip字段。

常用监控工具告警快捷接入能力
ARMS默认提供了云上云下多种监控系统的告警接入能力,可以参考集成概述 [ 4] 进行快速接入。

ARMS告警管理如何统一告警等级?
ARMS中将告警分为P1、P2、P3、P4四个等级。通过配置映射表,将多个不同类型的等级归一到P1-P4四个等级。如下图所示,将L1、Critical、严重告警这三种不同描述的告警等级都映射为P1告警,这样就可以统一不同系统中对于告警等级的不同定义。

ARMS告警管理对于不同格式的告警如何统一处理逻辑?
由于ARMS告警采用了半结构化的数据结构,可以通过标签来统一告警的处理逻辑。通常我们需要至少2个标签来统一告警的处理逻辑。一个标签用来决定这个告警应该通知给哪些人,比如业务标签(service,biz)。另一个标签用来决定这个告警应用通过什么样的方式进行通知和升级。如下表所示,通常使用告警等级(severity)来定义告警处理的SLA。

ARMS设计了通知策略和升级策略两种策略来满足不同等级的告警的处理要求,您可以参考通知策略最佳实践 [ 5] 来进行配置。
标签设计原则
当我们在设计用于告警处理的业务标签时需要满足如下原则:
- 互斥原则:指避免对同一个资源使用两个或以上的标签键。例如:如果已经使用了标签键service来标识业务,就不要再使用biz或业务等类似的标签键。
- 集体详尽原则:指所有资源都必须绑定已规划的标签键及其对应的标签值。例如:某公司有3个业务,标签键是service,则应至少有3个标签值分别代表这3个业务。
- 有限值原则:指为资源只保留核心标签值,删除多余的标签值。例如:某公司共有5个业务,那么应该有且仅有这5个业务的标签,方便管理。
除了业务标签也可以定义其他的标签来进行告警的管理,比如使用环境标签来区分开发和测试环境的告警。这些标签应该满足上述设计原则,这样可以简化告警管理配置的复杂度。
通过事件处理流给告警打标签(富化告警)
当我们设计好标签后如何对不同告警源的告警打标呢。在ARMS告警管理中设计了低代码方式的事件处理流 [ 6] ,通过拖拉拽的配置方式可以实现给告警打标签的能力(富化告警)。
场景一:匹配特定条件后给告警打标签
某xx业务使用了自研监控系统,通过自定义集成将自研的告警接入到ARMS告警管理中后,需要对这部分告警统一打上业务标签xx。事件处理流的配置如下:
a. 登录ARMS控制台 [ 7] ,在左侧导航栏选择告警管理,然后单击新建处理流。
b. 在弹出的面板创建事件处理流,编辑触发条件匹配自定义集成的名称为“xx自研监控系统”。

c. 添加设置业务标签动作,将"xx"设置为业务(service)标签值。

场景二:切割字符串,提取标签
某自研告警系统中所有的主机都使用固定格式进行命名,命名格式为env−env−env-biz-app−app−app-group-$index ,需要提取其中的biz字段做为业务标签。配置正确的触发条件后,使用分割内容操作,将hostname根据字符\'-\'进行分割,分割后的内容依次填充到env、service、 app、group字段。

场景三:通过查询Excel表格富化告警
某应用监控平台,在发生告警时仅通知了应用ID,需要根据Excel表格关联到应用名称、应用责任人等信息。

a. 创建Excel数据源,并上传app_cmdb.xlsx文件。

b. 配置事件处理流,添加字段丰富操作,选择数据源为第一步创建的数据源。编辑匹配字段为appId,将Excel表中其他字段分别填充到appName、owner、ownerPhone扩展字段中。
 **
**
**
场景四:通过Serverless(FunctionCompute)调用外部服务富化告警
同上述场景三,当告警中缺失的数据需要从CMDB等外部系统获取时,可以通过API类型的数据源来进行告警富化。

a. 创建函数计算应用 [ 8] ,开发一个HTTP服务,接收入参为appId,返回出参为appName、owner、ownerPhone等参数。如下截图仅为示例代码。

b. 创建API类型的数据源,URL地址为第一步中开发的函数。

c. 配置事件处理流,添加字段丰富操作,选择数据源为上一步创建的数据源。编辑匹配字段为appId,将Excel表中其他字段分别填充到appName、owner、ownerPhone扩展字段中。
ARMS告警管理如何配置告警自动恢复?
不同的监控系统对告警自动恢复的处理逻辑大不相同。如Prometheus告警不会发送特定格式的恢复告警,仅通过告警时间来标识告警是否结束。阿里云云监控 [ 9] 中告警是否恢复的状态合并到了告警等级中,如下所示。
- 参数:triggerLevel
- 数据类型:String
- 本次触发报警的级别。取值:
-
- CRITICAL:严重
- WARN:警告
- INFO:信息
- OK:正常
不同场景下的告警在处理是否恢复的逻辑可能也会有所区别。如阈值类型的告警,当监控值不满足阈值条件时期望立即恢复告警。但是对于事件类型的重要告警,告警发生只在一瞬间,并没有恢复的过程。需要运维人员人工确认事件产生的影响已经消除后才能恢复告警。
场景一:针对不会恢复的告警,配置自动恢复时长,告警按照时间自动恢复
针对事件类型的告警,通常需要人工确认事件的影响范围后再处理告警。这时告警自动恢复可能会导致需要被处理的事件没有被人工处理。针对这种情况需要在接收到告警后不进行自动恢复或者至少在一个长周期内不自动恢复,给处理人员一定的时间来确认该告警的影响。

ARMS自定义集成配置告警自动恢复时间截图:

场景二:配置恢复告警字段,接收到恢复事件后恢复告警
在ARMS的告警集成中,可以通过配置告警恢复字段,当告警内容中某个字段的值满足条件时,视为恢复告警。根据该告警的其他字段的内容寻找对应的告警进行恢复。告警主动恢复的示意图如下所示:

ARMS控制台配置方式截图:

告警恢复需要满足如下2点,才能正确的恢复对应的告警。
- 如果没有定义去重字段,那么告警和恢复告警的标签需要完全一致才能正确恢复告警。
- 如果定义了去重字段,那么告警和恢复告警的去重字段需要完全一致才能正确恢复告警。
说明:当配置了某个字段如(status)做完告警恢复字段时,请不要将这个字段添加到告警的映射规则中。通常会导致告警与恢复告警字段不匹配,从而恢复失败。
补充信息
FunctionCompute示例代码:
# -*- coding: utf-8 -*-
import logging
import json
def handler(environ, start_response):
context = environ[\'fc.context\']
request_uri = environ[\'fc.request_uri\']
body_str = get_request_body(environ)
id = json.loads(body_str).get(\'appId\')
# 这一行为伪代码,示例通过查询cmdb获取应用详细信息, 获取到的app格式如下
# "appId":"b38cdf95-2526-4d7a-9ea9-ffe7b32*****", "appName": "iot-iam", "owner":"王五", "ownerPhone": "130xxxx1236"
app = cmdb.getApp(id)
ret = json.dumps(app)
status = \'200 OK\'
response_headers = [(\'Content-type\', \'text/plain\')]
start_response(status, response_headers)
return [ret.encode(\'utf-8\')]
def get_request_body(environ):
try:
request_body_size = int(environ.get(\'CONTENT_LENGTH\', 0))
except (ValueError):
request_body_size = 0
request_body = environ[\'wsgi.input\'].read(request_body_size)
return request_body
相关链接:
[1] ARMS告警管理
[2] Prometheus告警定义
https://prometheus.io/docs/alerting/latest/clients/#sending-alerts
[3] 自定义集成
https://help.aliyun.com/document_detail/251850.htm?spm=a2c4g.2362717.0.0.18906bf4Pry1jD#task-2021669
[4] 集成概述
[5] 通知策略最佳实践
https://help.aliyun.com/document_detail/456953.htm?spm=a2c4g.2362717.0.0.1890951awN1Sbk#task-2249792
[6] 事件处理流
https://help.aliyun.com/document_detail/311905.htm?spm=a2c4g.2362717.0.0.18901c8dwhrptl#task-2114624
[7] ARMS控制台
[8] 函数计算应用
https://help.aliyun.com/document_detail/51783.htm?spm=a2c4g.2362717.0.0.189070368lSswF#multiTask782
[9] 阿里云云监控
https://help.aliyun.com/document_detail/60714.htm?spm=a2c4g.2362717.0.0.18904bf99bofq7#task-2151109
目前应用实时监控服务ARMS 提供全功能15天试用,开发者可以全面体验告警能力。点击此处,即可获取。
告警运维中心|构建高效精准的告警协同处理体系
简介:基于报告,ARMS 能快速的整合上下文,包括 Prometheus 监控进行监控。还有前端监控的相关数据,都会整合到报告里面,进行全方位检测来收敛相关问题。
作者:延福
在开始正式内容前,我想跟大家聊一聊为什么要做告警平台。
随着越来越多企业上云,会用到各种监控系统。这其中,用 Skywalking 做 tracing,Prometheus 做 matches,ES 或者云上日志服务,做日志相关监控,随便算算就至少有三套系统了,这其中还不包括云监控等云平台自身的监控平台。这么多监控平台如果没有统一配置告警的地方,就需要在每个系统中都维护一套联系人,这会是一个复杂的管理问题。与此同时,会非常难以形成上下文关联。比如,某一个接口出现问题,那可能云监控的拨测在报警,日志服务的日志也在报警,甚至 ARMS 应用监控也在报警。这些报警之间毫无关联,这是在云上做告警云很大的痛点。
其次无效告警非常多。什么叫无效告警?当业务系统出现严重故障时,关联系统也可能出现相关告警。而且关联告警会非常多,进而将关键信息淹没在告警海洋中,导致运维人员没办法及时对告警进行处理。最后,现在很多报警经常发生,但是没有人处理,就算有人处理了,但处理情况怎么样,关键性告警从发生到修复的时间到底有多长,每天有多少人在处理,企业的 MTTR 能不能算出来?这也是我们要做统一告警平台要解决的问题。

为了解决以上三个问题,ARMS 的智能告警平台应用而生。
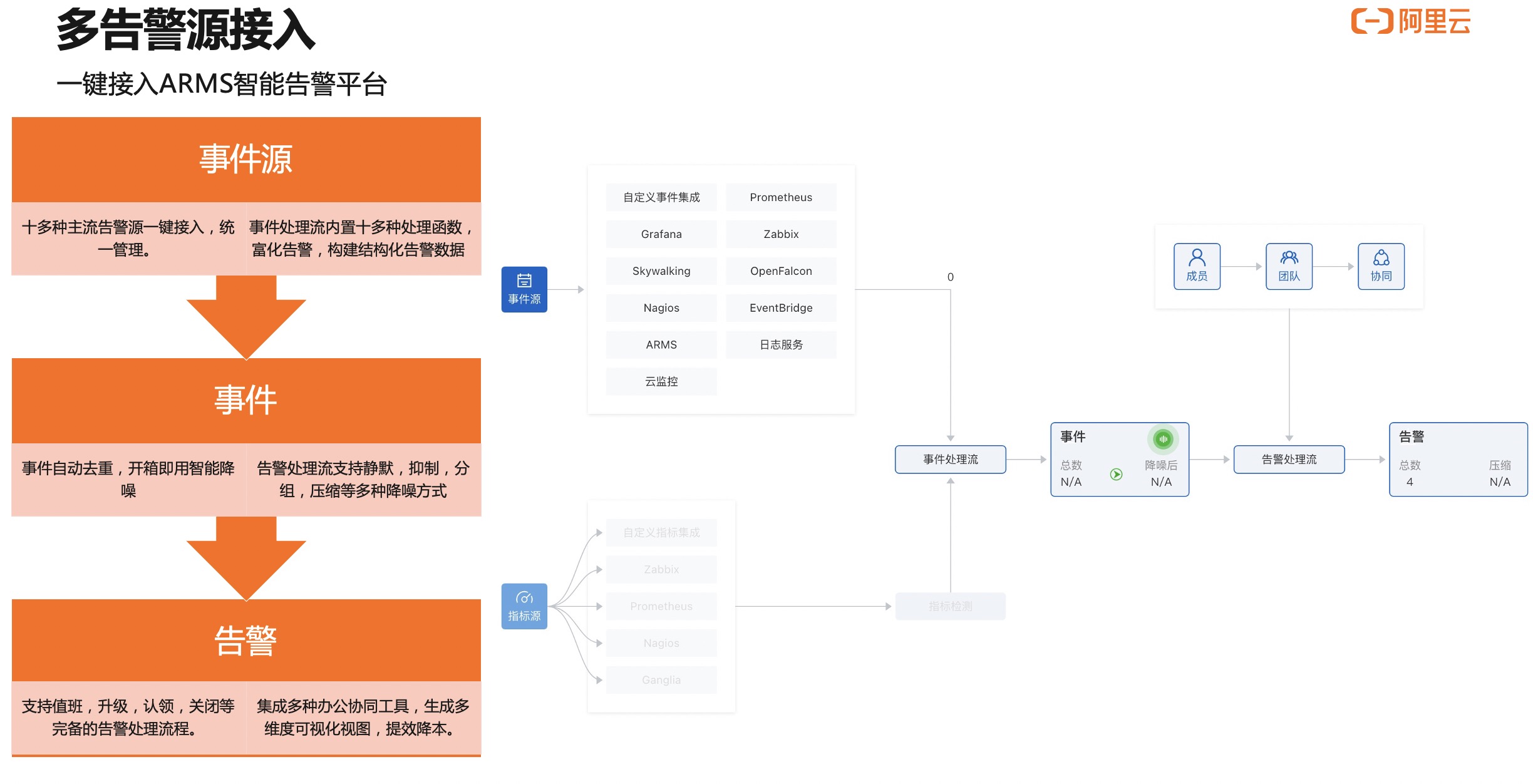
首先,集成了众多监控系统包括 ARMS 本身的应用监控、云监控、日志服务等十几家监控系统,并提供开箱即用的智能降噪能力。同时,为了更高效的协作,整个协同的工作流都可以放在钉钉、企业微信等 IM 工具上,用户可以更加便捷的去处理和运维相关的告警。最后,提供告警分析大盘帮助用户来分析告警是不是每天都有人在处理,处理情况是什么样的。

告警要在脑海里形成抽象的概念,到底分成哪些步骤?
第一、从事件源产生告警事件,事件是告警发送之前的状态。事件并不会直接发送进来,它需要和告警的联系人匹配完成以后,才能生成告警流程。这张图简单的介绍了告警的过程。这也是很多同学用系统时候会经常出现的问题:配置了事件,却不知道怎么样产生告警。必须要事件加联系人才能产生告警。

第二、很多同学用的告警系统默认没有接入。我们也提供了灵活告警事件源的接入方式。可以按照自定义的接入方式,将事件传进来,我们来清洗字段,最后接入形成告警平台可以理解的告警。
工单系统举例,希望系统里产生很重要的事件也往告警平台去传时,可以把工单系统的报警事件通过 webhook 的方式发送到告警平台。识别并设置相关内容,再通过电话或短信方式通知到相应联系人。告警平台本质上是接受事件,把告警团队相关信息配到告警平台,帮用户把事件给这些团队的联系人进行匹配发送。

接下来,展示一下这部分能力是怎么实现的,在界面上是什么样的功能。
首先,打开 ARMS 控制台,拉到最下面告警管理模块。我们可以看到概览,其中包括大部分接入过程、事件处理流程等等。
现在已经用 ARMS 应用监控的用户,可以直接在其中先创建一个告警的规则。条件是应用响应时间,调用次数大于一次的时候,它就会产生一个事件。

如果是开源 Skywalking 或其他服务,需要到其中去把告警规则设好,把相应的事件传递过来。传递进来以后,在报警事件列表里面就能看到对应报警的事件了。
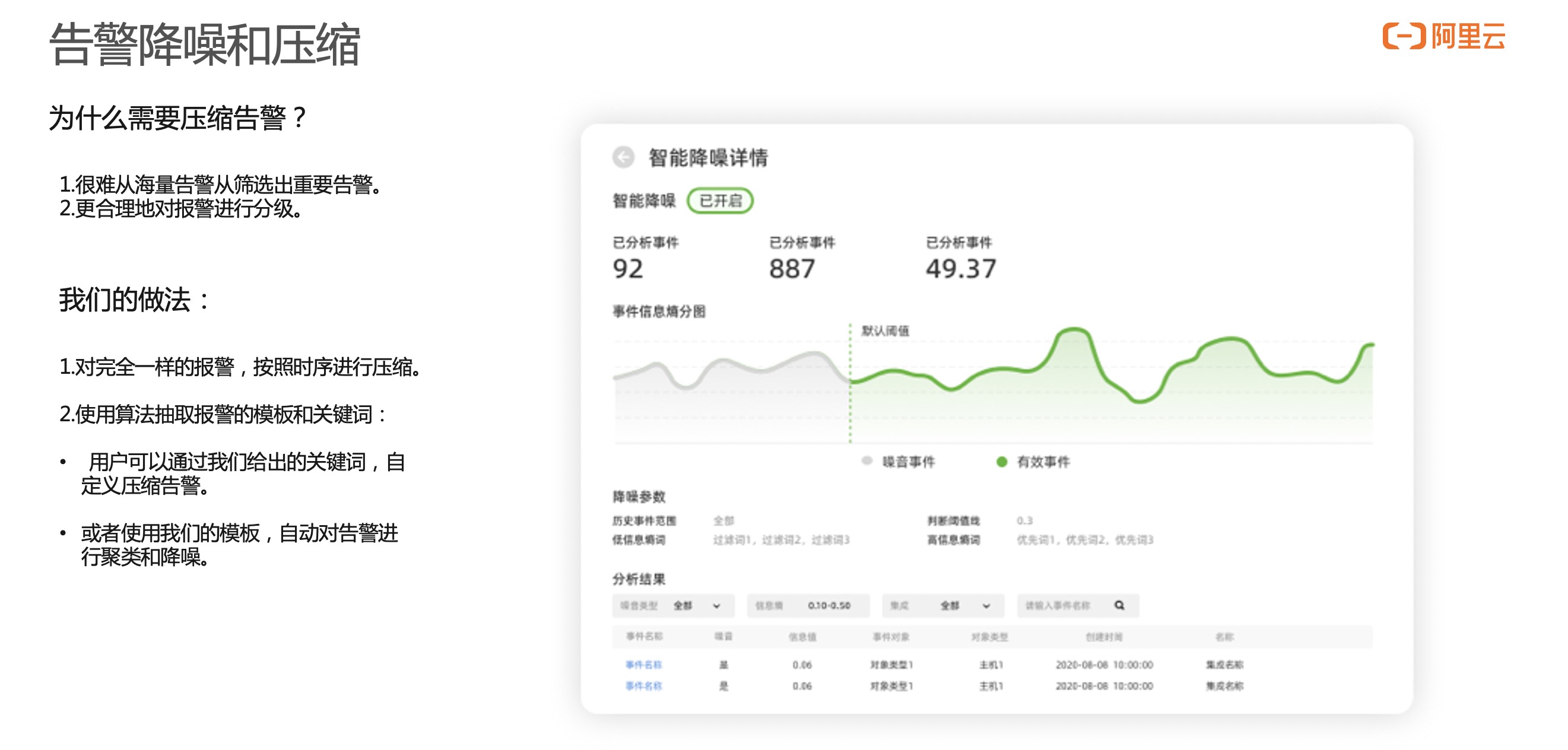
报警事件发送进来以后。首先会对告警事件进行降噪处理,识别告警目前最多关键词是什么样,哪些关键词高度重复,或者哪些内容是高度匹配的。同时,根据我们给出的关键词进行压缩。比如,不希望能收到来自于测试环境的告警,可以把“测试”这两个字作为屏蔽词,这样带“测试”相关屏蔽词的功能,告警事件就不会进行二次报警。
告警事件传递过来后,整个数据都会放在事件大池子里面。需要对这些事件进行分配,这个事件到底谁去接收他,谁来对这些事件做通知和排班管理。按照告警名称或者其他的字段等在告警里面预制的字段去匹配,对 Pod 状态的异常做匹配,那它会生成告警。
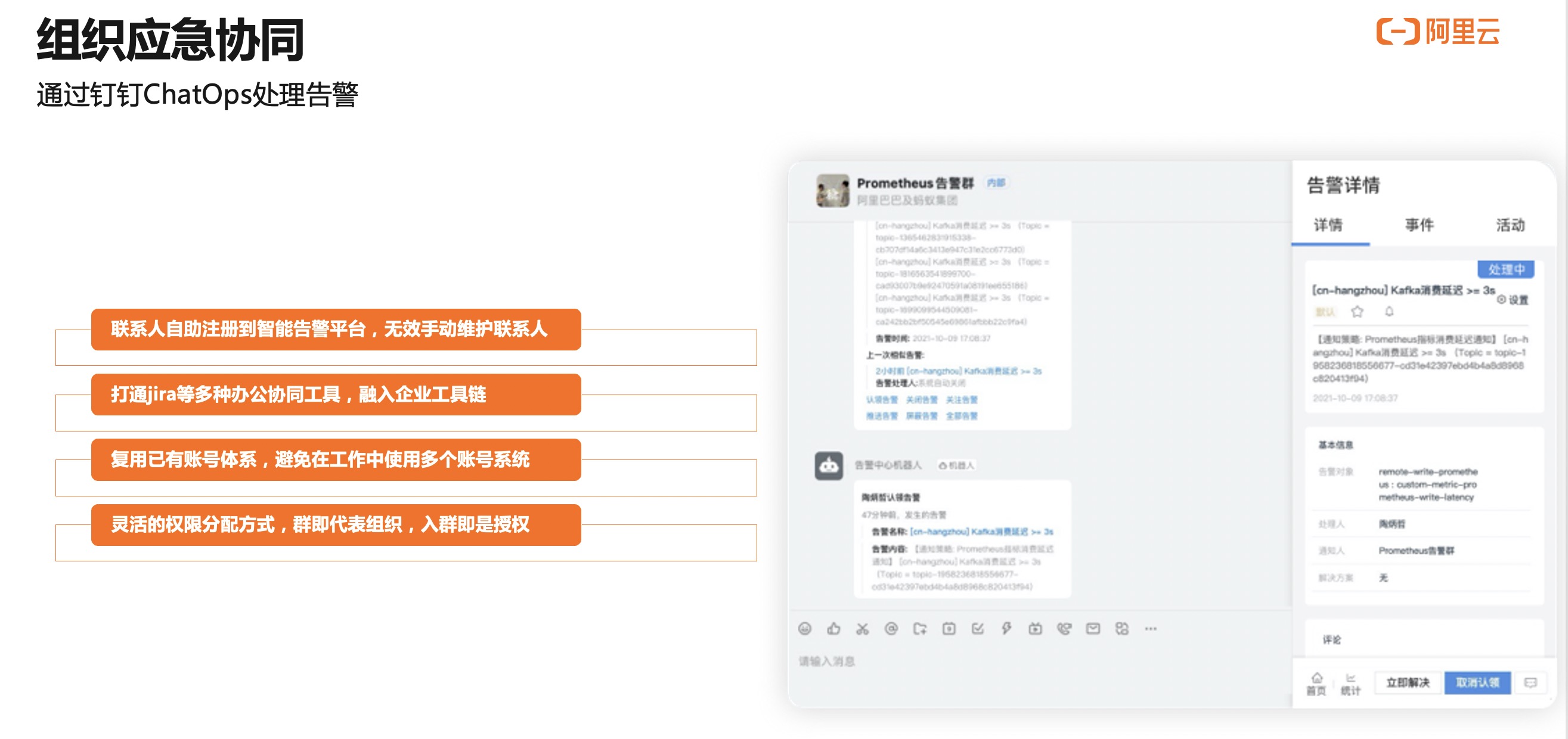
生成告警以后,可以在联系人里面去配置相关联系人,其中包括导入通讯录或配钉钉机器人等等。在通用策略里面,进一步配置,让用户配一个机器人或者真实的人去接受告警。也可以是对工单系统,比如 Jira 等平台里面去做对接,保证信息可以传递到他们那边。

配完通知策略以后,一旦产生告警,就可以收到相关的告警了。比较推荐您使用的是通过钉钉来接收相关的报警。
这里展示一下怎么样通过钉钉来接收相关的告警。比如,这是我们接收到钉钉相关告警。在接收到这个告警以后,对这条告警消息,只需有一个钉钉账号,不需要有理解这些相关信息,或者登录到系统,直接对这个告警进行认领。因为和钉钉系统深度集成,可以去认领告警,也可以在认领完以后点解决这条告警。
我们会把过程记录在活动里面。用户就会知道认领和关闭告警的整个过程。同时,每天会针对情况做统计,比如今天发生告警的数量,是否有处理,哪些没有处理,整体处理情况是怎么样的。如果团队比较大,有非常多运维同学,而且会有 L1 和 L2 分层运维同学的时候,可以使用排班功能进行线上排班。比如,这一周是某个同学接受告警,下一周是另外的同学。同时,也可以做升级策略的排班管理。重要告警在十分钟内没有人去做认领时,对重要告警做相应升级。

作为运维主管或运维总监,需要了解每天发生的这么多告警,经过一段时间后,它是不是有收敛或平均 MTTR 用了这些工具以后,有没有提升。我们提供了告警大盘,通过这个告警大盘可以了解到每天告警平均响应时间以及大家处理情况。MTTx 相关时间等统计数据会在这个大盘里面给用户进行展示,同时这个大盘是集成在 Grafana 上面,可根据实际需求,把相关数据放 Grafana 上,或者您的 Prometheus 数据源里面做二次的开发。

告警不仅是管理和收集的过程。很多时候虽然发现了告警。在告警处理过程中,阿里云是否可以提供一些建议参考。对此,我们也提供了相应功能来增强这一块的能力。
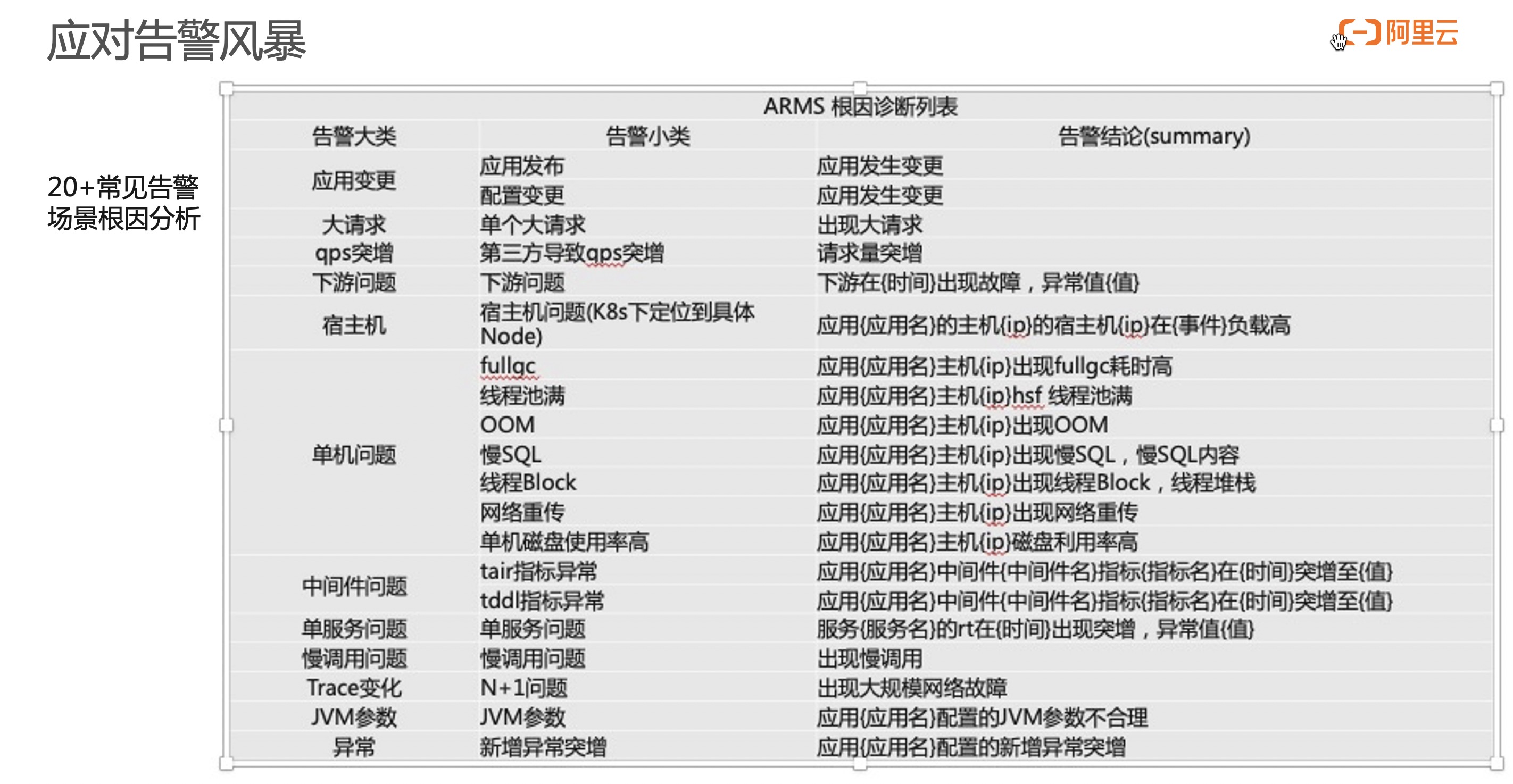
首先,基于类似应用监控的产品,提供一系列默认报警能力。一旦产生相关报警,我们会提供相关诊断能力。在如上图 20 多种场景下,会提供自动诊断报告。
举一个例子,应用的响应时间做突增,我们会生成一个直观的报表。在这个报表中,会告诉你当前突增的原因是什么。然后会整体的检测这个应用突增以后到底是哪些因素导致的。一般来说,这个诊断逻辑和普通的诊断逻辑是一样的。应用突增会去先检测一下多个主机是不是有突增,然后是不是接口有突增。这些接口如果它响应时间的数据特征是和整个应用一致,会在进一步分析这个接口里面到底又是哪些方法有突增,他传递的入参是什么,为什么有这样的突增?同时我们也会给出来一些特征请求告诉用户,慢的请求是怎样运行的。
以这个 version.json 接口为例,它是在对应的这个时刻,与应用有类似的突增。主要的核心方法就是这样一个方法,导致了接口缓慢。

同时我们结合当时打出来的堆栈可以再次确认,当时就是个 handler 方法导致了它的缓慢,那接下来我们就可以结合代码进一下进一步的优化了。
这就是 ARMS insight 针对常见问题深入分析的一个 case。基于报告,ARMS 能快速的整合上下文,包括 Prometheus 监控进行监控。还有前端监控的相关数据,都会整合到报告里面,进行全方位检测来收敛相关问题。
本文为阿里云原创内容,未经允许不得转载。
以上是关于面向多告警源,如何构建统一告警管理体系?的主要内容,如果未能解决你的问题,请参考以下文章