从开源到云原生,时序数据库 TDengine 六年回顾精彩纷呈
Posted 涛思数据TDengine
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从开源到云原生,时序数据库 TDengine 六年回顾精彩纷呈相关的知识,希望对你有一定的参考价值。

在欢庆之余,回顾 TDengine 六年发展,成长和进步跃然纸上。由小到大,由弱到强,伴随着 TDengine 影响力的逐渐扩大,涛思数据也走出了一条独具特色的创业之路。
2016 年底,TDengine 创始人 & 核心开发陶建辉看到了物联网大数据的市场机会,在两个月的时间写下一万八千行代码打造了 TDengine 的原型。2017 年 5 月,北京涛思数据科技有限公司正式注册,6 月 6 日在北京望京科技园正式开始办公。陶建辉汇聚了一批来自中国科大、中国科学院、上海交大、美国密歇根大学、马里兰大学等知名学府或机构的团队成员,正式开始了 TDengine 的产品研发之旅。2018 年 8 月,在经过多轮测试后,TDengine 终于发布了第一个商用版本。
一篇入门物联网大数据:TDengine时序数据库
目录
【本文正在参与“拥抱开源”|涛思数据TDengine有奖征稿】传送门:https://marketing.csdn.net/p/0ada836ca30caa924b9baae0fd33857c
一、大数据时代
大数据,已是技术发展中的重要领域,数据无处不在,支撑着大数据的中间件也不断迭代更新,TDengine成为当中的优势产品,生产应用场景不断扩大,这一篇入门物联网大数据:TDengine时序数据库,从零学习了解大数据时代的解决方案!
二、TDengine设计思想
在生活中,各种IOT的联网设备,比如智能手表、水表、汽车等,每时每刻都产生数据,这样的数据是按时间顺序的。
时间序列的数据一旦产生便是历史不再发生变化。因此,数据写入后不再有删除和修改的操作,因此,与MySQL等数据库相比较,TDengine简化了数据存储的数据结构上,使得一些聚合查询上可以通过预计算得到,更加高效。
TDengine最佳实践说明,为每一个独立产生数据 的IOT设备建立一张独立的表,这样保证了,不同设备之间存在时钟不同步或者服务器网络延时的情况下,同一张表(来自同一个设备)的数据仍然可以保证是顺序写入的。
三、CAP理论和TDengine的特性
1、CAP理论
CAP理论在互联网产品中是必然会应用到的理论,一致性Consistency、可用性Availability、分区容错性Partition tolerance。
一个分布式数据存储系统最多只能同时满足其中两点。因此,分布式系统势必只能在一致性和可用性中权衡做出选择。
一致性:每个读操作都可以得到一个最新写的结果或者明确的错误响应。
可用性:每一个读写操作都可以得到一个非错误的响应(不保证最新)。
分区容忍性:无论节点间的网络问题导致了多少消息丢失或者延迟到达,系统可以继续运转。
2、TDengine特性
TDengine在物联网的场景下以牺牲部分功能支持的代价换来了超过10倍的性能提升。基于顺序表结构的存储,追加写的插入,二分查找的查询,结构化的定长数据,预计算的聚合结果等优化大大提升了时序数据存储的读写性能。
TDengine支持按时间过期的方式删除陈旧的历史数据避免无限量的数据增长。
四、数据模型
1、数据特点
研究发现,物联网、车联网、运维监测类数据还具有很多其他明显的特征:
- 时间顺序;
- 极少更新或删除;
- 数据量巨大;
- 数据高度结构化;
- 无需事务处理;
- 写多读少;
- 查询分析更关注一段时间的趋势,而不是某个特定时间点的值;
- 数据有保留期限;
- 需要各种统计和实时计算操作;
- 流量平稳,可根据设备数量和采集频次预测出来。
根据这些数据的特征,TDengine采取经过特殊优化的存储和计算设计来处理时序数据,系统处理能力很大提高,而且降低了系统运维的复杂度。
2、超级表和表
从上面介绍我们知道,TDengine为一个数据采集点建一个表,而且,这个表第一列必须是时间戳timestamp类型。
很明显,表的数量巨大,难以管理,当应用需要做采集点之间的聚合操作,聚合的操作也变得复杂起来。为解决这个问题,TDengine引入超级表(Super Table,简称为STable)的概念。
超级表:同一类型数据采集点的集合。指某一特定类型的数据采集点的集合,同一类型的数据采集点的表结构是完全一样的,而静态属性(也叫标签,包括地点、设备的分组id等)不一样。一个系统有N个不同类型的数据采集点,就需要建立个超级表(Super Table)。

TDengine架构示意图
主要逻辑单元:物理节点(pnode)、数据节点(dnode)、虚拟节点(vnode)、管理节点(mnode)、虚拟节点组(VGroup)、驱动程序(Taosc)。
TDengine架构的详细部分这里暂时不展开,不影响后面的阅读。
3、数据查询
TDengine提供丰富地查询功能,除了常规聚合查询,还提供对时序数据的窗口查询、统计聚合等功能。查询处理功能由客户端、vnode、mnode节点协同完成。
a. 单表查询
SQL语句解析和校验工作在客户端完成。解析SQL语句并生成抽象语法树(AST),再进行校验和检查,以及向mnode请求查询中指定表的元数据信息。
然后,根据元数据信息中的End Point,将查询请求序列化后发送到该表所在的dnode。dnode接收识别出指向的vnode,将消息转发到vnode查询执行队列。dnode查询执行队列中的工作线程会等待vnode线程执行完成,再将查询结果返回给客户端。
b. 多表聚合查询
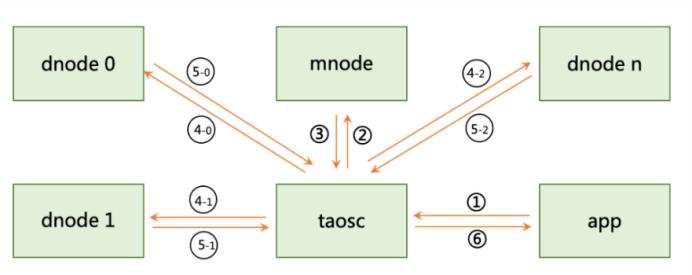
- APP应用将一个查询条件发往系统;
- Taosc将超级表的名字发往mnode(管理节点);
- mnode将超级表拥有的vnode列表发回taosc;
- Taosc将计算的请求跟标签过滤条件发往这些vnode对应的数据节点;
- 每个vnode先在内存中找出自己节点里符合的标签过滤条件的表集合,然后扫描存储的时序数据完成聚合计算,将结果返回taosc;
- Taosc将多个数据节点返回的结果做最后的聚合,返回给应用。
这里涉及到的标签数据、元数据的概念,可以继续看以下内容,对于管理节点、数据节点的概念,属于TDengine结构的具体内容,暂时不展开讨论。
五、存储模型
1、时序数据
存放在vnode,由data、head、last三个文件组成,数据量大。不支持删除操作,update参数为1时才能更新操作。一个采集点一种表,一个时间段的数据是连续的,写入是简单追加操作,这样对单个采集点的插入和查询操作,性能达到最优。
2、标签数据
存放在vnode的meta文件,支持CRUD操作,数据量不大。N张表就有N条记录,可以全内存存储。
3、元数据
存放在mnode,包含系统节点、用户、DB、Table Schema,支持CRUD,数据量不大,可全内存存储,而且客户端有缓存,查询量不大。
这一篇主要是学习大数据内容时,入门TDengine应用的简单总结,整理了一些基本且关键知识。
如果觉得不错欢迎“一键三连”哦,点赞收藏关注,评论提问建议,欢迎交流学习!一起加油进步,我们下篇见!
【本文正在参与“拥抱开源”|涛思数据TDengine有奖征稿】传送门:https://marketing.csdn.net/p/0ada836ca30caa924b9baae0fd33857c
涛思数据TDengine官方文档:https://www.taosdata.com/cn/documentation/
本篇内容首发我的CSDN博客:https://csdn-czh.blog.csdn.net/article/details/119089953
以上是关于从开源到云原生,时序数据库 TDengine 六年回顾精彩纷呈的主要内容,如果未能解决你的问题,请参考以下文章