python深浅拷贝
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python深浅拷贝相关的知识,希望对你有一定的参考价值。
python在内存中存储数据的结构
1先考虑一个问题为什么python list是可以被追加的,也就是数据会不断扩大?
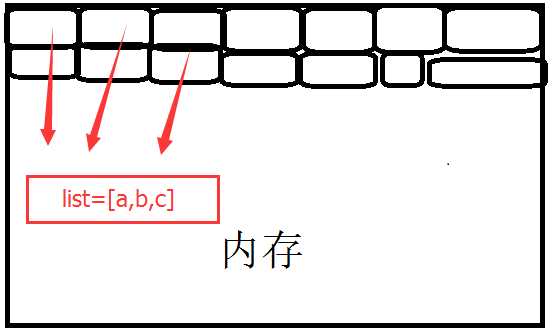 当生成一个列表对象那么python就会在内存中开辟一个区域来存放当前的值,如果在往里追加def内存中的数据会是连续存放的么?
当生成一个列表对象那么python就会在内存中开辟一个区域来存放当前的值,如果在往里追加def内存中的数据会是连续存放的么?
当然不会了,因为python就是利用c中的链表实现的追加方式,python创建列表的时候肯定不知道你需要存储多少东西所以无法给你开辟很大的内存空间。
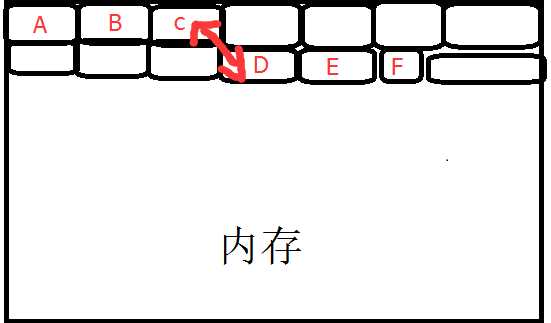 链表会记录上一个位置和下一个位置,这样就实现了追加的功能。
链表会记录上一个位置和下一个位置,这样就实现了追加的功能。
这里在说一点,因为python是c来开发的,c中是没有字符串这个概念的, 只有字符串数组。就向上面图片一样str="abc",abc就是分别存在三个内存块上。
当python修改str="adc",此时会开辟三个新的内存块来存储
看下下面的例子:
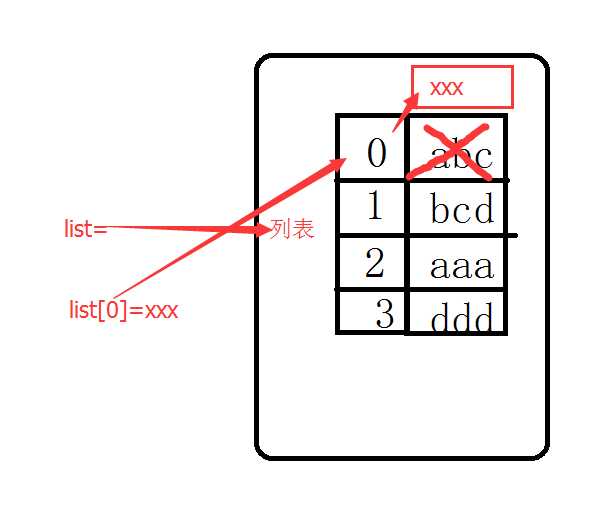 这里就是把list[0]的值改成xxx,从图上可以看出,0的下标以前指向abc,改后0指向xxx了,但是abc实际上还在内存中并没有消失。
这里就是把list[0]的值改成xxx,从图上可以看出,0的下标以前指向abc,改后0指向xxx了,但是abc实际上还在内存中并没有消失。
浅拷贝
python对数字和字符串有优化机制,这里 无论深浅拷贝内存地址都是一样的。
>>> n1=123
>>> n2=n1
>>> id(n1)
7367920L
>>> id(n2)
7367920L
>>> n1=123
>>> n2=copy.copy(n1)
>>> id(n1)
7367920L
>>> id(n2)
7367920L
>>> n2=copy.deepcopy(n1)
>>> id(n2)
7367920L
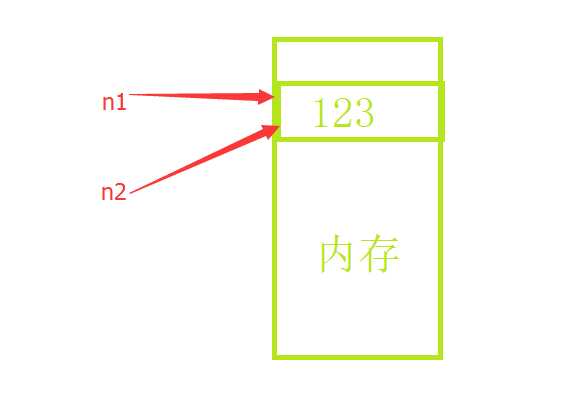 只要是数字或字符串那么不管如何cp都是指向同一个内存,实际上同样的东西开辟2个内存空间就会很浪费,因为值都是一样的。
只要是数字或字符串那么不管如何cp都是指向同一个内存,实际上同样的东西开辟2个内存空间就会很浪费,因为值都是一样的。
如果把n1的值改成=456?那么会影响n2的值么?当然不会了n2还是会指向123这个内存地址的。
那如果是数据类型是元组,列表,字典情况还是一样的么?
先定义个数据类型
>>> n1={"k1":"abc","k2":123,"k3":["hello","999"]}
>>> n2=n1
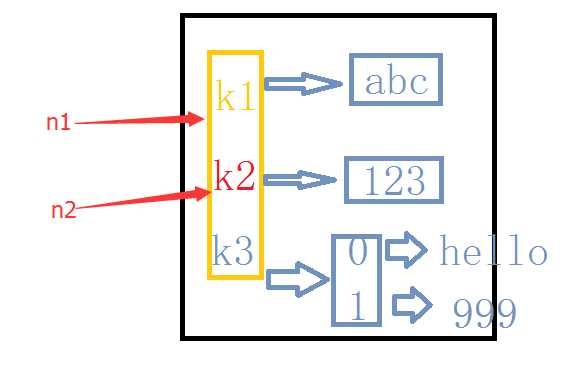 浅拷贝的话n2只会拷贝[k1,k2,k3]第一层内存id。
浅拷贝的话n2只会拷贝[k1,k2,k3]第一层内存id。
看看只拷贝第一层的效果:
2个id一样没有错
>> id(n2[‘k1‘])
4109480L
>> id(n1[‘k1‘])
4109480L
这就有变化了,如果上直接cp一个字符串,当A的值做出改变不会影响B,但是这里B的值会随着A的改变而改变。这就是只cp一层的问题。原因很简单N2只需要找k1就行,k1指针指向谁跟N2没有关系
>> n1["k1"]="ccc"
>> id(n1[‘k1‘])
5415864L
>> id(n2[‘k1‘])
5415864L
>> n2["k1"]
ccc‘
>> n1["k1"]
ccc‘
以上是关于python深浅拷贝的主要内容,如果未能解决你的问题,请参考以下文章