[重读经典论文]EfficientDet
Posted 大师兄的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[重读经典论文]EfficientDet相关的知识,希望对你有一定的参考价值。
参考博客:睿智的目标检测36——Pytorch搭建Efficientdet目标检测平台
参考视频:Pytorch 搭建自己的Efficientdet目标检测平台
EfficientNet+BIFPN+解耦Head(类似RetinaNet),Anchor-Base
重读经典:《Momentum Contrast for Unsupervised Visual Representation Learning》
MoCo 论文逐段精读【论文精读】
这次论文精读李沐博士继续邀请了亚马逊计算机视觉专家朱毅博士来精读 Momentum Contrast(MoCo),强烈推荐大家去看本次的论文精读视频。朱毅博士和上次一样讲解地非常详细,几乎是逐词逐句地讲解,在讲解时把 MoCo 相关领域的研究也都介绍了,听完之后收获满满。
MoCo 获得了 CVPR2020 最佳论文提名,是视觉领域使用对比学习的一个里程碑工作。对比学习目前也是机器学习领域最炙手可热的一个研究方向,由于其简单、有用、强大,以一己之力盘活了从2017年开始就卷的非常厉害的计算机视觉领域。MoCo 是一个无监督表征学习的工作,其不仅在分类任务,在检测、分割和人体关键点检测任务上都逼近或超越了有监督学习模型;MoCo 的出现证明我们可能并不需要大量标注好的数据去预训练。下图中 Yann LeCun 将机器学习比作一块蛋糕,强化学习是蛋糕上的樱桃、有监督学习是蛋糕上的奶油、无监督学习才是那块大蛋糕,才是问题的本质,目前很多的大模型都是通过自监督学习得到的。

MoCo 论文链接:https://arxiv.org/abs/1911.05722
0. 对比学习介绍
在开始精读论文之前,朱毅博士首先介绍了什么是对比学习。如下图所示,有三张图片,图1、2为同一个人不同的表情,图3为dog,在训练时不会为这三种图片去标注。将三种图片输入到模型中,模型会得到三张图片各自特征。由于图1、2为同一个人、对比学习就是让特征
f
1
、
f
2
f_1、f_2
f1、f2 比较接近,而特征
f
3
f_3
f3 与另外两个特征在特征空间相距较远,这就是对比学习需要达到的目的。
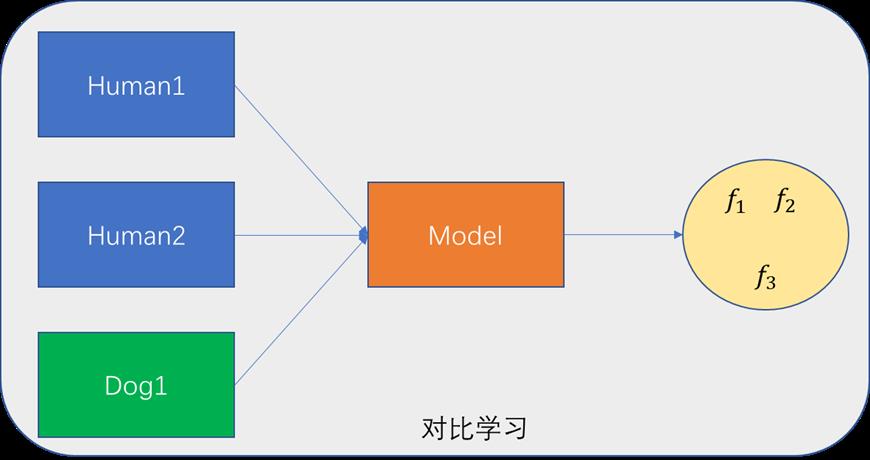
虽然在对比学习中并不需要为图片进行标注,但是仍然需要知道哪些图片是相似的,哪些图片是不相似的,在计算机视觉中通常使用代理任务来完成。举一个具体的例子 instance discrimination,假设有
n
n
n 张图片,选取一张图片
x
i
x_i
xi ,经过裁剪和数据增强后得到两张新的图片
x
i
1
x_i^1
xi1 和
x
i
2
x_i^2
xi2,则这两张图片和原来的图片就是相似的,也被称为正样本,其余图片即
j
≠
i
j \\neq i
j=i,则为负样本。对比学习的灵活之处就在于正负样本的划分,例如同一张图片不同视角可看作为正样本,视频中同一段视频任意两帧可以看为正样本,RGB和深度图也可看作为正样本等等。正是由于其灵活性,对比学习的应用才如此之广。

1. 标题、摘要、引言、结论
先是论文标题,论文标题的意思是:使用动量对比去做无监督视觉表征学习,MoCo 就来自于论文前两个单词前两个字幕。简单介绍什么是动量,动量在数学上就是加权移动平均。例如
y
t
=
m
×
y
t
−
1
+
(
1
−
m
)
×
x
t
y_t=m \\times y_t-1+(1-m) \\times x_t
yt=m×yt−1+(1−m)×xt,
y
t
−
1
y_t-1
yt−1 为上一时刻的输出,
x
t
x_t
xt 为当前输入,
m
m
m 为动量参数;当
m
m
m 很大时,
y
t
y_t
yt 就取决于上一时刻输出,其更新就很缓慢;当
m
m
m 很小时,
y
t
y_t
yt 就取决于当前时刻输入。
作者团队来自于 FAIR,就不过多介绍了,五个人谷歌学术引用数达到了50万+。

下面是论文摘要,摘要写的很简洁,总共只有7句话。
- 第1句话直接介绍主题,我们提出了
MoCo用于无监督视觉表征学习。第2句话意思是我们把对比学习看作是字典查询,我们建立了一个动态字典,使用到了对列和移动平均编码器。 - 第3句话意思是使用队列和移动平均编码器,我们可以建立一个很大且一致的字典,有助于对比无监督学习。
- 第4-6句话是模型效果,
MoCo在ImageNet分类上取得了很有竞争力的结果,其中linear protocol的意思是说将主干网冻结,只训练分类头。更重要的,将 MoCo 学到的特征迁移到下流任务时,在7个检测和分割任务上,MoCo都超过它的有监督预训练对手,counterpart的意思是有监督和无监督训练都使用同一个网络,例如ResNet-50。 - 最后一句话的意思是,在许多视觉任务上,无监督和有监督特征学习之间的鸿沟被大幅度的填上了。

下面是论文引言部分,
2. 相关工作
3. Moco模型、实验
以上是关于[重读经典论文]EfficientDet的主要内容,如果未能解决你的问题,请参考以下文章