Python入门 第二节
Posted wang0424
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python入门 第二节相关的知识,希望对你有一定的参考价值。
1 模块初识
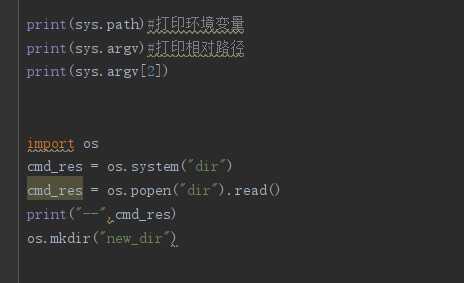
Python的有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持我们。先来象征性的学2个简单的,以sys模块和os模块为例:
2 Python数据类型
1.1 数字
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
浮点数用来处理实数,即带有小数的数字。占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
1.2布尔值
真或假
1 或 0
1.3字符串
“Hello World”
PS: 字符串是 %s;整数 %d;浮点数%f
1.4列表
基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 切片
- 循环
- 包含
1.5元组(不可变列表)
1.6字典(无序)
常用操作:
- 索引
- 新增
- 删除
- 键、值、键值对
- 循环
- 长度
3 列表
import copy
names = ["wangzhuoqun","xiewenwu","xiehao","shenshunqi","wangxuheng"] #列表
print(names) #遍历列表
print(names[0]) #读取列表
print(names[1],names[3])#读取列表
print(names[1:3]) #切片读取列表(左闭右开)
print(names[-1]) #右取值
print(names[-3:-1]) #右切片
print(names[-3:]) #右切片
print(names[0:4:2]) #跳步长切片
names.append("wangyuran")
print(names) #追加
names.insert(1,"wangshuai")#指定位置插入,1代表插入位置
print(names)
names[2] = "wangqishen" #替换
print(names)
names.remove("wangzhuoqun")#删除某项
print(names)
del names[1]#删除第几个
print(names)
names.pop()#删除最后一项,()有内容等同于del
print(names)
print(names.index("xiehao"))#找某个内容的位置
print(names[names.index("xiehao")])#打印某个位置
‘‘‘
names2 = ["wangzhuoqun","xiewenwu","xiehao","shenshunqi","wangxuheng","xiewenwu"] #有重名列表
‘‘‘
print(names2.count("xiewenwu"))#打印某内容在列表里出现的次数
names.clear()#清空列表
print(names)
names.reverse()# 反转列表
print(names)
names.sort()#按ASCII顺序排序
print(names)
names.extend(names2)#names2并入names names2仍存在
print(names)
del names2 #删除列表names2
print(names2)
names2 = names.copy() #将names拷贝至names2(只copy第一层,无法copy内层) 详见 copy.py
print(names,names2)
names[1] = "谢文武"
print(names)
names3 = ["wangzhuoqun","xiewenwu","xiehao","shenshunqi","wangxuheng",["wangyuren","wangshuai"],"xiewenwu"] #包含列表的列
names4 = copy.deepcopy(names3) #调用copy函数 用deepcopy 实现内外侧全部copy 不随另一个改变而改变
names3[5][0] = "汪宇蚺"#更改列表内部的列表
print(names3)
print(names4)
for i in names: #列表循环输出
print(i)
for i in names3:
print(i)
另外特别注释copy
# copy 无论改copy对象还是被copy对象 不能copy到内层列表 只copy到最外层列表 即最外层不变 内层随被另一个变化而变化 这跟内外侧列表的存储地址有关
#import copy
names = ["wangzhuoqun","xiewenwu",["xiehao",["wnagyuren","wangshuai"],"shenshunqi"],"wangxuheng"]
names2 = names.copy()
print(names)
print(names2)
names[1] = "谢文武"
names[2][0] = "薛浩"
print(names)
print(names2)
names[0] = "王卓群"
names[2][0] = "薛浩"
names[2][1][1] = "王帅"
print(names)
print(names2)
names3 = copy.deepcopy(names2)
print(names3)
4 元组
names = ("wangzhuoqun","xiewenwu","xiehao")
names.count()
5 字典
info = {
‘stu1101‘:"wangzhuoqun",
"stu1102":"xiehao",
"stu1103":"xiewenwu"
}
b={
‘stu1101‘:"wangxuheng",
1:2,
3:5
}
‘‘‘print(info) #输出字典
print(info["stu1101"]) #输出键stu110# 1
print(info.get(‘stu1103‘)) #输出stu1103 ,不出现报错g
print("stu1103" in info) #判断字典中是否存在stu1103
info["stu1101"]= "王卓群" #替换字典中的元素
print(info)
info["stu1104"] = "shenshunqi" #在字典中添加元素
print(info)
del info["stu1102"] #删除字典中的一项
print(info)
info.pop(‘stu1101‘) #删除字典中的一项
print(info)
info.popitem() #随机删除一个
print(info)
print(info.keys()) #取所有键值
print(info.values()) #取所有内容
print(info.setdefault("stu1106","Alex")) #去字典里查找stu1106,如果找到取出,如果没找到,赋值为Alex
info.update(b) #将两个字典合并 ,重复的替换
print(info)
print(info.items()) #将字典转换成一个列表
c = info.fromkeys([5,6,7,8],"text") #初始化字典 后面补充6 7 8 ,赋值为text
print(c)
for i in info:
print(i,info[i])
‘‘‘
6 字符串操作
name = "My name is alex"
‘‘‘print(name.capitalize()) #首字母大写
print(name.count("a")) #字符串中某字母出现的个数
print(name.center(50,"-")) #打印50个字符,name外不够的用-补充,那么居中
print(name.endswith("ex")) #判断是否以ex为结尾
print(name.expandtabs(tabsize = 30)) #将字符串中的 转换成一定数目个空格
print(name.find("y")) #打印y在字符串中所在的位置
print(name[name.find("name"):])
print(name.format( ))
print(name.format_map( )) #导入一个字典
print(name.isalnum()) #判断字符串是不是完全由数字和字母组成
print(name.isalpha()) #判断字符串是不是完全由字母组成
print(name.isdigit()) #判断是不是整数
print("1A".isidentifier()) #判断是不是合法的标识符
print(name.islower()) #判断是不是小写
print(name.isnumeric()) #判断是不是只包含数字
print(‘+‘.join(["1","2","3"])) #将列表转换为字符串,用+分隔
print(name.ljust(50,"*")) #字符数50 不够在后面用*补充
print(name.rjust(50,"-")) #字符数50 不够在前面用-补充
print(name.lower()) #全部小写
print(name.upper()) #全部大写
print(name.lstrip()) #去除左边胡空格肯会车
print(name.rstrip()) #去除右边胡空格和会车
print(name.strip()) #去除两边在空格和会车
p = str.maketrans("abcdef","123456")
print("Alex li".translate(p)) #用p方式替换加密
print(name.replace("a","A",1)) #将某字母换成其他,变换1个
print(name.rfind("l")) #找到左起第一个l的下标
print(name.split("a")) #以某字母为分割形成列表
print(name.swapcase()) #大小写互换
‘‘‘
以上是关于Python入门 第二节的主要内容,如果未能解决你的问题,请参考以下文章