读改变未来的九大算法笔记06_图形识别
Posted 躺柒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读改变未来的九大算法笔记06_图形识别相关的知识,希望对你有一定的参考价值。
看似智能的行为有可能从看似随机的系统中浮现出来
1. 人工智能研究人员在过去几十年中学到的最重要的教训之一
1.1. 看似智能的行为有可能从看似随机的系统中浮现出来
1.2. 如果我们有能力进入人脑,研究神经元之间连接的强度,其中绝大部分连接都会表现得很随机
1.3. 当作为集合体行动时,这些连接强度的松散集合产生了人的智能行为
2. 图形识别是人类具有天然优势的一个领域
3. 图形识别是人工智能(AI)的一部分
3.1. 图形识别处理高度变化的输入数据,如音频、照片和视频
3.1.1. 面部识别
3.1.2. 物体识别
3.1.3. 语音识别
3.1.4. 笔迹识别
3.2. 好的图形识别系统需要巨大的人力,但这是一次性投入,并能产生长期回报
3.3. 检验一种图形识别算法在哪些情况下会失效总是很吸引人
3.4. AI处理的任务更多元
3.4.1. 计算机国际象棋
3.4.2. 在线聊天机器人
3.4.3. 人形机器人
3.5. 任务的逐渐转变——从明显是直觉性的任务到显然是机械化的任务——还在继续
3.6. 普遍意义上以及图形识别中特殊意义上的人工智能正慢慢扩展它们的边界,提升它们的效能
3.7. 比如
3.7.1. 一份复杂的检验结果中帮助诊断病人疾病
3.7.2. 在自动收费亭识别汽车牌照
3.7.3. 向某个计算机用户展示什么广告
4. 最近邻分类器
4.1. 标准做法是将图形识别看作分类问题
4.2. 让计算机自动“学习”如何分类样本
4.2.1. 基本策略是给计算机标记大量数据(Labeled Data):已经被分类的样本
4.2.2. 每个样本都带有一个标签(也就是它的类),计算机能运用多种分析把戏提取每个类的特性
4.2.3. 之后再向计算机提供一个未标记的样本,通过选择和未标记样本特性最接近的样本,计算机能推测未标记样本的类
4.3. 点与点之间的地理距离,就能得出相距最近的点
4.4. 示例
4.4.1. 根据一个人的家庭住址,预测那个人会向哪个政治党派捐赠吗
4.4.2.
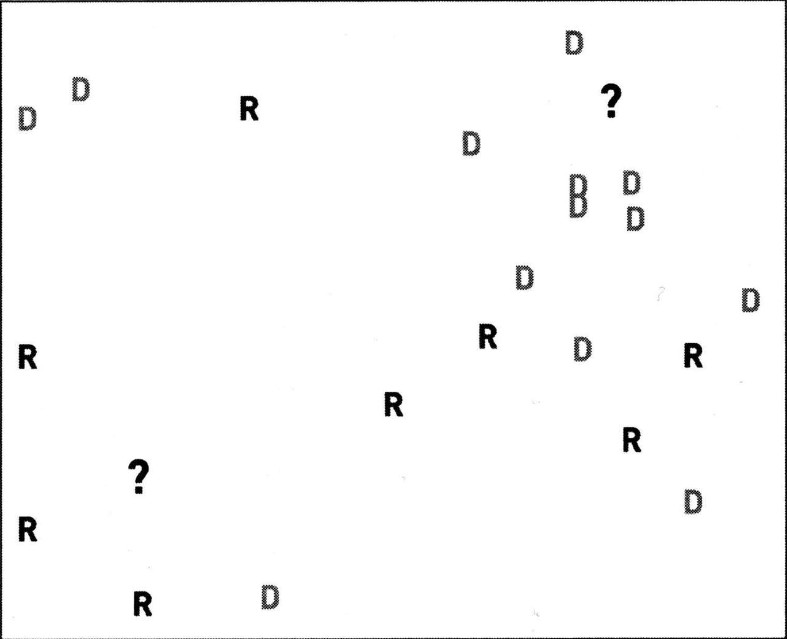
4.4.2.1. 右上角的?选择D,左下角的?选择R
4.4.2.2. 每个问号都被归为其最相邻对象所属的类
4.5. K个最近邻
4.5.1. K Nearest-neighbors
4.5.2. K代表3或5这样的小数字
4.5.3.
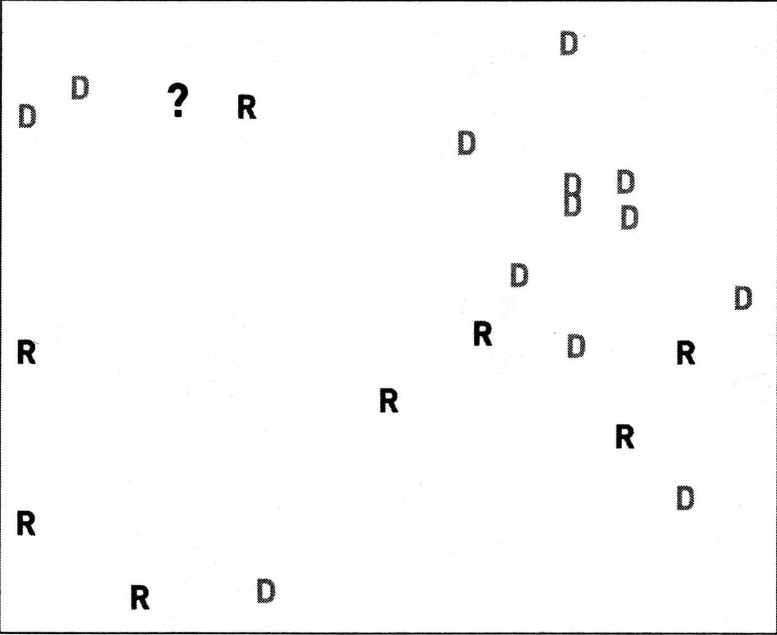
4.5.3.1. 左上角的?
4.5.3.1.1. 当只使用单个最近邻时,问号被归为“R”
4.5.3.1.2. 当使用三个最近邻时,问号被归为“D”
4.6. 手写数字
4.6.1. 人类也没有这种内置知识
4.6.1.1. 通过结合其他人的详尽教授以及观看我们用来教授自己的例子,我们学会了如何去识别数字及其他手写符号
4.6.2. 计算机并没有内建手写数字是什么样的知识
4.6.2.1. 这两种策略(详尽教授和从例子中学习)也被用于计算机图形识别
4.6.3. 计算两个不同手写数字示例之间的“距离”
4.6.3.1. 衡量数字图像之间的区别度,而非它们之间的地理距离
4.6.4. 区别度以百分比形式衡量
4.6.4.1. 区别度只有1%的图像是非常相近的邻
4.6.4.2. 区别度在99%的图像则相差很远
4.6.5.
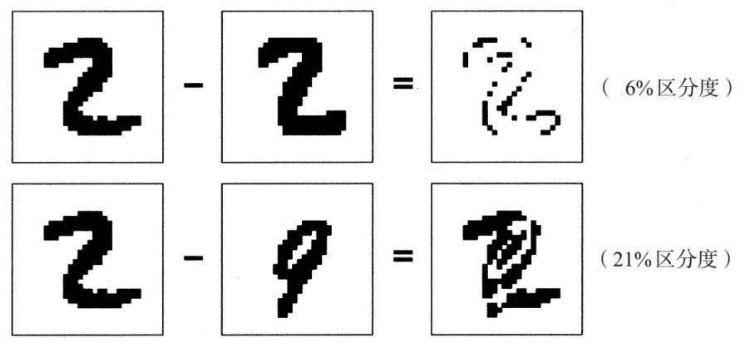
4.6.5.1. 在每一行,都要用第一张图减去第二张图,并得出右边的新图像,新图像中突出了这两张图中的区别
4.6.5.2. 区分度图像中突出部分所占的百分比,就能被视为原始图像之间的“距离”
4.6.5.3. 使用这种“最近邻”距离方法的系统效果相当好,精确度接近97%
4.6.6. 运用最先进的距离衡量法,最近邻分类器在手写数字上的精确度能超过99.5%
4.6.6.1. 这一精确度能和复杂得多的图形识别系统相比
4.6.6.2. 支持向量机(Support Vector Machine)
4.6.6.3. 回旋神经网络(Convolutional Neural Network)
4.7. 最近邻分类器的特殊属性:它们无须任何详尽的学习阶段
4.7.1. 直接使用最近邻把戏跳到了分类阶段
4.8. 在学习阶段无须费力
4.8.1. 但分类阶段要求我们将需要分类的每个东西和所有训练示例进行比对
5. 决策树
5.1. 基本上就是一个提前计划的20个问题游戏
5.1.1. 从“决策树”顶部开始,按照问题的答案一路往下即可
5.1.2. 当你到达“决策树”底部的一个框时,你也就得到了最终结果
5.2. 示例:网络垃圾
5.2.1.
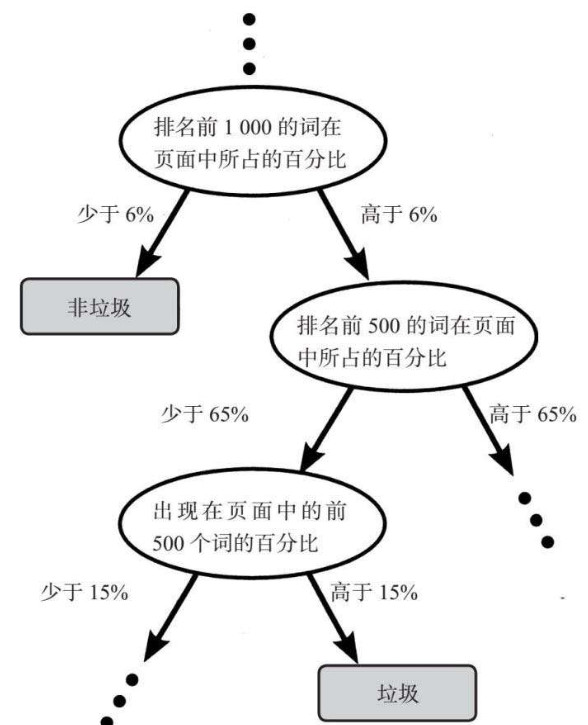
5.2.2. 网络垃圾制造者喜欢在页面中加入大量流行词以提升他们网页的排名,因此流行词占比较小,也预示该网页是垃圾的概率较低
5.2.3. “训练”页面被真人分为“垃圾”或“非垃圾”
5.2.4. 整棵“决策树”是由计算机程序基于约1.7万个网页上的训练数据自动生成的
5.3. 如果你有足够多的训练数据,系统可能会向一棵能进行精确分类的“决策树”学习
5.4. “决策树”分类器学习阶段的任务量非常庞大
5.4.1. 计算机测试大量可能出现的第一个问题,寻找一个能得出最佳可能信息的问题
5.4.2. 计算机将训练样本分为两组,这取决于样本对第一个问题的答案,并产生第二个对这两个组都是最佳的可能问题
5.4.3. 计算机一直用这种方法往“决策树”底部前进,永远基于达到“决策树”某一点的训练示例集合来决定最佳问题
5.4.4. 如果示例集合在某一点变得“纯净”,也就是说,集合中只包含“垃圾”页面或“非垃圾”页面,计算机就能停止生成新问题,输出对应剩余页面的答案
5.5. 学习过程可以很复杂,但它是全自动的,而且你只需要做一次
6. 神经网络
6.1. 人工神经网络领域(Artificial Neural Networks),简称“神经网络”
6.2. 其学习阶段不仅重要,而且直接受到人类和其他动物从环境中学习的方法的启发
6.3. 英国科学家阿兰·图灵(Alan Turing)
6.3.1. 1950年发表的经典论文《计算机器与智能》(Computing Machinery and Intelligence)以其对计算机是否能伪装成人类的哲学探讨而闻名于世
6.4. 当给予相同的输入时,“决策树”和神经网络产生了相同的结果
6.5. 示例:带伞问题
6.5.1.
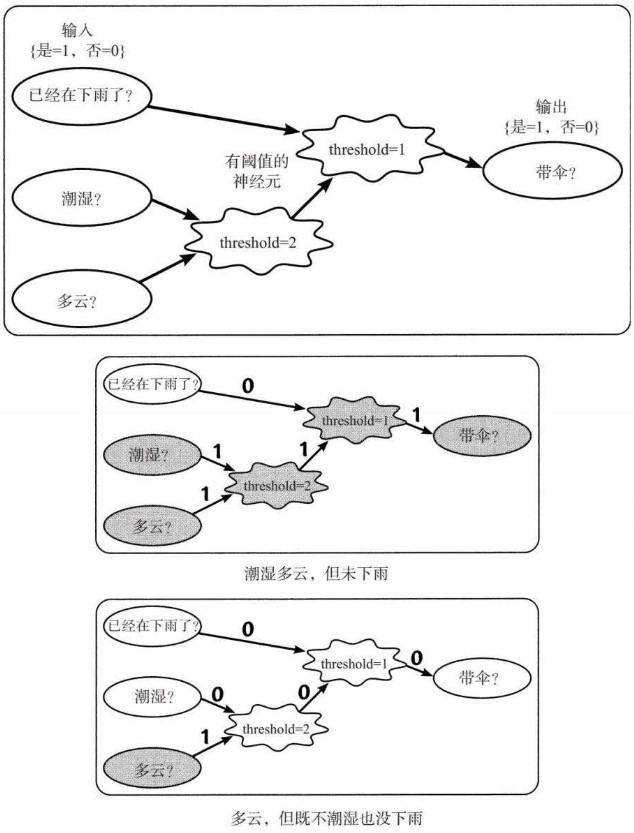
6.5.2. 带伞网络中的输入和输出信号被限制在0和1,不能携带任何中间值
6.5.3. 神经元在没有用任何方法替换输入的情况下将输入相加
6.6. 示例:判断人脸上是否带太阳镜
6.6.1.
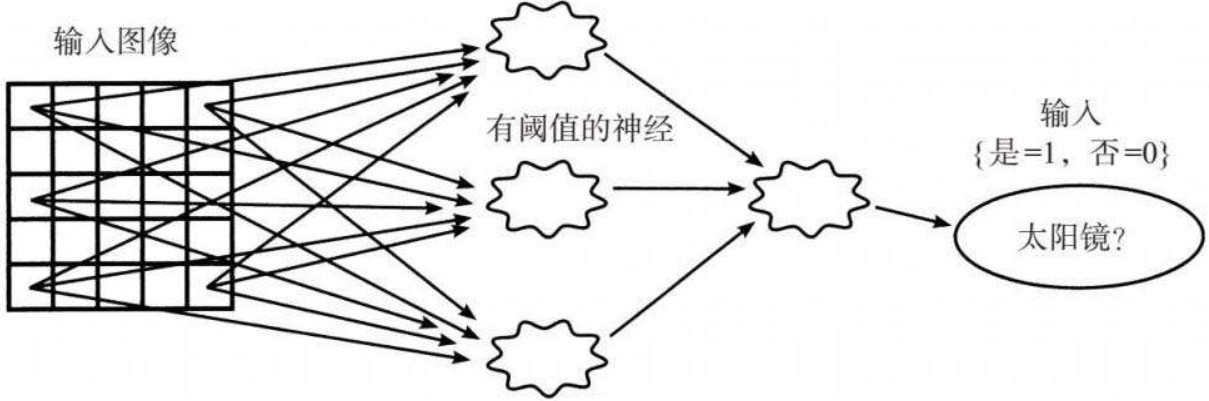
6.6.2. 增强措施1:信号只能携带0和1之间的任意值
6.6.2.1. 新网络中的信号值可以是0.002 3或0.755
6.6.2.2. 一个全白的像素会发送值1
6.6.2.3. 一个全黑的像素会发送值0
6.6.2.4. 不同灰度会对应地产生0~1的值
6.6.3. 增强措施 2:输入总和,通过加权求和计算
6.6.3.1. 神经网络考虑了每个连接强度不同的情况
6.6.3.2. 连接的强度由一个数字代表,这个数字被称为该连接的权重
6.6.3.3. 当一个神经元计算其输入的总和时,每个输入信号在被加进总和之前,都会和其连接的权重相乘
6.6.4. 增强措施3:阈值的作用被软化
6.6.4.1. 当输入总和远低于阈值时,输出会接近于0
6.6.4.1.1. 输出值接近0,则强烈暗示了不存在太阳镜
6.6.4.1.2. 低于0.5的输出结果被视为“没有太阳镜”
6.6.4.2. 当输入总和远高于阈值时,输出接近于1
6.6.4.2.1. 输出值接近1强烈暗示了存在太阳镜
6.6.4.2.2. 超过0.5的输出结果被视为“有太阳镜”
6.6.4.3. 当输入总和接近阈值时,会产生一个接近0.5的中间输出
6.6.5. 可以将权重和阈值想象成网络中的小刻度盘,每个刻度盘都能像电灯开关中的调光器一样调上调下
6.6.6. 最开始,这些刻度盘的值都是随机值
6.6.7. 在多次运行完所有训练样本后,网络的效能基本上会达到很高的水平,而学习阶段也以配置当时的刻度盘而结束
6.6.7.1. 多变量微积分(Multivariable Calculus)
6.6.7.2. 随机梯度下降(Stochastic Gradient Descent)
6.6.7.2.1. 用于训练神经网络的多种公认方法之一
6.6.8. 神经网络的学习阶段相当耗费精力,这涉及对所有权重和阈值的反复调整,直到网络在训练样本上运作良好
6.6.9. 所有这些都能被计算机自动完成,而结果就是一个能简单高效地给新样本分类的网络
读Java性能权威指南(第2版)笔记23_ 性能分析工具

1. 性能分析工具
1.1. 必须有足够大的堆来处理数据
1.2. 运行性能分析工具时开启并发GC算法
1.3. 不合时宜的Full GC暂停会导致缓冲区的数据溢出
1.4. 性能分析的一个缺陷就是在应用程序中引入测试会改变其性能
1.5. 在工作时要“附加”到被分析的应用程序上
-
1.5.1. 通过socket或者被称为JVM工具接口(JVM Tool Interface,JVMTI)的原生Java接口进行的
-
1.5.2. 目标应用程序和性能分析工具开始交换关于目标应用程序行为的信息
2. 采样分析器
2.1. 性能分析的基本模式
2.2. 想要减小误差,就要延长采样周期并减小采样间隔
2.3. 安全点偏差(safepoint bias)
- 2.3.1. 只有在线程到安全点之后才可以获取线程的栈轨迹(stack trace)
2.4. 线程自动进入安全点场景
-
2.4.1. 在同步锁上阻塞
-
2.4.2. 等待I/O时阻塞
-
2.4.3. 等待管程时阻塞
-
2.4.4. 线程挂起
-
2.4.5. 正在执行Java本地接口(Java Native Interface,JNI)代码(执行GC锁定函数除外)
2.5. 异步分析器(async profiler)
-
2.5.1. JVM可以在任何时间点提供栈信息,而无须等待线程到达(同步)安全点
-
2.5.2. 通过AsyncGetCallTrace接口实现的
-
2.5.3. 异步接口在Java 8被公开,在此之前它是私有接口
-
2.5.4. 以异步方式收集栈信息的采样分析器引入的测量失真更小
2.6. 火焰图(flame graph)
-
2.6.1. 一个应用程序调用栈的交互式图表
-
2.6.2. 自底向上的图表
-
2.6.3. 开源项目async-profiler
2.7. 自顶向下的调用树(call tree)
3. 探查分析器
3.1. 相对于采样分析器更有侵入性
- 3.1.1. 会在类加载时更改字节码序列
3.2. 能提供更多关于应用程序内部正在发生什么的有益信息
3.3. 更可能在应用程序中引入性能偏差
- 3.3.1. 编译器是基于代码的大小来决定是否内联的,而根据代码探查的方式,方法可能不再符合内联的条件
3.4. 最好用于二级分析
-
3.4.1. 采样分析器将性能问题指向某个包或某段代码,然后探查分析器在需要时深入研究此代码
-
3.4.2. 用于探查一小部分代码——几个类或包
4. 阻塞方法和线程时间线
4.1. 要知道线程阻塞是不是性能问题的原因,需要检查它们为什么被阻塞
4.2. 通过正在阻塞的方法或者线程时间线分析,可以分辨阻塞的线程
5. 原生分析器
5.1. async-profiler和Oracle Developer Studio的工具
5.2. 可以提供JVM代码和应用程序代码的内部运行信息
5.3. 如果原生分析器显示主要占用CPU资源的是GC时间,那么优化垃圾回收器是正确的选择
5.4. 如果它显示编译线程占用大量时间,那么这通常不会影响应用程序的性能
以上是关于读改变未来的九大算法笔记06_图形识别的主要内容,如果未能解决你的问题,请参考以下文章