深度学习降噪专题课:整体介绍降噪算法
Posted 欢迎来到杨元超的世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习降噪专题课:整体介绍降噪算法相关的知识,希望对你有一定的参考价值。
大家好~本课程基于全连接和卷积神经网络,学习LBF等深度学习降噪算法,实现实时路径追踪渲染的降噪
本课程偏向于应用实现,主要介绍深度学习降噪算法的实现思路,演示实现的效果,给出实现的相关代码
线上课程资料:
本节课录像回放
加QQ群,获得相关资料,与群主交流讨论:106047770
本系列文章为线上课程的复盘,每上完一节课就会同步发布对应的文章
本课程系列文章可进入合集查看:
深度学习降噪专题课系列文章合集
降噪的目的
光追、路径追踪 都会产生噪点,需要降噪
实时路径追踪渲染中,降噪是重点
传统降噪方法
小波过滤
SVGF、BMFR
针对1 spp降噪
算法的基本思想:
- 通过帧间复用,累积多帧的采样数,从而提升1 spp到X spp
- 在Compute Shader中使用小波过滤、线性代数过滤等传统过滤方法对采样的图片降噪
- 结合TAA,实现抗锯齿
它们属于实时降噪,其中:
SVGF耗时:4ms
BMFR耗时:1.6ms
深度学习降噪方法
这是最近的趋势,目前已经有了深度学习蒙特卡洛实时渲染降噪,如WSPK,它只耗时7ms左右
深度学习蒙特卡洛降噪和深度学习图片降噪区别
前者多出了使用辅助特征来加速收敛,辅助特征包括:normal、world position、camera space depth、albedo等
深度学习蒙特卡洛降噪介绍
深度学习蒙特卡洛降噪主要包括LBF、KPCN、WPSK等算法
深度学习蒙特卡洛降噪的基本思想
主要包括下面几个部分:
输入->network->输出
其中,分为训练、推理两个阶段
在训练阶段中:
输入是包含辅助特征的多个patch数据,如对于KPCN而言,输入的tensor的shape为[64,28,128,128],它是一个batch的输入数据,batch size为64,有28个channel,大小为(128宽,128高)
输出是包含颜色(也就是辐射亮度)的patch数据,如对于KPCN而言,输出的tensor的shape为[64,3,128,128],它是一个batch的输出数据,batch size为64,有3个channel(辐射亮度的r、g、b),大小为128*128
在推理阶段中:
输入是包含辅助特征的整个场景图片,如对于KPCN而言,输入的tensor的shape为[1,28,720,1280],它是一个batch的输入数据,batch size为1,有28个channel,大小为场景大小(这里为1280宽,720高)
输出是包含颜色(也就是辐射亮度)的整个场景图片,如对于KPCN而言,输出的tensor的shape为[1,3,720,1280],它是一个batch的输出数据,batch size为1,有3个channel(辐射亮度的r、g、b),大小为场景大小(这里为1280宽,720高)
训练通常是离线的,它的dataset是预先准备好的图片。训练完成后,将模型数据保存到文件中。
推理通常是实时的,它的dataset是图片或者GPU数据(如WebGPU中的GBuffer数据,它保存了辅助特征以及color),需要先读取模型数据到network中
为了提高训练和推理速度,我们通常是优化network这部分:
如使用更快收敛的network,以及改进network的输出层(如通过核预测实现类似于softmax的输出);
另外,对于WPSK而言,由于network使用了RepVGG块,可以通过结构重参数化来使得训练和推理的network的结构不一样(训练的network是多路架构,推理的network是单路架构),从而提高network的收敛速度
深度学习蒙特卡洛降噪的实现
我们会使用pytorch框架来实现训练,使用WebNN API来实现推理
WebNN API是浏览器提供的深度学习API,底层调用了深度学习硬件来加速,同时使用WebGPU、WebGL来做polyfill
感谢您的阅读~
扫码加入我的QQ频道:

扫码加入免费知识星球-YYC的Web3D旅程:

(深度学习快速入门)自编码器及其变体(关键词:自编码器堆叠降噪变分AESAESDAEVAE)
文章目录
一:自编码器(AE)
自编码器(Auto-Encoders, AE):自编码器可以理解为一个试图还原原始输入的系统,主要由编码器(Encoder)和解码器(Decoder)组成,其主要目的是将输入 x x x转换成中间变量 y y y,然后再把 y y y转化为 x ︿ \\mathopx\\limits^︿ x︿,训练 x x x和 x ︿ \\mathopx\\limits^︿ x︿让它们无限接近

从直观上来看,自动编码器可以用于特征降维,类似主成分分析PCA,但是其相比PCA其性能更强,这是由于神经网络模型可以提取更有效的新特征。除了进行特征降维,自动编码器学习到的新特征可以送入有监督学习模型中,所以自动编码器可以起到特征提取器的作用
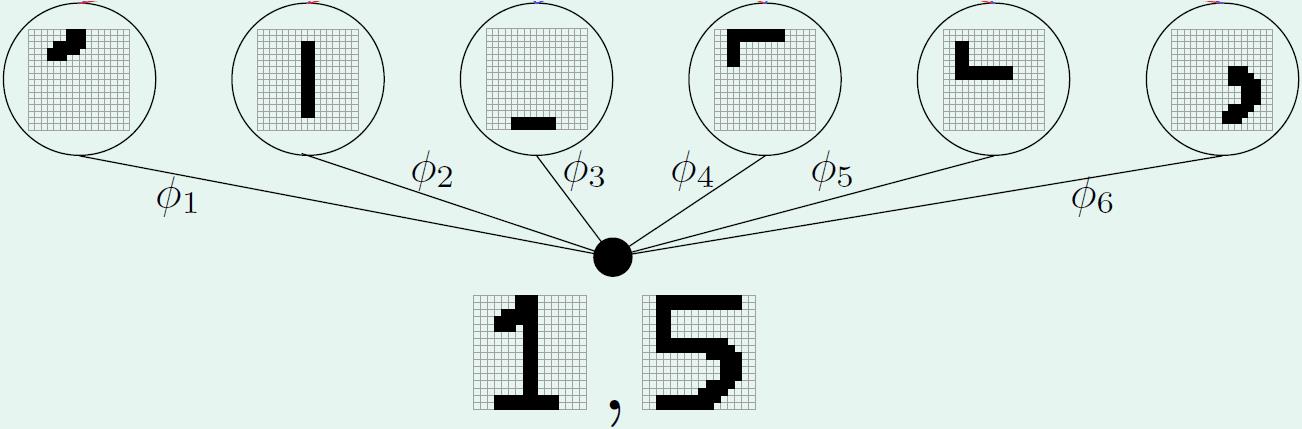
比如下图,将手写数字图片进行编码,编码后生成的
ϕ
1
\\phi_1
ϕ1~
ϕ
6
\\phi_6
ϕ6 较完整的保留了原始图像的典型特征,因此可较容易地通过解码恢复出原始图像
如下,利用Pytorch实现一个简单的自编码器
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 定义网络模型
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 128),
nn.ReLU(True),
nn.Linear(128, 64),
nn.ReLU(True),
nn.Linear(64, 12),
nn.ReLU(True),
nn.Linear(12, 3), # encoding layer
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(True),
nn.Linear(12, 64),
nn.ReLU(True),
nn.Linear(64, 128),
nn.ReLU(True),
nn.Linear(128, 28 * 28),
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
# 加载数据集并预处理
from torchvision.datasets import MNIST
dataset = MNIST(root='data/', download=True)
data_loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size=100,
shuffle=True)
# 定义损失函数和优化器
model = Autoencoder().cuda()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
for epoch in range(100):
for data in data_loader:
img, _ = data
img = img.view(img.size(0), -1).cuda()
# ===================forward=====================
output = model(img)
loss = criterion(output, img)
# ===================backward====================
optimizer.zero_grad()
loss.backward()
optimizer.step()
# ===================log========================
print('epoch [/], loss::.4f'
.format(epoch + 1, 100, loss.data.item()))
# 保存模型
torch.save(model.state_dict(), 'autoencoder.pth')
二:自编码器变体
(1)堆叠自编码器(SAE)
堆叠自编码器(Stacked Autoencoder, SAE):将多个自编码器进行堆叠,每个自编码器的输出都作为下一个自编码器的输入,并且每个自编码器都可以训练从原始数据到低维表示的映射

如下,用Pytorch实现一个堆叠自编码器
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
# 设置随机种子
torch.manual_seed(0)
# 加载 MNIST 数据集
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=64, shuffle=True)
# 定义自动编码器模型
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(32, 64),
nn.ReLU(),
nn.Linear(64, 128),
nn.ReLU(),
nn.Linear(128, 28 * 28),
nn.Sigmoid()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
# 堆叠自动编码器
class StackedAutoencoder(nn.Module):
def __init__(self):
super(StackedAutoencoder, self).__init__()
self.autoencoder1 = Autoencoder()
self.autoencoder2 = Autoencoder()
self.autoencoder3 = Autoencoder()
def forward(self, x):
x = self.autoencoder1(x)
x = self.autoencoder2(x)
x = self.autoencoder3(x)
return x
# 创建堆叠自动编码器模型
model = StackedAutoencoder()
# 定义损失函数和优化器
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 训练模型
num_epochs = 30
for epoch in range(num_epochs):
for data in train_loader:
img, _ = data
img = img.view(img.size(0), -1)
output = model(img)
loss = criterion(output, img)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch+1) % 5 == 0:
print('Epoch [/], Loss: :.4f'.format(epoch+1, num_epochs, loss.item()))
# 在测试数据上评估模型
with torch.no_grad():
correct = 0
total = 0
for data in test_loader:
img, label = data
img = img.view(img.size(0), -1)
output = model(img)
total += label.size(0)
correct += (output.round() == img).sum().item()
print('Accuracy on test set: / (:.0f%)'.format(correct, total, 100. * correct / total))
(2)降噪自编码器(DAE)
降噪自编码(Denoising Auto-Encoders, DAE):首先对干净的输入信号加入噪声产生一个受损的信号。然后将受损信号送入传统的自动编码器中,使其重建回原来的无损信号
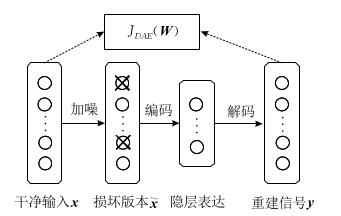
降噪编码器与传统自编码器的主要区别在于
- 降噪自编码器通过人为的增加噪声使模型获得鲁棒性的特征表达
- 避免使隐层单元学习一个传统自编码器中没有意义的恒等函数
降噪自编码器优缺点
- 优点:重建信号对输入中的噪声具有一定的鲁棒性
- 缺点:每次进行网络训练之前,都需要对干净输入信号人为地添加噪声,以获得它的损坏信号,这无形中就增加了该模型的处理时间
(3)堆叠降噪自编码器(SDAE)
堆叠降燥自编码器 (Stacked Denoising Auto-Encoders, SDAE):它是降噪自编码器的一个应用方法,采用了降噪编码器的编码器(encoder)作为基础单元,这个编码器是被预训练(pre-training)好的
如下图所示,编码器 f 1 f_1 f1, f 2 f_2 f2,…, f n f_n fn分别对应的是预训练号的降噪自编码器 D 1 D_1 D1、 D 2 D_2 D2、 D n D_n Dn的编码函数(编码器)
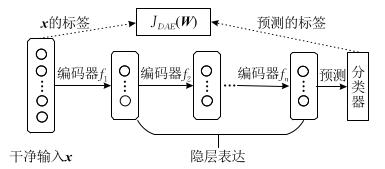
堆叠降噪自编码器训练过程如下
- 输入 x x x
- 加入噪声,和 f 1 f_1 f1对应的解码器 f 1 、 f_1^、 f1、采用降噪自编码器的方式进行训练
- 固定 f 1 f_1 f1,以相同方式训练 f 2 f_2 f2, f 3 f_3 f3,…, f n f_n fn,并在最后一层加入分类器
- 利用 x x x的真实标签和预测标签以监督方式进行训练,对网络参数进行微调
SDAE可以看作是监督学习和无监督学习的结合。在无监督学习中,通过编码-解码过程学习输入数据的表示,而不需要标记数据。并且,其降噪方面通过强制它从损坏的版本重建原始输入,进一步增强了它学习有意义的数据表示的能力。在监督学习中,它学习到的表示可以用作下游监督任务的特征,例如分类或回归。其最后一层通常替换为分类器或回归器,自动编码器的权重根据特定任务的标记数据进行微调。因此,SDAE 可以被视为无监督学习和有监督学习的混合体,其中无监督组件为数据提供有意义的表示,而有监督组件将这些表示用于特定任务
(4)变分自编码器(VAE)
变分自动编码器(Variational Auto-Encoders, VAE):是一种主要用于数据生成的自编码器的变体。首先利用数据训练变分自编码器,然后只使用变分自编码器的解码部分,自动生成与训练数据类似的输出。相当于在传统自编码器的隐层表达上增加一个对隐变量的约束(目的使编码器产生的隐层表达满足正态分布,能够更好的生成图像模型),是一种将概率模型和神经网络结构结合的方法
整个结构可以分成三个部分,分别是编码部分,解码部分和生成部分。编码部分和解码部分同时进行训练
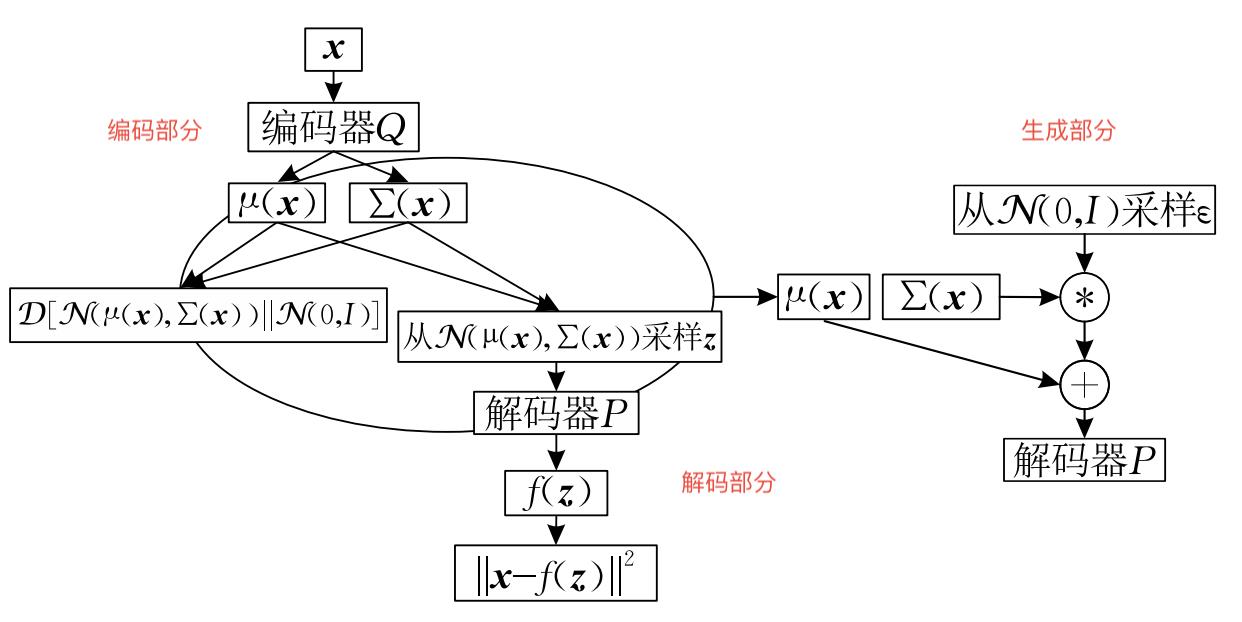
VAE采用方差推断技术最大化ELBO公式
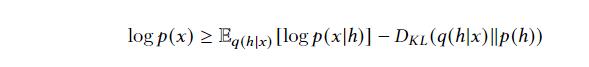
其中
- D K L D_KL DKL表示两个分布之间的KL散度
- p h p_h ph是潜在表征的先验分布
- q ( h ∣ x ; ϕ ) q(h|x;\\phi) q(h∣x;ϕ)是表示的变分后验,用来逼近真实后验
如下,使用Pytorch实现一个简单的VAE模型
VAE的架构由两部分组成:编码器和解码器。编码器获取输入数据 x 并通过两个全连接层 fc1 和 fc2 将其转换为潜在表示 z。 reparameterize 方法从均值 mu 和方差 log_var 的对数生成样本 z。然后解码器采用潜在表示 z 并通过两个完全连接的层 fc3 和 fc4 重建原始数据 x。
import torch
import torch.nn as nn
import torch.nn.functional as F
class VAE(nn.Module):
def __init__(self, input_size, hidden_size, latent_size):
super(VAE, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, latent_size * 2)
self.fc3 = nn.Linear(latent_size, hidden_size)
self.fc4 = nn.Linear(hidden_size, input_size)
def encode(self, x):
h = F.relu(self.fc1(x))
return self.fc2(h)
def reparameterize(self, mu, log_var):
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h = F.relu(self.fc3(z))
return torch