K8S | 核心原理分析
Posted 知了一笑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K8S | 核心原理分析相关的知识,希望对你有一定的参考价值。
 K8S作为开源的容器编排引擎,用来对容器化应用进行自动化部署、 扩缩和管理;
K8S作为开源的容器编排引擎,用来对容器化应用进行自动化部署、 扩缩和管理;
整体上理解流程和原理;
一、背景
基于分布式的架构中,需要管理的服务是非常多的,无论是服务的数量还是体系划分;
从服务的能力上看,可以进行分层管控,只是其中有相当一部分服务层,改动更新的频率很低,所以感知也不明显;

就以自己当下参与研发的系统来说;
通过K8S进行管理的服务近百个,这中间有部分服务采用集群模式,即便是这个规模的系统,也几乎不可能依赖纯人工运维的形式,自动化流程必不可少;
二、持续集成
此前围绕该主题写过一个完整的实践案例,主要围绕Jenkins、Docker、K8S等组件的使用层面,总结源码编译、打包、镜像构建、部署等自动化管理的流程;
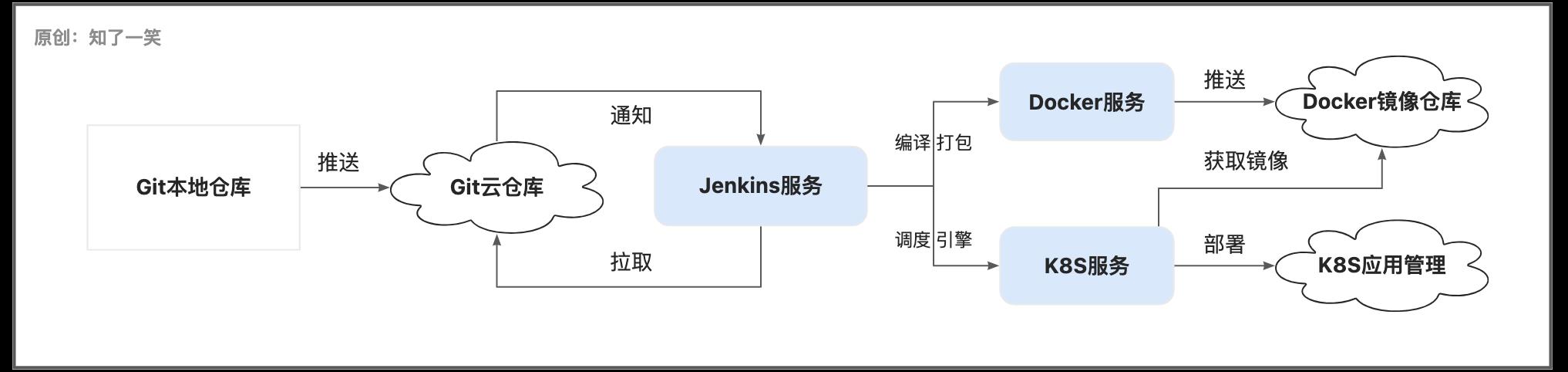
Jenkins:是一个扩展性非常强的软件,用于自动化各种任务,包括构建、测试和部署等;
Docker:作为开源的应用容器引擎,可以把应用程序和其相关依赖打包生成一个Image镜像文件,是一个标准的运行环境,提供可持续交付的能力;
Kubernetes:作为开源的容器编排引擎,用来对容器化应用进行自动化部署、 扩缩和管理;
三、K8S架构
1、核心组件

Control-Plane-Components:控制平面组件
对集群做出全局决策,例如:资源调度、检测、事件响应,可以在集群中的任何节点上运行;
- api:开放K8S的API,组件之间通过API交互,相当于控制面的前端;
- controllermanager:运行控制器进程,逻辑上是一个单独的进程;
- scheduler:监听新建未指定运行节点的Pods,并为Pod选择运行节点;
- etcd:兼具一致性和高可用性的键值数据库,作为保存K8S数据的后台库;
Node:节点组件
该组件会在每个节点上运行,负责维护运行的Pod并提供Kubernetes运行环境;
- kubelet:在每个节点上运行的代理,保证容器都运行在Pod中;
- kube-proxy:每个节点上运行的网络代理, 维护节点上的网络规则;
Container-Runtime:容器运行时
负责运行容器的软件,支持Docker、containerd、CRI-O等多个容器运行环境,以及任何实现Kubernetes-CRI容器运行环境接口;
2、分层结构
从整体的功能上来考虑,K8S集群可以分为:用户、控制平面、节点三个模块;

用户侧:不论是CLI命令行还是UI界面,会与控制面板的APIserver进行交互,APIserver再与其他组件交互,最终执行相应的操作命令;
控制平面:以前也称为Master,核心组件包括APIserver、controller、scheduler、etcd,主要用来调度整个集群,以及做出全局决策;
节点:通过将容器放入在节点上运行的Pod中来执行工作负载,简单的理解工作负载就是各种应用程序等,节点上的核心组件包括Pod、kubelet、Container-Runtime、kube-proxy等;
3、核心能力
站在研发的视角来看,K8S提供极其强大的应用服务管理能力;
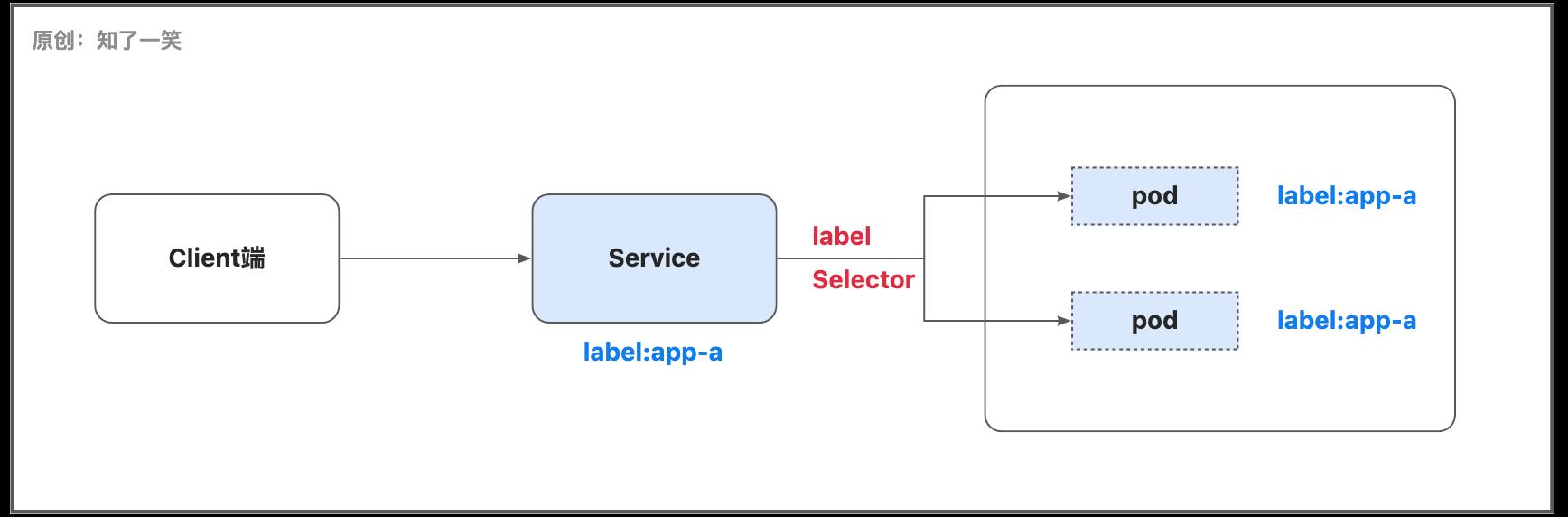
3.1 发现与负载
服务Service可以将运行在一个或一组Pod上的网络应用程序公开为网络服务的方法,通常使用标签对资源对象进行筛选过滤;
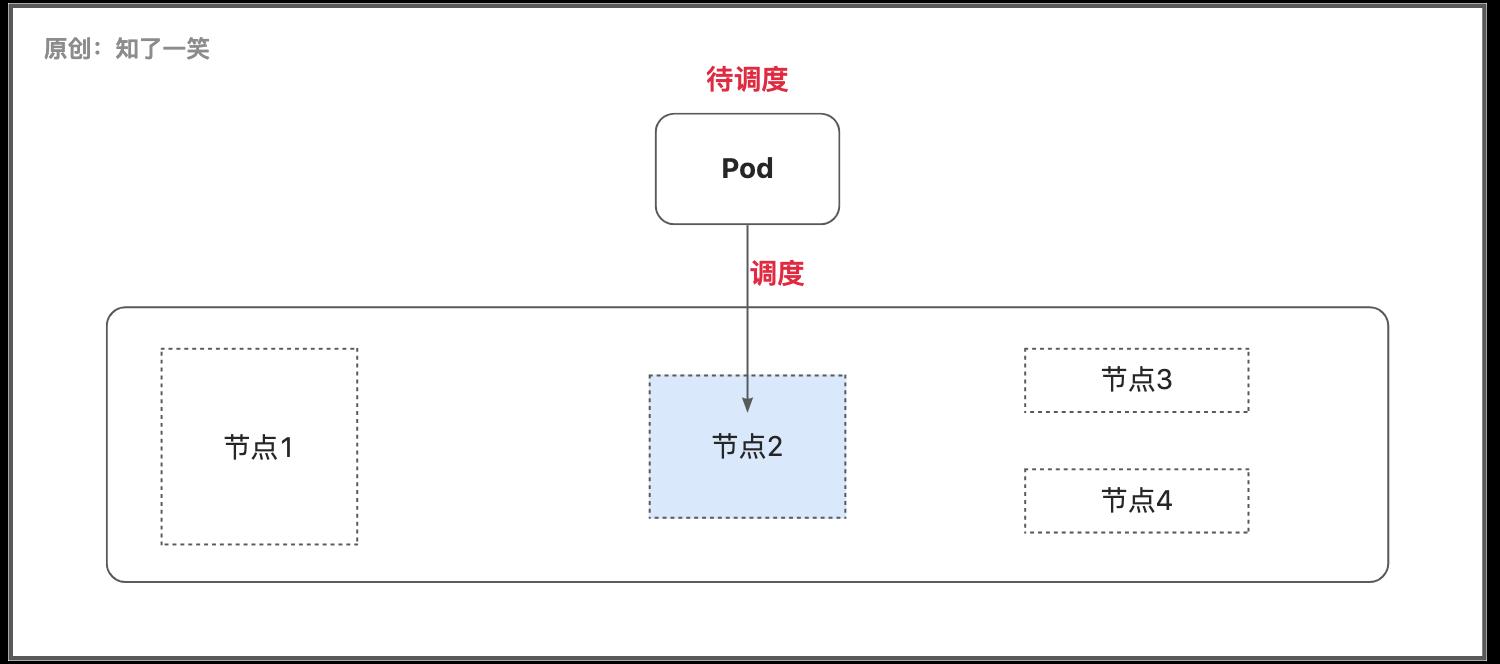
3.2 调度
调度器通过监测机制来发现集群中新创建且尚未被调度到节点上的Pod,由于Pod中的容器和Pod本身可能有不同的资源要求,调度会将Pod放置到合适的节点上;
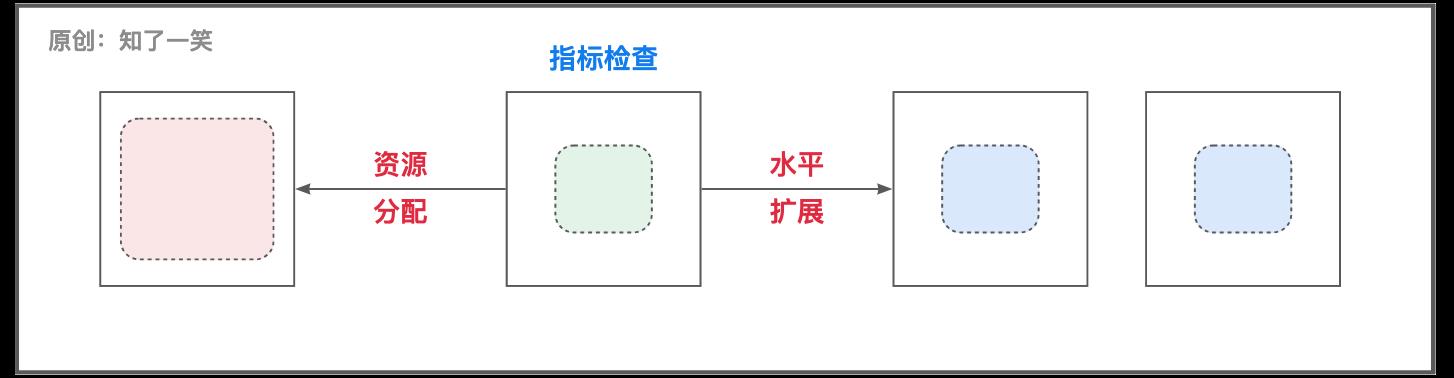
3.3 自动伸缩
K8S可以通过指标检查工作负载的资源需求,例如CPU利用率、响应时长、内存利用率、或者其他,从而判断是否需要执行伸缩,垂直维度可以是更多的资源分配,水平维度可以是更多的集群部署;
K8S可以自动伸缩,也具备自动修复的能力,当节点故障或者应用服务异常时,会被检查到,可能会进行节点迁移或者重启;
四、应用案例
1、服务部署
在此前的实践案例中,用CLI命令行和脚本文件的方式,完成的部署动作,而在整个流程中涉及集群的多个组件协作,多次的通信和调度;
kubectl create -f pod.yaml

2、交互流程
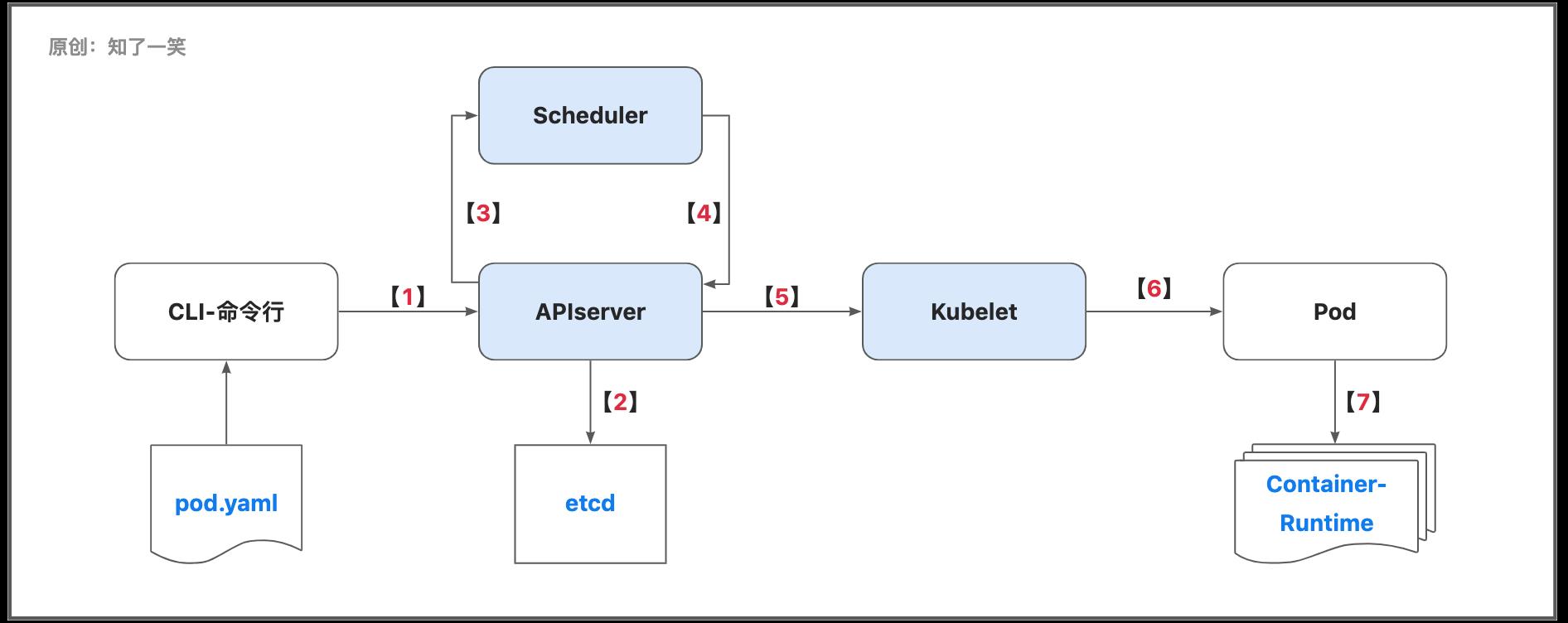
【1】CLI命令行和UI界面,都是通过APIserver接口,与集群内部组件交互,比如上述的Pod部署操作;
【2】在APIserver收到请求之后,会将序列化状态的对象写入到etcd中完成存储操作;
【3】Scheduler调度器通过监测(Watch)机制来发现集群中新创建且尚未被调度到节点上的Pod;
【4】在集群中找到一个Pod的所有可调度节点,对这些可调度节点打分,选出其中得分最高的节点来运行Pod,然后调度器将这个调度决定通知给APIserver;
【5】APIserver完成信息存储后,然后通知相应节点的Kubelet;
【6】Kubelet是基于PodSpec来工作的,确保这些PodSpec中描述的容器处于运行状态且运行状况良好,每个PodSpec是一个描述Pod的YAML或JSON对象;
【7】Pod是可以在Kubernetes中创建和管理的、最小的可部署的计算单元,包括一个或多个容器;
五、参考源码
文档仓库:
https://gitee.com/cicadasmile/butte-java-note
脚本仓库:
https://gitee.com/cicadasmile/butte-auto-parent
(转)使用K-S检验一个数列是否服从正态分布两个数列是否服从相同的分布
假设检验的基本思想:
若对总体的某个假设是真实的,那么不利于或者不能支持这一假设的事件A在一次试验中是几乎不可能发生的。如果事件A真的发生了,则有理由怀疑这一假设的真实性,从而拒绝该假设。
实质分析:
假设检验实质上是对原假设是否正确进行检验,因此检验过程中要使原假设得到维护,使之不轻易被拒绝;否定原假设必须有充分的理由。同时,当原假设被接受时,也只能认为否定该假设的根据不充分,而不是认为它绝对正确。
1、检验指定的数列是否服从正态分布
借助假设检验的思想,利用K-S检验可以对数列的性质进行检验,看代码:
|
1
2
3
4
5
6
7
|
from scipy.stats import kstestimport numpy as npx = np.random.normal(0,1,1000)test_stat = kstest(x, ‘norm‘)#>>> test_stat#(0.021080234718821145, 0.76584491300591395) |
首先生成1000个服从N(0,1)标准正态分布的随机数,在使用k-s检验该数据是否服从正态分布,提出假设:x从正态分布。
最终返回的结果,p-value=0.76584491300591395,比指定的显著水平(假设为5%)大,则我们不能拒绝假设:x服从正态分布。
这并不是说x服从正态分布一定是正确的,而是说没有充分的证据证明x不服从正态分布。因此我们的假设被接受,认为x服从正态分布。
如果p-value小于我们指定的显著性水平,则我们可以肯定的拒绝提出的假设,认为x肯定不服从正态分布,这个拒绝是绝对正确的。
2、检验指定的两个数列是否服从相同分布
|
1
2
3
4
5
|
from scipy.stats import ks_2sampbeta=np.random.beta(7,5,1000)norm=np.random.normal(0,1,1000)ks_2samp(beta,norm)#>>>(0.60099999999999998, 4.7405805465370525e-159) |
我们先分别使用beta分布和normal分布产生两个样本大小为1000的数列,使用ks_2samp检验两个数列是否来自同一个样本,提出假设:beta和norm服从相同的分布。
最终返回的结果,p-value=4.7405805465370525e-159,比指定的显著水平(假设为5%)小,则我们完全可以拒绝假设:beta和norm不服从同一分布。