CMU15445 (Fall 2020) 之 Project#1
Posted 之一Yo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CMU15445 (Fall 2020) 之 Project#1相关的知识,希望对你有一定的参考价值。
前言
去年暑假完成了 CMU15-445 Fall 2019 的四个实验,分别对应下述博客:
- CMU15445 (Fall 2019) 之 Project#1 - Buffer Pool 详解
- CMU15445 (Fall 2019) 之 Project#2 - Hash Table 详解
- CMU15445 (Fall 2019) 之 Project#3 - Query Execution 详解
- CMU15445 (Fall 2019) 之 Project#4 - Logging & Recovery 详解
今年打算接着完成 Fall 2020 的四个实验,同时解读一下课程组写好的那一部分代码,比如数据存储和页面布局的代码,加深自己对数据库系统的理解。
环境搭建
在 GitHub 上新建一个私有仓库,命名为 CMU15445-Fall2020,然后将官方仓库克隆到本地:
git clone git@github.com:cmu-db/bustub.git ./cmu15445-fall2020
cd cmu15445-fall2020
目前官方的代码应该更新到 Fall2023 了,需要回滚到 Fall2020,并将代码传到自己的远程仓库:
git reset --hard 444765a
git remote rm origin
git remote add origin git@github.com:zhiyiYo/cmu15445-fall2020.git #添加自己仓库作为远程分支
git push -u origin main
实验环境为 Ubuntu20.04 虚拟机,所以执行下述代码安装依赖包:
sudo build_support/packages.sh
和去年一样,因为 googletest 仓库将 master 分支重命名为 main 了,所以需要将 build_support/gtest_CMakeLists.txt.in 的内容改为:
cmake_minimum_required(VERSION 3.8)
project(googletest-download NONE)
include(ExternalProject)
ExternalProject_Add(googletest
GIT_REPOSITORY git@github.com:google/googletest.git
GIT_TAG main
SOURCE_DIR "$CMAKE_BINARY_DIR/googletest-src"
BINARY_DIR "$CMAKE_BINARY_DIR/googletest-build"
CONFIGURE_COMMAND ""
BUILD_COMMAND ""
INSTALL_COMMAND ""
TEST_COMMAND ""
)
最后编译一下,如果编译成功就说明环境搭建完成:
mkdir build
cd build
cmake ..
make
缓存池
由于磁盘读写速度远慢于内存,所以数据库会在内存中开辟一块连续空间,用于存储最近访问的页,这块空间称为缓存池。执行引擎不会直接从磁盘读取页,而是向缓存池要。如果缓存池中没有想要的页,就会从磁盘读入到池中,然后返回给执行引擎。页内数据更新后也不会立即写入磁盘,而是打上了一个 Dirty 标志位并暂存在缓存池中,等到时机成熟再写入。
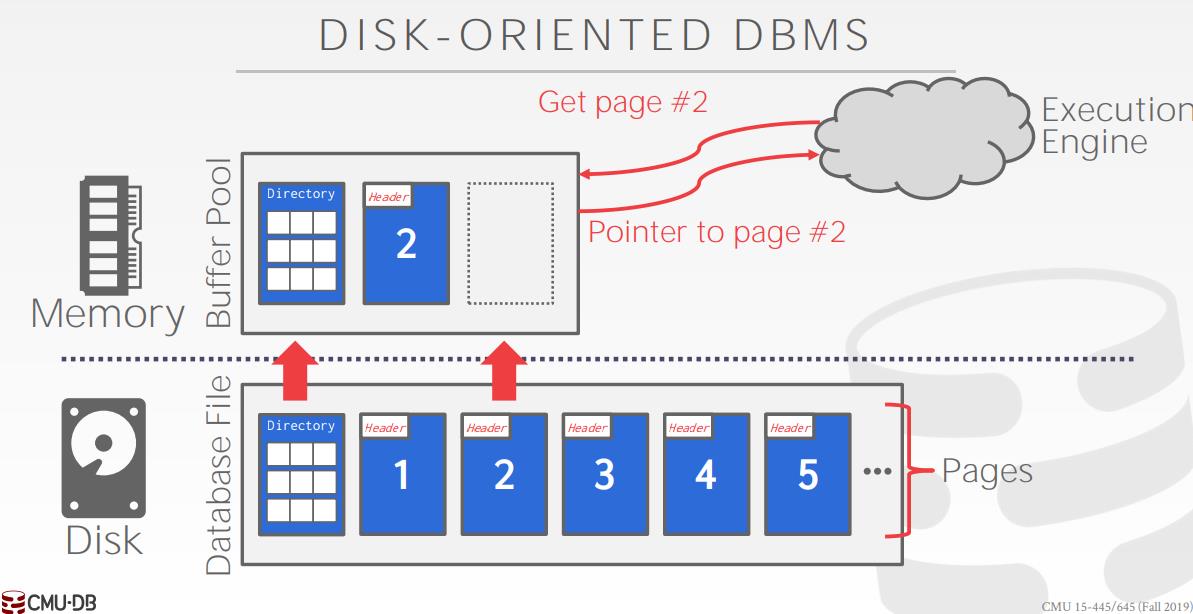
缓冲池的本质是一个数组,只能存一定数量的页。如果执行引擎想要的 Page 不在缓存池中,且缓存池已满,这时候需要从中踢出一个页来腾出空间给新 Page,被踢出的 Dirty 页需要被保存到磁盘中来保证数据一致性。需要指出的是,不是任何 Page 都能被换出,那些正在被使用的页不能换出,而判断一个页是否正被使用的依据是 Page 内部保存的 Pin/Reference 计数器,只要计数器的值大于 0,就说明至少有一个线程在使用它。
缓冲池内部维护着一个 page_id 到 frame_id 的映射表,用来指出页和内部数组索引的映射关系。同时内部还有一个互斥锁来保证并发安全,对缓存池的增删改查都需要上锁。

实验要求
任务 1:LRU Replacement Policy
Fall2019 要求实现的是时钟替换算法,而 Fall2020 则改成了 LRU 替换算法,实现方式一般使用双向链表 + 哈希表,C艹 可以直接用标准库中的 std::list 和 std::unordered_map。双向链表中存放允许被换出的 frame_id,哈希表中存 frame_id 及其对应的双向链表迭代器,这样可以实现 \\(O(1)\\) 复杂度的读写。链表的表头处存放最近访问的 frame_id,而尾处则是距离上次访问时间最远的的 frame_id。
class LRUReplacer : public Replacer
public:
/**
* Create a new LRUReplacer.
* @param num_pages the maximum number of pages the LRUReplacer will be required to store
*/
explicit LRUReplacer(size_t num_pages);
~LRUReplacer() override;
/**
* Remove the victim frame as defined by the replacement policy.
* @param[out] frame_id id of frame that was removed, nullptr if no victim was found
* @return true if a victim frame was found, false otherwise
*/
bool Victim(frame_id_t *frame_id) override;
/**
* Pins a frame, indicating that it should not be victimized until it is unpinned.
* @param frame_id the id of the frame to pin
*/
void Pin(frame_id_t frame_id) override;
/**
* Unpins a frame, indicating that it can now be victimized.
* @param frame_id the id of the frame to unpin
*/
void Unpin(frame_id_t frame_id) override;
/** @return the number of elements in the replacer that can be victimized */
size_t Size() override;
private:
size_t num_pages_;
std::list<frame_id_t> list_;
std::unordered_map<frame_id_t, std::list<frame_id_t>::iterator> map_;
std::shared_mutex mutex_;
;
具体实现如下所示,可以看到 LRUReplacer 对缓冲池中存了多少页以及存了哪些页是一无所知的,它只关心能被换出的 frame_id,外界通过调用 LURReplacer::Unpin() 添加一个能被换出的 frame_id,调用 LRUReplacer::Pin() 来移除一个 frame_id:
LRUReplacer::LRUReplacer(size_t num_pages) : num_pages_(num_pages)
LRUReplacer::~LRUReplacer() = default;
bool LRUReplacer::Victim(frame_id_t *frame_id)
lock_guard<shared_mutex> lock(mutex_);
if (Size() == 0)
return false;
*frame_id = list_.back();
list_.pop_back();
map_.erase(*frame_id);
return true;
void LRUReplacer::Pin(frame_id_t frame_id)
lock_guard<shared_mutex> lock(mutex_);
// frame 需要在缓冲池中
if (!map_.count(frame_id))
return;
auto it = map_[frame_id];
map_.erase(frame_id);
list_.erase(it);
void LRUReplacer::Unpin(frame_id_t frame_id)
lock_guard<shared_mutex> lock(mutex_);
// 缓冲池满了不能插入新的 page,不能重复插入 page
if (Size() == num_pages_ || map_.count(frame_id))
return;
list_.push_front(frame_id);
map_[frame_id] = list_.begin();
size_t LRUReplacer::Size()
return list_.size();
在终端输入命令:
mkdir build
cd build
cmake ..
make lru_replacer_test
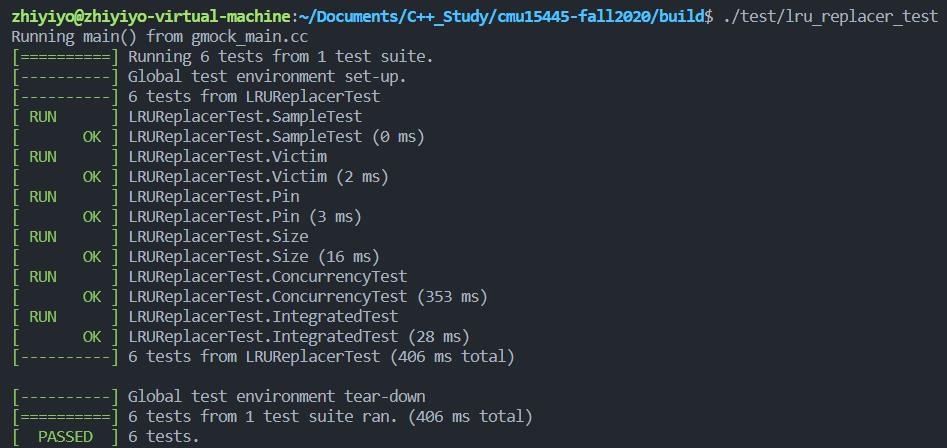
./test/lru_replacer_test
测试结果如下:
任务2:Buffer Pool Manager
BufferPoolManager 用于管理缓冲池,内部有一个 DiskManager 来读写磁盘数据,LRUReplacer 执行替换算法。这个类要求我们实现五个函数:
FetchPageImpl(page_id)NewPageImpl(page_id)UnpinPageImpl(page_id, is_dirty)FlushPageImpl(page_id)DeletePageImpl(page_id)FlushAllPagesImpl()
下面会一个个实现上述函数。
FetchPageImpl(page_id)
该函数实现了缓冲池的主要功能:向上层提供指定的 page。缓冲池管理器首先在 page_table_ 中查找 page_id 键是否存在:
- 如果存在就根据
page_id对应的frame_id从缓冲池pages_取出page - 如果不存在就通过
GetVictimFrameId()函数选择被换出的帧,该函数首先从free_list_中查找缓冲池的空位,如果没找到空位就得靠上一节实现的LRUReplacer选出被换出的冤大头
具体代码如下:
Page *BufferPoolManager::FetchPageImpl(page_id_t page_id)
lock_guard<mutex> lock(latch_);
// 1. Search the page table for the requested page (P).
Page *page;
auto it = page_table_.find(page_id);
// 1.1 If P exists, pin it and return it immediately.
if (it != page_table_.end())
auto frame_id = it->second;
page = &pages_[frame_id];
replacer_->Pin(frame_id);
page->pin_count_++;
return page;
// 1.2 If P does not exist, find a replacement page (R) from either the free list or the replacer.
// Note that pages are always found from the free list first.
auto frame_id = GetVictimFrameId();
if (frame_id == INVALID_PAGE_ID)
return nullptr;
// 2. If R is dirty, write it back to the disk.
page = &pages_[frame_id];
if (page->IsDirty())
disk_manager_->WritePage(page->page_id_, page->data_);
// 3. Delete R from the page table and insert P.
page_table_.erase(page->page_id_);
page_table_[page_id] = frame_id;
// 4. Update P\'s metadata, read in the page content from disk, and then return a pointer to P.
disk_manager_->ReadPage(page_id, page->data_);
page->update(page_id, 1, false);
replacer_->Pin(frame_id);
return page;
frame_id_t BufferPoolManager::GetVictimFrameId()
frame_id_t frame_id = INVALID_PAGE_ID;
if (!free_list_.empty())
frame_id = free_list_.front();
free_list_.pop_front();
else
replacer_->Victim(&frame_id);
return frame_id;
上述代码中还用了一个 Page::update 辅助函数,用于更新 page 的元数据:
/**
* update the meta data of page
* @param page_id the page id
* @param pin_count the pin count
* @param is_dirty is page dirty
* @param reset_memory whether to reset the memory of page
*/
void update(page_id_t page_id, int pin_count, bool is_dirty, bool reset_memory = false)
page_id_ = page_id;
pin_count_ = pin_count;
is_dirty_ = is_dirty;
if (reset_memory)
ResetMemory();
NewPageImpl(page_id)
该函数在缓冲池中插入一个新页,如果缓冲池中的所有页面都正在被线程访问,插入失败,否则靠 GetVictimFrameId() 计算插入位置:
Page *BufferPoolManager::NewPageImpl(page_id_t *page_id)
// 0. Make sure you call DiskManager::AllocatePage!
lock_guard<mutex> lock(latch_);
// 1. If all the pages in the buffer pool are pinned, return nullptr.
auto frame_id = GetVictimFrameId();
if (frame_id == INVALID_PAGE_ID)
return nullptr;
// 2. Pick a victim page P from either the free list or the replacer. Always pick from the free list first.
auto page = &pages_[frame_id];
if (page->IsDirty())
disk_manager_->WritePage(page->page_id_, page->data_);
// 3. Update P\'s metadata, zero out memory and add P to the page table.
*page_id = disk_manager_->AllocatePage();
page_table_.erase(page->page_id_);
page_table_[*page_id] = frame_id;
page->update(*page_id, 1, false, true);
replacer_->Pin(frame_id);
// 4. Set the page ID output parameter. Return a pointer to P.
return page;
DeletePageImpl(page_id)
该函数从缓冲池和数据库文件中删除一个 page,并将其 page_id 设置为 INVALID_PAGE_ID:
bool BufferPoolManager::DeletePageImpl(page_id_t page_id)
// 0. Make sure you call DiskManager::DeallocatePage!
lock_guard<mutex> lock(latch_);
// 1. Search the page table for the requested page (P).
// 1. If P does not exist, return true.
auto it = page_table_.find(page_id);
if (it == page_table_.end())
return true;
// 2. If P exists, but has a non-zero pin-count, return false. Someone is using the page.
auto frame_id = it->second;
auto &page = pages_[frame_id];
if (page.pin_count_ > 0)
return false;
// 3. Otherwise, P can be deleted. Remove P from the page table, reset its metadata and return it to the free list.
disk_manager_->DeallocatePage(page_id);
page_table_.erase(page.page_id_);
free_list_.push_back(frame_id);
page.update(INVALID_PAGE_ID, 0, false);
return true;
UnpinPageImpl(page_id, is_dirty)
该函数用以减少对某个页的引用数 pin count,当 pin_count 为 0 时需要将其添加到 LRUReplacer 中:
bool BufferPoolManager::UnpinPageImpl(page_id_t page_id, bool is_dirty)
lock_guard<mutex> lock(latch_);
auto it = page_table_.find(page_id);
if (it == page_table_.end())
return false;
auto frame_id = it->second;
auto &page = pages_[frame_id];
if (page.pin_count_ <= 0)
return false;
page.is_dirty_ |= is_dirty;
if (--page.pin_count_ == 0)
replacer_->Unpin(frame_id);
return true;
FlushPageImpl(page_id)
该函数将缓冲池中的页写入磁盘以保持同步,这里不管页是否为脏,一律写入磁盘,不然并发的测试用例过不了:
bool BufferPoolManager::FlushPageImpl(page_id_t page_id)
// Make sure you call DiskManager::WritePage!
lock_guard<mutex> lock(latch_);
auto it = page_table_.find(page_id);
if (it == page_table_.end())
return false;
auto &page = pages_[it->second];
disk_manager_->WritePage(page_id, page.data_);
page.is_dirty_ = false;
return true;
FlushAllPagesImpl()
该函数将缓冲池中的所有 page 写入磁盘:
void BufferPoolManager::FlushAllPagesImpl()
lock_guard<mutex> lock(latch_);
for (auto &[page_id, frame_id] : page_table_)
auto &page = pages_[frame_id];
if (page.IsDirty())
disk_manager_->WritePage(page_id, page.data_);
page.is_dirty_ = false;
测试
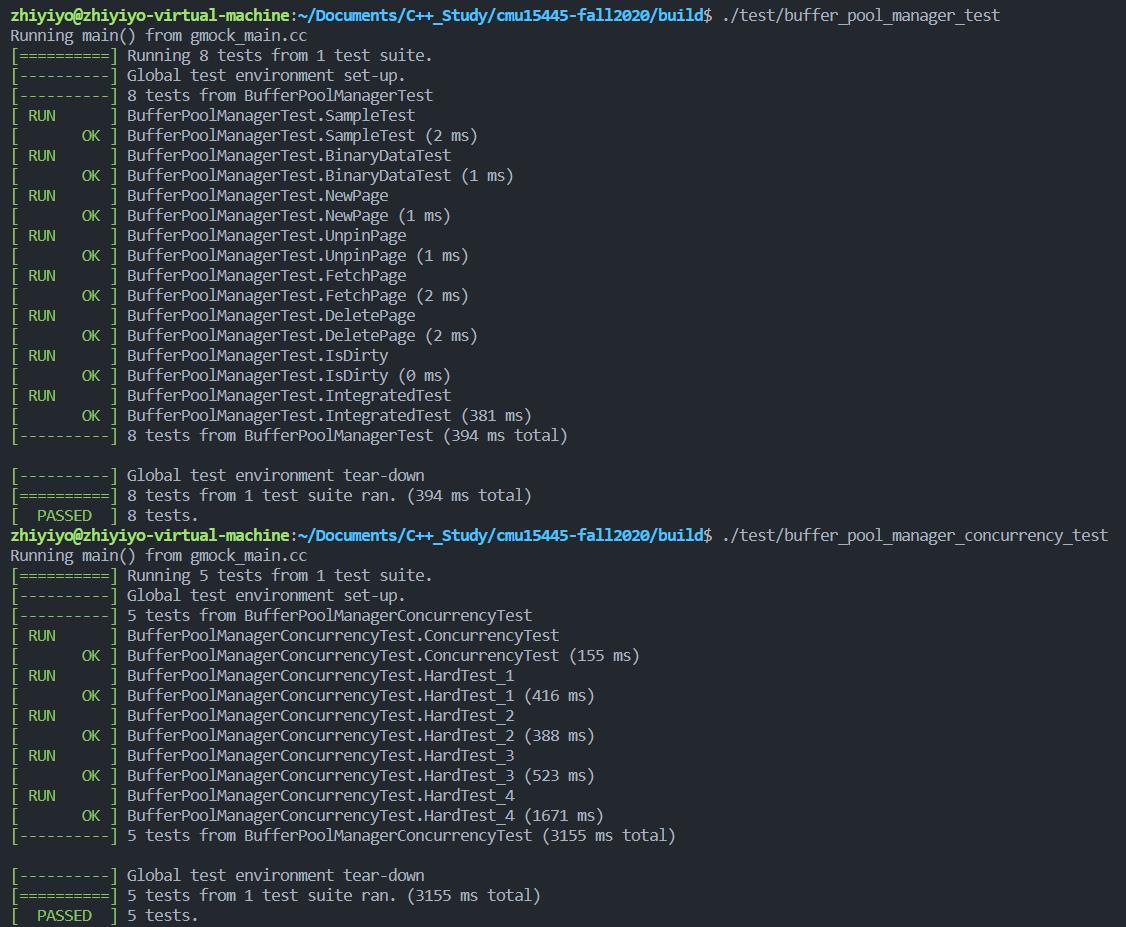
在终端输入指令:
cd build
make buffer_pool_manager_test
./test/buffer_pool_manager_test
# 下面是从 gradescope 扒下来的测试用例
make buffer_pool_manager_concurrency_test
./test/buffer_pool_manager_concurrency_test
测试结果如下:
总结
这个实验主要考察学生对并发和 STL 的掌握程度,由于注释中列出了实现步骤(最搞的是 You can do it! 注释),所以代码写起来也比较顺畅,以上~~
CMU15-445 Lecture #05 Buffer Pools
课程链接:15-445/645 Database Systems (Fall 2020)
本文由 nefu-ljw 翻译于Notes:https://15445.courses.cs.cmu.edu/fall2020/notes/05-bufferpool.pdf
所有Notes已同步更新于我的github仓库:https://github.com/nefu-ljw/database-notes
文章目录
1. Introduction
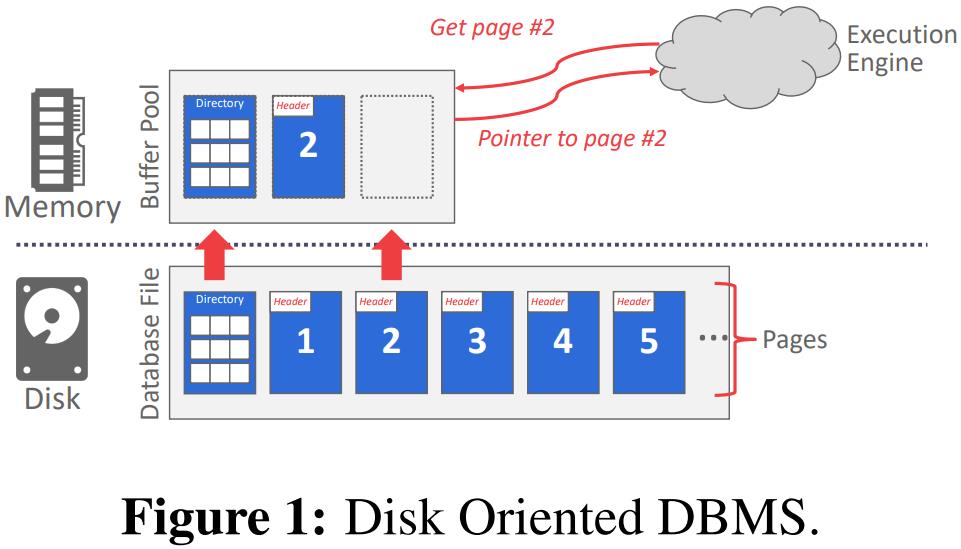
DBMS负责管理其内存以及从磁盘来回移动数据。因为在大多数情况下,数据不能直接在磁盘上操作,所以任何数据库都必须能够有效地将其磁盘上表示为文件的数据移动到内存中,以便可以使用。这种交互的图表如图1所示。DBMS面临的一个障碍是将移动数据的速度降至最低的问题。理想情况下,它应该“看起来”好像所有的数据都已经在内存中了。
考虑这个问题的另一种方式是从空间和时间控制的角度。
空间控制(Spatial Control)指的是在磁盘上物理写入页面的位置。空间控制的目标是使经常在一起使用的页面在物理上尽可能靠近磁盘。
时间控制(Temporal Control)指的是何时将页面读入内存以及何时将其写入磁盘。时间控制旨在最大限度地减少不得不从磁盘读取数据的停顿次数。
2. Locks vs. Latches
在讨论DBMS如何保护其内部元素时,我们需要区分锁(locks)和锁存器(latches)。
Locks: 锁是保护数据库(例如,元组、表、数据库)的内容不受其他事务影响的更高级别的逻辑原语。事务将在其整个持续时间内保持锁定。当运行查询时,数据库系统可以向用户暴露哪些锁被持有。锁需要能够回滚更改。
Latches: 锁存器是DBMS用于其内部数据结构(例如,哈希表、存储器区域)中的临界区的低级保护原语。仅在进行操作的持续时间内保持锁存。锁存器不需要能够回滚更改。
3. Buffer Pool
缓冲池是从磁盘读取的页面的内存缓存。它本质上是在数据库内部分配的一个大内存区域,用于存储从磁盘获取的页面。
缓冲池的内存区域,组织为固定大小的页面数组。每个数组条目都称为一帧(frame)。当DBMS请求页面时,会将一个完全相同的副本放入缓冲池的一帧中。然后,当请求页面时,数据库系统可以首先搜索缓冲池。如果找不到该页,则系统将从磁盘获取该页的副本。 有关缓冲池的内存组织图,请参见图2。
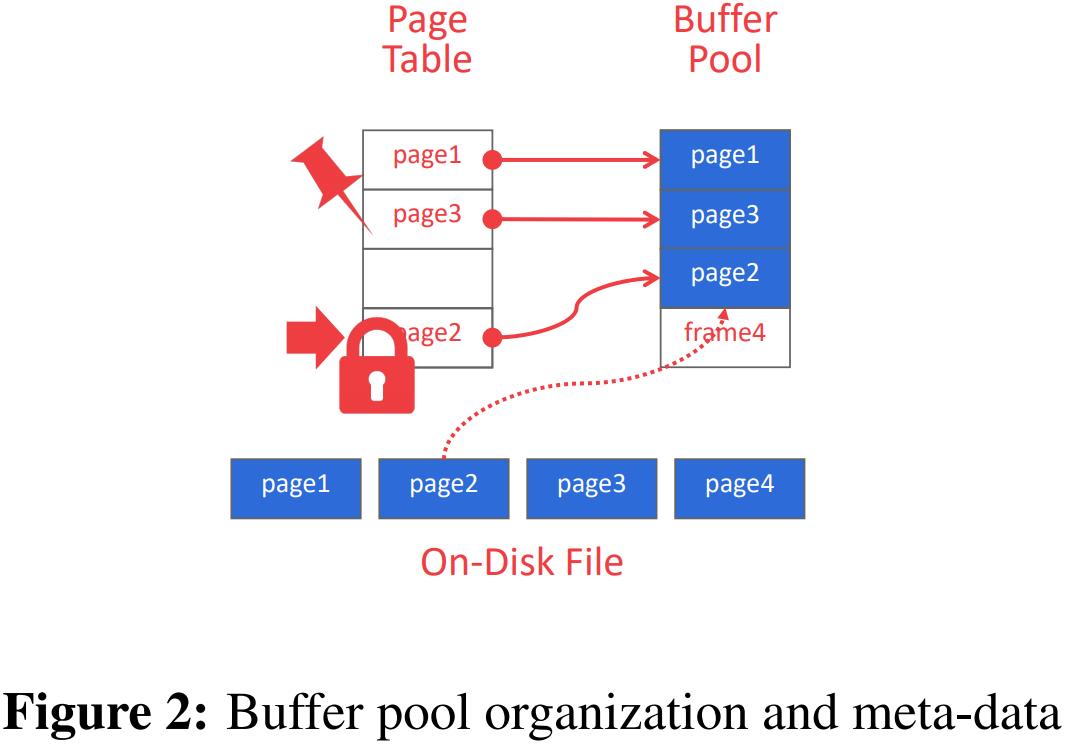
Buffer Pool Meta-data
缓冲池必须维护某些元数据才能有效和正确地使用。
首先,页表(page table)是内存中的哈希表,跟踪当前内存中的页面。页表将页面ID映射到缓冲池中的帧位置。 因为缓冲池中的页面顺序不一定反映磁盘上的顺序,所以这个额外的间接层允许标识缓冲池中的页面位置。请注意,不要将页表与页目录(page directory)混淆,页目录是从页面ID映射到数据库文件中的页位置。
页表还维护每页的附加元数据、脏标志和固定/引用计数器。
脏标志(dirty-flag)是由线程在修改页面时设置的。这向存储管理器指示该页必须写回磁盘。
固定/引用计数器(Pin/Reference Counter)跟踪当前正在访问该页面(读取或修改该页面)的线程数。线程在访问页面之前必须递增计数器。如果页面的计数大于零,则不允许存储管理器将该页面从内存中逐出。
Memory Allocation Policies
数据库中的内存根据两个策略分配给缓冲池。
全局策略(global policies)处理DBMS应该做出的决策,以使正在执行的整个工作负载受益。它会考虑所有活动事务,以找到分配内存的最佳决策。
另一种选择是本地策略(local policies)做出决策,使单个查询或事务运行得更快,即使这对整个工作负载不好。本地策略将帧分配给特定事务,而不考虑并发事务的行为。
大多数系统同时使用全局视角和本地视角。
4. Buffer Pool Optimizations
有许多方法可以优化缓冲池以使其适应应用程序的工作负载。
Multiple Buffer Pools
DBMS可以为不同的目的维护多个缓冲池(即每个数据库的缓冲池、每个页面类型的缓冲池)。然后,每个缓冲池都可以采用为其中存储的数据量身定做的本地策略。此方法有助于减少锁存争用并改善局部性。
将所需页面映射到缓冲池的两种方法是对象ID和散列。
对象ID(Object IDs)涉及扩展记录ID(record IDs)以包括有关每个缓冲池管理的数据库对象的元数据。然后,通过对象标识符,可以维护从对象到特定缓冲池的映射。
另一种方法是DBMS散列(hashing)页面ID以选择要访问的缓冲池。
Pre-fetching
DBMS还可以根据查询计划预取页面进行优化。然后,在处理第一组页面时,可以将第二组页面预取到缓冲池中。当数据库管理系统(DBMS)连续访问多个页面时,通常使用这种方法。
Scan Sharing
查询游标可以重用从存储或操作符计算中检索到的数据。这允许多个查询附加到一个扫描表的游标上。如果一个查询开始扫描,并且已经有另一个查询这么做过了,那么DBMS将附加到第二个查询的游标上。DBMS跟踪第二个查询与第一个查询的连接位置,以便在到达数据结构的末尾时完成扫描。
Buffer Pool Bypass
顺序扫描操作符不会将获取的页面存储在缓冲池中,以避免开销。相反,内存对于正在运行的查询是本地的。如果操作符需要读取磁盘上连续的大量页序列,则这种方法很有效。缓冲池旁路(Bypass)也可以用于临时数据(排序、连接)。
5. OS Page Cache
大多数磁盘操作都通过操作系统API进行。除非明确告知,否则操作系统维护自己的文件系统缓存。
大多数DBMS使用直接I/O来绕过(bypass)操作系统的缓存,以避免页面的冗余拷贝和不得不管理不同的驱逐策略。
Postgres是一个使用操作系统的页面缓存的数据库系统的例子。
6. Buffer Replacement Policies
当DBMS需要释放一个帧来为一个新页腾出空间时,它必须决定从缓冲池中驱逐哪个页。
替换策略是DBMS实现的一种算法,它可以在缓冲池需要空间时决定从缓冲池中驱逐哪些页面。
替换策略的实现目标是提高正确性、准确性、速度和(降低)元数据开销。
Least Recently Used (LRU)
最近最少使用的替换策略维护了每个页面最后访问时间的时间戳。这个时间戳可以存储在一个单独的数据结构中,比如一个队列,以便进行排序并提高效率。DBMS选择删除时间戳最旧的页面。此外,页面按照排序的顺序保持,以减少收回时的排序时间。
CLOCK
CLOCK策略近似于LRU,但不需要每个页面单独的时间戳。在CLOCK策略中,每页都有一个参考位。当访问页面时,设置为1。
为了直观地看到这一点,可以使用“时钟指针”将页面组织在一个循环缓冲区中。扫描时检查页面的位是否设置为1。如果是,设置为0,如果不是,驱逐它。这样,时钟指针就能记住两次驱逐之间的位置。
Alternatives
LRU和CLOCK策略存在许多问题。
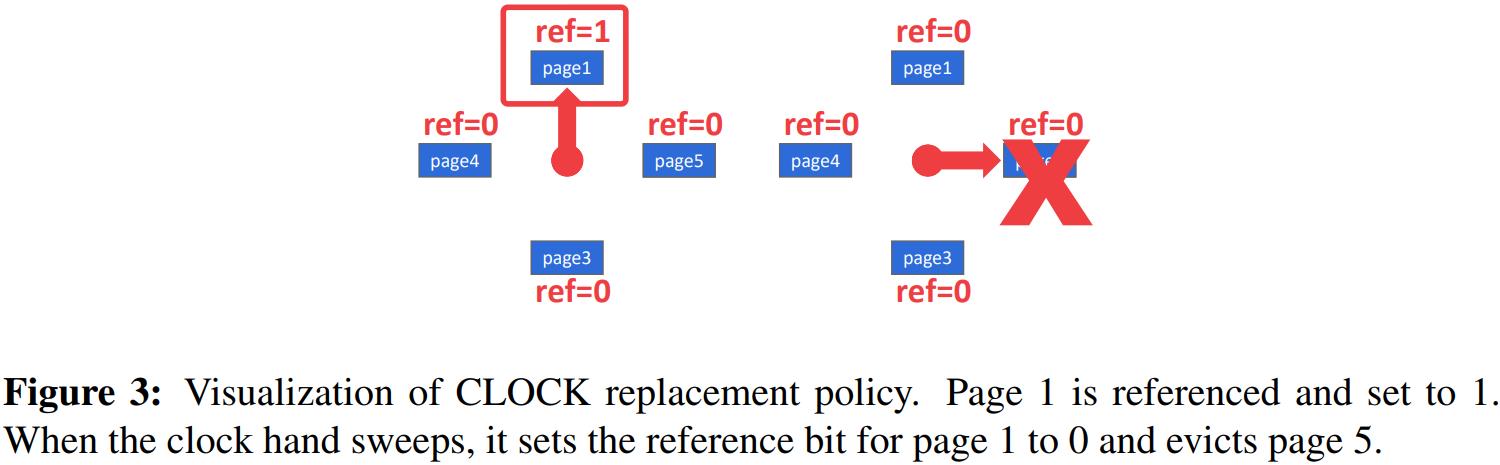
(图3:时钟替换策略的可视化。第1页被引用并设置为1。当时钟指针扫描时,它将第1页的参考位设置为0,并驱逐第5页)
也就是说,LRU和CLOCK很容易受到顺序泛洪(sequential flooding)的影响,即由于顺序扫描,缓冲池的内容被破坏。由于顺序扫描读取每一页,所读取的页的时间戳可能不能反映我们真正想要的页。换句话说,最近使用的页面实际上是最不需要的页面。
有三种解决方案可以解决LRU和CLOCK策略的缺点。
一种解决方案是LRU-K,它将最后K个引用的历史作为时间戳进行跟踪,并计算后续访问之间的间隔。此历史记录用于预测下一次访问页面的时间。
另一个优化是对每个查询进行本地化(localization)。DBMS根据每个事务/查询选择要逐出的页面。这最大限度地减少了每次查询对缓冲池的污染。
最后,优先级提示(priority hints),允许事务在查询执行期间根据每个页面的上下文告诉缓冲池页面是否重要。
Dirty Pages
有两种方法可以处理含有脏位的页面。最快的选择是删除缓冲池中任何不脏的页面。一种较慢的方法是将脏页写回磁盘,以确保将其更改持久化。
这两种方法说明了快速收回与将来不会再次读取的脏写入页之间的权衡。
一种避免不必要地写页面的方法是背景写入(background writing)。通过背景写入,DBMS可以定期遍历页表并将脏页写入磁盘。当安全写入脏页时,DBMS可以驱逐该页或只是取消脏标志的设置。
7. Other Memory Pools
除了元组和索引之外,DBMS还需要内存。根据实施情况,这些其他内存池可能并不总是由磁盘支持。
- Sorting + Join Buffers(排序+连接缓冲区)
- Query Caches(查询缓存)
- Maintenance Buffers(维护缓冲区)
- Log Buffers(日志缓冲区)
- Dictionary Caches(字典缓存)
以上是关于CMU15445 (Fall 2020) 之 Project#1的主要内容,如果未能解决你的问题,请参考以下文章