你没见过的分库分表原理解析和解决方案
Posted 薛家明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你没见过的分库分表原理解析和解决方案相关的知识,希望对你有一定的参考价值。
你没见过的分库分表原理解析和解决方案(一)
高并发三驾马车:分库分表、MQ、缓存。今天给大家带来的就是分库分表的干货解决方案,哪怕你不用我的框架也可以从中听到不一样的结局方案和实现。
一款支持自动分表分库的orm框架easy-query 帮助您解脱跨库带来的复杂业务代码,并且提供多种结局方案和自定义路由来实现比中间件更高性能的数据库访问。
上篇文章简单的带大家了解了框架如何使用分片本章将会以理论为主加实践的方式呈现不一样的分表分库。
介绍
分库分表一直是老生常谈的问题,市面上也有很多人侃侃而谈,但是大部分的说辞都是一样,甚至给不出一个实际的解决方案,本人经过多年的深耕在其他语言里面多年的维护和实践下来秉着happy coding的原则希望更多的人可以了解和认识到该框架并且给大家一个全新的针对分库分表的认识。
我们也经常戏称项目一开始就用了分库分表结果上线没多少数据,并且整个开发体验来说非常繁琐,对于业务而言也是极其不友好,大大拉长开发周期不说,bug也是更加容易产生,针对上述问题该框架给出了一个非常完美的实现来极大程度上的给用户完美的体验
分片存储
分库分表简单的实现目前大部分框架已经都可以实现了,就是动态表名来实现分表下的简单存储,如果是分库下面的那么就使用动态数据源来切换实现,如果是分库加分表就用动态数据源加动态表名来实现,听上去是不是很完美,但是实际情况下你需要表写非常繁多的业务代码,并且会让整个开发精力全部集中在分库分表下,针对后期的维护也是非常麻烦的一件事。
但是分库分表的分片规则又是和具体业务耦合的所以合理的解耦分片路由是一件非常重要的事情。
插入
假设我们按订单id进行分表存储
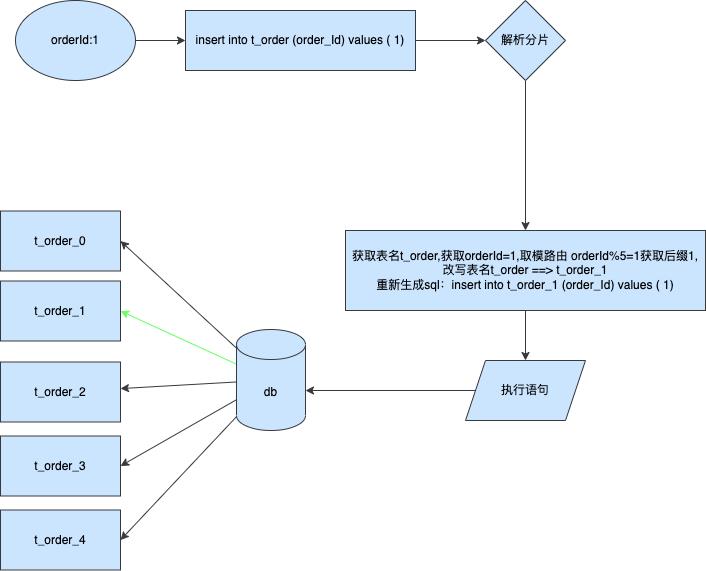
通过上述图片我们可以很清晰的了解到分片插入的执行原理,通过拦截执行sql分析对应的值计算出所属表名,然后改写表名进行插入。该实现方法有一个弊端就是如果插入数据是increment的自增类型,那么这种方法将不适合,因为自增主键只有在插入数据库后才会正真的被确定是什么值,可以通过拦截器设置自定义自增拨号器来实现伪自增,这样也可以实现“自增”列。
更新删除)
这边假设我们也是按照订单id进行分表更新
更新分片键
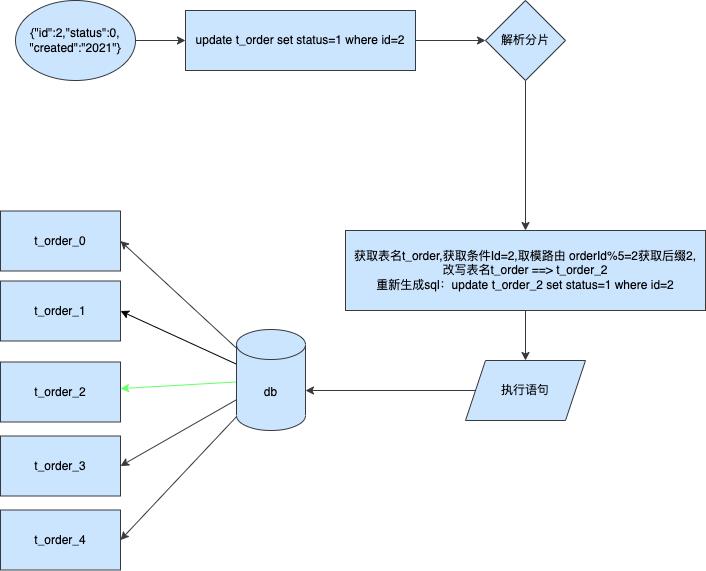
一模一样的处理,将sql进行拦截后解析where和分片字段id然后计算后将结果发送到对应路由的表中进行执行。
那么如果我们没办法进行路由确定呢,如果我们使用created字段来更新的那么会发生生呢
更新非分片键
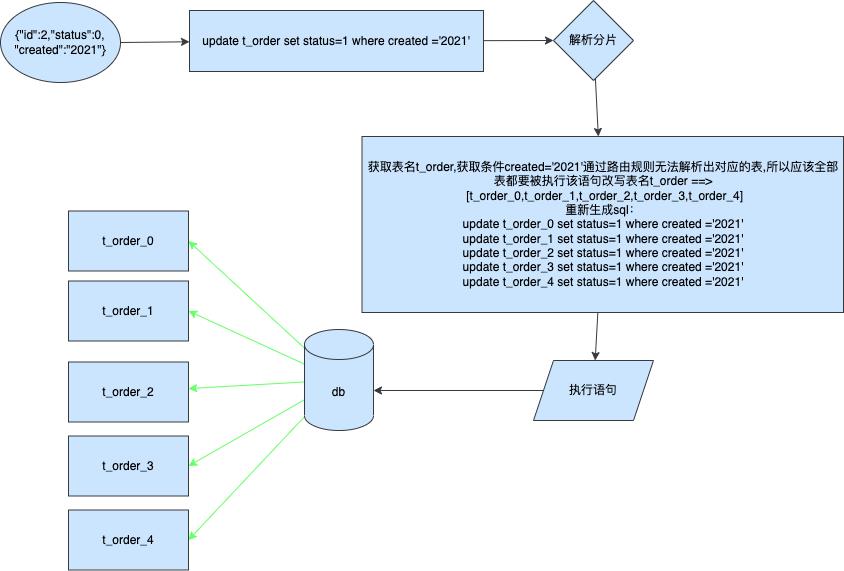
为了得到正确的结果需要将每条sql进行改写分别发送到对应的表中,然后将各自表的执行结果进行聚合返回最终受影响行数
分片查询
众所周知分库分表的难点并不在如何存储数据到对应的db,也不在于如何更新指定实体数据,因为他们都可以通过分片键的计算来重新路由,可以让分片的操作降为单表操作,所以orm只需要支持动态表名那么以上所有功能都是支持的,
但是实际情况缺是如果orm或者中间件只支持到了这个级别那么对于稍微复杂一点的业务你必须要编写大量的业务代码来实现业务需要的查询,并且会浪费大量的重复工作和精力
单分片表查询
加下来我来讲解单分片表查询,其实原理和上面的insert一样
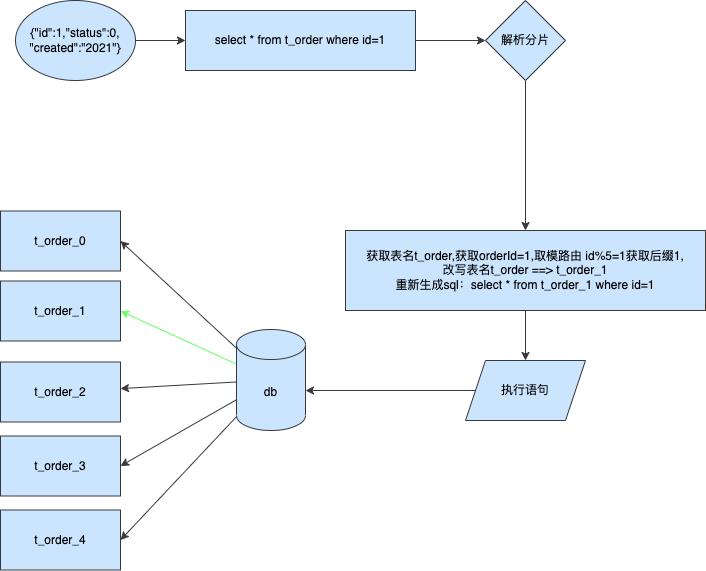
到这里为止其实都是ok的并没有什么问题.但是如果我们的本次查询需要跨分片呢比如跨两个分片那么应该如何处理
跨分片表查询
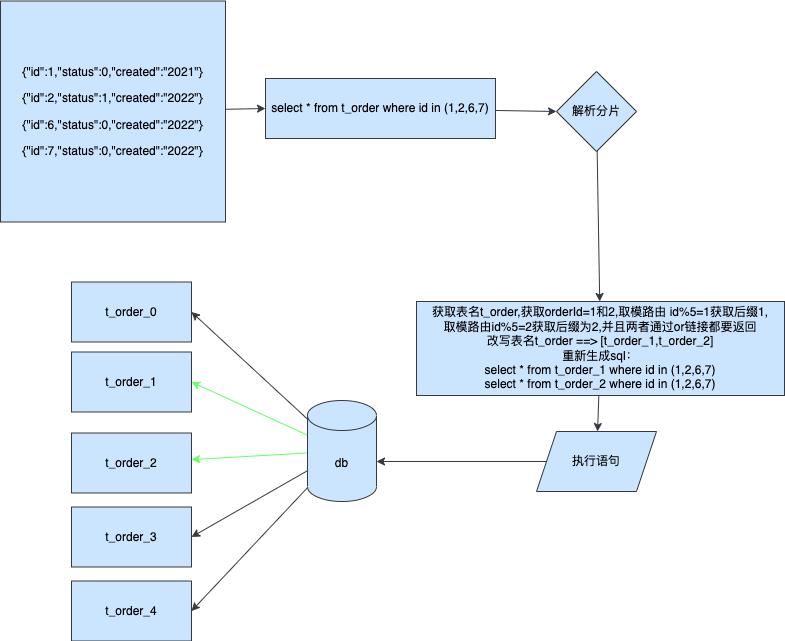
到这一步我们已经将对应的数据路由到对应的数据库了,那么我们应该如何获取自己想要的结果呢
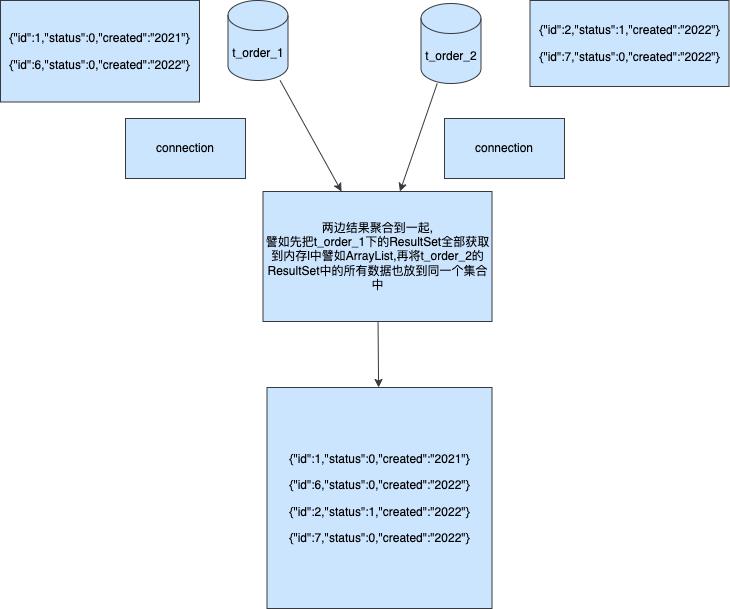
通过上图我们可以了解到在跨分片的聚合下我们可以分表通过对a,b两张表进行查询可以并行可以串行,最终将结果汇聚到同一个集合那么返回给用户端就是一个完整的数据包,并没有缺少任何数据
跨分片排序
基于上述分片聚合方式我们清晰的了解到如何可以进行跨分片下降数据获取到内存中,但是通过图中结果可以清晰的了解到返回的数据并不像我们预期的那样有序,那是因为各个节点下的所有数据都是仅遵循各自节点的数据库排序而不受其他节点分片影响。
那么如果我们对数据进行分片聚合+排序那么又会是什么样的场景呢
方案一内存排序
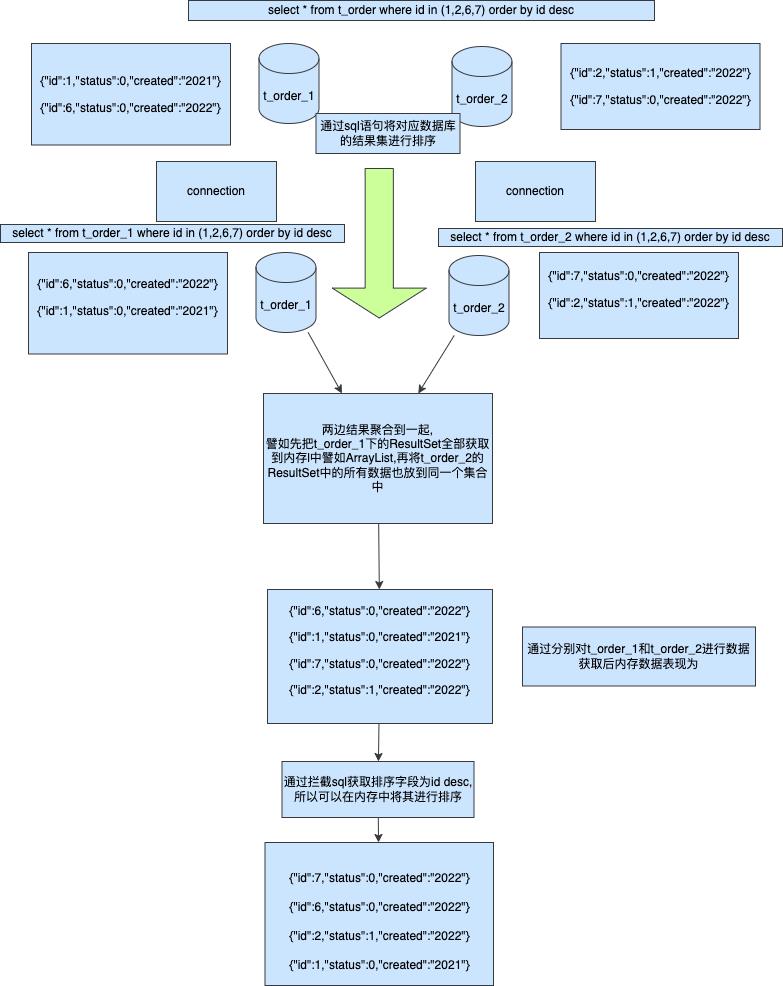
首先我们将执行sql分别路由到t_order_1和t_order_2两张表,并且执行order by id desc将其数据id大的排在前面这样可以保证单个Connection的ResultSet肯定是大的先被返回
所以在单个Connection下结果是正确的但是因为多个分片节点间没有交互所以当取到内存中后数据依然是乱的,所以这边需要对sql进行拦截获取排序字段并且将其在内存中的集合里面实现,这样我们就做到了和排序字段一样的返回结果
方案二流式排序
大部分orm到这边就为止了,毕竟已经实现了完美的节点处理,但是我们来看他需要消耗的性能事多少,假设我们分片命中2个节点,每个节点各自返回2条数据,我们对于整个ResultSet的遍历将是每个链接都是2那么就是4次,然后在内存中在进行排序如果性能差一点还需要多次所以这个是相对比较浪费性能的,因为如果我们有1000条数据返回那么内存中的排序是很高效的但是这个也是我们这次需要讲解的更加高效的排序处理流式排序
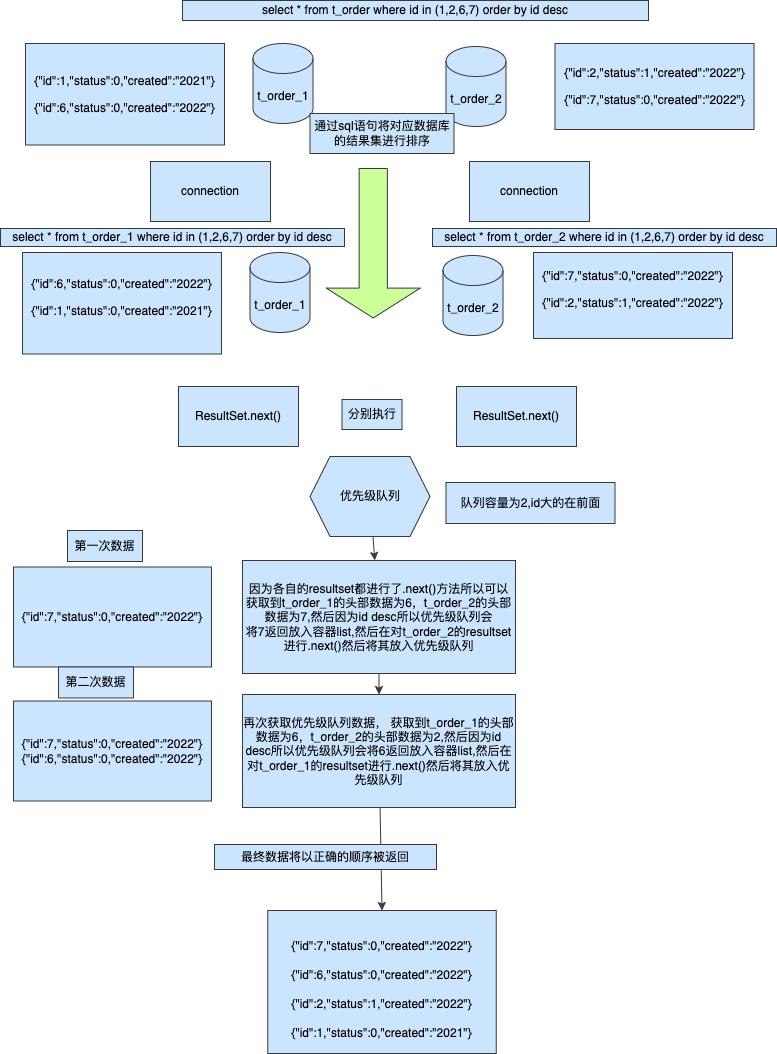
相较于内存排序这种方式十分复杂并且繁琐,而且对于用户也很不好理解,但是如果你获取的数据是分页,那么内存排序进行获取结果将会变得非常危险,有可能导致内存数据过大从而导致程序崩溃
无order字段
到这边不要以为跨分片聚合已经结束了因为当你的sql查询order by了一个select不存在的字段,那么上述两种排序方式都将无法使用,因为程序获取到的结果集并没有排序字段,这个时候一般我们会改写sql让其select的时候必须要带上对应的order by字段这样就可以保证我们数据的正确返回
以下两个问题因为涉及到过多内容本章节无法呈现所以将会在下一章给出具体解决方案
跨分片分组
如果我们程序遇到了这个那么我们该如何处理呢
跨分片分页
业务中常常需要的跨分片分页我们该如何解决,easy-query又如何处理这种情况,如果跨的分片过多我们又该怎么办,
- 如何解决深分页问题
- 如何解决流式瀑布问题
- 如何进行分页缓存高效获取问题
接下来将在下篇文章中一一解答近
最后
我这边将演示easy-query在本次分片理论中的实际应用
这次采用h2数据库作为演示
CREATE TABLE IF NOT EXISTS `t_order_0`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS `t_order_1`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS `t_order_2`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS `t_order_3`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS `t_order_4`
(
`id` INTEGER PRIMARY KEY,
`status` Integer,
`created` VARCHAR(100)
);
安装maven依赖
<dependency>
<groupId>com.easy-query</groupId>
<artifactId>sql-h2</artifactId>
<version>0.9.32</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.easy-query</groupId>
<artifactId>sql-api4j</artifactId>
<version>0.9.32</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.199</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>$spring.version</version>
</dependency>
创建实体对象对应数据库
@Data
@Table(value = "t_order",shardingInitializer = H2OrderShardingInitializer.class)
public class H2Order
@Column(primaryKey = true)
@ShardingTableKey
private Integer id;
private Integer status;
private String created;
// 分片初始化器
public class H2OrderShardingInitializer extends AbstractShardingTableModInitializer<H2Order>
@Override
protected int mod()
return 5;//模5
@Override
protected int tailLength()
return 1;//表后缀长度1位
//分片路由规则
public class H2OrderRule extends AbstractModTableRule<H2Order>
@Override
protected int mod()
return 5;
@Override
protected int tailLength()
return 1;
创建datasource和easyquery
orderShardingDataSource=DataSourceFactory.getDataSource("dsorder","h2-dsorder.sql");
EasyQueryClient easyQueryClientOrder = EasyQueryBootstrapper.defaultBuilderConfiguration()
.setDefaultDataSource(orderShardingDataSource)
.optionConfigure(op ->
op.setMaxShardingQueryLimit(10);
op.setDefaultDataSourceName("ds2020");
op.setDefaultDataSourceMergePoolSize(20);
)
.build();
EasyQuery easyQueryOrder = new DefaultEasyQuery(easyQueryClientOrder);
QueryRuntimeContext runtimeContext = easyQueryOrder.getRuntimeContext();
QueryConfiguration queryConfiguration = runtimeContext.getQueryConfiguration();
queryConfiguration.applyShardingInitializer(new H2OrderShardingInitializer());//添加分片初始化器
TableRouteManager tableRouteManager = runtimeContext.getTableRouteManager();
tableRouteManager.addRouteRule(new H2OrderRule());//添加分片路由规则
插入代码
ArrayList<H2Order> h2Orders = new ArrayList<>();
for (int i = 0; i < 100; i++)
H2Order h2Order = new H2Order();
h2Order.setId(i);
h2Order.setStatus(i%3);
h2Order.setCreated(String.valueOf(i));
h2Orders.add(h2Order);
easyQueryOrder.insertable(h2Orders).executeRows();
==> main, name:ds2020, Preparing: INSERT INTO t_order_3 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 0(Integer),0(Integer),0(String)
<== main, name:ds2020, Total: 1
==> main, name:ds2020, Preparing: INSERT INTO t_order_4 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 1(Integer),1(Integer),1(String)
<== main, name:ds2020, Total: 1
==> main, name:ds2020, Preparing: INSERT INTO t_order_0 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 2(Integer),2(Integer),2(String)
<== main, name:ds2020, Total: 1
==> main, name:ds2020, Preparing: INSERT INTO t_order_1 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 3(Integer),0(Integer),3(String)
<== main, name:ds2020, Total: 1
==> main, name:ds2020, Preparing: INSERT INTO t_order_2 (id,status,created) VALUES (?,?,?)
==> main, name:ds2020, Parameters: 4(Integer),1(Integer),4(String)
.....省略
List<H2Order> list = easyQueryOrder.queryable(H2Order.class)
.where(o -> o.in(H2Order::getId, Arrays.asList(1, 2, 6, 7)))
.toList();
Assert.assertEquals(4,list.size());
==> SHARDING_EXECUTOR_2, name:ds2020, Preparing: SELECT id,status,created FROM t_order_3 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_4, name:ds2020, Preparing: SELECT id,status,created FROM t_order_0 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_3, name:ds2020, Preparing: SELECT id,status,created FROM t_order_4 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_1, name:ds2020, Preparing: SELECT id,status,created FROM t_order_2 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_4, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_5, name:ds2020, Preparing: SELECT id,status,created FROM t_order_1 WHERE id IN (?,?,?,?)
==> SHARDING_EXECUTOR_3, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_5, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_1, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_2, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
<== SHARDING_EXECUTOR_2, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_5, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_1, name:ds2020, Time Elapsed: 1(ms)
<== SHARDING_EXECUTOR_4, name:ds2020, Time Elapsed: 1(ms)
<== SHARDING_EXECUTOR_3, name:ds2020, Time Elapsed: 1(ms)
<== Total: 4
``
通过上述sql展示我们可以清晰的看到哪个线程执行了哪个数据源(分片下会不一样),执行了什么sql,最终执行消耗多少时间参数是多少,一共返回多少条数据
分片排序
```java
List<H2Order> list = easyQueryOrder.queryable(H2Order.class)
.where(o -> o.in(H2Order::getId, Arrays.asList(1, 2, 6, 7)))
.orderByDesc(o->o.column(H2Order::getId))
.toList();
Assert.assertEquals(4,list.size());
Assert.assertEquals(7,(int)list.get(0).getId());
Assert.assertEquals(6,(int)list.get(1).getId());
Assert.assertEquals(2,(int)list.get(2).getId());
Assert.assertEquals(1,(int)list.get(3).getId());
==> SHARDING_EXECUTOR_1, name:ds2020, Preparing: SELECT id,status,created FROM t_order_1 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_5, name:ds2020, Preparing: SELECT id,status,created FROM t_order_3 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_4, name:ds2020, Preparing: SELECT id,status,created FROM t_order_2 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_3, name:ds2020, Preparing: SELECT id,status,created FROM t_order_4 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_5, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_1, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_4, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_2, name:ds2020, Preparing: SELECT id,status,created FROM t_order_0 WHERE id IN (?,?,?,?) ORDER BY id DESC
==> SHARDING_EXECUTOR_3, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
==> SHARDING_EXECUTOR_2, name:ds2020, Parameters: 1(Integer),2(Integer),6(Integer),7(Integer)
<== SHARDING_EXECUTOR_1, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_5, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_4, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_2, name:ds2020, Time Elapsed: 0(ms)
<== SHARDING_EXECUTOR_3, name:ds2020, Time Elapsed: 0(ms)
<== Total: 4
最后的最后
附上源码地址,源码中有文档和对应的qq群,如果决定有用请点击star谢谢大家了
2021年最全java面试真题解析(980道),你没见过的船新面试题都在这里
前言

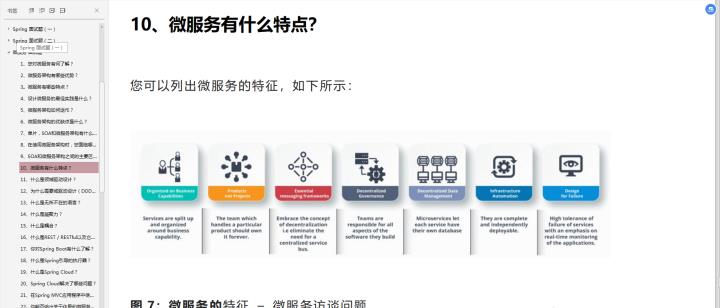
2021年已经快过去一半了,时间一眨眼就过去了。今年金三银四面试有没有被面试官虐呢,金九银十跳槽想跳去哪个大厂呢,这是个问题。说实话,今年我面试也被虐了,为了金九银十能找到一份心怡的工作,特地的从朋友那里讨来一份面试圣经(阿里某大牛),980道面试真题和解析,一共485页PDF。囊括Java、MyBatis、ZooKeeper、Dubbo、Elasticsearch、Memcached、Redis、MySQL、Spring、Spring Boot、Spring Cloud、RabbitMQ、Kafka、Linux 等技术栈。
由于面试真题涉及全面,解析详细,所有的解析就不在文中给大家全部列出,整个980道面试真题都整理在一个pdf文档里面。
每个专题总结将近50道真题(含解析),一共包含java、MyBatis、ZooKeeper、Dubbo等二十个多个专题。485页PDF。

20多个专题:

正文:
MyBatis 面试题(27道):
什么是 Mybatis?
1、Mybatis 是一个半 ORM(对象关系映射)框架,它内部封装了 JDBC,开发时只需要关注 SQL 语句本身,不需要花费精力去处理加载驱动、创建连接、创建statement 等繁杂的过程。程序员直接编写原生态 sql,可以严格控制 sql 执行性能,灵活度高。
2、MyBatis 可以使用 XML 或注解来配置和映射原生信息,将 POJO 映射成数据库中的记录,避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
3、通过 xml 文件或注解的方式将要执行的各种 statement 配置起来,并通过java 对象和 statement 中 sql 的动态参数进行映射生成最终执行的 sql 语句,最后由 mybatis 框架执行 sql 并将结果映射为 java 对象并返回。(从执行 sql 到返回 result 的过程)。
-
Mybaits 的优点:
-
MyBatis 框架的缺点:
-
MyBatis 框架适用场合:
-
MyBatis 与 Hibernate 有哪些不同?
-
#{}和${}的区别是什么?
-
当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
-
模糊查询 like 语句该怎么写?
-
通常一个 Xml 映射文件,都会写一个 Dao 接口与之对应,请问,这个 Dao 接口的工作原理是什么?Dao 接口里的方法,参数不同时,方法能重载吗?
-
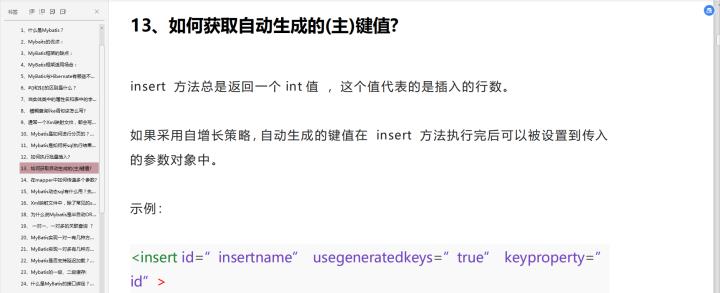
Mybatis 是如何进行分页的?分页插件的原理是什么?
-
Mybatis是如何将sql执行结果封装为目标对象并返回的?都有哪些映射形式?
ZooKeeper 面试题(28道):
ZooKeeper 面试题?
ZooKeeper 是一个开放源码的分布式协调服务,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户。分布式应用程序可以基于 Zookeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
-
ZooKeeper 提供了什么?
-
Zookeeper 文件系统
-
ZAB 协议?
-
四种类型的数据节点 Znode
-
Zookeeper Watcher 机制--数据变更通知
-
客户端注册 Watcher 实现
-
服务端处理 Watcher 实现
-
客户端回调 Watcher

Dubbo 面试题(30道):
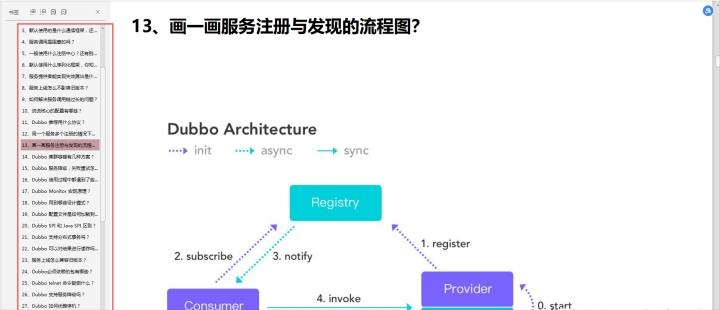
为什么要用 Dubbo?
随着服务化的进一步发展,服务越来越多,服务之间的调用和依赖关系也越来越复杂,诞生了面向服务的架构体系(SOA),也因此衍生出了一系列相应的技术,如对服务提供、服务调用、连接处理、通信协议、序列化方式、服务发现、服务路由、日志输出等行为进行封装的服务框架。就这样为分布式系统的服务治理框架就出现了,Dubbo 也就这样产生了。
-
Dubbo 的整体架构设计有哪些分层?
-
默认使用的是什么通信框架,还有别的选择吗?
-
服务调用是阻塞的吗?
-
服务调用是阻塞的吗?
-
一般使用什么注册中心?还有别的选择吗?
-
默认使用什么序列化框架,你知道的还有哪些?
-
服务提供者能实现失效踢出是什么原理?
-
服务上线怎么不影响旧版本?
Elasticsearch 面试题(24道):
详细描述一下 Elasticsearch 索引文档的过程?
面试官:想了解 ES 的底层原理,不再只关注业务层面了。
解答:这里的索引文档应该理解为文档写入 ES,创建索引的过程。文档写入包含:单文档写入和批量 bulk 写入,这里只解释一下:单文档写入流程。记住官方文档中的这个图。
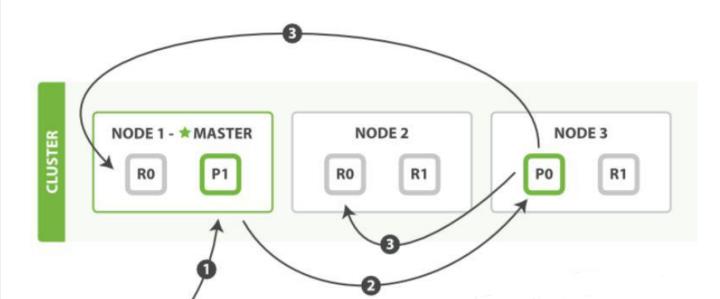
第一步:客户写集群某节点写入数据,发送请求。(如果没有指定路由/协调节点,请求的节点扮演路由节点的角色。)
第二步:节点 1 接受到请求后,使用文档_id 来确定文档属于分片 0。请求会被转到另外的节点,假定节点 3。因此分片 0 的主分片分配到节点 3 上。
第三步:节点 3 在主分片上执行写操作,如果成功,则将请求并行转发到节点 1和节点 2 的副本分片上,等待结果返回。所有的副本分片都报告成功,节点 3 将向协调节点(节点 1)报告成功,节点 1 向请求客户端报告写入成功。
如果面试官再问:第二步中的文档获取分片的过程?
回答:借助路由算法获取,路由算法就是根据路由和文档 id 计算目标的分片 id 的过程。
shard = hash(_routing) % (num_of_primary_shards)
-
elasticsearch 了解多少,说说你们公司 es 的集群架构,索引数据大小,分片有多少,以及一些调优手段 。
-
elasticsearch 的倒排索引是什么
-
elasticsearch 索引数据多了怎么办,如何调优,部署
-
elasticsearch 是如何实现 master 选举的
-
详细描述一下 Elasticsearch 搜索的过程?
-
Elasticsearch 在部署时,对 Linux 的设置有哪些优化方法
-
lucence 内部结构是什么?

Memcached 面试题(23道):
Memcached 是什么,有什么作用?
Memcached 是一个开源的,高性能的内存绶存软件,从名称上看 Mem 就是内存的意思,而 Cache 就是缓存的意思。Memcached 的作用:通过在事先规划好的内存空间中临时绶存数据库中的各类数据,以达到减少业务对数据库的直接高并发访问,从而达到提升数据库的访问性能,加速网站集群动态应用服务的能力。
-
Memcached 服务分布式集群如何实现?
-
Memcached 服务特点及工作原理是什么?
-
简述 Memcached 内存管理机制原理?
-
memcached 是怎么工作的?
-
memcached 最大的优势是什么?
-
memcached 和 MySQL 的 query
-
memcached 和服务器的 local cache(比如 PHP 的 APC、mmap 文件等)相比,有什么优缺点?

Redis 面试题(40道):
什么是 Redis?
Redis 是完全开源免费的,遵守 BSD 协议,是一个高性能的 key-value 数据库。
Redis 与其他 key-value 缓存产品有以下三个特点:
-
Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
-
Redis 不仅仅支持简单的 key-value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。
-
Redis 支持数据的备份,即 master-slave 模式的数据备份。
Redis 优势
-
性能极高–Redis 能读的速度是 110000 次/s,写的速度是 81000 次/s 。
-
丰富的数据类型–Redis 支持二进制案例的 Strings, Lists, Hashes, Sets 及Ordered Sets 数据类型操作。
-
原子–Redis 的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC指令包起来。
-
丰富的特性–Redis 还支持 publish/subscribe, 通知, key 过期等等特性。
Redis 与其他 key-value 存储有什么不同?
Redis 有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis 的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
Redis 运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样 Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
-
Redis 的数据类型?
-
使用 Redis 有哪些好处?
-
Redis 相比 Memcached 有哪些优势?
-
Memcache 与 Redis 的区别都有哪些?
-
Redis 是单进程单线程的?
-
一个字符串类型的值能存储最大容量是多少?
-
Redis 的持久化机制是什么?各自的优缺点?
-
Redis 常见性能问题和解决方案:

MySQL 面试题(50道):
MySQL 中有哪几种锁?
1、表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
2、行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
3、页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
-
MySQL 中有哪些不同的表格?
-
简述在 MySQL 数据库中 MyISAM 和 InnoDB 的区别
-
MySQL 中 InnoDB 支持的四种事务隔离级别名称,以及逐级之间的区别?
-
CHAR 和 VARCHAR 的区别?
-
主键和候选键有什么区别?
-
myisamchk 是用来做什么的?
-
如果一个表有一列定义为 TIMESTAMP,将发生什么?

总结:
上面给大家展示了八个专题的一部分真题和一部分解析,还有,Java并发编程123道,Java面试题228道,spring面试题116道,微服务面试题50道,Linux 面试题45道,Spring Boot 面试题22道,Spring Cloud 面试题8道,RabbitMQ 面试题12道,kafka 面试题18道。980道面试真题(485页PDF)。
由于篇幅限制,就不一一展示了,有需要文中以上分享的全部资料完整版的小伙伴们注意啦:一键三连(点赞+收藏+关注)后直接添加微信:mxh5261 即可百分百免费获取

以上是关于你没见过的分库分表原理解析和解决方案的主要内容,如果未能解决你的问题,请参考以下文章