如何获取 C#程序 内核态线程栈
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何获取 C#程序 内核态线程栈相关的知识,希望对你有一定的参考价值。
一:背景
1. 讲故事
在这么多的案例分析中,往往会发现一些案例是卡死在线程的内核态栈上,但拿过来的dump都是用户态模式下,所以无法看到内核态栈,这就比较麻烦,需要让朋友通过其他方式生成一个蓝屏的dump,这里我们简单汇总下。
二:如何生成内核态dump
1. 案例代码
为了方便演示,来一段简单的测试代码,目的就是观察 Console.ReadLine 方法的内核态栈。
internal class Program
static void Main(string[] args)
Console.WriteLine("hello world!");
Console.ReadLine();
通过 任务管理器 或者 Process Explorer 默认抓取的dump都是 ntdll 之上的空间,可以用 k 来看一下。
0:000> k 3
# Child-SP RetAddr Call Site
00 000000d6`7c9fe328 00007ffe`61405593 ntdll!NtReadFile+0x14
01 000000d6`7c9fe330 00007ffd`50724782 KERNELBASE!ReadFile+0x73
02 000000d6`7c9fe3b0 00007ffe`215bc742 0x00007ffd`50724782
问题来了,如果我要看下 ntdll!NtReadFile 函数对应在内核态中的 nt!NtReadFile 方法怎么办呢?只能抓内核态dump,抓内核态dump的方式有很多,这里聊一下其中的两种方式。
2. 使用 notmyfault 抓取
说到 蓝屏 我相信有很多朋友都知道,简而言之就是内核态代码出bug导致系统崩溃,也有朋友知道通过增加一些配置可以在蓝屏的时候自动生成 dump 文件,这种 dump 文件就属于内核态,配置如下:

但这里有一个问题,操作系统不可能无缘无故的蓝屏,那怎么办呢?微软想了一个办法,人为的造蓝屏,所以提供了一个叫 notmyfault.exe 的工具, MSDN网址:https://learn.microsoft.com/en-us/sysinternals/downloads/notmyfault
有了这些前置基础,接下来就可以操练一下,双击 notmyfault.exe 工具,崩溃原因选择默认的 High IRQL fault,最后点击 Crash 按钮,稍等片刻电脑就会蓝屏。截图如下:
我这里用的是一台物理的 迷你主机 测试,再次远程连接后,在 C:\\Windows 下会生成一个 MEMORY.dmp 文件,截图如下:
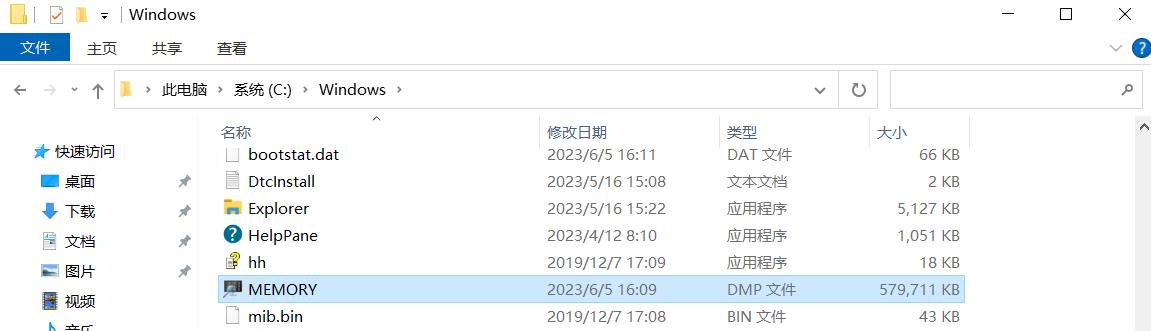
拿到 dump 之后就可以用 windbg 中的 !process 之类的命令分析了,非常爽。
1: kd> !process 0 2 ConsoleApp1.exe
PROCESS ffffdb05c1641080
SessionId: 1 Cid: 1bc8 Peb: fd877dd000 ParentCid: 15ec
DirBase: 1b9ef3000 ObjectTable: ffffa105fc3d5280 HandleCount: 161.
Image: ConsoleApp1.exe
THREAD ffffdb05bf3c7080 Cid 1bc8.0924 Teb: 000000fd877de000 Win32Thread: ffffdb05c00d0ad0 WAIT: (Executive) KernelMode Alertable
ffffdb05c1902ef8 NotificationEvent
THREAD ffffdb05c0fc6080 Cid 1bc8.07c8 Teb: 000000fd877e4000 Win32Thread: 0000000000000000 WAIT: (UserRequest) UserMode Non-Alertable
ffffdb05be642ae0 NotificationEvent
THREAD ffffdb05be694080 Cid 1bc8.17dc Teb: 000000fd877e6000 Win32Thread: 0000000000000000 WAIT: (UserRequest) UserMode Non-Alertable
ffffdb05be645860 SynchronizationEvent
ffffdb05be646e60 SynchronizationEvent
ffffdb05be645d60 SynchronizationEvent
THREAD ffffdb05be7e2080 Cid 1bc8.1020 Teb: 000000fd877e8000 Win32Thread: 0000000000000000 WAIT: (UserRequest) UserMode Non-Alertable
ffffdb05b68b53a0 NotificationEvent
ffffdb05be651de0 SynchronizationEvent
1: kd> .thread ffffdb05bf3c7080
Implicit thread is now ffffdb05`bf3c7080
1: kd> k
*** Stack trace for last set context - .thread/.cxr resets it
# Child-SP RetAddr Call Site
00 fffff50f`606ed570 fffff800`52c1c9c0 nt!KiSwapContext+0x76
01 fffff50f`606ed6b0 fffff800`52c1beef nt!KiSwapThread+0x500
02 fffff50f`606ed760 fffff800`52c1b793 nt!KiCommitThreadWait+0x14f
03 fffff50f`606ed800 fffff800`52df04c4 nt!KeWaitForSingleObject+0x233
04 fffff50f`606ed8f0 fffff800`53010cdb nt!IopWaitForSynchronousIoEvent+0x50
05 fffff50f`606ed930 fffff800`52fcc9e8 nt!IopSynchronousServiceTail+0x50b
06 fffff50f`606ed9d0 fffff800`52ff9ae8 nt!IopReadFile+0x7cc
07 fffff50f`606edac0 fffff800`52e0f3f5 nt!NtReadFile+0x8a8
08 fffff50f`606edbd0 00007ffa`2fb4d124 nt!KiSystemServiceCopyEnd+0x25
09 000000fd`8797e108 00000000`00000000 0x00007ffa`2fb4d124
从卦中看,主线程的内核态栈中的 nt!NtReadFile 函数果然给找到了。
2. 使用 procdump
如果仅仅是看线程的内核态栈,我发现有一个非常简单的方式,就是在 procudump 中多加一个 mk 参数即可,截图如下:

接下来使用 Terminal 执行 procdump,输出如下:
PS C:\\Users\\Administrator\\Desktop> procdump -ma -mk ConsoleApp -o D:\\testdump
ProcDump v11.0 - Sysinternals process dump utility
Copyright (C) 2009-2022 Mark Russinovich and Andrew Richards
Sysinternals - www.sysinternals.com
[16:24:49] Dump 1 initiated: D:\\testdump\\ConsoleApp1.exe_230605_162449.dmp
[16:24:50] Dump 1 writing: Estimated dump file size is 57 MB.
[16:24:50] Dump 1 complete: 57 MB written in 0.1 seconds
[16:24:50] Dump 1 kernel: D:\\testdump\\ConsoleApp1.exe_230605_162449.Kernel.dmp
[16:24:50] Dump count reached.

从卦中看,当前生成了两个 dmp 文件,一个是用户态dump,一个是内核态dump,也能看到后者还不到 1M,和刚才用 notmyfault 生成的 500M dump 所存储的信息量相差甚远,但对我目前的场景来说已经够用了。
接下来打开 ConsoleApp1.exe_230605_162449.Kernel.dmp 文件,使用 !process 找到 ConsoleApp1.exe 的进程。
..................................................
For analysis of this file, run !analyze -v
nt!DbgkpLkmdSnapThreadInContext+0x95:
fffff804`5e688b51 488364242800 and qword ptr [rsp+28h],0 ss:0018:ffffe10d`62386fd8=ffffe10d5b8fa810
0: kd> !process 0 2 ConsoleApp1.exe
Unable to read _LIST_ENTRY @ fffff8045ea1e080
0: kd> .reload /user
Loading User Symbols
0: kd> !process 0 2 ConsoleApp1.exe
Unable to read _LIST_ENTRY @ fffff8045ea1e080
从卦中看居然报错了,那怎么办呢?办法肯定是有办法的,可以到用户态dump中寻找进程ID即可。
0:000> ~
. 0 Id: 3adc.5920 Suspend: 0 Teb: 000000d6`7cb98000 Unfrozen
1 Id: 3adc.2240 Suspend: 0 Teb: 000000d6`7cba0000 Unfrozen
2 Id: 3adc.514 Suspend: 0 Teb: 000000d6`7cba2000 Unfrozen
3 Id: 3adc.3c68 Suspend: 0 Teb: 000000d6`7cba4000 Unfrozen ".NET Finalizer"
拿到 3adc 进程号后再找下面的主线程,观察它的线程栈信息,输出如下:
0: kd> .process 3adc
Implicit process is now 00000000`00003adc
0: kd> !process
PROCESS ffffcf8d5d5b0080
SessionId: none Cid: 3adc Peb: d67cb97000 ParentCid: 4c80
DirBase: 367d95000 ObjectTable: ffff8e81710bbb40 HandleCount: <Data Not Accessible>
Image: ConsoleApp1.ex
VadRoot ffffcf8d5b20fcb0 Vads 90 Clone 0 Private 1529. Modified 941. Locked 2.
DeviceMap ffff8e8172645110
Token ffff8e815e216060
ReadMemory error: Cannot get nt!KeMaximumIncrement value.
fffff78000000000: Unable to get shared data
ElapsedTime 00:00:00.000
UserTime 00:00:00.000
KernelTime 00:00:00.000
QuotaPoolUsage[PagedPool] 153768
QuotaPoolUsage[NonPagedPool] 12648
Working Set Sizes (now,min,max) (14126, 50, 345) (56504KB, 200KB, 1380KB)
PeakWorkingSetSize 14033
VirtualSize 2101882 Mb
PeakVirtualSize 2101888 Mb
PageFaultCount 15757
MemoryPriority BACKGROUND
BasePriority 8
CommitCharge 1628
Job ffffcf8d53a102c0
THREAD ffffcf8d5ae14080 Cid 3adc.5920 Teb: 000000d67cb98000 Win32Thread: ffffcf8d54c3a3b0 RUNNING on processor 0
THREAD ffffcf8d4f63e080 Cid 3adc.2240 Teb: 000000d67cba0000 Win32Thread: 0000000000000000 INVALID
THREAD ffffcf8d69a32080 Cid 3adc.0514 Teb: 000000d67cba2000 Win32Thread: 0000000000000000 INVALID
THREAD ffffcf8d55003580 Cid 3adc.3c68 Teb: 000000d67cba4000 Win32Thread: 0000000000000000 INVALID
0: kd> .thread ffffcf8d5ae14080
Implicit thread is now ffffcf8d`5ae14080
0: kd> k
*** Stack trace for last set context - .thread/.cxr resets it
# Child-SP RetAddr Call Site
00 ffffe10d`62386fb0 fffff804`5e688a7b nt!DbgkpLkmdSnapThreadInContext+0x95
01 ffffe10d`623874f0 fffff804`5e01dcd0 nt!DbgkpLkmdSnapThreadApc+0x3b
02 ffffe10d`62387520 fffff804`5e01bb67 nt!KiDeliverApc+0x1b0
03 ffffe10d`623875d0 fffff804`5e01ad6f nt!KiSwapThread+0x827
04 ffffe10d`62387680 fffff804`5e01a613 nt!KiCommitThreadWait+0x14f
05 ffffe10d`62387720 fffff804`5e439c68 nt!KeWaitForSingleObject+0x233
06 ffffe10d`62387810 fffff804`5e411fe9 nt!IopSynchronousServiceTail+0x238
07 ffffe10d`623878b0 fffff804`5e20d9f5 nt!NtReadFile+0x599
08 ffffe10d`62387990 00007ffe`6390d184 nt!KiSystemServiceCopyEnd+0x25
09 000000d6`7c9fe328 00000000`00000000 0x00007ffe`6390d184
怎么样,上面的 nt!NtReadFile+0x599 函数就是。
三:总结
有时候真的需要去抓内核态dump,总有一些千奇百怪的问题,太难了,这里总结一下给后来人少踩坑吧。

Go 为什么这么“快”

Goroutine 上下文切换只涉及到三个寄存器(PC / SP / DX)的值修改;而对比线程的上下文切换则需要涉及模式切换(从用户态切换到内核态)、以及 16 个寄存器、PC、SP…等寄存器的刷新;内存占用少:线程栈空间通常是 2M,Goroutine 栈空间最小 2K;
Golang 程序中可以轻松支持10w 级别的 Goroutine 运行,而线程数量达到 1k 时,内存占用就已经达到 2G。
(逻辑处理器)来作获取内核线程资源的『中介』。Go 调度器模型我们通常叫做G-P-M 模型,他包括 4 个重要结构,分别是G、P、M、Sched:
G:Goroutine,每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、状态以及任务函数,可重用。
G 并非执行体,每个 G 需要绑定到 P 才能被调度执行。
P:
Processor,表示逻辑处理器,对 G 来说,P 相当于 CPU 核,G 只有绑定到 P 才能被调度。对 M 来说,P 提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等。
P 的数量决定了系统内最大可并行的 G 的数量(前提:物理 CPU 核数 >= P 的数量)。
P 的数量由用户设置的 GoMAXPROCS 决定,但是不论 GoMAXPROCS 设置为多大,P 的数量最大为 256。
M:
Machine,OS 内核线程抽象,代表着真正执行计算的资源,在绑定有效的 P 后,进入 schedule 循环;而 schedule 循环的机制大致是从 Global 队列、P 的 Local 队列以及 wait 队列中获取。
M 的数量是不定的,由 Go
Runtime 调整,为了防止创建过多 OS 线程导致系统调度不过来,目前默认最大限制为 10000 个。
M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。
Sched:Go 调度器,它维护有存储 M 和 G 的队列以及调度器的一些状态信息等。
调度器循环的机制大致是从各种队列、P 的本地队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 Goexit 做清理工作并回到 M,如此反复。
理解 M、P、G 三者的关系,可以通过经典的地鼠推车搬砖的模型来说明其三者关系:
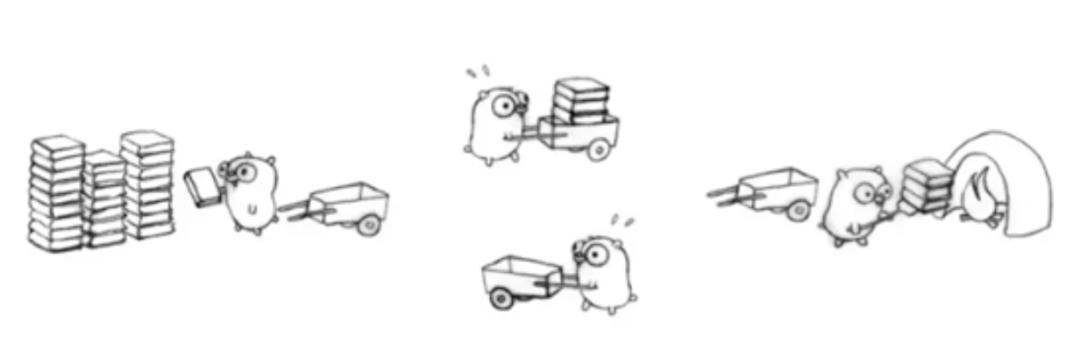
地鼠(Gopher)的工作任务是:工地上有若干砖头,地鼠借助小车把砖头运送到火种上去烧制。M 就可以看作图中的地鼠,P 就是小车,G 就是小车里装的砖。
弄清楚了它们三者的关系,下面我们就开始重点聊地鼠是如何在搬运砖块的。
Processor(P):
根据用户设置的 GoMAXPROCS 值来创建一批小车(P)。
Goroutine(G):
通过 Go 关键字就是用来创建一个 Goroutine,也就相当于制造一块砖(G),然后将这块砖(G)放入当前这辆小车(P)中。
Machine (M):
地鼠(M)不能通过外部创建出来,只能砖(G)太多了,地鼠(M)又太少了,实在忙不过来,刚好还有空闲的小车(P)没有使用,那就从别处再借些地鼠(M)过来直到把小车(P)用完为止。
这里有一个地鼠(M)不够用,从别处借地鼠(M)的过程,这个过程就是创建一个内核线程(M)。
需要注意的是:地鼠(M) 如果没有小车(P)是没办法运砖的,小车(P)的数量决定了能够干活的地鼠(M)数量,在 Go 程序里面对应的是活动线程数;
在 Go 程序里我们通过下面的图示来展示 G-P-M 模型:
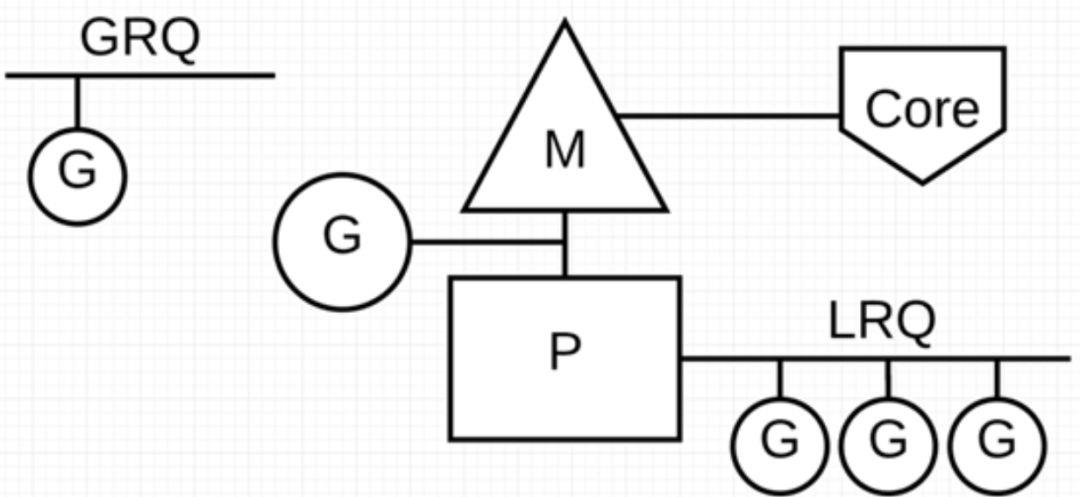
P 代表可以“并行”运行的逻辑处理器,每个 P 都被分配到一个系统线程 M,G 代表 Go 协程。
Go 调度器中有两个不同的运行队列:全局运行队列(GRQ)和本地运行队列(LRQ)。
每个 P 都有一个 LRQ,用于管理分配给在 P 的上下文中执行的 Goroutines,这些 Goroutine 轮流被和 P 绑定的 M 进行上下文切换。GRQ 适用于尚未分配给 P 的 Goroutines。
从上图可以看出,G 的数量可以远远大于 M 的数量,换句话说,Go 程序可以利用少量的内核级线程来支撑大量 Goroutine 的并发。多个 Goroutine 通过用户级别的上下文切换来共享内核线程 M 的计算资源,但对于操作系统来说并没有线程上下文切换产生的性能损耗。
为了更加充分利用线程的计算资源,Go 调度器采取了以下几种调度策略:
任务窃取(work-stealing)
我们知道,现实情况有的 Goroutine 运行的快,有的慢,那么势必肯定会带来的问题就是,忙的忙死,闲的闲死,Go 肯定不允许摸鱼的 P 存在,势必要充分利用好计算资源。
为了提高 Go 并行处理能力,调高整体处理效率,当每个 P 之间的 G 任务不均衡时,调度器允许从 GRQ,或者其他 P 的 LRQ 中获取 G 执行。
减少阻塞
如果正在执行的 Goroutine 阻塞了线程 M 怎么办?P 上 LRQ 中的 Goroutine 会获取不到调度么?
在 Go 里面阻塞主要分为一下 4 种场景:
场景 1:由于原子、互斥量或通道操作调用导致 Goroutine 阻塞,调度器将把当前阻塞的 Goroutine 切换出去,重新调度 LRQ 上的其他 Goroutine;
场景 2:由于网络请求和 IO 操作导致 Goroutine 阻塞,这种阻塞的情况下,我们的 G 和 M 又会怎么做呢?
Go 程序提供了网络轮询器(NetPoller)来处理网络请求和 IO 操作的问题,其后台通过 kqueue(MacOS),epoll(Linux)或 iocp(Windows)来实现 IO 多路复用。
通过使用 NetPoller 进行网络系统调用,调度器可以防止 Goroutine 在进行这些系统调用时阻塞 M。这可以让 M 执行 P 的 LRQ 中其他的 Goroutines,而不需要创建新的 M。有助于减少操作系统上的调度负载。
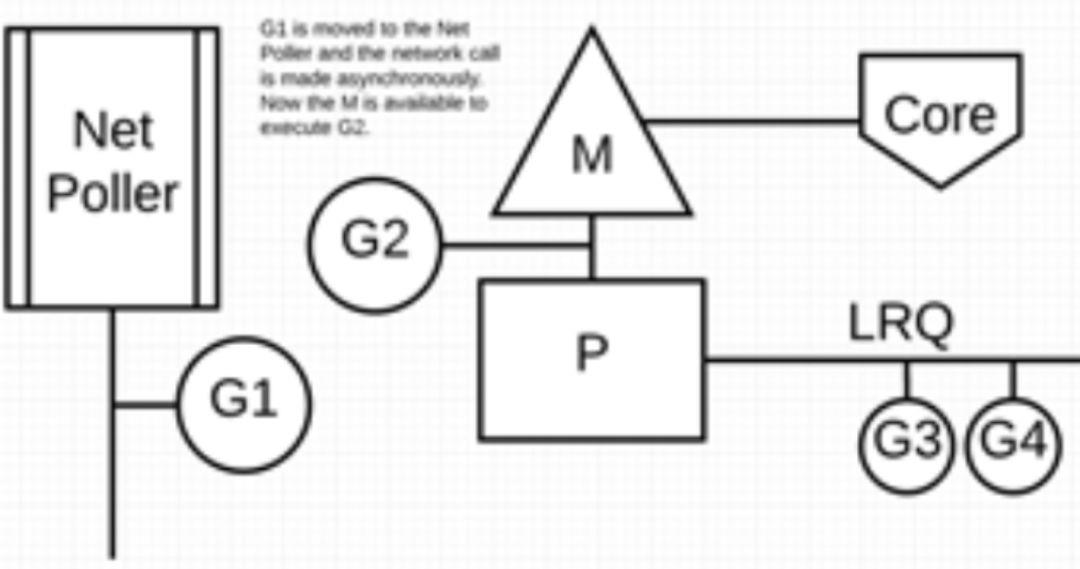
下图展示它的工作原理:G1 正在 M 上执行,还有 3 个 Goroutine 在 LRQ 上等待执行。网络轮询器空闲着,什么都没干。
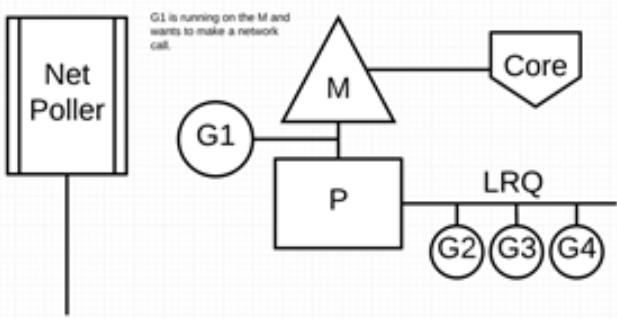
接下来,G1 想要进行网络系统调用,因此它被移动到网络轮询器并且处理异步网络系统调用。然后,M 可以从 LRQ 执行另外的 Goroutine。此时,G2 就被上下文切换到 M 上了。
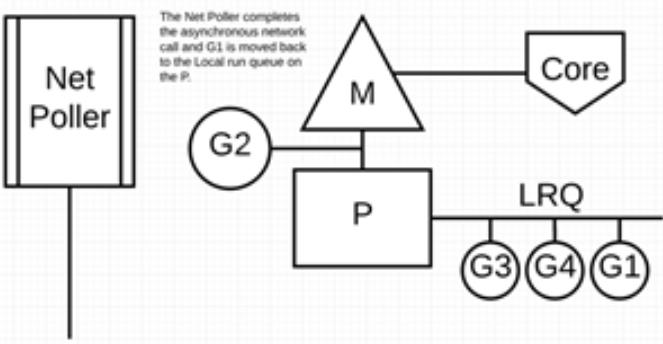
最后,异步网络系统调用由网络轮询器完成,G1 被移回到 P 的 LRQ 中。一旦 G1 可以在 M 上进行上下文切换,它负责的 Go 相关代码就可以再次执行。这里的最大优势是,执行网络系统调用不需要额外的 M。网络轮询器使用系统线程,它时刻处理一个有效的事件循环。
这种调用方式看起来很复杂,值得庆幸的是,Go 语言将该“复杂性”隐藏在 Runtime 中:Go 开发者无需关注 socket 是否是 non-block 的,也无需亲自注册文件描述符的回调,只需在每个连接对应的 Goroutine 中以“block I/O”的方式对待 socket 处理即可,实现了 goroutine-per-connection 简单的网络编程模式(但是大量的 Goroutine 也会带来额外的问题,比如栈内存增加和调度器负担加重)。
用户层眼中看到的 Goroutine 中的“block socket”,实际上是通过 Go runtime 中的 netpoller 通过 Non-block socket + I/O 多路复用机制“模拟”出来的。Go 中的 net 库正是按照这方式实现的。
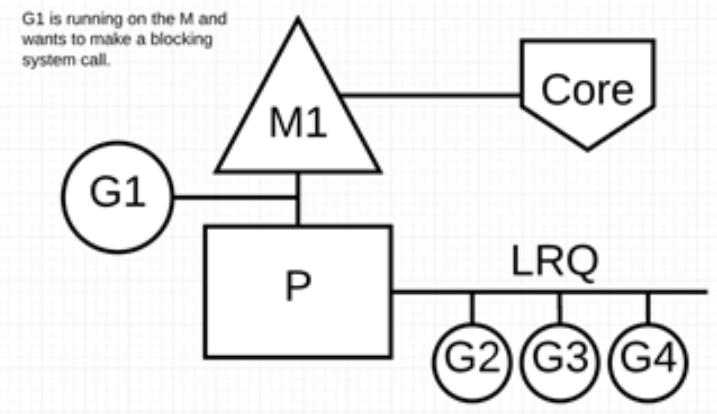
场景 3:当调用一些系统方法的时候,如果系统方法调用的时候发生阻塞,这种情况下,网络轮询器(NetPoller)无法使用,而进行系统调用的 Goroutine 将阻塞当前 M。
让我们来看看同步系统调用(如文件 I/O)会导致 M 阻塞的情况:G1 将进行同步系统调用以阻塞 M1。
调度器介入后:识别出 G1 已导致 M1 阻塞,此时,调度器将 M1 与 P 分离,同时也将 G1 带走。然后调度器引入新的 M2 来服务 P。此时,可以从 LRQ 中选择 G2 并在 M2 上进行上下文切换。
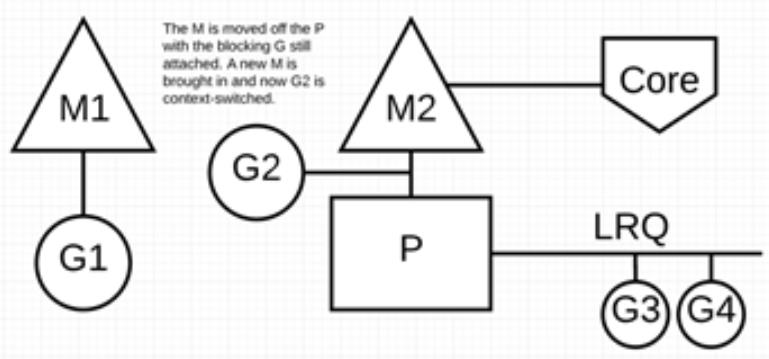
阻塞的系统调用完成后:G1 可以移回 LRQ 并再次由 P 执行。如果这种情况再次发生,M1 将被放在旁边以备将来重复使用。

场景 4:如果在 Goroutine 去执行一个 sleep 操作,导致 M 被阻塞了。
Go 程序后台有一个监控线程 sysmon,它监控那些长时间运行的 G 任务然后设置可以强占的标识符,别的 Goroutine 就可以抢先进来执行。
只要下次这个 Goroutine 进行函数调用,那么就会被强占,同时也会保护现场,然后重新放入 P 的本地队列里面等待下次执行。
小结本文主要从 Go 调度器架构层面上介绍了 G-P-M 模型,通过该模型怎样实现少量内核线程支撑大量 Goroutine 的并发运行。以及通过 NetPoller、sysmon 等帮助 Go 程序减少线程阻塞,充分利用已有的计算资源,从而最大限度提高 Go 程序的运行效率。
参考文档:
https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part1.html
https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html
https://www.ardanlabs.com/blog/2018/12/scheduling-in-go-part3.html
https://segmentfault.com/a/1190000016038785
https://segmentfault.com/a/1190000016611742
https://segmentfault.com/a/1190000017333717
https://segmentfault.com/a/1190000015352983
https://segmentfault.com/a/1190000015464889
https://www.cnblogs.com/lxmhhy/p/6041001.html
https://www.cnblogs.com/mokafamily/p/9975980.html
https://studyGolang.com/articles/9211
https://www.zhihu.com/question/20862617
https://codeburst.io/why-Goroutines-are-not-lightweight-threads-7c460c1f155f
https://blog.csdn.net/tiandyoin/article/details/76556702
https://www.jianshu.com/p/cc3c0fefee43
https://www.jianshu.com/p/a315224886d2
以上是关于如何获取 C#程序 内核态线程栈的主要内容,如果未能解决你的问题,请参考以下文章