druid活跃线程数量持续增长问题
Posted 幻影
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了druid活跃线程数量持续增长问题相关的知识,希望对你有一定的参考价值。
1、问题现象
前一阵子,在一个老项目里面加了一个接口,分页查询数据库里面的记录,用于前端展示。
(嗯,先别急,我要说的不是分页查询的性能导致的问题。)
需求很easy,三两下就搞定了,结果上线后过不了多久就收到告警druid活跃线程数量超过90%。
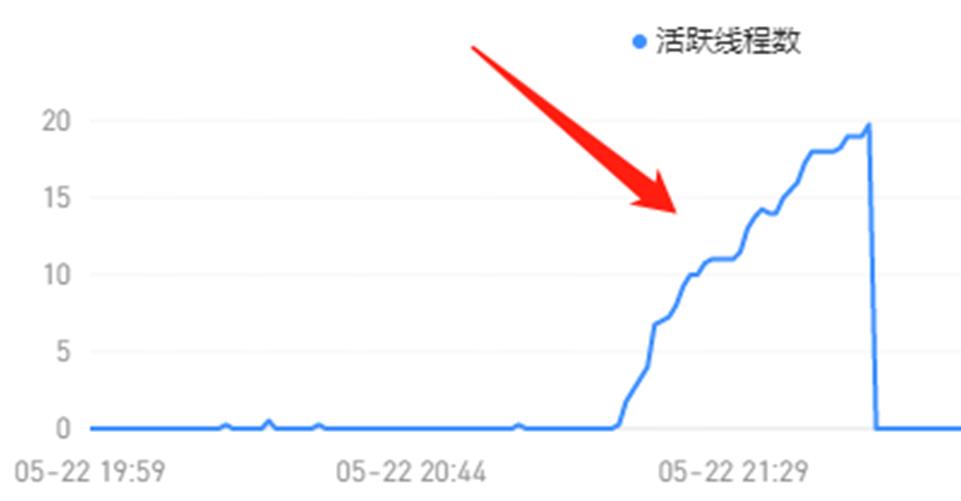
以前活跃线程数平均下来几乎为0,这次就加了一个分页查询接口,竟然导致活跃线程数量飙升?奇怪,我也没改特别的呀。
分页查询嘛,需要查询总记录数 + 当前页的记录。一般习惯用PageHelper之类的分页插件,但需要额外引入PageHelper这个jar,我看原来项目里已经有mybatis-paginator。想着还是少引入一个jar吧,就基于mybatis-paginator干吧。
2、问题分析
突然收到这个报警,也是觉得挺莫名其妙的,毕竟改动很小,就加了一个分页查询。
仔细确认了一下分页的代码,嗯,没啥毛病!
那咋弄呢?好在druid有monitor页面,先把monitor监控页面整出来,借助它来分析一下。
2.1、配置druid-monitor
首先,需要在web.xml里加上一些配置
<filter>
<filter-name>DruidWebStatFilter</filter-name>
<filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class>
<init-param>
<param-name>exclusions</param-name>
<param-value>/static/*,*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*</param-value>
</init-param>
<init-param>
<param-name>profileEnable</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>DruidWebStatFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
<init-param>
<param-name>loginUsername</param-name>
<param-value>druid</param-value>
</init-param>
<init-param>
<param-name>loginPassword</param-name>
<param-value>druid</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>DruidStatView</servlet-name>
<url-pattern>/druid/*</url-pattern>
</servlet-mapping>
然后,需要在DruidDataSource对象申明的地方,配置上
<property name="filters" value="config,stat,slf4j" />
配置好之后,就可以打开druid-monitor页面了。没什么意外的话,就可以看到数据源、连接数之类的信息了。
没意外的话,意外发生了---页面是出来了,数据源信息死活没出来。

这是什么情况?难道是配置哪里不对?查找了各种配置说明之后,才发现这可能是druid的bug。升级一下druid就解决了。
于是把druid从1.0.12升级到 1.0.29,数据源tab页就正常了。
2.2、观察数据指标
通过druid-monitor,重点关注【数据源】页的三个参数:
- 活跃连接数
- 逻辑连接打开次数
- 逻辑连接关闭次数
在测试环境试了一段时间,发现有些时候逻辑连接打开数 略大于 关闭数,这说明有些连接确实没关闭了。只不过测试环境请求量比较小,问题不容易暴漏。
那有啥办法定位是哪里没关闭连接吗?
2.3、连接泄露检测
百度谷歌了下,找到了温少的wiki-连接泄露检测
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close">
... ...
<property name="removeAbandoned" value="true" /> <!-- 打开removeAbandoned功能 -->
<property name="removeAbandonedTimeout" value="1800" /> <!-- 1800秒,也就是30分钟 -->
<property name="logAbandoned" value="true" /> <!-- 关闭abanded连接时输出错误日志 -->
... ...
</bean>
当removeAbandoned=true之后,可以在内置监控界面datasource.html中的查看ActiveConnection StackTrace属性的,可以看到未关闭连接的具体堆栈信息,从而方便查出哪些连接泄漏了。
比如下面这样:
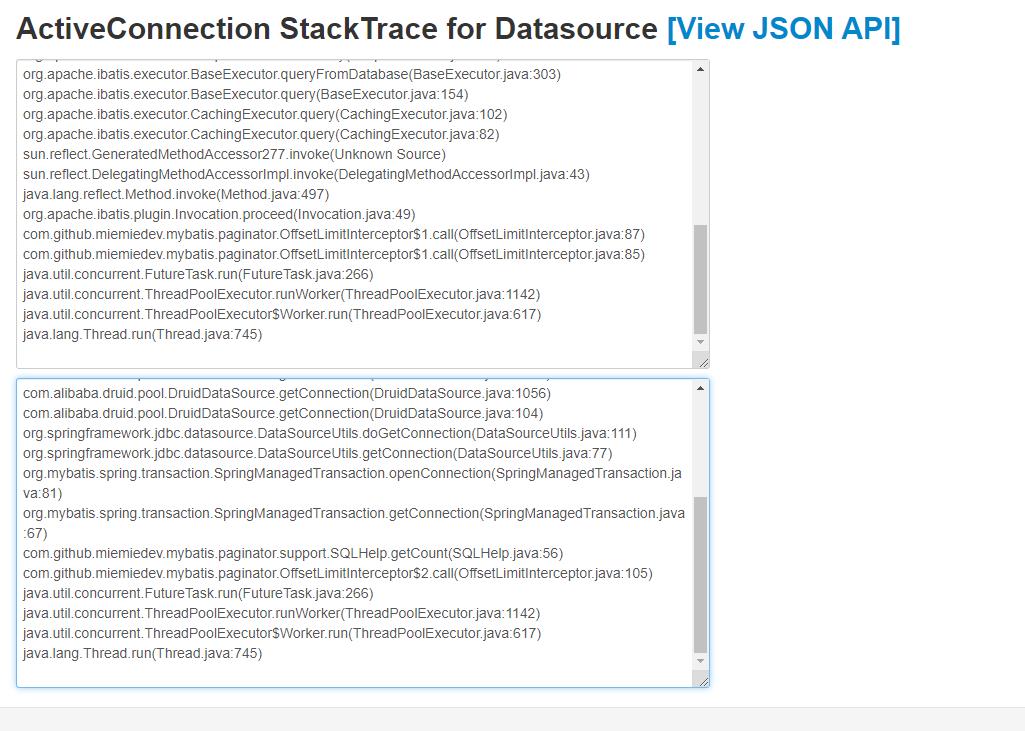
这些堆栈信息貌似也没啥特殊的,没有一行是项目的代码
java.lang.Thread.getStackTrace(Thread.java:1552)
com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:1140)
com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4544)
com.alibaba.druid.filter.logging.LogFilter.dataSource_getConnection(LogFilter.java:854)
com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4540)
com.alibaba.druid.filter.stat.StatFilter.dataSource_getConnection(StatFilter.java:670)
com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4540)
com.alibaba.druid.filter.FilterAdapter.dataSource_getConnection(FilterAdapter.java:2723)
com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4540)
com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1064)
com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1056)
com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:104)
org.springframework.jdbc.datasource.DataSourceUtils.doGetConnection(DataSourceUtils.java:111)
org.springframework.jdbc.datasource.DataSourceUtils.getConnection(DataSourceUtils.java:77)
org.mybatis.spring.transaction.SpringManagedTransaction.openConnection(SpringManagedTransaction.java:81)
org.mybatis.spring.transaction.SpringManagedTransaction.getConnection(SpringManagedTransaction.java:67)
org.apache.ibatis.executor.BaseExecutor.getConnection(BaseExecutor.java:315)
org.apache.ibatis.executor.SimpleExecutor.prepareStatement(SimpleExecutor.java:75)
org.apache.ibatis.executor.SimpleExecutor.doQuery(SimpleExecutor.java:61)
org.apache.ibatis.executor.BaseExecutor.queryFromDatabase(BaseExecutor.java:303)
org.apache.ibatis.executor.BaseExecutor.query(BaseExecutor.java:154)
org.apache.ibatis.executor.CachingExecutor.query(CachingExecutor.java:102)
org.apache.ibatis.executor.CachingExecutor.query(CachingExecutor.java:82)
sun.reflect.GeneratedMethodAccessor300.invoke(Unknown Source)
sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
java.lang.reflect.Method.invoke(Method.java:497)
org.apache.ibatis.plugin.Invocation.proceed(Invocation.java:49)
com.github.miemiedev.mybatis.paginator.OffsetLimitInterceptor$1.call(OffsetLimitInterceptor.java:87)
com.github.miemiedev.mybatis.paginator.OffsetLimitInterceptor$1.call(OffsetLimitInterceptor.java:85)
java.util.concurrent.FutureTask.run(FutureTask.java:266)
java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
java.lang.Thread.run(Thread.java:745)
不过,多来几次之后,就发现一个类名出现的次数比较多----OffsetLimitInterceptor!难道是这玩意导致的?
OffsetLimitInterceptor是mybatis-paginator实现分页查询的类。
于是乎尝试不使用mybatis-paginator,而是换了最原始的分页查询。结果问题解决了~
是的,就这么解决了! 这谁能想的到!
3、原因分析
前面猜测是mybatis-paginator的OffsetLimitInterceptor引起的,没想到蒙对了。改了之后问题就消失了。
那来看看OffsetLimitInterceptor到底做了什么
@Intercepts(@Signature(
type= Executor.class,
method = "query",
args = MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class))
public class OffsetLimitInterceptor implements Interceptor
private static Logger logger = LoggerFactory.getLogger(OffsetLimitInterceptor.class);
static int MAPPED_STATEMENT_INDEX = 0;
static int PARAMETER_INDEX = 1;
static int ROWBOUNDS_INDEX = 2;
static int RESULT_HANDLER_INDEX = 3;
static ExecutorService Pool;
String dialectClass;
boolean asyncTotalCount = false;
public Object intercept(final Invocation invocation) throws Throwable
final Executor executor = (Executor) invocation.getTarget();
final Object[] queryArgs = invocation.getArgs();
final MappedStatement ms = (MappedStatement)queryArgs[MAPPED_STATEMENT_INDEX];
final Object parameter = queryArgs[PARAMETER_INDEX];
final RowBounds rowBounds = (RowBounds)queryArgs[ROWBOUNDS_INDEX];
final PageBounds pageBounds = new PageBounds(rowBounds);
if(pageBounds.getOffset() == RowBounds.NO_ROW_OFFSET
&& pageBounds.getLimit() == RowBounds.NO_ROW_LIMIT
&& pageBounds.getOrders().isEmpty())
return invocation.proceed();
final Dialect dialect;
try
Class clazz = Class.forName(dialectClass);
Constructor constructor = clazz.getConstructor(MappedStatement.class, Object.class, PageBounds.class);
dialect = (Dialect)constructor.newInstance(new Object[]ms, parameter, pageBounds);
catch (Exception e)
throw new ClassNotFoundException("Cannot create dialect instance: "+dialectClass,e);
final BoundSql boundSql = ms.getBoundSql(parameter);
queryArgs[MAPPED_STATEMENT_INDEX] = copyFromNewSql(ms,boundSql,dialect.getPageSQL(), dialect.getParameterMappings(), dialect.getParameterObject());
queryArgs[PARAMETER_INDEX] = dialect.getParameterObject();
queryArgs[ROWBOUNDS_INDEX] = new RowBounds(RowBounds.NO_ROW_OFFSET,RowBounds.NO_ROW_LIMIT);
Boolean async = pageBounds.getAsyncTotalCount() == null ? asyncTotalCount : pageBounds.getAsyncTotalCount();
// 查记录
Future<List> listFuture = call(new Callable<List>()
public List call() throws Exception
return (List)invocation.proceed();
, async);
// 查总数
if(pageBounds.isContainsTotalCount())
Callable<Paginator> countTask = new Callable()
public Object call() throws Exception
Integer count;
Cache cache = ms.getCache();
if(cache != null && ms.isUseCache() && ms.getConfiguration().isCacheEnabled())
CacheKey cacheKey = executor.createCacheKey(ms,parameter,new PageBounds(),copyFromBoundSql(ms,boundSql,dialect.getCountSQL(), boundSql.getParameterMappings(), boundSql.getParameterObject()));
count = (Integer)cache.getObject(cacheKey);
if(count == null)
count = SQLHelp.getCount(ms,executor.getTransaction(),parameter,boundSql,dialect);
cache.putObject(cacheKey, count);
else
count = SQLHelp.getCount(ms,executor.getTransaction(),parameter,boundSql,dialect);
return new Paginator(pageBounds.getPage(), pageBounds.getLimit(), count);
;
Future<Paginator> countFutrue = call(countTask, async);
return new PageList(listFuture.get(),countFutrue.get());
return listFuture.get();
// 这里可以同步 or 异步 去查
private <T> Future<T> call(Callable callable, boolean async)
if(async)
return Pool.submit(callable);
else
FutureTask<T> future = new FutureTask(callable);
future.run();
return future;
// ......
从源码看,这里支持同步或者异步去执行2个sql。然后通过Future.get()返回结果。
异步使用的pool线程池是
public void setPoolMaxSize(int poolMaxSize)
if(poolMaxSize > 0)
logger.debug("poolMaxSize: ", poolMaxSize);
Pool = Executors.newFixedThreadPool(poolMaxSize);
else
Pool = Executors.newCachedThreadPool();
至此,问题应该比较清楚了。Pool连接池线程终止后,数据库连接未释放,导致活跃数持续增长。
(为啥使用这个Pool线程池就会出现数据库连接未回收问题呢?我跟着源码 也没找到答案,o(╥﹏╥)o)
看网上很多类似的问题,但最后都是配置removeAbandoned=true就完了。但
RemoveAbandanded功能不建议在生产环境中使用,仅用于连接泄露检测诊断
4、其他
1、为啥以前就没出问题呢?
项目里面的mybatis.xml中配置的是:
<plugins>
<plugin interceptor="com.github.miemiedev.mybatis.paginator.OffsetLimitInterceptor">
<property name="dialectClass" value="com.github.miemiedev.mybatis.paginator.dialect.MySQLDialect"/>
<property name="asyncTotalCount" value="false"/>
</plugin>
</plugins>
asyncTotalCount=false,那为啥实际情况是使用的Pool线程池去异步执行的呢?
原来是依赖的一个二方包里面,包含了一个mybatis的配置文件,里面配置的asyncTotalCount为true,而且它先被先一步加载!
2、druid为什么不打印日志?
druid不依赖任何的log组件,但支持多种log组件,会检测当前环境,选择一种合适的log实现。选择日志的优先级依次是:
log4j > log4j2 > slf4j > commons-logging > jdk-logging
具体检测方法是尝试加载对应的class,如果加载成功就认为当前环境支持此种log组件,就使用它来处理日志打印。
如果想要指定特定的log组件,你可以通过JVM启动参数来配置,比如:
-Ddruid.logType=slf4j
-Ddruid.logType=log4j
-Ddruid.logType=log4j2
-Ddruid.logType=commonsLog
-Ddruid.logType=jdkLog
源码见:
// com.alibaba.druid.support.logging.LogFactory
public class LogFactory
private static Constructor logConstructor;
static
String logType= System.getProperty("druid.logType");
if(logType != null)
if(logType.equalsIgnoreCase("slf4j"))
tryImplementation("org.slf4j.Logger", "com.alibaba.druid.support.logging.SLF4JImpl");
else if(logType.equalsIgnoreCase("log4j"))
tryImplementation("org.apache.log4j.Logger", "com.alibaba.druid.support.logging.Log4jImpl");
else if(logType.equalsIgnoreCase("log4j2"))
tryImplementation("org.apache.logging.log4j.Logger", "com.alibaba.druid.support.logging.Log4j2Impl");
else if(logType.equalsIgnoreCase("commonsLog"))
tryImplementation("org.apache.commons.logging.LogFactory",
"com.alibaba.druid.support.logging.JakartaCommonsLoggingImpl");
else if(logType.equalsIgnoreCase("jdkLog"))
tryImplementation("java.util.logging.Logger", "com.alibaba.druid.support.logging.Jdk14LoggingImpl");
// 优先选择log4j,而非Apache Common Logging. 因为后者无法设置真实Log调用者的信息
tryImplementation("org.apache.log4j.Logger", "com.alibaba.druid.support.logging.Log4jImpl");
tryImplementation("org.apache.logging.log4j.Logger", "com.alibaba.druid.support.logging.Log4j2Impl");
tryImplementation("org.slf4j.Logger", "com.alibaba.druid.support.logging.SLF4JImpl");
tryImplementation("org.apache.commons.logging.LogFactory",
"com.alibaba.druid.support.logging.JakartaCommonsLoggingImpl");
tryImplementation("java.util.logging.Logger", "com.alibaba.druid.support.logging.Jdk14LoggingImpl");
if (logConstructor == null)
try
logConstructor = NoLoggingImpl.class.getConstructor(String.class);
catch (Exception e)
throw new IllegalStateException(e.getMessage(), e);
// ...
配置上启动参数后【-Ddruid.logType=slf4j】,有连接未正常关闭,就会打印如下日志:
2023-05-25 10:19:49.153 [TID:] [trace ] [userName ] [eid ] [Druid-ConnectionPool-Destroy-1392407412] ERROR com.alibaba.druid.pool.DruidDataSource - abandon connection, owner thread: pool-1-thread-2, connected at : 1684980819318, open stackTrace
at java.lang.Thread.getStackTrace(Thread.java:1559)
at com.alibaba.druid.pool.DruidDataSource.getConnectionDirect(DruidDataSource.java:1140)
at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4544)
at com.alibaba.druid.filter.logging.LogFilter.dataSource_getConnection(LogFilter.java:854)
at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4540)
at com.alibaba.druid.filter.stat.StatFilter.dataSource_getConnection(StatFilter.java:670)
at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4540)
at com.alibaba.druid.filter.FilterAdapter.dataSource_getConnection(FilterAdapter.java:2723)
at com.alibaba.druid.filter.FilterChainImpl.dataSource_connect(FilterChainImpl.java:4540)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1064)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:1056)
at com.alibaba.druid.pool.DruidDataSource.getConnection(DruidDataSource.java:104)
at org.springframework.jdbc.datasource.DataSourceUtils.doGetConnection(DataSourceUtils.java:111)
at org.springframework.jdbc.datasource.DataSourceUtils.getConnection(DataSourceUtils.java:77)
at org.mybatis.spring.transaction.SpringManagedTransaction.openConnection(SpringManagedTransaction.java:81)
at org.mybatis.spring.transaction.SpringManagedTransaction.getConnection(SpringManagedTransaction.java:67)
at com.github.miemiedev.mybatis.paginator.support.SQLHelp.getCount(SQLHelp.java:56)
at com.github.miemiedev.mybatis.paginator.OffsetLimitInterceptor$2.call(OffsetLimitInterceptor.java:105)
at java.util.concurrent.FutureTask.run$$$capture(FutureTask.java:266)
at java.util.concurrent.FutureTask.run(FutureTask.java)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
ownerThread current state is TERMINATED, current stackTrace
智能团队协作工具 Microsoft Teams服务增长惊人
Microsoft Teams 已经成为微软历史上增长速度最快的服务。今年4月底,Microsoft Teams的日活跃用户数量达到了7500万,相比较前一个月(4400万)增长惊人。当然3100万日活跃用户数量的增长很大程度上归功于本次疫情对远程办公的需求,而另一方面也表明微软过去两年对Teams的付出终于得到了回报。
Microsoft Teams将会成为下一个Windows。它将会成为一个超越操作系统的平台,规模会比Windows更大。是的,我们希望人们能够构建基于Teams的应用,在iOS、Android、Web、Mac以及Windows上运行。因此,按照这个定义,Teams最终将是一个更加无处不在的平台,随着时间的推移,它将成为一个更加无处不在的平台。它不会消除对Windows的需求,而且... 我们会看到强劲的增长,数亿人使用Teams。在某个时候,人们在在线会议上花费的时间比例一定会回落。所以,每天40亿分钟的会议时间,这将继续增长。但在某一时刻,这个数字会逐渐趋于平缓,因为如果可以当面开会的话,人们不想每天花8个小时在网上开会。但就用户而言,我非常看好这个数字会继续增长。
长按或扫描下面的二维码关注Linux公社
关注Linux公社,添加“星标”
每天获取技术干货,让我们一起成长
合作联系微信:kungfuyuyu
以上是关于druid活跃线程数量持续增长问题的主要内容,如果未能解决你的问题,请参考以下文章