[重读经典论文] FPN及PAN
Posted 大师兄的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[重读经典论文] FPN及PAN相关的知识,希望对你有一定的参考价值。
1. FPN
1.1. FPN简介
特征金字塔,全称Feature Pyramid Networks ,由Tsung-Yi Lin等2017年在论文《Feature Pyramid Networks for Object Detection》中提出,它的主要目标是解决在不同尺度上进行目标检测和分割时的信息丢失和分辨率不匹配的问题。FPN的框架可以总结为,为了在多尺度上建立高级语义特征映射(high-level semantic feature maps at all scales),一种带有横向连接(lateral connections)的自上而下的(topdown architecture)的框架。
1.2. 金字塔框架介绍

如上图所示,识别不同尺度的物体是计算机视觉的一个基本挑战,论文列举了几种不同的实现方式。
(a)是图像金字塔,在传统图像处理算法中用得比较多,就是将图片resize到不同的大小,然后分别得到对应大小的特征,然后进行预测。这种方法虽然可以一定程度上解决多尺度的问题,但是很明显,带来的计算量也非常大。
(b) 使用单个feature map进行检测,这种结构在17年的时候是很多人在使用的结构,比如YOLOv1、YOLOv2、Faster R-CNN中使用的就是这种架构。直接使用这种架构导致预测层的特征尺度比较单一,对小目标检测效果比较差。
(c) 像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量,但是不同的层次的特征图有巨大的语义差距,高分辨率的特征图只有低级特征,损害了表示能力,不利于目标识别。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
(d) 经典FPN架构,通过自上而下和自下而上的路径来构建特征金字塔。自下而上的路径是指从底层特征图开始,通过下采样操作逐渐减小特征图的分辨率,同时增加其语义信息。自上而下的路径是指从顶层特征图开始,通过上采样操作逐渐增加特征图的分辨率,还引入了横向连接,用于在自上而下和自下而上的路径之间传递信息,高层特征图通过1x1卷积进行降维后与低层特征图进行融合,以产生具有更好分辨率和语义信息的金字塔特征。
1.3. 细节

如上图所示,一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少feature map通道数和向下的路径匹配。
自底向上其实就是网络的前向过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。本论文用ResNet作为backbone,将每个stage的输出命名为Ci,i代表是bacbone中的哪个stage,如论文采用C2,C3,C4,C5对应的下采样的倍数为4,8,16,32,因为考虑到内存占用,没用到C1。
自顶向下的过程采用上采样(upsampling)进行,而横向连接则是将上采样(一般用简单的最近邻插值)的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。
1.4. 基于FPN的Faster Rcnn

如上图所示,Ci为上面提到的每个res stage的输出,在C2到C5之间做融合,产生P2到P5,然后P5再通过最大池化下采样为P6。
1.5. 总结
为什么FPN采用融合以后效果要比使用pyramidal feature hierarchy(ssd中采用的)这种方式要好呢,知乎上有个总结[1]:
- 卷积虽然能够高效地向上提取语义,但是也存在像素错位问题,通过上采样还原特征图的方式很好地缓解了像素不准的问题。
- backbone可以分为浅层网络和深层网络,浅层网络负责提取目标边缘等底层特征,而深层网络可以构建高级的语义信息,通过使用FPN这种方式,让深层网络更高级语义的部分的信息能够融合到稍浅层的网络,指导浅层网络进行识别。
- 从感受野的角度思考,浅层特征的感受野比较小,深层网络的感受野比较大,浅层网络主要负责小目标的检测,深层的网络负责大目标的检测,FPN中的top-down之路通过融合不同感受野,能够让高层加强低层所对应的感受野。
实际上FPN Pi层的融合这里采用了add,后面还有各种变种是采用按通道concat。在这之后,几乎所有的检测算法都会采用FPN架构。
2. PAN
2.1. PAN简介
PAN(Path Aggregation Network),Shu Liu等在2018年《Path Aggregation Network for Instance Segmentation》中提出,它扩展了FPN的思想并改进了特征融合的方法。
FPN使用横向连接将高层特征图与低层特征图进行融合,但这种简单的融合方法可能会导致信息的不完整性,尤其是对于小目标或细节部分。PAN的主要目标是解决FPN在特征融合过程中可能存在的信息丢失和不完整的问题,主要是通过融合高低层特征提升目标检测的效果,尤其可以提高小尺寸目标的检测效果。
2.2. PAN框架介绍

如上图所示,为PAN的网络架构。包括以下部分:
- FPN(这个已经有了,不算论文的贡献)。
- Bottom-Up Path Augmentation。
- Adaptive Feature Pooling。
- Fully-Connected Fusion。
2.3. 细节
2.3.1. Bottom-up Path Augmentation
Bottom-up Path Augemtation的提出主要是考虑到网络的浅层特征对于实例分割非常重要,因此,为了保留更多的浅层特征,论文引入了Bottom-up Path Augemtation。
在框架图Figure1 中红色的箭头自底向上的过程,浅层的特征传递到顶层需要经过几十个甚至上百个网络层(如backbone采用ResNet50或者101),因此经过这么多层传递之后,浅层的特征信息丢失就会比较严重。
绿色的箭头表作者添加了一个Bottom-up Path Augemtation结构,这个结构本身不到10层,这样浅层特征经过原始FPN中的横向连接到P2然后再从P2沿着Bottom-up Path Augemtation传递到顶层,经过的层数不到10层,能较好的保存浅层特征信息。注意,这里的N2和P2表示同一个特征图。 但N3,N4,N5和P3,P4,P5不一样,实际上N3,N4,N5是P3,P4,P5融合后的结果。
如下图所示是Bottom-up Path Augemtation的基本结构,这个是个常规的特征融合操作,Ni经过一个卷积核尺寸为3*3,步长为2的卷积层,特征尺寸减半,然后与粗粒度特征Pi+1相加,得到的特征图再经过一个卷积核尺寸为3*3,步长为1的卷积层,得到Ni+1。

2.3.2. Adaptive Feature Pooling

主要做的还是特征融合,我们知道在Faster RCNN系列的目标检测或分割算法中,RPN网络得到的ROI需要经过ROI Pooling或ROI Align提取ROI特征,这一步操作中每个ROI所基于的特征都是单层特征(FPN也是如此),比如ResNet网络中常用的res5的输出。而adaptive feature pooling则是将单层特征也换成多层特征,也就是说每个ROI需要和多层特征(文中是4层)做ROI Align的操作,然后将得到的不同层的ROI特征融合在一起,这样每个ROI特征就融合了多层特征。后续的分类和回归都是基于此最终的特征进行。
2.3.3. Fully-Connected Fusion

如上图所示,这是对原有的分割支路(FCN)引入一个前景二分类的全连接支路,通过融合这两条支路的输出得到更加精确的分割结果。主要是在原始的Mask支路(即带deconv那条支路)的基础上增加了下面那个支路做融合。增加的这个支路包含2个3*3 的卷积层,然后接一个全连接层,再经过reshape操作得到维度和上面支路相同的前背景Mask,即是说下面这个支路做的就是前景和背景的二分类,输出维度类似于文中说的28*28*1 。而上面的支路输出维度类似28*28*K ,其中K 代表数据集目标类别数。最终,这两条支路的输出Mask做融合以获得更加精细的最终结果。
3. 参考
[1] Feature Pyramid Network解读和理解
[2] 1.1.2 FPN结构详解
[3] FPN(feature pyramid networks)算法讲解
[4] PANet算法笔记
[5] 【CV中的特征金字塔】四,CVPR 2018 PANet
(完)
[重读经典论文]ResNext
1. 前言
ResNeXt是由何凯明团队在论文《Aggregated Residual Transformations for Deep Neural Networks》提出来的新型图像分类网络。
ResNeXt是ResNet的升级版,在ResNet的基础上,引入了cardinality的概念,其实本质上就是将Res模块中的卷积分支换成分组卷积,然后探索分组卷积的最佳组数(C)和每个分组的卷积核个数(d),通过改进resnet网络,通过各种消融实验,得出了最佳的模型结构。
在ILSVRC 2016分类竞赛中Top5错误率达到3.03%,获得亚军。
2. 解决什么问题
作者首先提出现在随着深度学习的发展,CV已经由原来的“特征工程”转为“网络工程”了,架构越来越复杂,超参数也越来越多。然后提到Inception网络,虽然迭代了很多次,但是终究可以归纳为一个模式:split-transform-merge。
然后踩了一下Inception,就是它太复杂了,人工设计的成分太大了,有太多超参要调,也不见得能适应新的数据和任务。
然后,分析了神经网络的标准范式就符合这样的split-transform-merge模式。以一个最简单的普通神经元为例(比如FC中的每个神经元):

将输入X拆分(splitting)到个一个低维的嵌入,也就是一维的子空间xi,然后对这些低维的表示进行转换(transforing),也就是乘以wi,最后再将结果进行聚合求和(aggregating),这个过程可以用以下公式表示:

由此归纳出神经网络的一个通用的单元可以用如下公式表示:

结合ResNet的identity映射,带residual的结构可以用如下公式表示:

上面的变换T可以是任意形式,在这篇文章中每个分支的拓扑结构T都是一样的, 一共有C个独立的变换,作者将C称之为基数,并且指出,基数C对于结果的影响比宽度和深度更加重要,而且这样的结构易于拓展。
3. 什么是分组卷积
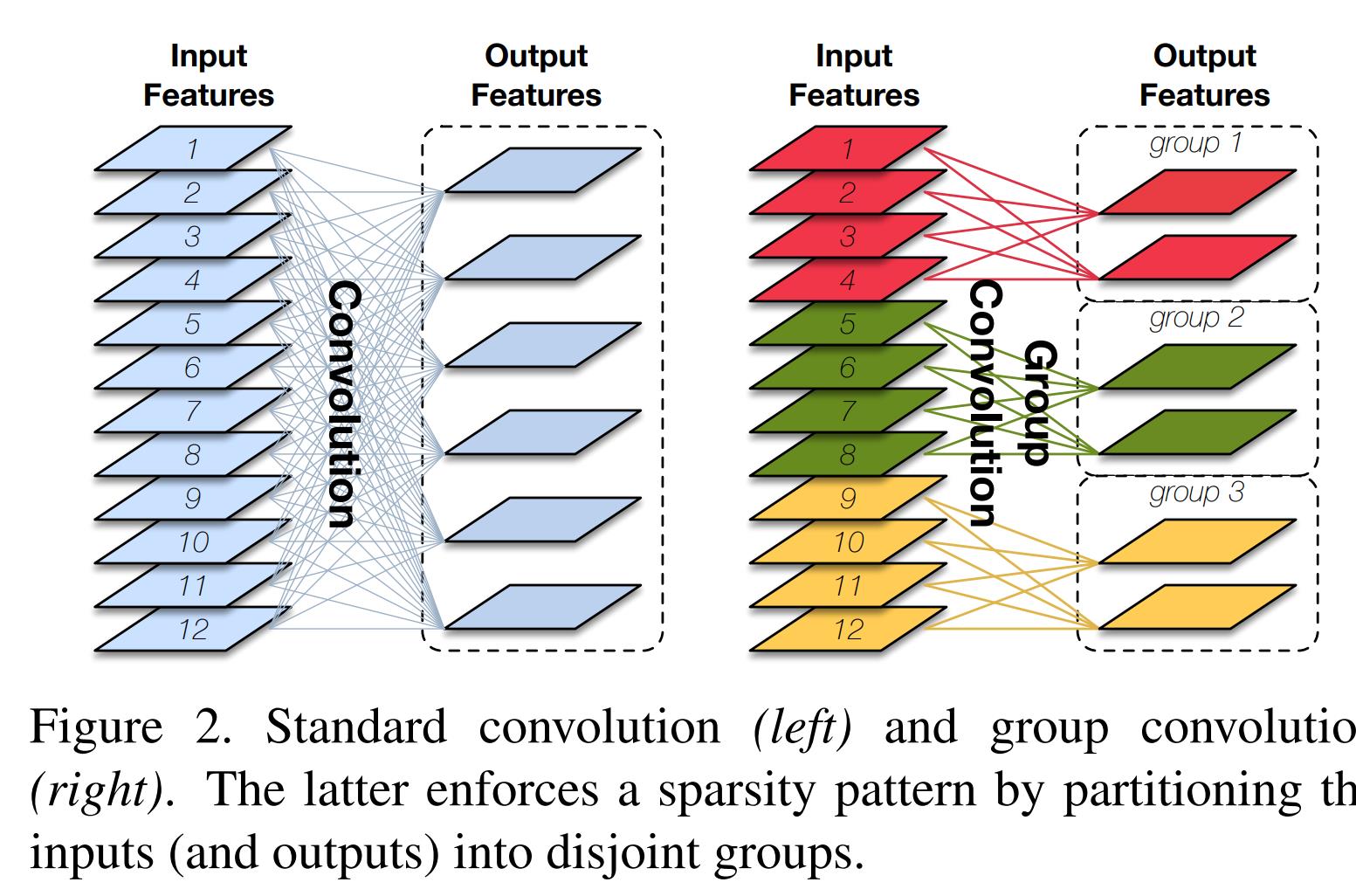
如上图所示,左边是普通的卷积,一个卷积核需要处理输入的所有通道,输入为12通道,则卷积核的形状为k*k*12;右边则为分组卷积,如图右所示,将输入分为三组,每组有4个通道,每组的卷积核只需要处理当组的输入即可,则卷积核的形状为k*k*4。
归纳来说,假如输入的通道为Cin,卷积后的输出通道为n,则
普通卷积,卷积核的形状为k*k*Cin,需要输出n个通道,则需要n个卷积核,因此参数量为k*k*Cin*n;
分组卷积:分组数为g,则卷积核的形状为k*k*Cin/g,输出n个通道,则每个分组输出n/g个通道,每组需要n/g个卷积核,则参数量为(k*k*Cin/g*n/g)*g,化简为k*k*Cin*n*1/g,为普通卷积的1/g倍。

因此,分组的卷积的明显优点是降低了参数量与计算,减少内存占用,加快推断速度。
缺点也很明显,分组卷积的组和组之间是没有信息交流的,会导致类型近亲繁殖的现象,无法更好提取特征,导致性能下降。
4. ResNext模块结构

如上图所示,图左为原始的Resnet结构基本结构,右边是ResNext的基本机构,作者在设计模块的时候遵循了两点原则:
- 如果输入输出的尺寸是一样的,则这些模块的超参都是一样的(宽度和filter尺寸)。
- 如果输出尺寸减半的时候,通道翻倍。
其实也就是Vgg和ResNet的规则。
可以看到,旁边的residual connection就是公式中的x直接连过来,然后剩下的是32组独立的同样结构的变换,最后再进行融合,符合split-transform-merge的模式。
作者进一步指出,split-transform-merge是通用的神经网络的标准范式,前面已经提到,基本的神经元符合这个范式,而如下图所示:

上面这三个模块其实是等价的,最后出于实现的简易性选择了上图中的c模块,即分组卷积,可以知道中间的模块,分了32组,由于输出的通道数为128,因此每组的卷积核个数为4。
5. 网络结构
作者在ResNet的基础上进行修改,将每个stage替换成分组卷积,其中32代表ResNext模块中的第二个卷积的分组数为32组,每一组的卷积核的个数为4个,如下表所示:

可以看到两个网络的参数和计算量都差不多,但是在后面的测试中,ResNext性能更好:

上表也是作者对C和分组数量d进行的消融实验,可以发现随着C提高,性能也逐渐提高,权衡参数量和计算复杂度,最后选择了32x4d的组合。
后面还试着把block的残差连接去掉,发现性能严重下降,为了说明残差能够真正帮助网络进行学习,不是没有的(diss 了InceptionV4那篇论文)。
6. 总结
总的来说,本文总结了Inception和ANN的结构,从很高的逼格上提出了split-transform-merge这么一种范式,并基于这种范式提出一种相同拓扑多分支的结构,并归纳为分组卷积的模式,简洁、高效,易于调试。
7. 参考
[1] 6.1.2 ResNeXt网络结构
[2] 深度学习——分类之ResNeXt
(完)
以上是关于[重读经典论文] FPN及PAN的主要内容,如果未能解决你的问题,请参考以下文章