Python中的编码
Posted mrzysv5
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python中的编码相关的知识,希望对你有一定的参考价值。
编码中的相关术语
- ACR Abstract Character Repertoire
- the set of characters to be encoded, for example, some alphabet or symbol set
- CCS Coded Character Set
- a mapping from an abstract character repertoire to a set of nonnegative integers
- CEF Character Encoding Form
- a mapping from a set of nonnegative integers that are elements of a CCS to a set of sequences of particular code units of some specified width, such as 32-bit integers
- CES Character Encoding Scheme
- a reversible transformation from a set of sequences of code units (from one or more CEFs to a serialized sequence of bytes)
- Code Point Nonnegative integer in the CCS
- Code Unit The minimal bit combination that can represent a unit of encoded text for processing or interchange. The Unicode Standard uses 8-bit code units in the UTF-8 encoding form, 16-bit code units in the UTF-16 encoding form, and 32-bit code units in the UTF-32 encoding form
对于汉字,使用unicode编码字符集,这样就可以得到每个中文字符对于的码点(code point)。然后选择使用UTF-8字符编码表,这样就确定了每个码点对应的码元(code unit)。最终使用UTF-8字符编码格式,将码元编码成字节序列。
比如中文字符汉,它的unicode码点是U+6C49,因为UTF-8的码元是8位,对于U+6C49,需要使用3个字节(24位)来进行编码,最终编码为11100110 10110001 10001001。
根据UTF-8编码规则,取第一个字节的后4位,取第二个字节的后6位,取第三个字节的后6位,得到0110 110001 001001,将其转位16进制刚好就是6C49。
Unicode
Unicode根据字符的使用频率将字符划分到17个平面中,每个平面有216=65536个码点,所以一共有17 * 216 = 1,114,112码点。图1为Unicode平面,图2为Basic Multilingual Plane(第0个平面),也是最常用的平面。
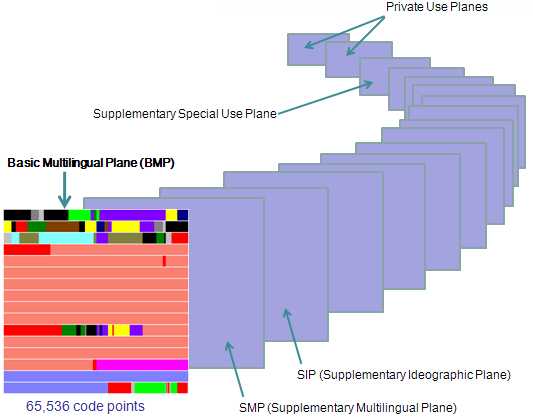
图1:Unicode平面
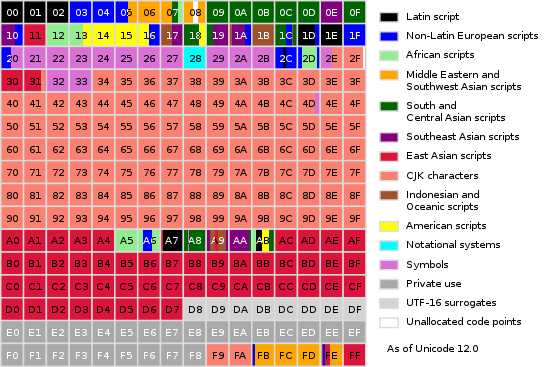
图2:Basic Multilingual Plane
前面提到的汉的码点为U+6C49,我们可以在图2中发现,是符合CJK(中日韩统一表意文字)字符的码点范围的。
UTF-8
在前面提及UTF-8的时候,强调了UTF-8字符编码表(CEF)和UTF-8字符编码格式(CES)。在没有限定条件下,可以使用UTF-8模糊这两个概念。但是实际上还是有区别的:
It is important not to confuse a Character Encoding Form (CEF) and a CES.
- The CEF maps code points to code units, while the CES transforms sequences of code units to byte sequences. (For a direct mapping from characters to serialized bytes, see Section 6 Character Maps.)
- The CES must take into account the byte-order serialization of all code units wider than a byte that are used in the CEF.
- Otherwise identical CESs may differ in other aspects, such as the number of user-defined characters allowed. (This applies in particular to the IBM CDRA architecture, which may distinguish host CCSIDs based on whether the set of UDC‘s is conformably convertible to the corresponding code page or not.)
UTF-8 是一种变长的编码方式,一般用 1~4 个字节序列来表示 Unicode 字符,也是目前应用最广泛的一种 Unicode 编码方式,但是它不是最早的 Unicode 编码方式,最早的 Unicode 编码方式是 UTF-16。UTF-8 编码算法有以下特点:
- 首字节码用来区分采用的编码字节数,如果首字节以 0 开头,表示单字节编码;如果首字节以 110 开头,表示双字节编码;如果首字节以 1110 开头,表示三字节编码,以此类推
- 除了首字节码外,用 10 开头表示多字节编码的后续字节
- 与 ASCII 编码方式完全兼容:U+0000 到 U+007F 范围内(十进制为 0~127)的 Unicode 码点值所对应的字符就是 ASCII 字符集中的字符,用一个字节表示,编码方式和 ASCII 编码一致
- 无字节序,在 UFT-8 编码格式的文本中,如果添加了 BOM,则标示该文本是由 UTF-8 编码方式编码的,而不用来说明字节序

图3:UTF-8编码方式
UTF-16和US-2
UTF-16 是最早的 Unicode 字符集编码方式,在概述 UTF-16 之前,需要解释一下 USC-2 编码方式,他们有源远流长的关系,UTF-16 源于 UCS-2。UCS-2 将字符编号(同 Unicode 中的码点)直接映射为字符编码,亦即字符编号就是字符编码,中间没有经过特别的编码算法转换。
UCS-2 编码方式只覆盖基本多语言平面的码点,因为 16 位二进制表示的最大值为 0xFFFF,而对于增补平面中的码点(范围为 0x10000~0x10FFFF,十进制为 65536~1114111),两字节的 16 位二进制是无法表示的。为了解决这个问题,The Unicode Consortium 提出了通过代理机制来扩展原来的 UCS-2 编码方式,也就是 UTF-16。
所以扩展UCS-2,采用代理对(surrogate pair)对unicode编码:用两个基本平面中未定义字符的码点合起来为增补平面中的码点编码,基本平面中这些用作"代理"的码点区域就被称之为"代理区(Surrogate Zone)",其码点编号范围为 0xD800~0xDFFF(十进制 55296~57343),共 2048个码点。代理区的码点又被分为高代理码点和低代理码点,高代理码点的取值范围为 0xD800~0xDBFF,低代理码点的取值范围为 0xDC00~0xDFFF,高代理码点和低代理码点合起来就是代理对,刚好可以表示增补平面内的所有码(1024 * 1024)。
UTF-32和US-4
UTF-32 是一个以固定四字节编码方式,ISO 10646 中称其为 UCS-4 的编码机制的子集。优点是每一个 Unicode 码点都和 UTF-16 的 Code Unit 一一对应,程序中如果采用 UTF-32 处理起来比较简单,但是所有的字符都用四个字节,特别浪费空间,所以实际上使用比较少。
Python2.x的unicode
相同的代码,在Centos6.5和Windows10系统中执行的结果却不一样。
Centos6.5:
# python
Python 2.7.5 (default, Apr 11 2018, 07:36:10)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-28)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> re.compile(u'[U0001F300-U0001F64F]', re.UNICODE)
<_sre.SRE_Pattern object at 0x7f337690c588>
>>> Windows10:
> python
Python 2.7.15 (v2.7.15:ca079a3ea3, Apr 30 2018, 16:30:26) [MSC v.1500 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> re.compile(u'[U0001F300-U0001F64F]', re.UNICODE)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "D:Temp oolsvenv_devlib
e.py", line 194, in compile
return _compile(pattern, flags)
File "D:Temp oolsvenv_devlib
e.py", line 251, in _compile
raise error, v # invalid expression
sre_constants.error: bad character rangePyUnicodeObject
在源码中,PyUnicodeObject的结构:
typedef struct {
PyObject_HEAD
Py_ssize_t length; /* Length of raw Unicode data in buffer */
Py_UNICODE *str; /* Raw Unicode buffer */
long hash; /* Hash value; -1 if not set */
PyObject *defenc; /* (Default) Encoded version as Python
string, or NULL; this is used for
implementing the buffer protocol */
} PyUnicodeObject;unicode的值保存在Py_UNICODE中,官方文档的解释:
This type represents the storage type which is used by Python internally as basis for holding Unicode ordinals. Python’s default builds use a 16-bit type for Py_UNICODE and store Unicode values internally as UCS2. It is also possible to build a UCS4 version of Python (most recent Linux distributions come with UCS4 builds of Python). These builds then use a 32-bit type for Py_UNICODE and store Unicode data internally as UCS4. On platforms where wchar_t is available and compatible with the chosen Python Unicode build variant, Py_UNICODE is a typedef alias for wchar_t to enhance native platform compatibility. On all other platforms, Py_UNICODE is a typedef alias for either unsigned short (UCS2) or unsigned long (UCS4).
在Windows10中,默认使用US-2,所以在编译正则表达式的时候将[U0001F300-U0001F64F]转换为[ud83cudf00-ud83dude4f],解析正则表达式的时候:
...
if sourcematch("-"):
# potential range
this = sourceget()
if this == "]":
if code1[0] is IN:
code1 = code1[1][0]
setappend(code1)
setappend((LITERAL, ord("-")))
break
elif this:
if this[0] == "\\":
code2 = _class_escape(source, this, nested + 1)
else:
code2 = LITERAL, ord(this)
if code1[0] != LITERAL or code2[0] != LITERAL:
raise error, "bad character range"
lo = code1[1]
hi = code2[1]
if hi < lo:
raise error, "bad character range"
setappend((RANGE, (lo, hi)))
...这里的lo是udf00,hi是ud83d,因此hi<lo,也就是这个范围是不合法的。所以报错了。
而在Centos6.5中,默认使用US-4编码,所以就是[U0001F300-U0001F64F],这当然是一个合法的范围。
参考
- Unicode 及编码方式概述
- UNICODE CHARACTER ENCODING MODEL
- Emoji的编码以及常见问题处理
- [python]去掉 unicode 字符串前面的 u
- PEP 261 -- Support for "wide" Unicode characters
以上是关于Python中的编码的主要内容,如果未能解决你的问题,请参考以下文章
markdown 打字稿...编码说明,提示,作弊,指南,代码片段和教程文章
在 Python 多处理进程中运行较慢的 OpenCV 代码片段