杂文重新审视 ViT 中的 Token 表示
Posted 废 物 回 收 站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了杂文重新审视 ViT 中的 Token 表示相关的知识,希望对你有一定的参考价值。
Transformer专题Vision Transformer(ViT)原理 + 代码
目录
前言
Vision Transformer是第一篇Transformer在CV领域的应用,论文地址:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
在视觉任务中,主要是利用到了Transformer中的Encoder模块,所以下面主要是关注这个模块。
我主要是看这个UP主学的:VIT (Vision Transformer) 模型论文+代码(源码)从零详细解读,看不懂来打我 他的Transformer系列讲的挺好的。
一、Transformer的Encoder
如果对Transformer理论不了解的可以看我的上一篇博客:【Transformer专题】一、Attention is All You Need(Transformer)
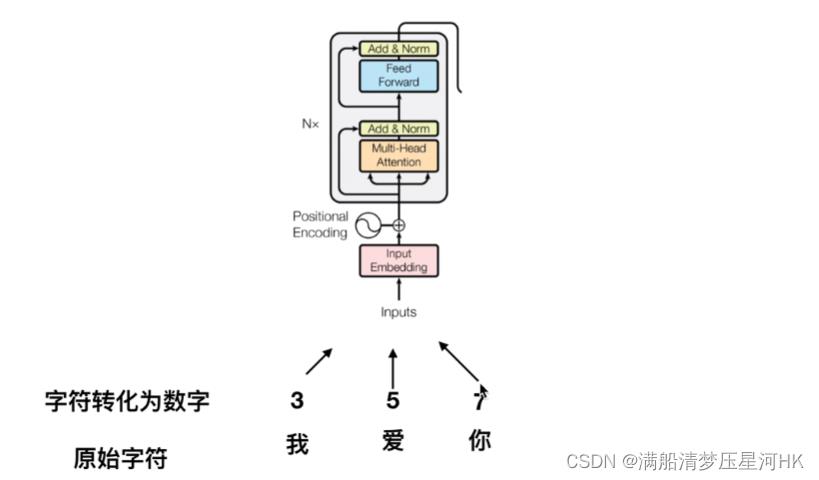
如下图所示:
Encode的输入:原始字符转换为数字,再转换为向量Input Embedding再和位置编码Positional Encoding对应位置相加,就得到了最终Encoder的输入。
Encoder = 多头注意力 + Add & Norm + Feed Forward(2个全连接层) + Add & Norm
那么怎么把一张图片融入到这个编码器Encoder当中呢?直观是想法:把图片的每一个像素都拿出来,组成一个词向量,再个对应的位置编码相加,不就把一张图片送入Encoder了吗?
但是这样子会产生一个复杂度的问题:假设一张图片的输入是224x224,那么序列长度 = 224 * 224,参数量和计算量就太大了。
解决办法:把整张图片切分为一个个的patch,现在是一大块像素作为一个token(patch和token可以理解为一个东西):
二、ViT整体架构
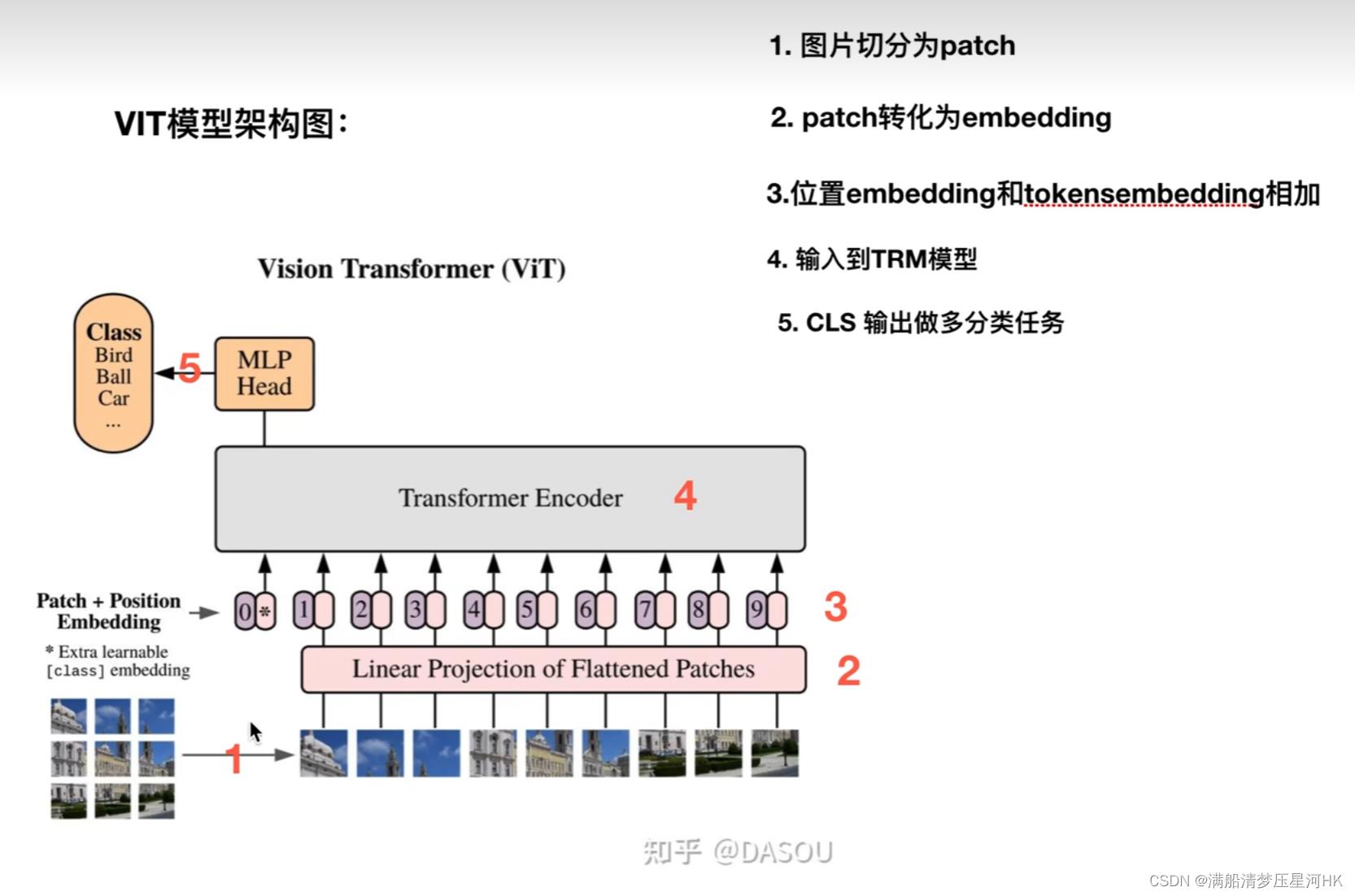
如图为整个ViT的架构,分为5个部分:
- 将图片切分为一个个的Token
- 将Token转化为Token Embedding
- 将Token Embedding 和 Position Embedding对应位置相加
- 输入到Transformer Encoder中
- Cls输出做多分类任务
三、ViT的输入部分
3.1、图片切分为Token
输入x = [bs,3,224,224]
比如一张224x224x3的图片,切分为16x16个token,每个token是14x14大小,得到16x16x3=768个token。
3.2、Token转换为Token Embedding
- 将一个16x16x3=768个Token拉直,拉到一个1维,长度为768的向量 -> [bs,196,768];
- 接一个Linear层,把768映射到Transormer Encode规定的Embedding Size(1024)的长度 -> [bs,196,1024];
3.3、Token Embedding和Position Embedding对应位置相加
- 生成一个Cls对应的Token Embedding(对应图中的*部分) -> [bs,1,1024];
- 生成所有序列的位置编码(包括Cls符号和和所有Token Embeding的位置编码 对应图中的0-9) -> [bs,197,1024];
- 将Token Embedding和Position Embedding对应位置相加 -> [bs,197,1024];
问题1:为什么要加一个Cls的符号呢?
Cls是在Bert中的用到的一个符号,NLP任务中的Cls可以在一定程度上让bert的两个任务保持一定的独立性,而在ViT中只有一个多分类任务,所以Cls符号并不是必须的;
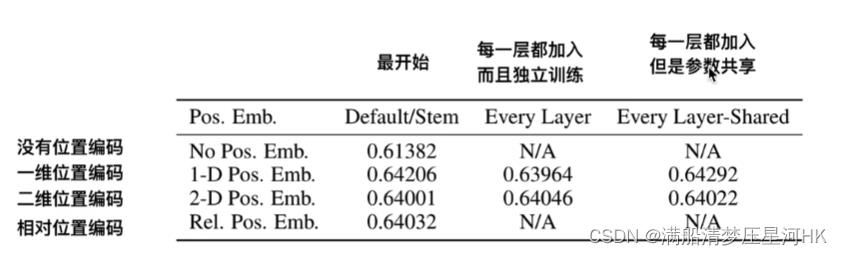
而论文作者也做了实验证明了这点,在ViT的任务中,加Cls和不加Cls训练效果是差不多的,所以我认为可以不用;
问题2:为什么需要位置编码?
RNN在计算的时候是一个个的运算,具有一种天然时序关系,可以告诉模型哪些单词在前面,哪些单词在后面;但是在Transformer中它的单词是一起输入进去的,然后经过Attention层,那么如果没用位置编码,模型并不知道哪些单词在前面哪些单词在后面。所以,我们需要给模型一个位置信息,告诉模型,哪些词/哪个token在前面,哪些词/token在后面。
问题3:为什么Token Embedding和Position Embedding是相加的?可不可以Concat?
这个问题好像没用什么很好的答案,Concat会让计算量翻倍?从论文的实验结果可以发现,加入位置编码可以加3个点左右。位置编码是有用的。
四、Encoder部分
Encoder 输入:[bs,197,1024]
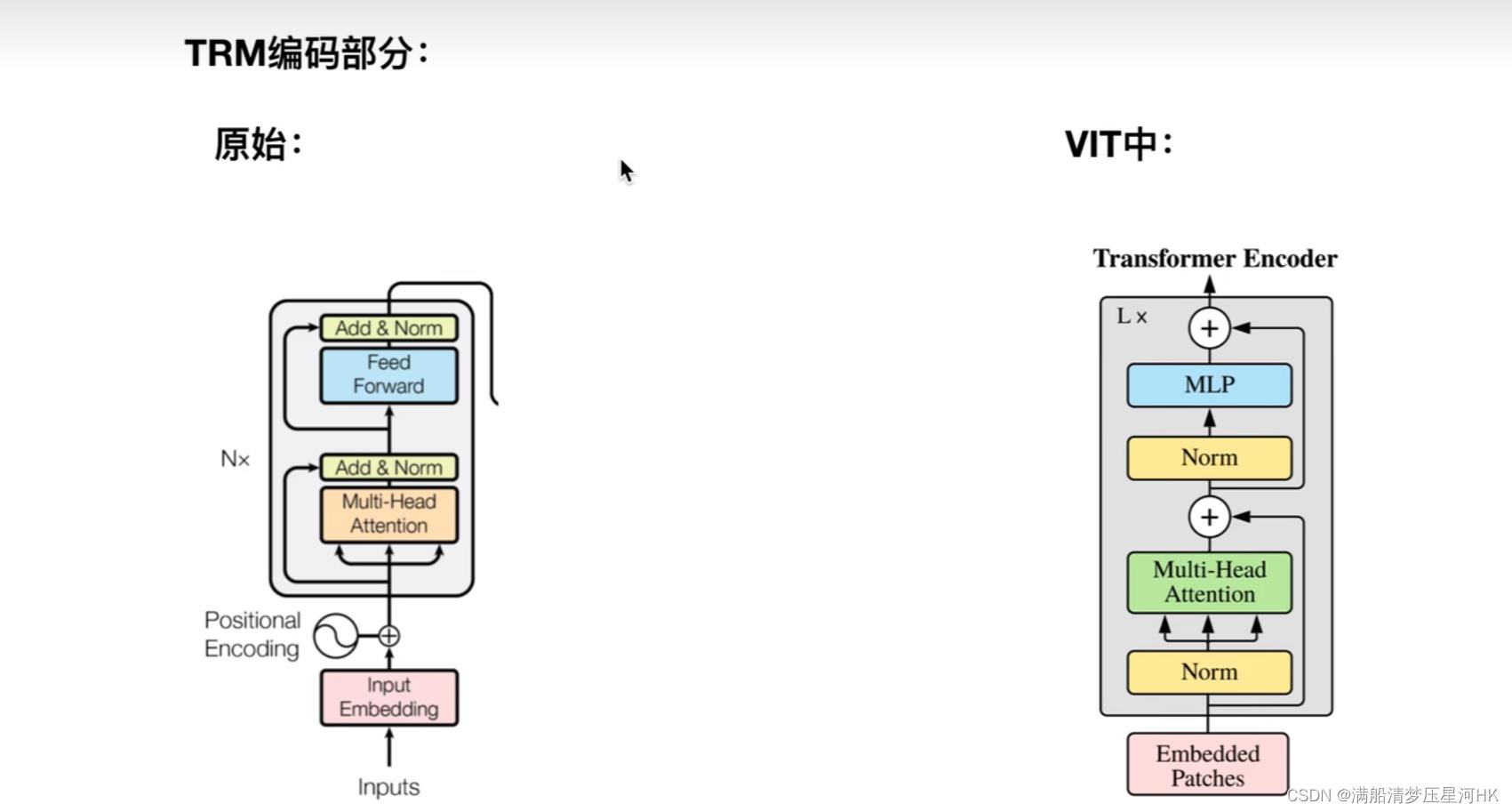
Transformer和ViT中的Encoder部分的区别:
- 把Norm层提前了;
- 没用Pad符号;
Encoder 输出:[bs,197,1024]五、CLS多分类输出
最终得到每一个token都会得到一个1024的输出,再把第一个1024的向量拿出来,接一个全连接层进行多分类。
[bs,197,1024] -> 拿第一个[bs,1024] -> [bs,num_classes]六、代码讲解
## from https://github.com/lucidrains/vit-pytorch import torch from torch import nn from einops import rearrange, repeat from einops.layers.torch import Rearrange def pair(t): return t if isinstance(t, tuple) else (t, t) class PreNorm(nn.Module): # 在执行fn之前执行一个Layer Norm def __init__(self, dim, fn): super().__init__() self.norm = nn.LayerNorm(dim) self.fn = fn def forward(self, x, **kwargs): return self.fn(self.norm(x), **kwargs) class FeedForward(nn.Module): def __init__(self, dim, hidden_dim, dropout = 0.): super().__init__() # 前馈神经网络 = 2个全连接层 self.net = nn.Sequential( nn.Linear(dim, hidden_dim), nn.GELU(), nn.Dropout(dropout), nn.Linear(hidden_dim, dim), nn.Dropout(dropout) ) def forward(self, x): return self.net(x) class Attention(nn.Module): def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.): super().__init__() inner_dim = dim_head * heads project_out = not (heads == 1 and dim_head == dim) self.heads = heads self.scale = dim_head ** -0.5 # 缩放因子 self.attend = nn.Softmax(dim = -1) self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False) self.to_out = nn.Sequential( nn.Linear(inner_dim, dim), nn.Dropout(dropout) ) if project_out else nn.Identity() def forward(self, x): # x: [bs, 197, 1024] 197 = 1个Cls + 196个patch 1024就是每一个patch需要转为1024长度的向量 # self.to_qkv(x)将x向量映射到长度为1024*3 # chunk: qkv 最后是一个元祖,tuple,长度是3,每个元素形状:[1, 197, 1024] # 直接用x配合一个Linear生成qkv,再切分为3块 qkv = self.to_qkv(x).chunk(3, dim = -1) # 再把qkv分别拆分开来 # q: [1, 16, 197, 64] k: [1, 16, 197, 64] v: [1, 16, 197, 64] q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv) # q * k转置 除以根号d_k dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale # softmax得到每个token对于其他token的attention系数 attn = self.attend(dots) # * v [1, 16, 197, 64] out = torch.matmul(attn, v) # [1, 197, 1024] out = rearrange(out, 'b h n d -> b n (h d)') return self.to_out(out) class Transformer(nn.Module): def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.): super().__init__() self.layers = nn.ModuleList([]) for _ in range(depth): # 堆叠多个Encoder depth个 self.layers.append(nn.ModuleList([ # 每个encoder = Attention(Multi-Head Attention) + FeedForward(MLP) # PreNorm:指在fn(Attention/FeedForward)之前执行一个Layer Norm PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)), PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout)) ])) def forward(self, x): for attn, ff in self.layers: x = attn(x) + x x = ff(x) + x return x class ViT(nn.Module): def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.): super().__init__() image_height, image_width = pair(image_size) # 224*224 patch_height, patch_width = pair(patch_size) # 16 * 16 assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.' num_patches = (image_height // patch_height) * (image_width // patch_width) # 得到多少个token 14x14=196 patch_dim = channels * patch_height * patch_width # 3x16x16 = 768 patch展平后的维度 assert pool in 'cls', 'mean', 'pool type must be either cls (cls token) or mean (mean pooling)' self.to_patch_embedding = nn.Sequential( Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width), # 把所有的patch拉平->768维 nn.Linear(patch_dim, dim), # 映射到encoder需要的维度768->1024 ) self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim)) # 生成所有token和Cls的位置编码 self.cls_token = nn.Parameter(torch.randn(1, 1, dim)) # 生成Cls的初始化参数 self.dropout = nn.Dropout(emb_dropout) # embedding后面一般会接的一个Dropout self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout) # encoder self.pool = pool self.to_latent = nn.Identity() self.mlp_head = nn.Sequential( # CLS多分类输出部分 nn.LayerNorm(dim), nn.Linear(dim, num_classes) ) def forward(self, img): # img: [1, 3, 224, 224] x = [1, 196, 1024] # 生成每张图片的Patch Embedding # 图片的每一个通道切分为Token + 将3个channel的所有Token拉直,拉到一个1维,长度为768的向量 + 接一个线性层映射到encoder需要的维度768->1024 x = self.to_patch_embedding(img) b, n, _ = x.shape # b = 1 n = 196 # 为每张图片生成一个Cls符号 [1, 1, 1024] cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b) # [1, 197, 1024] 将每张图片的Cls符号和Patch Embedding进行拼接 x = torch.cat((cls_tokens, x), dim=1) # 初始化位置编码 再和(Cls和Patch Embedding)对应位置相加 x += self.pos_embedding[:, :(n + 1)] # embedding后接一个Dropout x = self.dropout(x) # 将最终的Embedding输入Encoder x: [1, 197, 1024] -> [1, 197, 1024] x = self.transformer(x) # self.pool = 'cls' 所以取第一个输出直接进行多分类 [1, 1024] x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0] x = self.to_latent(x) # 恒等映射 [1, 1024] # Cls Head 多分类 [1, cls_num] return self.mlp_head(x) if __name__ == '__main__': v = ViT( image_size=224, # 输入图像的大小 patch_size=16, # 每个token/patch的大小16x16 num_classes=1000, # 多分类 dim=1024, # encoder规定的输入的维度 depth=6, # Encoder的个数 heads=16, # 多头注意力机制的head个数 mlp_dim=2048, # mlp的维度 dropout=0.1, # emb_dropout=0.1 # embedding一半会接一个dropout ) img = torch.randn(1, 3, 224, 224) preds = v(img) # (1, 1000)Reference
VIT (Vision Transformer) 模型论文+代码(源码)从零详细解读,看不懂来打我
以上是关于杂文重新审视 ViT 中的 Token 表示的主要内容,如果未能解决你的问题,请参考以下文章
Transformer专题Vision Transformer(ViT)原理 + 代码
看源码,重新审视Spring Security中的角色(roles)是怎么回事
后Taproot时代:重新审视比特币在多链格局中的定位与叙事 |链捕手