认识LightDB
Posted 滞人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了认识LightDB相关的知识,希望对你有一定的参考价值。
认识LightDB - 高可用安装
LightDB 是恒生电子股份有限公司开发的一款关系型数据库,基于 PostgreSQL 生态。
LightDB 分为 lightdb-x 与 lightdb-a 两款产品,-a 是基于 Greeplum 开发的,适用于 OLAP 场景,不太适合日间实时交易。本文若不进行特殊说明,所有 LightDB 都指的是 lightdb-x 。
综述
安装文档:http://www.light-pg.com/docs/LightDB_Install_Manual/current/index.html
LightDB 主要有三种部署方式:单机、高可用、分布式。LightDB 自带了命令行和 GUI 的安装程序,大大简化了安装过程。不过安装过程中仍有一些需要注意的点。
本文档基于 LightDB 13.8-23.1 版本编写。
安装要点
官网的安装过程已经十分清晰,这里只提一些要注意的点。
- 要求 lightdb 用户 sudo 免密码,应使用 root 运行
visudo指令来修改 - 安装环境要求
- 最少要求 4G 空间,但一定不够,应当 10g 以上
- 内存需求 1g 即可
- NTP 与 keepalived
- 这两项在安装过程中是有提示的,应当再开启一个终端,使用 root 执行
部署架构
最基本的高可用模式的部署架构类似下图:
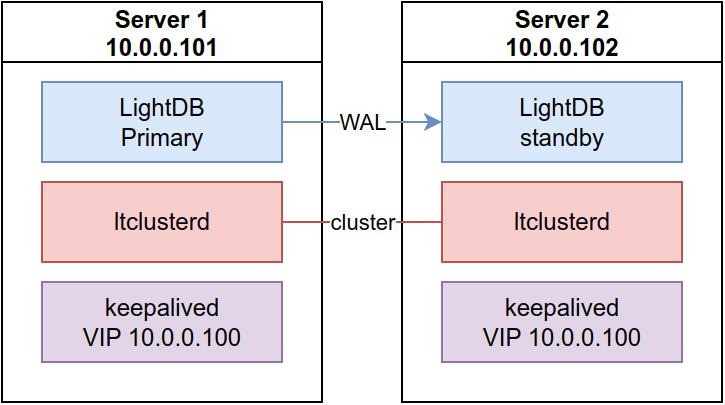
从节点是允许部署多个的,此时为了避免双主的出现,应当引入 witness 节点,避免双主情况的发生。
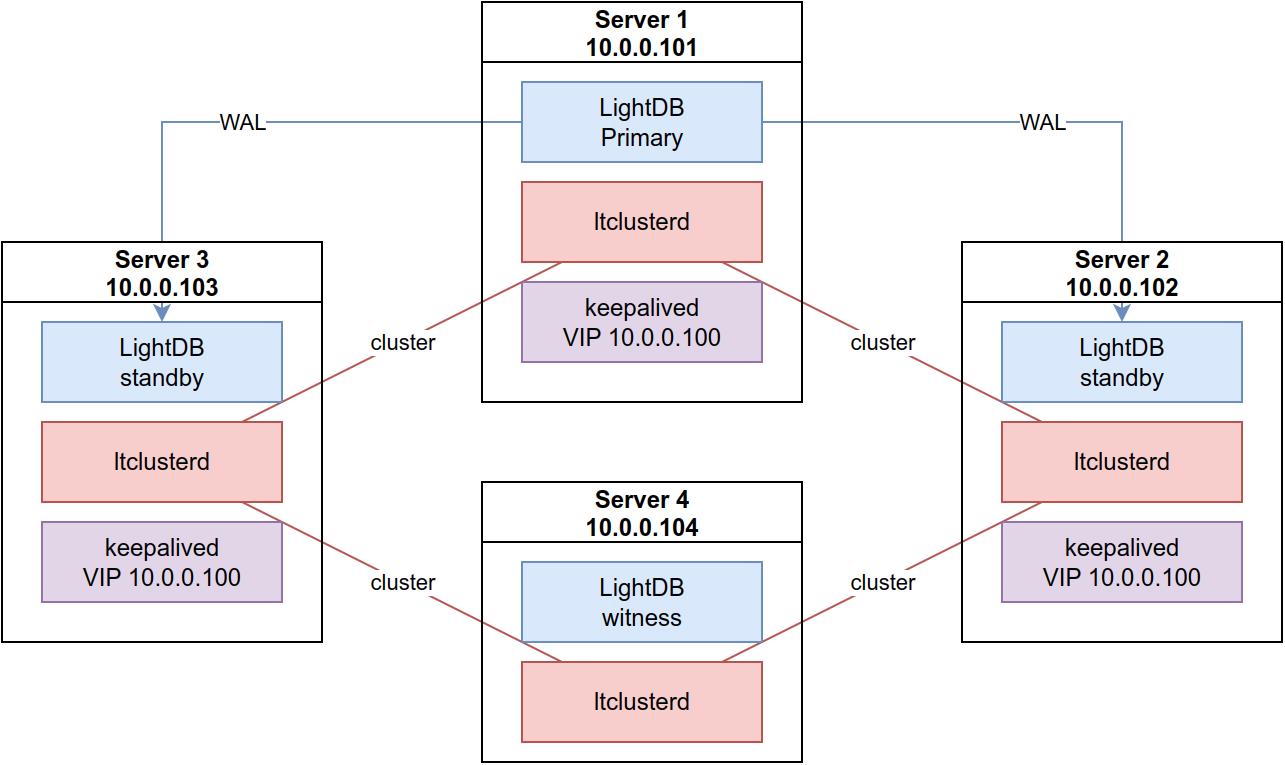
高可用基本原理
高可用模式是基于主备热同步模式 + 集群控制系统实现的。
WAL
主从同步是通过 PostgreSQL 的 WAL 机制实现的。
WAL 是 Write-Ahead Logging 的缩写,是一种确保事务持久化的机制,类似于 MySQL 的 BinLog。它要求事务写入数据表所在的数据块之前,必须先进行日志记录;每次记录对数据有影响的操作及数据,数据足够支撑回放功能。
WAL 文件存放于 $LTDATA/lt_wal ,可通过 lt_wal 工具进行解码,可使用 lt_wal -f 来实时跟踪 WAL 日志的写入情况。
ltcluster
ltcluster 是一系列开源工具集,用于管理集群的复制与故障转移功能。
ltclusterd 会以守护进程的形式运行,根据集群配置文件,与一台本地的 LightDB 实例进行绑定。
ltcluster 集群信息会放在 LightDB 数据库中,名为 ltcluster 的 schema 中,可通过 SQL 查看有哪些集群信息:
select * from information_schema.tables where table_schema=\'ltcluster\';
很多 ltcluster 命令行工具提供的功能都是从这个 ltcluster schema 中获取信息并展示的,如 ltcluster cluster show ,就相当于对 select * from ltcluster.nodes 的结果进行处理展示的。
故障转移
当主库发生故障时,ltcluster 会执行故障转移(failover)。故障转移时
常用维护命令
本章描述一些基本的状态监控及集群操作方式。
高可用模式的维护大多围绕 ltcluster 指令,这个指令每次都需要指定集群配置文件的路径,所以在下面的说明中,以 ltcluster-x 代指 ltcluster -f $LTDATA/../etc/ltcluster/ltcluster.conf 。
状态监控
-
如何判断当前机器的 LightDB 是否为高可用模式?
可直接通过
ltcluster指令判断是否为集群模式安装,若不存在,则肯定不是集群模式。若存在,可输入
ltcluster-x cluster show来查看集群运行状态。 -
如何判断集群的健康状态?
可使用
ltcluster-x cluster show查看整体状态,可通过ltcluster-x cluster matrix
看每个节点的连接矩阵图,识别节点间的互通故障;更多指令可参考
ltcluster cluster --help。 -
如何查看 VIP 在哪个节点?
LightDB 没有自带相关的指令,需要根据 Linux 系统的方式来判断:
ip a |grep $vip。也可以使用 shell 封装一份脚本,来更好地发现集群中 VIP 的归属,脚本如下:
vip=10.0.3.200 ltcluster -f $LTDATA/../etc/ltcluster/ltcluster.conf cluster show | grep -o \'host=[^ ]*\' | cut -d\'=\' -f2 | while read -r line; do yes=$(ssh -n "$line" "/sbin/ip a | grep $vip"); if [ -n "$yes" ]; then echo "$line"; fi; done -
如何查看节点间的同步状态?
主库通过复制信息表
pg_stat_replication查看与每一个备库的同步状态;备库要查询
pg_stat_wal_receiver查询接收 wal 日志的进度。主库指令:
psql -h 主库IP -x -d postgres -U lightdb -c "select * from pg_stat_replication"从库指令
psql -h 从库IP -x -d postgres -U lightdb -c "select * from pg_stat_wal_receiver" -
集群日志如何查看?
集群日志位于
$LTDATA/../etc/ltcluster/ltcluster.log
集群操作
这里介绍集中常用操作:
- 重启主库
- 重启从库
- 主备切换
重启主库
有时为了调整系统参数、内核参数等,需要对主库进行重启。在集群中重启主库是很有讲究的,需要有一些步骤来保证。
整体步骤如下:
- 停止所有从库的 keepalived
- 暂停整个 ltcluster 集群
- 停止数据库
- 此时数据库已经关闭,可以执行需要停库期间要做的操作
- 启动数据库
- 取消 ltcluster 集群的暂停
- 启动每个从库的 keepalived
停止所有从库的 keepalived
只要使用 root 连上每一个主库,找到每个 /var/run/keepalived.pid 将其 kill 即可。
# 停止 standby01 服务器的 keepalived
ssh root@standby01 \'kill $(cat /var/run/keepalived.pid)\'
# 如果有多个 standby 服务器,可尝试以下写法:
for id in 01,2,3,4; do ssh root@standby$id \'kill $(cat /var/run/keepalived.pid)\'; done
暂停整个 ltcluster 集群
先使用 ltcluster-x service status 确认集群状态。在我的三机器集群上,输出类似于:
ID | Name | Role | Status | Upstream | ltclusterd | PID | Paused? | Upstream last seen
----+---------------------------+---------+-----------+---------------------------+------------+-------+---------+--------------------
1 | lightdbCluster10032015432 | standby | running | lightdbCluster10032045432 | running | 4051 | no | 1 second(s) ago
2 | lightdbCluster10032025432 | standby | running | lightdbCluster10032045432 | running | 28292 | no | 0 second(s) ago
4 | lightdbCluster10032035432 | witness | * running | lightdbCluster10032045432 | running | 2076 | no | 0 second(s) ago
5 | lightdbCluster10032045432 | primary | * running | | running | 12063 | no | n/a
再执行 ltcluster-x service pause ,会看到以下输出:
NOTICE: node 1 (lightdbCluster10032015432) paused
NOTICE: node 2 (lightdbCluster10032025432) paused
NOTICE: node 4 (lightdbCluster10032035432) paused
NOTICE: node 5 (lightdbCluster10032045432) paused
此时应再次执行 ltcluster-x service status 确认集群状态:
ID | Name | Role | Status | Upstream | ltclusterd | PID | Paused? | Upstream last seen
----+---------------------------+---------+-----------+---------------------------+------------+-------+---------+--------------------
1 | lightdbCluster10032015432 | standby | running | lightdbCluster10032045432 | running | 4051 | yes | 0 second(s) ago
2 | lightdbCluster10032025432 | standby | running | lightdbCluster10032045432 | running | 28292 | yes | 1 second(s) ago
4 | lightdbCluster10032035432 | witness | * running | lightdbCluster10032045432 | running | 2076 | yes | 1 second(s) ago
5 | lightdbCluster10032045432 | primary | * running | | running | 12063 | yes | n/a
看到 Paused? 这一列变为 yes 即成功暂停了集群。
停止数据库
停止数据库使用 lt_ctl -D $LTDATA stop 指令;如果停止失败,可加上 -m immediate 参数再尝试。
停止成功的输出类似于:
waiting for server to shut down.... done
server stopped
停止数据库会将未提交的事务全部回滚,是比较安全的。
启动数据库
使用 lt_ctl -D $LTDATA start 启动数据库,只要见到 server started 就是启动成功了。
取消 ltcluster 集群的暂停
先执行 ltcluster-x service pause,再执行 ltcluster-x service status ,看到结果中 Paused? 列变为 no 即成功。
启动每个从库的 keepalived
如果是正常通过安装程序装的 LightDB,那么 keepalived 的配置文件会位于 $LTHOME/etc/keepalived/keepalived.conf,keepalived 的启动路径在 $LTHOME/tools/bin/keepalived,所以启动指令可使用 lightdb 用户登录,并执行:
sudo $LTHOME/tools/bin/keepalived -f $LTHOME/etc/keepalived/keepalived.conf
注意 root 用户可能没有
$LTHOME环境变量,所以推荐用 lightdb 用户来登录
与关闭类似,可使用 for 语法简化多个 standby 的操作:
for id in 01,2,3,4; do ssh lightdb@standby$id \'sudo $LTHOME/tools/bin/keepalived -f $LTHOME/etc/keepalived/keepalived.conf\'; done
重启从库
重启从库可参考重启主库的步骤,不过无需操作 keepalived ,其余步骤完全相同,依旧需要:
- 暂停整个 ltcluster 集群
- 停止数据库
- 此时数据库已经关闭,可以执行需要停库期间要做的操作
- 启动数据库
- 取消 ltcluster 集群的暂停
可参考官网的方式:http://www.light-pg.com/docs/LightDB_Install_Manual/current/install.html#id22
主备切换
在备机执行 ltcluster-x standby switchover --siblings-follow --dry-run,先试运行一下,在我的机器会得到以下输出:
NOTICE: checking switchover on node "lightdbCluster10032015432" (ID: 1) in --dry-run mode
INFO: SSH connection to host "10.0.3.204" succeeded
INFO: able to execute "ltcluster" on remote host "10.0.3.204"
INFO: all sibling nodes are reachable via SSH
INFO: 3 walsenders required, 10 available
INFO: demotion candidate is able to make replication connection to promotion candidate
INFO: 0 pending archive files
INFO: replication lag on this standby is 0 seconds
INFO: 2 replication slots required, 10 available
NOTICE: local node "lightdbCluster10032015432" (ID: 1) would be promoted to primary; current primary "lightdbCluster10032045432" (ID: 5) would be demoted to standby
INFO: following shutdown command would be run on node "lightdbCluster10032045432":
"/home/lightdb/lightdb/lightdb-x/13.8-23.1/bin/lt_ctl -D \'/home/lightdb/lightdb/lightdb-x/13.8-23.1/cluster/data\' -W -m fast stop"
INFO: parameter "shutdown_check_timeout" is set to 1800 seconds
INFO: prerequisites for executing STANDBY SWITCHOVER are met
这句 prerequisites for executing STANDBY SWITCHOVER are met 说明预检查已经通过,达到了主备切换的条件,这时就可以真正执行切换了。
切换前输入 ltcluster-x service status 会看到 primary 属于 204 的机器:
ID | Name | Role | Status | Upstream | ltclusterd | PID | Paused? | Upstream last seen
----+---------------------------+---------+-----------+---------------------------+------------+-------+---------+--------------------
1 | lightdbCluster10032015432 | standby | running | lightdbCluster10032045432 | running | 4051 | yes | 1 second(s) ago
2 | lightdbCluster10032025432 | standby | running | lightdbCluster10032045432 | running | 28292 | yes | 0 second(s) ago
4 | lightdbCluster10032035432 | witness | * running | lightdbCluster10032045432 | running | 2076 | yes | 1 second(s) ago
5 | lightdbCluster10032045432 | primary | * running | | running | 12063 | yes | n/a
这时去掉试运行选项 --dry-run ,正式执行 ltcluster-x standby switchover --siblings-follow;只要输出中看到 NOTICE: STANDBY SWITCHOVER has completed successfully 就是已经切换完成了。
此时再输入 ltcluster-x service status 会看到 primary 属于 201 的机器:
ID | Name | Role | Status | Upstream | ltclusterd | PID | Paused? | Upstream last seen
----+---------------------------+---------+-----------+---------------------------+------------+-------+---------+--------------------
1 | lightdbCluster10032015432 | primary | * running | | running | 4051 | no | n/a
2 | lightdbCluster10032025432 | standby | running | lightdbCluster10032015432 | running | 28292 | no | 1 second(s) ago
4 | lightdbCluster10032035432 | witness | * running | lightdbCluster10032015432 | running | 2076 | no | 0 second(s) ago
5 | lightdbCluster10032045432 | standby | running | lightdbCluster10032015432 | running | 12063 | no | 1 second(s) ago
但一定要注意,VIP 的切换是比较缓慢的,需要 15s 左右消失,再 25s 左右才会被新的机器获取;在此期间基于 VIP 的服务是无法正常使用的。所以建议在切换之前前,先将旧的主库的 keepalived kill ,再执行切换。
参考资料
lightdb-归档日志清理
LightDB 归档日志清理(22.3及之前)
LightDB 支持通过配置参数来支持归档日志文件的清理。下面对原理与参数进行说明。
简单原理
在归档完成后,会进行归档文件的清理,需要同时配置 lightdb_archive_dir 和 lightdb_archive_retention_size 参数,才能使归档起效。
如果只配置 lightdb_archive_retention_size 参数不起效,会打印 warning 日志提醒。
清理时通过遍历归档目录下文件,删除不符合保留规则的归档文件。保留规则如下:
- Latest checkpoint’s REDO WAL file(最近一次checkpoint所在文件) 之前的文件保留lightdb_archive_retention_size 个, 不包括 Latest checkpoint’s REDO WAL file。
- checkpoint 之后的 wal 日志都保留
参数介绍
- lightdb_archive_dir 归档目录,即在 archive_command 中使用的归档目录。
- lightdb_archive_retention_size 日志保留数, 保留最近一次checkpoint之前的N个文件。
参考
以上是关于认识LightDB的主要内容,如果未能解决你的问题,请参考以下文章