python实现网易云音乐批量下载
Posted 公众号:小布软件分享
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python实现网易云音乐批量下载相关的知识,希望对你有一定的参考价值。
今天给大家带来的是网易云音乐批量下载,代码有些粗糙,以后有时间再慢慢改进。我只爬取了某个明星的全部歌曲,如果再添加点代码完全可以爬取整站音乐,但是我认为还是点到为止,剩下的代码也不难。首先,通过网页抓包获取真实音乐文件的链接,然后找到该提交地址,并分析传入的 data 。比较走运的是,网上有很多关于获取 encSecKey和 params 的教程,大家可以搜索一下。
一、抓包
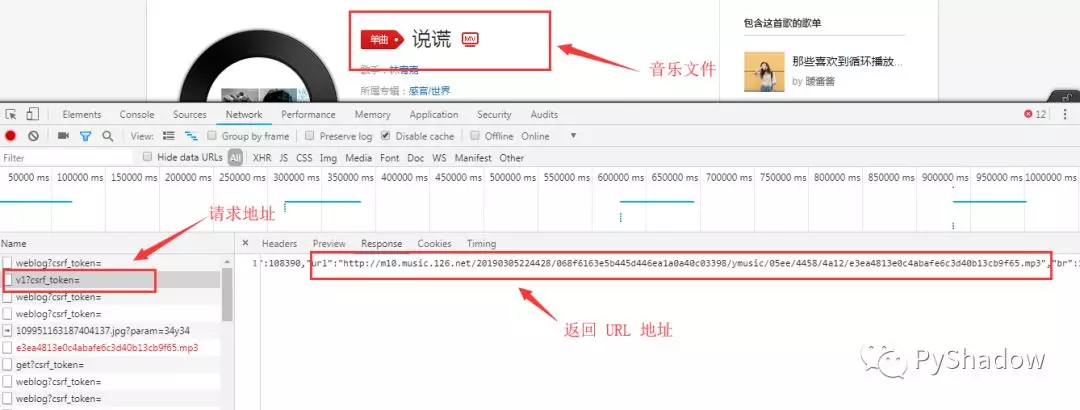
我们的目的是获取到真实的 URL 地址,可以看到 post 访问该网址,可以返回真实的 URL 。

二、分析
post 提交的有两个参数,但是被加密过!我们可以通过全局查找,找 params 和 encSecKey 参数,看它俩是从哪里蹦出来的!

通过查找,出现一大批文件,都是含有这两个关键词的,==!(慢慢找吧)。但是我们可以试试 encSecKey 这个参数。

这个比较少,拿这个下手。
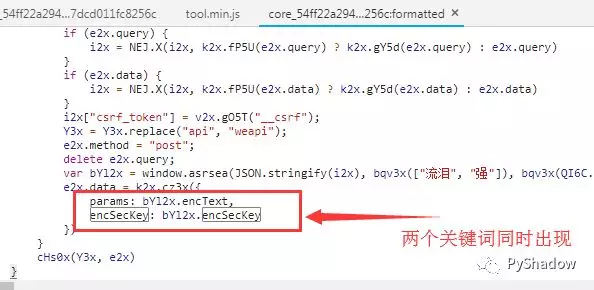
经过一番搜索,找到很敏感的东西,两个加密参数同时出现。接着找到这个函数...(js分析过程就不赘述了,网上有好多)。js分析过程:https://www.zhihu.com/question/36081767。通过分析 js ,我们得知通过给 js 传入参数,就会获取到两个参数的加密值。我们把这个 js 打包,使用 python 调用,就可以获取到两个参数了。
三、敲代码
import requests import re import execjs import json class Down(object): def __init__(self): pass # 获取音乐文件的 ids 参数 def getids(self): _headers = {\'Referer\': \'https://music.163.com/\', \'User-Agent\': \'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko\'} # 通过该链接,获取该页面的源码。 html = requests.get(\'https://music.163.com/artist?id=3685\', headers=_headers).text # 返回通过正则匹配获得的所有 ids 值。 return re.findall(\'<li><a.href=.*?song.*?id=(.*?)">(.*?)</a></li>\', html) # 计算 ids 的加密后的值(通过引入js文件,计算相应的值) def countids(self,ids): # 传入的参数,这里指的是获取音乐URL时,需要传入含有该音乐文件ids的字符串。 ddd = \'{"ids":"[\'+ids+\']","level":"standard","encodeType":"aac","csrf_token":""}\' # 导入js文件 f=open(\'countdis.js\',\'r\',encoding=\'utf-8\') line = f.readline() htmlstr = \'\' while line: htmlstr = htmlstr + line line = f.readline() ctx = execjs.compile(htmlstr) f.close() # 运行js的 d 函数,并传入参数 ddd,也就是刚才定义的完整字符串,并返回。 return ctx.call(\'d\', ddd) # 获取到该音乐的真实 url 地址 def geturl(self): # 因为该页面有多个音乐,会生成多个加密文本,所以这里迭代出来。 for i in self.getids(): # getids返回的是含有params 和 encSecKey两个加密文的,所以通过列表获取到相应的值。 str=self.countids(i[0]) encSecKey=str[0] params=str[1] _headers={\'Referer\':\'https://music.163.com/\', \'User-Agent\':\'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36\' } _data={\'encSecKey\':encSecKey,\'params\':params} # 把获取到的两个参数值,提交到服务器,获得 URL 地址。 urltext=requests.post(\'https://music.163.com/weapi/song/enhance/player/url/v1?csrf_token=\',headers=_headers,data=_data).text _json=json.loads(urltext) url=_json[\'data\'][0][\'url\'] # 获得URL后,直接使用get下载音乐文件到本地。 data=requests.get(url,_headers,stream=True) with open(i[1]+\'.mp3\',\'wb\') as f: for j in data.iter_content(chunk_size=512): f.write(j) print(i[1]+\'.mp3 写出完毕!\') # 运行 if __name__==\'__main__\': bb=Down() bb.geturl()
* 我们最开始访问的“https://music.163.com/artist?id=3685”是某个歌星的全部歌曲的页面,需要抓包获取。
四、运行以上代码,得到音乐文件。


五、python源码 和 js代码请关注公众号:PyShadow,在后台回复“1”获取。

以上是关于python实现网易云音乐批量下载的主要内容,如果未能解决你的问题,请参考以下文章