linux 性能自我学习 ———— cpu 高怎么办 [三]
Posted 程序员其实就是一个写文档的工作,代码只是文档的一部分,一切皆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux 性能自我学习 ———— cpu 高怎么办 [三]相关的知识,希望对你有一定的参考价值。
前言
linux 性能分析自我学习。
正文
一般我们说cpu,一般是什么高呢? 一般是指cpu 使用率高。
那么什么是cpu 使用率呢?
cpu 使用率 = 1- 空闲时间/总cpu 时间
平均cpu 使用率 = 1 -(new空闲时间 - old 空闲时间)/ (new总cpu时间 - old总cpu时间)
我们可以使用top 查看:
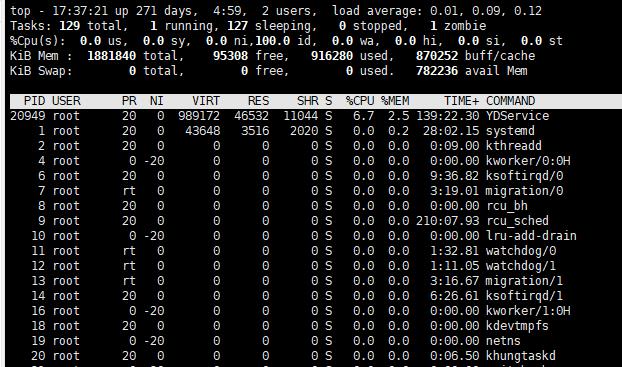
那么来看下这些参数的意义:
-
user (通常为us), 用户态的时间。(不包含nice的时间,但是包含guest的时间)
-
nice (ni) 表示低优先级用户态cpu 时间,也就是进程的nice 值被调整为1-19 之间的cpu 时间。 nice 值可取-20-19,数值越大,优先级越低。
-
system (sys), 表示内核态cpu 时间。
-
idle, 代表空闲时间。 注意,它不包含等待 i/o 的时间。
-
iowait (通常为wa), 表示等待i/o的cpu 时间。
-
irq(通常为hi),表示处理硬中断的cpu 时间
-
softtirq(si), 表示处理软中断的cpu时间
-
steal(st),表示该系统运行在虚拟机中的时候,被其他虚拟机占用的cpu时间。
-
guest(通常缩写为guest), 代表虚拟化运行其他操作系统的时间,也就是运行虚拟机的cpu时间
-
guest_nice(通常缩写为gnice),表示低优先级运行虚拟机的时间。
然后下面是进程占用cpu的时间,但是其中间并没有分为用户态使用率和内核态使用率
那么就需要使用pidstat:

那么我们怎么定位cpu 高到底是怎么造成的呢?
一般使用perf 这个工具。
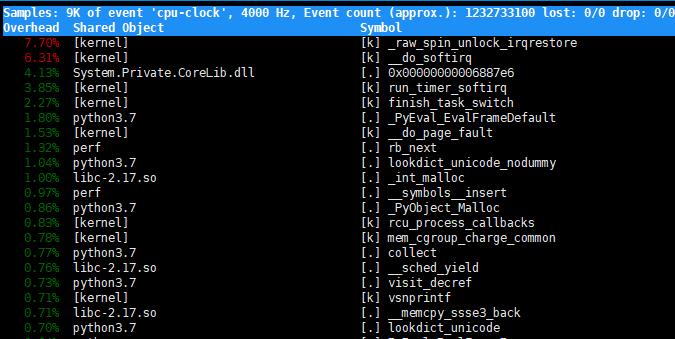
如果使用perf top 看下,那么是怎么样的呢?
第一行包含3个数据, 分别是采样数, 事件类型event, 事件总数量。
第二行:
overhead, 是该符号的性能事件在所有采样中的比例,用百分号来表示
shared, 是该函数或指令所在的动态共享对象(dynamic shared object), 如内核,进程名,动态链接库名, 内核模块名等。
object, 是动态共享对象的类型,比如. 表示用户空间的可执行程序或者链接库,而k 表示内核空间
symbol, 是符号名,也是函数名。当函数未知时候,用十六进制地址表示。
还可以直接使用perf record 和 perf report。
perf record 将信息收集起来。
然后perf report 就打开记录进行分析。
一般我们定位到具体的pid的时候,那么会使用:
perf -g -p xxx
这个-g 表示了,调用关系。
然后一般我们的web 服务会进行压测。
一般使用ab。
ab -c 10 -n 10000 http://10.254.0.5:10000
这样去压测,如果压测吞吐很低,那么就应该分析性能问题。
实验
实验:cpu 很高,但是找不到cpu高的应用。
运行nginx:
docker run --name nginx -p 10000:80 -itd feisky/nginx:sp
运行php代码:
docker run --name phpfdm -itd --network container:nginx feisky/php-fpm:sp
curl 一下:
curl http://192.168.62.136:10000
发现成功. 压测一下:
ab -c 100 -n 1000 http://192.168.62.136:10000/
ab 安装:
yum -y install httpd-tools
结果为:
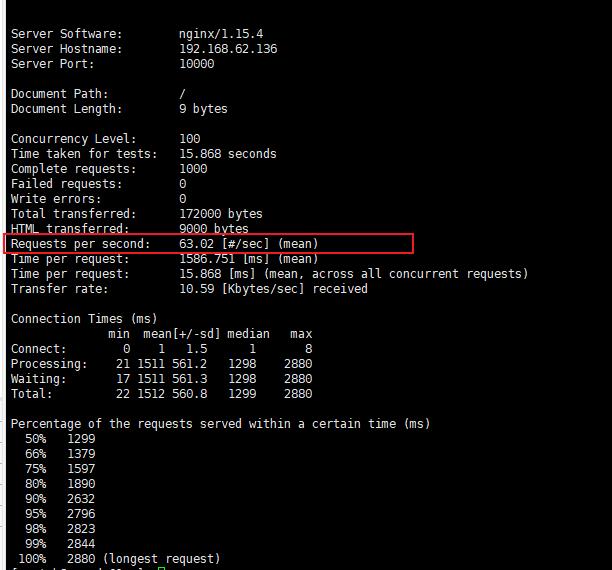
每秒60多,有点小低了。
ab -c 5 -t 600 http://192.168.62.136:10000/
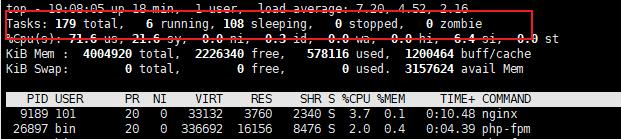
通过top 看一下cpu情况:
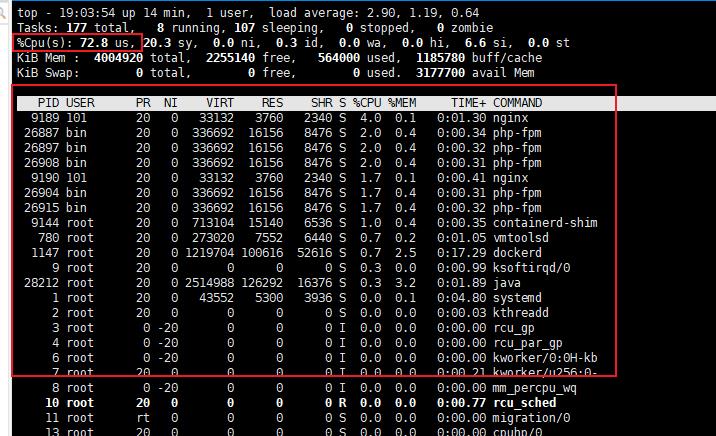
发现top 很高,但是进程cpu不高,这怎么说?
难道还有进程不占用cpu?
通过pidstat 查看一下:

cpu 也不高啊。
通过task 这一行看下,发现就绪队列有6个:
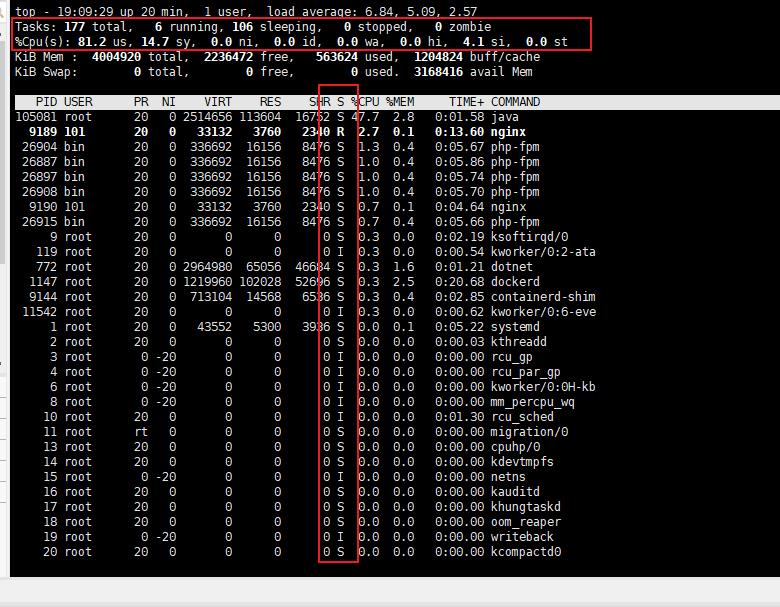
诡异的事情出现了,这一排居然没有发现6个就绪进程。
那么可能原因是什么呢?
-
进程在不停的崩溃重启,比如因为段错误等。 这时候,进程在推出后又被监控系统自动重启了。
-
这些进程是短时进程,也就是在其他应用内部通过exec 调用的外部命令。这些命令一般都只运行很短时间就会结束,你很难用top这种间隔比较长的工具发现。
用ps tree 查看一下:
yum -y install psmisc
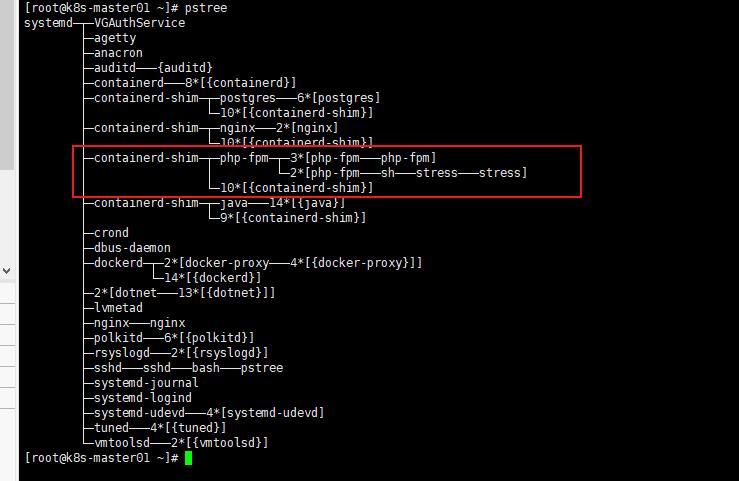
这里可以看到php-fpm 中启动了stress,那么是不是stress的问题呢?
这个时候可以看代码,其实一般看错误日志就知道了。
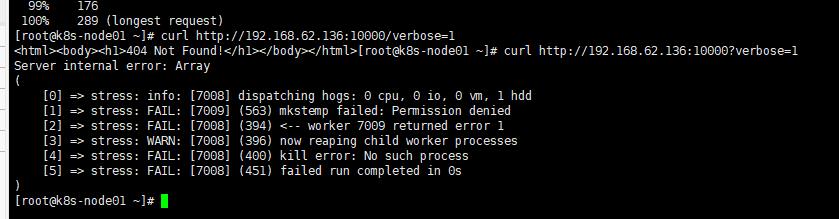
这种排查方式比较慢,直接用perf比较好。
的确看到了stree,但是cpu 使用高还是kernel,内核方法。
perf record -g
等一段时间看下情况:
perf report
那么有没有其他短时进程监控能马上能查看到的呢? execsnoop.
centos 怎么安装呢?
下载:
https://github.com/brendangregg/perf-tools
一般我会下载zip,然后解压。
然后运行:
./perf-tools/perf-tools-master/bin/execsnoop
结
不可中断进程和僵尸进程。
linux 性能优化-- cpu 切换以及cpu过高
参考技术A本文先介绍了cpu上下文切换的基础知识,以及上下文切换的类型(进程,线程等切换)。然后介绍了如何查看cpu切换次数的工具和指标的解释。同时对日常分析种cpu过高的情况下如何分析和定位的方法做了一定的介绍,使用一个简单的案例进行分析,先用top,pidstat等工具找出占用过高的进程id,然后通过分析到底是用户态cpu过高,还是内核态cpu过高,并用perf 定位到具体的调用函数。(来自极客时间课程学习笔记)
1、多任务竞争CPU,cpu变换任务的时候进行CPU上下文切换(context switch)。CPU执行任务有4种方式:进程、线程、或者硬件通过触发信号导致中断的调用。
2、当切换任务的时候,需要记录任务当前的状态和获取下一任务的信息和地址(指针),这就是上下文的内容。因此,上下文是指某一时间点CPU寄存器(CPU register)和程序计数器(PC)的内容, 广义上还包括内存中进程的虚拟地址映射信息.
3、上下文切换的过程:
4、根据任务的执行形式,相应的下上文切换,有进程上下文切换、线程上下文切换、以及中断上下文切换三类。
5、进程和线程的区别:
进程是资源分配和执行的基本单位;线程是任务调度和运行的基本单位。线程没有资源,进程给指针提供虚拟内存、栈、变量等共享资源,而线程可以共享进程的资源。
6、进程上下文切换:是指从一个进程切换到另一个进程。
(1)进程运行态为内核运行态和进程运行态。内核空间态资源包括内核的堆栈、寄存器等;用户空间态资源包括虚拟内存、栈、变量、正文、数据等
(2)系统调用(软中断)在内核态完成的,需要进行2次CPU上下文切换(用户空间-->内核空间-->用户空间),不涉及用户态资源,也不会切换进程。
(3)进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了用户空间的资源,也包括内核空间资源。
(4)进程的上下文切换过程:
(5)、下列将会触发进程上下文切换的场景:
7、线程上下文切换:
8、中断上下文切换
快速响应硬件的事件,中断处理会打断进程的正常调度和执行。同一CPU内,硬件中断优先级高于进程。切换过程类似于系统调用的时候,不涉及到用户运行态资源。但大量的中断上下文切换同样可能引发性能问题。
重点关注信息:
系统的就绪队列过长,也就是正在运行和等待 CPU 的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高。
这个结果中有两列内容是我们的重点关注对象。一个是 cswch ,表示每秒自愿上下文切换(voluntary context switches)的次数,另一个则是 nvcswch ,表示每秒非自愿上下文切换(non voluntary context switches)的次数。
linux的中断使用情况可以从 /proc/interrupts 这个只读文件中读取。/proc 实际上是 Linux 的一个虚拟文件系统,用于内核空间与用户空间之间的通信。/proc/interrupts 就是这种通信机制的一部分,提供了一个只读的中断使用情况。
重调度中断(RES),这个中断类型表示,唤醒空闲状态的 CPU 来调度新的任务运行。这是多处理器系统(SMP)中,调度器用来分散任务到不同 CPU 的机制,通常也被称为处理器间中断(Inter-Processor Interrupts,IPI)。
这个数值其实取决于系统本身的 CPU 性能。如果系统的上下文切换次数比较稳定,那么从数百到一万以内,都应该算是正常的。但当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现了性能问题。这时,需要根据上下文切换的类型,再做具体分析。
比方说:
首先通过uptime查看系统负载,然后使用mpstat结合pidstat来初步判断到底是cpu计算量大还是进程争抢过大或者是io过多,接着使用vmstat分析切换次数,以及切换类型,来进一步判断到底是io过多导致问题还是进程争抢激烈导致问题。
CPU 使用率相关的重要指标:
性能分析工具给出的都是间隔一段时间的平均 CPU 使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,你一定要保证它们用的是相同的间隔时间。比如,对比一下 top 和 ps 这两个工具报告的 CPU 使用率,默认的结果很可能不一样,因为 top 默认使用 3 秒时间间隔,而 ps 使用的却是进程的整个生命周期。
top 和 ps 是最常用的性能分析工具:
这个输出结果中,第三行 %Cpu 就是系统的 CPU 使用率,top 默认显示的是所有 CPU 的平均值,这个时候你只需要按下数字 1 ,就可以切换到每个 CPU 的使用率了。继续往下看,空白行之后是进程的实时信息,每个进程都有一个 %CPU 列,表示进程的 CPU 使用率。它是用户态和内核态 CPU 使用率的总和,包括进程用户空间使用的 CPU、通过系统调用执行的内核空间 CPU 、以及在就绪队列等待运行的 CPU。在虚拟化环境中,它还包括了运行虚拟机占用的 CPU。
预先安装 stress 和 sysstat 包,如 apt install stress sysstat。
stress 是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。而 sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统的性能。我们的案例会用到这个包的两个命令 mpstat 和 pidstat。
下面的 pidstat 命令,就间隔 1 秒展示了进程的 5 组 CPU 使用率,
包括:
perf 是 Linux 2.6.31 以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
第一种常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
输出结果中,第一行包含三个数据,分别是采样数(Samples)如2K、事件类型(event)如cpu-clock:pppH和事件总数量(Event count)如:371909314。
第二种常见用法,也就是 perf record 和 perf report。 perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。
1.启动docker 运行进程:
2.ab工具测试服务器性能
ab(apache bench)是一个常用的 HTTP 服务性能测试工具,这里用来模拟 Ngnix 的客户端。
3.分析过程
CPU 使用率是最直观和最常用的系统性能指标,在排查性能问题时,通常会关注的第一个指标。所以更要熟悉它的含义,尤其要弄清楚:
这几种不同 CPU 的使用率。比如说:
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数.
以上是关于linux 性能自我学习 ———— cpu 高怎么办 [三]的主要内容,如果未能解决你的问题,请参考以下文章