第八课 常用机器学习算法性能对比
Posted tgltt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第八课 常用机器学习算法性能对比相关的知识,希望对你有一定的参考价值。
市面上常用的机器学习算法,也就剩下KNN、朴素贝叶斯、决策树、随机森林这些算法了,这些算法各有优劣,适用不同的场景,没有谁能把所有其他的算法干掉而统一天下。
下面将通过准确率、耗时两个维度,来对比KNN、朴素贝叶斯、决策树、随机森林这几个算法的性能。
1、构建数据集,并拆分为训练集和测试集

调用SkLearn的make_classification构建分类数据集,总计10个分类,10万个样本,每个样本有100个特征(属性),这100个特征中,有意义的特征有20个,冗余的特征也有20个。
构建完数据集,调用train_test_split将构建好的数据集拆分为训练集(8万个样本)和测试集(2万个)样本。
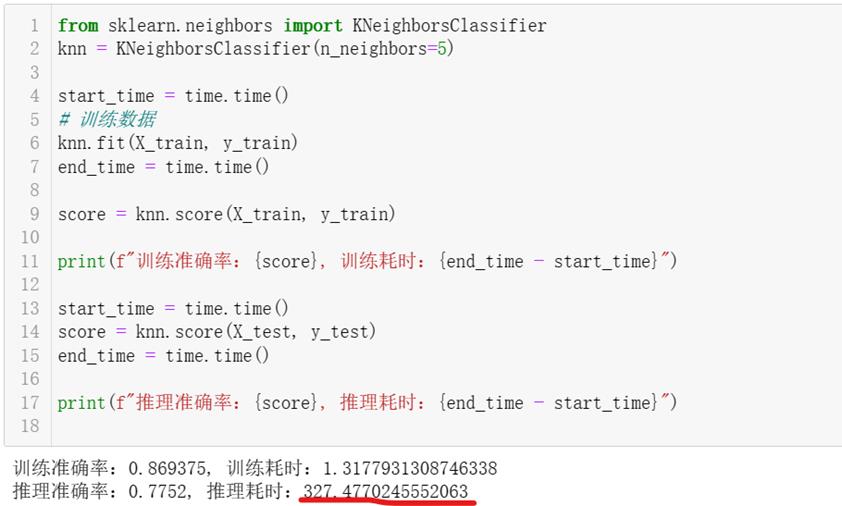
2、测试KNN算法
调用SkLearn的KNeighborsClassifier,使用上面自定义的数据集训练和测试,测试结果:训练耗时1.3秒,训练集准确率86.9%,而推理准确率77.5%,推理耗时327秒。
3、测试朴素贝叶斯算法
调用SkLearn的GaussionNB,使用上面自定义的数据集训练和测试,测试结果:
训练耗时0.16秒,训练集准确率42.7%,测试集准确率42.1%,推理耗时0.19秒。

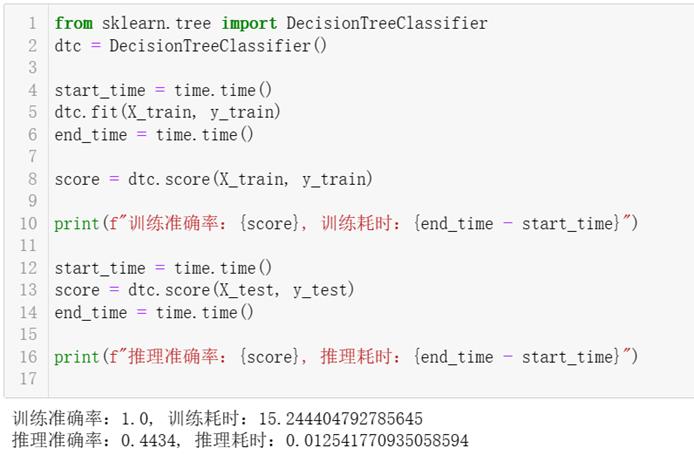
4、测试决策树算法
调用SkLearn的DecisionTreeClassifier,使用上面自定义的数据集训练和测试,测试结果:训练耗时15.24秒,训练集准确率100%,测试集准确率44.3%,推理耗时0.01秒。可见使用默认参数(无剪枝的情况下) ,决策树算法严重过拟合,所以需对决策树进行适当剪枝。
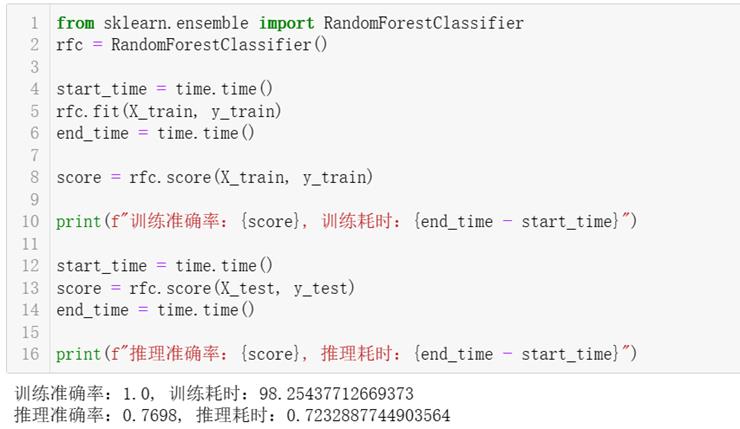
5、测试随机森林算法
调用SkLearn的RandomForestClassifier,使用上面自定义的数据集训练和测试,测试结果:训练耗时98.25秒,训练集准确率100%,测试集准确率77.0%,推理耗时0.72秒。
随机森林的训练时间比决策树的时间长,因为随机森林要训练很多棵树,下面代码的随机森林内包含100棵树,其达到的准确率还是可以的,推理时间也很快,虽然训练时间长了点,但这只是线下时间,用户并不关心你的模型训练要多长时间,他只关心线上推理时间是否接受。
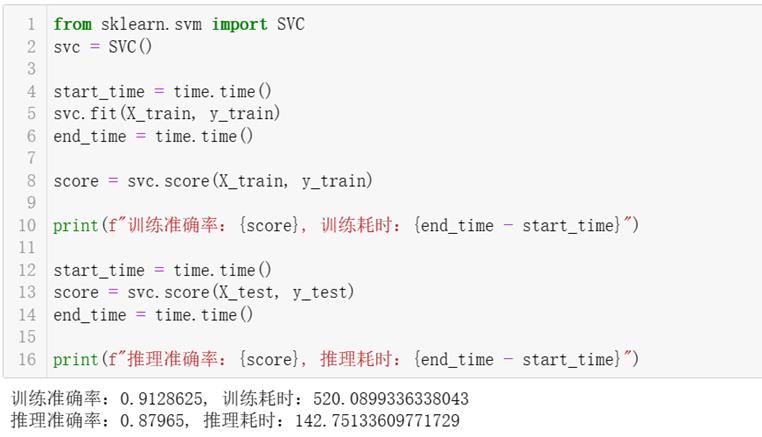
6、测试支持向量机(SVM)算法
支持向量机是过去算法的王者,如今已经没落了,它的算法准确率是机器学习算法中最高的,但其所需的推理时间也是最慢的,尤其是在大数据集上,所以本系列课程并未引入课程对其进行介绍。
调用SkLearn的SVC,使用上面自定义的数据集训练和测试,测试结果:训练耗时520.09秒,训练集准确率91.3%,测试集准确率88.0%,推理耗时142.75秒。
7、小结
上面对KNN、朴素贝叶斯、决策树、随机森林、SVC五种机器学习算法进行了比较,为了更直观地进行对比,下面将汇总一个表格来体现这几个算法的性能数据。
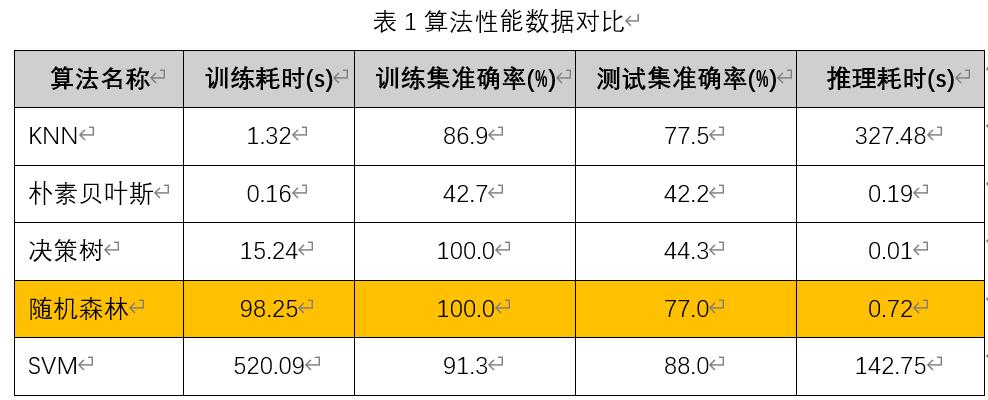
综合比较,随机森林在当前场景的性能是最优的。
Scrapy学习第八课
python爬虫框架scrapy学习第八课
目标爬取文章,实现文本和图片数据存储
文本数据以json文件存储
文本数据存储在mongodb数据库中
图片保存在本地
爬取地址:伯乐在线文章
爬虫实例
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class JobboleItem(scrapy.Item):
#标题
title = scrapy.Field()
#发布日期
create_date = scrapy.Field()
#链接
url = scrapy.Field()
#MD5加密的url
url_object_id = scrapy.Field()
#图片的url
front_image_url = scrapy.Field()
#图片存储路径
front_image_path = scrapy.Field()
#点赞数
praise_nums = scrapy.Field()
#收藏数
fav_nums = scrapy.Field()
#评论数
comment_nums = scrapy.Field()
#标签
tag = scrapy.Field()
#内容
#content = scrapy.Field()
# -*- coding: utf-8 -*-
import scrapy
from urllib.parse import urljoin
from jobBole.items import JobboleItem
import re
import hashlib
import datetime
def get_md5(md5str):
#生成1个MD5对象
m1 = hashlib.md5()
#使用MD5对象你的update方法进行md5转换
m1.update(md5str.encode("utf-8"))
md5ConvertStr = m1.hexdigest()
return md5ConvertStr
class BoleSpider(scrapy.Spider):
name = 'bole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
def parse(self, response):
'''
1.获取文章列表也中具体文章url,并交给scrapy进行下载后并进行解析
2.获取下一页的url并交给scrapy进行下载,下载完成后,交给parse
:param response:
:return:
'''
#解析列表页中所有文章的url, 并交给scrapy下载并解析
post_nodes = response.css("#archive .floated-thumb .post-thumb a")
for post_node in post_nodes:
#image_url是图片的地址
image_url = post_node.css("img::attr(src)").extract_first("")
post_url = post_node.css("::attr(href)").extract_first("")
#这里通过meta参数将图片的url传递进来,parse.urljoin的好处是如果有域名,则前面的response.url不生效
#如果没有,就会把response.url和post_urlz做拼接
yield scrapy.Request(url=urljoin(response.url, post_url), meta=
"front_image_url": urljoin(response.url, image_url)
,callback = self.parse_detail)
#提取下一页并交给scrapy下载
next_url = response.css(".next.page-numbers::attr(href)").extract_first("")
curr_page = int(response.xpath('//span[@class="page-numbers current"]/text()').extract()[0])
if next_url and curr_page < 3:
yield scrapy.Request(url = next_url, callback = self.parse)
def parse_detail(self, response):
'''
获取文章的详细内容
:param response:
:return:
'''
article_item = JobboleItem()
front_image_url = response.meta.get("front_image_url", "")
title = response.xpath('//div[@class="entry-header"]/h1/text()').extract_first()
create_date = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/text()').extract()[0].strip().split()[0]
tag_list = response.xpath('//p[@class="entry-meta-hide-on-mobile"]/a/text()').extract()
#去掉标签中的评论
tag_list = [element for element in tag_list if -1 == element.find("评论")]
tag = ",".join(tag_list)
praise_nums = response.xpath('//span[contains(@class, "vote-post-up")]/h10/text()') .extract()[0]
print('praise_nums ', praise_nums)
if len(praise_nums) == 0:
praise_nums = 0
else:
praise_nums = int(praise_nums[0])
fav_nums = response.xpath('//span[contains(@class, "bookmark-btn")]/text()').extract()[0]
match_re = re.match(".*(\\d+).*", fav_nums)
if match_re:
fav_nums = int(match_re.group(1))
else:
fav_nums = 0
#print('@@@@ ', response.xpath('//a[@href="#article-comment"]/span/text()').extract())
comment_nums = response.xpath('//a[@href="#article-comment"]/span/text()').extract()[0]
match_com = re.match(".*(\\d+).*", comment_nums)
if match_com:
comment_nums= int(match_com.group(1))
else:
comment_nums = 0
content = response.xpath('//div[@class="entry"]').extract()[0]
article_item['url_object_id'] = get_md5(response.url) #对地址进行md5变成了定长
article_item['title'] = title
article_item['url'] = response.url
try:
create_date = datetime.datetime.strptime(create_date, '%Y/%m/%d').date()
except Exception as e:
create_date = datetime.now().date()
article_item['create_date'] = str(create_date)
article_item['front_image_url'] = [front_image_url]
article_item['praise_nums'] = int(praise_nums)
article_item['fav_nums'] = fav_nums
article_item['comment_nums'] = comment_nums
article_item['tag'] = tag
#article_item['content'] = content
yield article_item
ITEM_PIPELINES =
'jobBole.pipelines.JobbolePipeline': 300,
'jobBole.pipelines.ArticleImagePipeline' : 301,
'jobBole.pipelines.MongoDBTwistedPipline': 302
IMAGES_STORE = 'D:\\SunWork\\python\\jobBole'
MONGODB_HOST = '127.0.0.1'
MONGODB_PORT = 27017
MONGODB_DBNAME = 'bole'
MONGODB_SHEETNAME = 'bolePaper'
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import scrapy
from scrapy.pipelines.images import ImagesPipeline
import codecs
import json
import pymongo
from scrapy.conf import settings
class JobbolePipeline(object):
'''
返回json数据到文件中
'''
def __init__(self):
self.file = codecs.open("article.json", 'w',encoding='utf-8')
def process_item(self, item, spider):
print('@@@@@@@@@@ ', item)
lines = json.dumps(dict(item), ensure_ascii=False) + "\\n"
self.file.write(lines)
return item
def spider_closed(self, spider):
self.file.close()
class ArticleImagePipeline(ImagesPipeline):
'''
对图片的处理
'''
def get_media_requests(self, item, info):
for image_url in item['front_image_url']:
yield scrapy.Request(image_url)
def item_completed(self, results, item, info):
for ok, value in results:
if ok:
image_file_path = value['path']
item['front_image_path'] = image_file_path
else:
item['front_image_path'] = ""
return item
class MongoDBTwistedPipline(object):
def __init__(self):
#主机
host = settings["MONGODB_HOST"]
#端口
port = settings["MONGODB_PORT"]
#数据库名
dbname = settings["MONGODB_DBNAME"]
#数据表名
sheetname = settings["MONGODB_SHEETNAME"]
#创建MONGODB数据库
client = pymongo.MongoClient(host=host, port=port)
#指定数据库
mydb = client[dbname]
#指定数据表
self.post = mydb[sheetname]
def process_item(self, item, spider):
data = dict(item)
self.post.insert(data)
return item
注:代码来源https://www.cnblogs.com/zhaof/p/7173094.html。在此基础上进行部分修改。
以上是关于第八课 常用机器学习算法性能对比的主要内容,如果未能解决你的问题,请参考以下文章