如何制作3层的PDF电子书
Posted zhaorufei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何制作3层的PDF电子书相关的知识,希望对你有一定的参考价值。
先说一下双层PDF,它是指同时有图像层和文字层的PDF,是相对仅有一个图像层的PDF而言。其优点是既能得到扫描图像的细腻质感,又兼有可搜索可复制文字的便利。
双层PDF的文字层一般由OCR 工具生成。比如一些扫描仪附带软件,以及第三方的OCR软件如 Abbyy。
再来说下三层PDF,3层PDF是既要又要还要的产物。既要高保真的插图的质感,又要文字部分黑白分明的清晰锐利,还要文字可搜索可复制。在满足这一切时,文件还得足够小。
核心需求是文件大小,如果不要求文件大小,回到双层PDF即可。
有了需求,再来说说多层PDF的每一层,都对应什么需求,首先是OCR所得之文字层,其它的所有层,都是平衡文件大小与视觉效果的产物。
比如上面单提的一条:文字黑白分明清晰税利,这一条可通过把文字主体处理成黑白图像模式达成,代表软件是 ScanTailor Advanced和老马的
ComicEnhancedPro,主要是通过二值化达到。这一条附带的一项红利: Group4 压缩算法能带来极小的文件尺寸,目前我试验过的针对二值图像的无损压缩算法中,压缩比最高。
既有了上面的二值图像,又要看到丰富细腻的插图,而且插图还可能是彩色的。就需要另一个独立的图像来保存彩色的部分。一页内有一幅这样的插图,就把你带到了3层PDF。
如有多幅插图,就自然产生了N>3 层的PDF文件了。
多张彩色插图自然可以保存在同一层中,但如此一来,文件大小也就变大了,实测一页中上下两幅bpp8的灰度插图的文件,独立保存成两个图像对象的PDF 明显更小。
下面是重点,即制作工艺。我是从既有的PDF电子书开始二次创作。
原料往往是单层的纯图像的PDF。
1. 提取PDF 中每一页的图像文件,我用 PDF Patcher, 注意要用它的提取图片功能,不是保存每页为图像,前者不会产生质量损失。得到所有的图像文件之后。观察图像文件的尺寸.
宽度1000 左右的是一类,宽度2000 左右的是另一类。这两类我见的最多, 其它的不讨论,对于宽度1000的,回头需要缩放,宽度是2000 或以上的,不需要缩放。我的经验是每个汉字有
40像素左右宽高时,在从电脑屏到手机屏的常见尺寸的屏幕上阅读,观感都不错。而宽度在2000 pixels以上的文件,可以达到此标准.
1.1 对宽度1000 左右的文件,强行指定其分辨率
dir/b/a-d | rush "mogrify -density 150x150 -units PixelsPerInch "
来处理, rush 是并行处理的工具。
1.2 对宽度在2000+ 的文件,仍要强行指定其分辨率
dir/b/a-d | rush "mogrify -density 300x300 -units PixelsPerInch "
2. 在Acdsee 中查看所有文件的缩略图,用CTRL+鼠标单击的方式,把所有的文件分为两类,一类是含有插图的,一类是没有插图的,分别以两个文件夹单独保存。
3. 用 ScanTailor 处理含有插图的部分. 因为ScanTailor 有混合模式,可以在做二值化时排除指定的图像区域, 被排除的图像区域,既可以让软件自行检测,也可以手工指定。
我都是手工指定.
注意在下面选中300的输出分辨率。模式务必选中Mixed。指的是图文混合。

3.1 把Picture Shape改成 Off:

注意改了之后,要点 Apply To...把它应用到所有图像的处理上去:

这样可以让不要自动检测图像区域,全手工指定
设置之后,要点击 Picture Zone 这个Tab:

在此通过鼠标操作选中图像的部分,这样二值化就会排除这些部分,此处选择不要纠结,大一点没关系,按住CTRL的同时,单击
鼠标左键, 会开始画一个矩形,鼠标调整矩形大小时, 不需要再保持CTRL按下的状态,松开即可,鼠标再次点击时矩形就被定义了。
这个过程是最繁琐的,需要每个文件独立操作,ScanTailor 每切换一个文件时,也会比较慢。
4. 对于不含插图的图像文件, 用老马的 ComicEnhancerPro (我的版本是 6.01 ) 做二值化。
这个软件速度比ScanTailor Advanced快出太多,而且其二值化的选项也很多,其二值化功能是妥妥超过STA的。但遗憾的是不支持
图文混排情况下的二值化。
5. 对第3步生成的混排TIF 文件,进行图文分层,这一步在Photoshop中完成,用鼠标选中插图,然后
在矩形选区中右键,“通过剪切的图层", 要想文件最小, 每个插图要独立成层
5.1 对承载黑白的背景层,要进行特殊的处理,反色,快捷键是CTRL+I,其原因与后面的Enfocus PitStop 的一个操作步骤的特点有关。
5.2 将图像保存为多层TIF 文件。为了文件大小故,都不要选ICC了。PS 中的TIFF保存选项中, 可选的RLE,ZIP, LZW压缩也都是无损的,
此时还是中间步骤,中间过程中不要使用有损压缩,避免累计图像质量损失。
这一步是鼠标密集型操作,说点感想,搭配录制动作和快捷键之后,这一步的繁琐就大为减轻,右手鼠标画矩形选区,左手常放在录制动作的
快捷键上,2~4秒一张图
6. 用 Adobe Illustrator (以下简称AI)将第5步产生的多层TIF文件转换为多层PDF文件,这是制作3层PDF的关键之一,因为面对第5步产生的多层TIF文件,
其它的工具如 tiffcp, imagemagick convert, FreePic2PDF 等,都无法象AI那样生成单页多图的PDF, 要么是多页多图(每层一图), 要么是单页单图(
合并所有层,或只取其中一层). 最令人意外的是,photoshop自身本可以在第5步直接把多层内容保存为PDF文件的,但它生成的PDF只是单页单图。
这一步操作好在AI 也是可以做批处理的,我的试验中,AI 2023版本比AI CS6 慢太多,CS6 几乎是每秒一个文件。
录制的动作虽只有一个保存文件的动作,其细节却很关键。一定不要在此时重新采样或采用有损压缩。
此时保存出来的PDF文件中,文字层仍是黑白反相的,这是第5步中PS里那一步的结果。下一步会让它转正。
6.1 把前一步产生的每页一个PDF文件组合为单个PDF文件,方便后续操作。用Acrobat合并, 每个文件会产生对应的一个书签。(此处为伏笔)
7. Enfocus PitStop 2022 插件中,把前一步中产生的PDF的文字层颜色空间改为索引。CTRL+ALT+A 调出动作,自定义一个动作:
7.1 第一个动作是选中目标对象,也就是黑白文字的这个图像对象,我的办法是按图像大小选择,比如目标页面是2000像素左右,
指定宽度大于1800 像素的即可
7.2 针对7.1 步骤选中的图像对象,执行“将图像转换为索引色彩空间"

这一步的作用是让多层PDF中的文字层接下来能以1bpp 的方式存储,这样它才能用上 Group4(image magick 中 -compress选项指定 CCITTFAX 4 的关键词).
这一步骤之后,文字层原来黑白反相的内容会进行黑白对调,这是pitstop这一操作的一个副作用,正因如此,才会在第5步中PS里操作里,提前把该层反相。
此时所有的图文混排的页面都在同一个PDF 文件中了,但这时的文件还只是图文混排的文件。还需要跟另一类纯黑白文字层的TIF 按正确的页序合并为一个PDF文件,这样才
原来的整本书。
8. 将第7步的单个PDF 再还原为每页一个PDF 文件,仍用 Acrobat,我的 Acrobat 9 Pro中,操作是: 文档->拆分文档, 设置如下:

最好指定输出到一个干净的文件夹中。
9. 将纯黑白文字层的TIF文件按 Group4 压缩
dir/b *.tif | rush "mogrify -compress Group4 "
[[ 注: 此类步骤执行时,最好关闭windows的实时病毒防护, proc explorer显示,它有着可观的CPU占用. ]]
此时可以把生成的TIF全部复制到上一步中指定的每页一个PDF的输出文件夹中了,此时文件名就是页码,与原书一一对应。
用 Acrobat 将这些文件合并为单个的PDF文件。
10. 优化PDF文件,在Acrobat(注意不是reader,我不确定现在的reader是否有此功能) 中优化文件。有两个需要关注的优化指令.
一是图像压缩:

另一是清理用户数据:
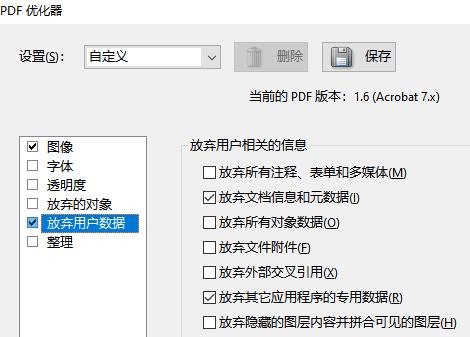
根据我对操作结果的分析,以上两项对应着 AI 生成的PDF 文件中的不必要的数据。
对非黑白图像,最终采用的有损压缩发生在这里,这一步是图像处理部分的终章。
我的经验,JPEG 中等质量压缩,几乎看不出任何差距。但文件尺寸却是大大减小。
11. OCR
到此为止,还缺少关键的OCR文字层,这一步很简单,最新的Abbyy 15中,可以直接打开整个PDF, OCR之后选择另存为双层PDF, 图像在上文字在下。
此时我们得到了一个双层PDF文件。这个文件应该是当今99.99%双层PDF文件的样态。它的图像存储方面,还欠优化,它所欠缺的优化,我们在第10步已经达成。
下一步,进行图文合并。根据我对Abbyy的使用经验,无法在达到前面步骤所得的图像存储方面的优化。
12. 迁移OCR: Enfocus PitStop 2022 64-bit 插件
这一关键步骤中所用的PitStop 插件功能,这一版本中有,但该插件的32位版本17中还是没有的。
12.1 对上一步骤中通过 Abbyy 所得的双层PDF, 需要去除其所有图像,留下仅含不可见的OCR文字层的PDF文件。这一步骤也通过 PitStop完成,但这一步骤在版本17也可完成。
方法同上,自定义动作,先选中图像,再加一个移除的动作。此时得到一个看似空白的PDF文件,但它含有关键的OCR文字层。
12.2 用装了 PitStop 2022插件的Acrobat 打开步骤10 中的PDF文件。定义如下动作:(原图过大,略作处理)
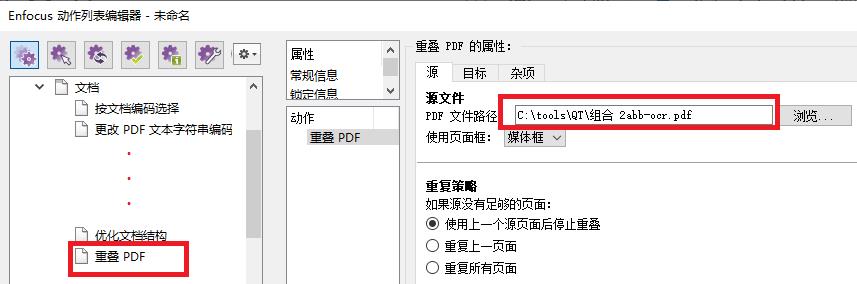
这个重叠PDF功能, 就是把包含 OCR文字层的PDF,逐页地把每一页的文字层内容,重叠到当前PDF中的对应页上去。
13. 至此,3层PDF制作就基本完成了,但作为一个方便阅读的PDF文件,还需要书签和内嵌索引(能极大提高Acrobat 类软件的搜索速度)两项。
书签制作我仍是推荐老马的 FreePic2PDF, 配合前面的Abbyy OCR步骤,已经产生了书签的内容。加上vim中的正则表达式操作,该步骤很快就可完成。
至于内嵌索引,在Adobe中一步就可完成。
感谢老马的诸多软件,实在是国内电子书处理的集大成者。 感谢PDF补丁丁的作者 WMJordan,它的提取图片功能比Acrobat 快太多了,文档结构探查对于本文
研究PDF文件的内部构成帮助很大。
iebook制作问题:如何将已有的pdf文档利用电子杂志制作软件做成电子杂志。
我现在有一些pdf文档需要做成电子期刊杂志,请大家推荐个软件,或者告诉我iebook如何实现。
多谢wma999,不过这个属于短期需要,所以公司不会付费买的,不一定要可以直接转的,有可行方法,比如将pdf转换为什么再导入电子杂志制作软件也可以。把使用的工具说清楚就ok啦。再辛苦下大家。
zmaker.zcom.com上有下载试用版.
以上是关于如何制作3层的PDF电子书的主要内容,如果未能解决你的问题,请参考以下文章