ChunJun FTP Connector 功能扩展解读
Posted 数栈DTinsight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ChunJun FTP Connector 功能扩展解读相关的知识,希望对你有一定的参考价值。
本文将从 FTP Connector 的功能详解,自定义文件切割及自定义 FileFormat 三个方面为大家带来 ChunJun FTP Connector 的功能扩展分享。
FTP Connector 详解
FTP 是用于在网络上进行文件传输的一套标准协议,它工作在 OSI 模型的第七层, TCP 模型的第四层, 即应用层,提供一种在服务器和客户机之间上传和下载文件的有效方式。
FTP Connector 基本功能
ChunJun FTP Connector 基本功能如下:
· 支持 FTP 协议 与 SFTP 协议读写;
· 支持断点续传;
· 支持并发读写;
· 支持多种文件格式的读写。
断点续传
主要的类:Position,Data,FtpFileReader,代码如下:
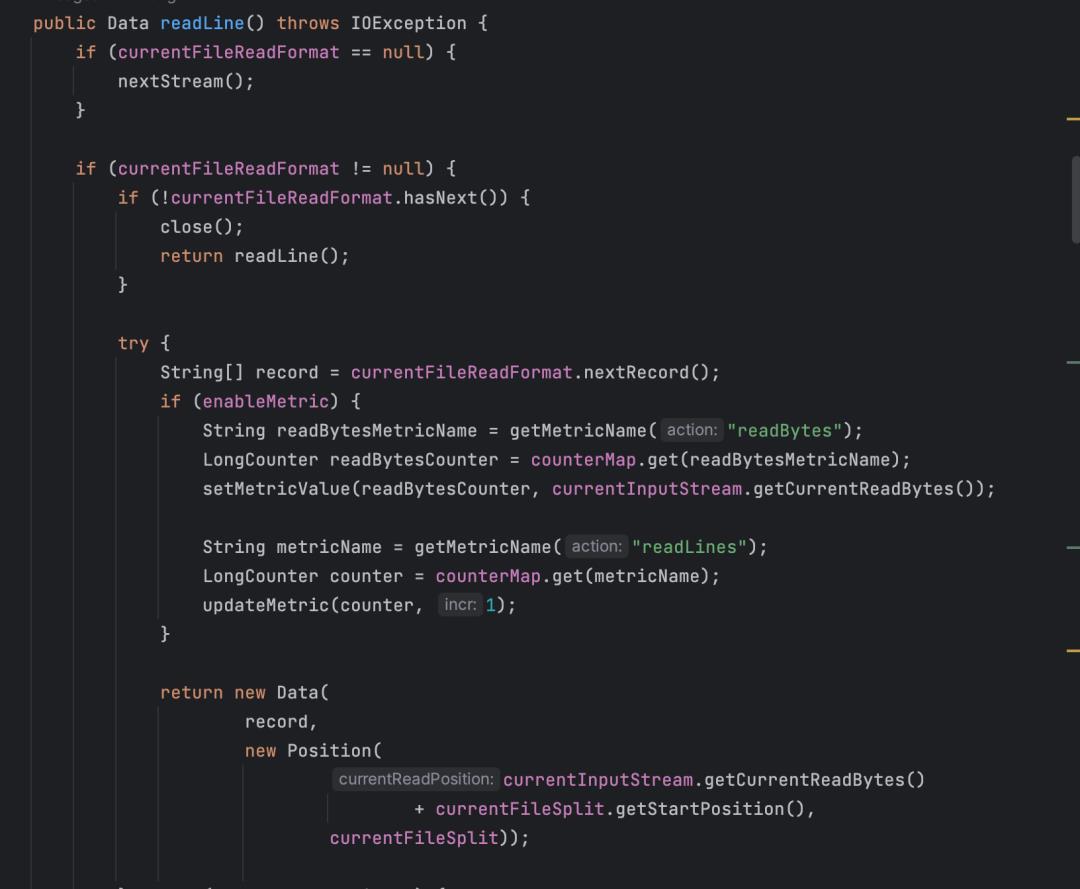

并发读写
代码如下:
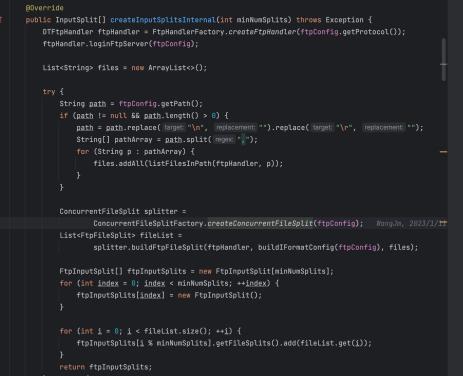
自定义文件切割
ConcurrentFileSplitFactory 像一个工厂,通过这个工厂去创建其他的类,包括 ConcurrentZipCompressSplit、ConcurrentCsvSplit 以及默认的 DefaultFileSplit,类结构如下图:
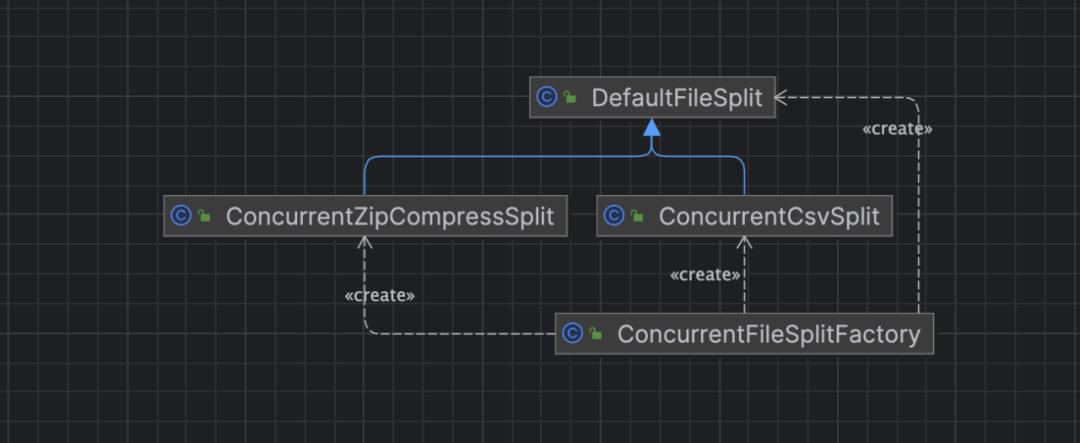
处理流程
FTP 读取文件时,通过 ConcurrentFileSplit 对文件进行切割,切割成多个 FTPFileSplit,配置到 Channel 中,最后根据 FileSplit 保存的信息,自定义读取文件。

处理逻辑
· 使用 maxFetchSize 配置,当同步的文件大于这个值时,开启大文件切割功能
· 对文件进行分析,构建分片,以文件大小1.2G、分片数4举例,每个分片数处理的数据量约等于1.2G / 4 = 300M
其中使用的分片构建算法逻辑如下:
1)从第300M偏移量开始读文件,按单个字节遍历文件,记录下一个\'\\n\'的文件偏移量,如300.1M,第一个分片处理文件的范围就是0~ 300.1M
2)第二个分片从 300.1M + 300M开始读文件,遍历文件,记录下一个\'\\n\'的文件偏移量,如600.3M,第二个分片处理文件的范围就是300.1M~ 600.3M
3)以此类推, 构建完所有的分片
· 单个文件的数据在多个通道并发读取后,写入目标表时,无法对多个通道的数据按原文件中记录的顺序进行写入
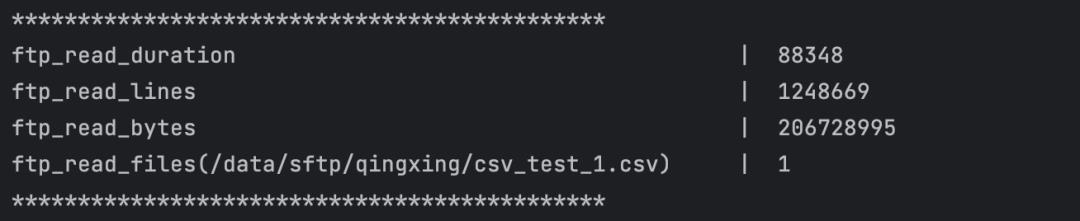
单个并行度读取耗时为122s:
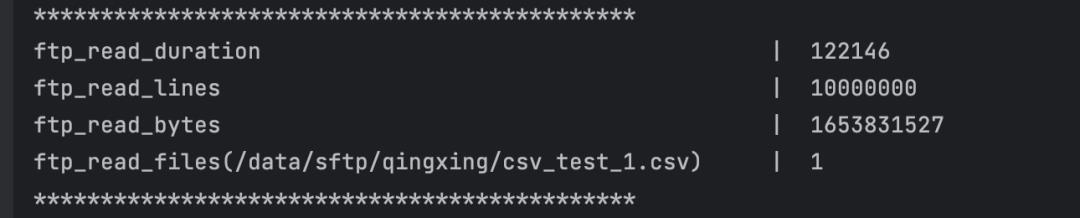
8个并行度读取平均耗时为88s:
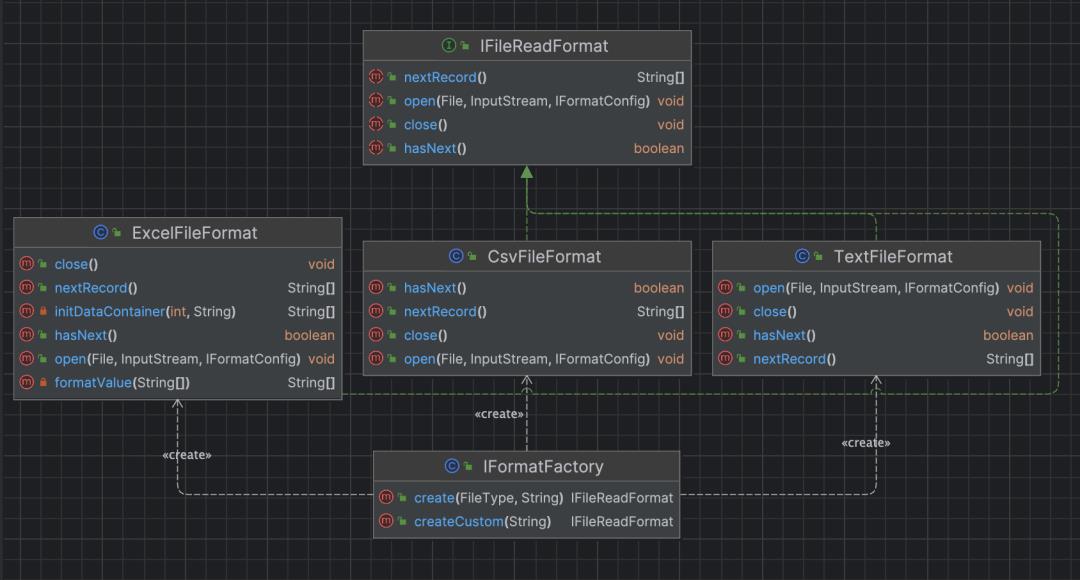
自定义 FileFormat
自定义 FlieFormat 同样是以工厂模式实现的,ChunJun 目前已实现 Excel、Csv、Text 三种文件结构,当前仍然局限于 FTP,后续会扩展成公共模块,独属于 ChunJun 的 Format。类结构如下图:
ChunJun 设计方案
FTP 增加的功能点如下:
· FTP支持用户自定义解析方式;
· FTP 支持自定义数据转换。
针对上述新增功能点 ChunJun 设计方案如下:
· FTP soource 新增参数 customFormatClassName:自定义解析器类名
· 抽象出公共模块,定义解析器接口 IFileReadFormat ,解析方式由用户实现以及 ChunJun 自带的实现
大量具体代码请看视频教程⬇️:
视频课程&PPT获取
视频课程:
https://www.bilibili.com/video/BV1Gm4y1a7Fv/?spm_id_from=333.999.0.0
课件获取:
https://www.dtstack.com/resources/1044
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
详解 Flink Catalog 在 ChunJun 中的实践之路
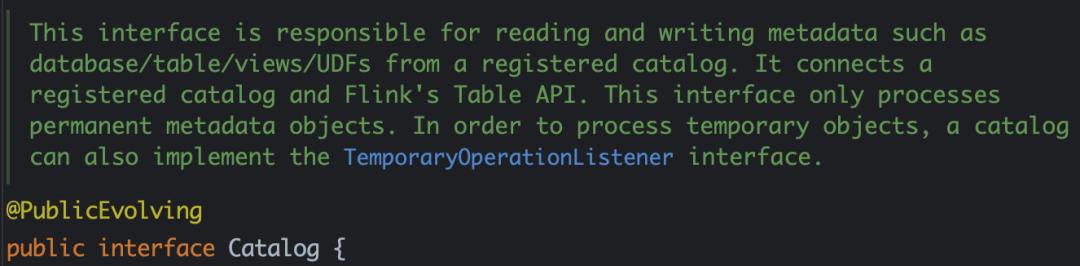
我们知道 Flink 有Table(表)、View(视图)、Function(函数/算子)、Database(数据库)的概念,相对于这些耳熟能详的概念,Flink 里还有一个 Catalog(目录) 的概念。
本文将为大家带来 Flink Catalog 的介绍以及 Flink Catalog 在 ChunJun 中的实践之路。
Flink Catalog 简介
Catalog 提供元数据,如数据库、表、分区、视图,以及访问存储在数据库或其他外部系统中的数据所需的函数和信息。
Flink Catalog 作用
数据处理中最关键的一个方面是管理元数据:
· 可能是暂时性的元数据,如临时表,或针对表环境注册的 UDFs;
· 或者是永久性的元数据,比如 Hive 元存储中的元数据。
Catalog 提供了一个统一的 API 来管理元数据,并使其可以从表 API 和 SQL 查询语句中来访问。
Catalog 使用户能够引用他们数据系统中的现有元数据,并自动将它们映射到 Flink 的相应元数据。例如,Flink 可以将 JDBC 表自动映射到 Flink 表,用户不必在 Flink 中手动重写 DDL。Catalog 大大简化了用户现有系统开始使用 Flink 所需的步骤,并增强了用户体验。
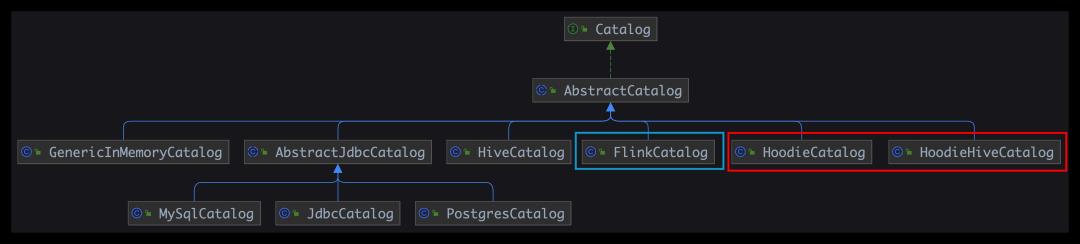
Flink Catalog 的结构
● Flink Catalog 原生结构
• GenericInMemoryCatalog:基于内存实现的 Catalog
• Jdbc Catalog:可以将 Flink 通过 JDBC 协议连接到关系数据库,目前 Flink 在1.12和1.13中有不同的实现,包括 MySql Catalog 和 Postgres Catalog
• Hive Catalog:作为原生 Flink 元数据的持久化存储,以及作为读写现有 Hive 元数据的接口
● Flink Iceberg Catalog
● Flink Hudi Catalog
HoodieCatalog、HoodieHiveCatalog
Flink Catalog 详解
GenericInMemoryCatalog
final CatalogManager catalogManager =
CatalogManager.newBuilder()
.classLoader(userClassLoader)
.config(tableConfig)
.defaultCatalog(
settings.getBuiltInCatalogName(),
new GenericInMemoryCatalog(
settings.getBuiltInCatalogName(),
settings.getBuiltInDatabaseName()))
.build();
defaultCatalog =
new GenericInMemoryCatalog(
defaultCatalogName, settings.getBuiltInDatabaseName());
CatalogManager catalogManager =
builder.defaultCatalog(defaultCatalogName, defaultCatalog).build();
GenericInMemoryCatalog 所有的数据都保存在 HashMap 里面,无法持久化。
JDBC Catalog
CREATE CATALOG my_catalog WITH(
\'type\' = \'jdbc\',
\'default-database\' = \'...\',
\'username\' = \'...\',
\'password\' = \'...\',
\'base-url\' = \'...\'
);
USE CATALOG my_catalog;
如果创建并使用 Postgres Catalog 或 MySQL Catalog,请配置 JDBC 连接器和相应的驱动。
JDBC Catalog 支持以下参数:
• name:必填,Catalog 的名称
• default-database:必填,默认要连接的数据库
• username:必填,Postgres/MySQL 账户的用户名
• password:必填,账户的密码
• base-url: 必填,(不应该包含数据库名)
对于 Postgres Catalog base-url 应为 "jdbc:postgresql://:" 的格式
对于 MySQL Catalog base-url 应为 "jdbc:mysql://:" 的格式
Hive Catalog
CREATE CATALOG myhive WITH (
\'type\' = \'hive\',
\'default-database\' = \'mydatabase\',
\'hive-conf-dir\' = \'/opt/hive-conf\'
);
-- set the HiveCatalog as the current catalog of the session
USE CATALOG myhive;

Iceberg Catalog
● Hive Catalog 管理 Iceberg 表
(Flink) default_database.flink_table ->
(Iceberg) default_database.flink_table
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
\'connector\'=\'iceberg\',
\'catalog-name\'=\'hive_prod\',
\'uri\'=\'thrift://localhost:9083\',
\'warehouse\'=\'hdfs://nn:8020/path/to/warehouse\'
);
(Flink)default_database.flink_table ->
(Iceberg) hive_db.hive_iceberg_table
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
\'connector\'=\'iceberg\',
\'catalog-name\'=\'hive_prod\',
\'catalog-database\'=\'hive_db\',
\'catalog-table\'=\'hive_iceberg_table\',
\'uri\'=\'thrift://localhost:9083\',
\'warehouse\'=\'hdfs://nn:8020/path/to/warehouse\'
);
● Hadoop Catalog 管理 Iceberg 表
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
\'connector\'=\'iceberg\',
\'catalog-name\'=\'hadoop_prod\',
\'catalog-type\'=\'hadoop\',
\'warehouse\'=\'hdfs://nn:8020/path/to/warehouse\'
);
● 自定义 Catalog 管理 Iceberg 表
CREATE TABLE flink_table (
id BIGINT,
data STRING
) WITH (
\'connector\'=\'iceberg\',
\'catalog-name\'=\'custom_prod\',
\'catalog-impl\'=\'com.my.custom.CatalogImpl\',
-- More table properties for the customized catalog
\'my-additional-catalog-config\'=\'my-value\',
...
);
• connector:iceberg
• catalog-name:用户指定的目录名称,这是必须的,因为连接器没有任何默认值
• catalog-type:内置目录的 hive 或 hadoop(默认为hive),或者对于使用 catalog-impl 的自定义目录实现,不做设置
• catalog-impl:自定义目录实现的全限定类名,如果 catalog-type 没有被设置,则必须被设置,更多细节请参见自定义目录
• catalog-database: 后台目录中的 iceberg 数据库名称,默认使用当前的 Flink 数据库名称
• catalog-table: 后台目录中的冰山表名,默认使用 Flink CREATE TABLE 句子中的表名
Hudi Catalog
create catalog hudi with(
\'type\' = \'hudi\',
\'mode\' = \'hms\',
\'hive.conf.dir\'=\'/etc/hive/conf\'
);
--- 创建数据库供hudi使用
create database hudi.hudidb;
--- order表
CREATE TABLE hudi.hudidb.orders_hudi(
uuid INT,
ts INT,
num INT,
PRIMARY KEY(uuid) NOT ENFORCED
) WITH (
\'connector\' = \'hudi\',
\'table.type\' = \'MERGE_ON_READ\'
);
select * from hudi.hudidb.orders_hudi;
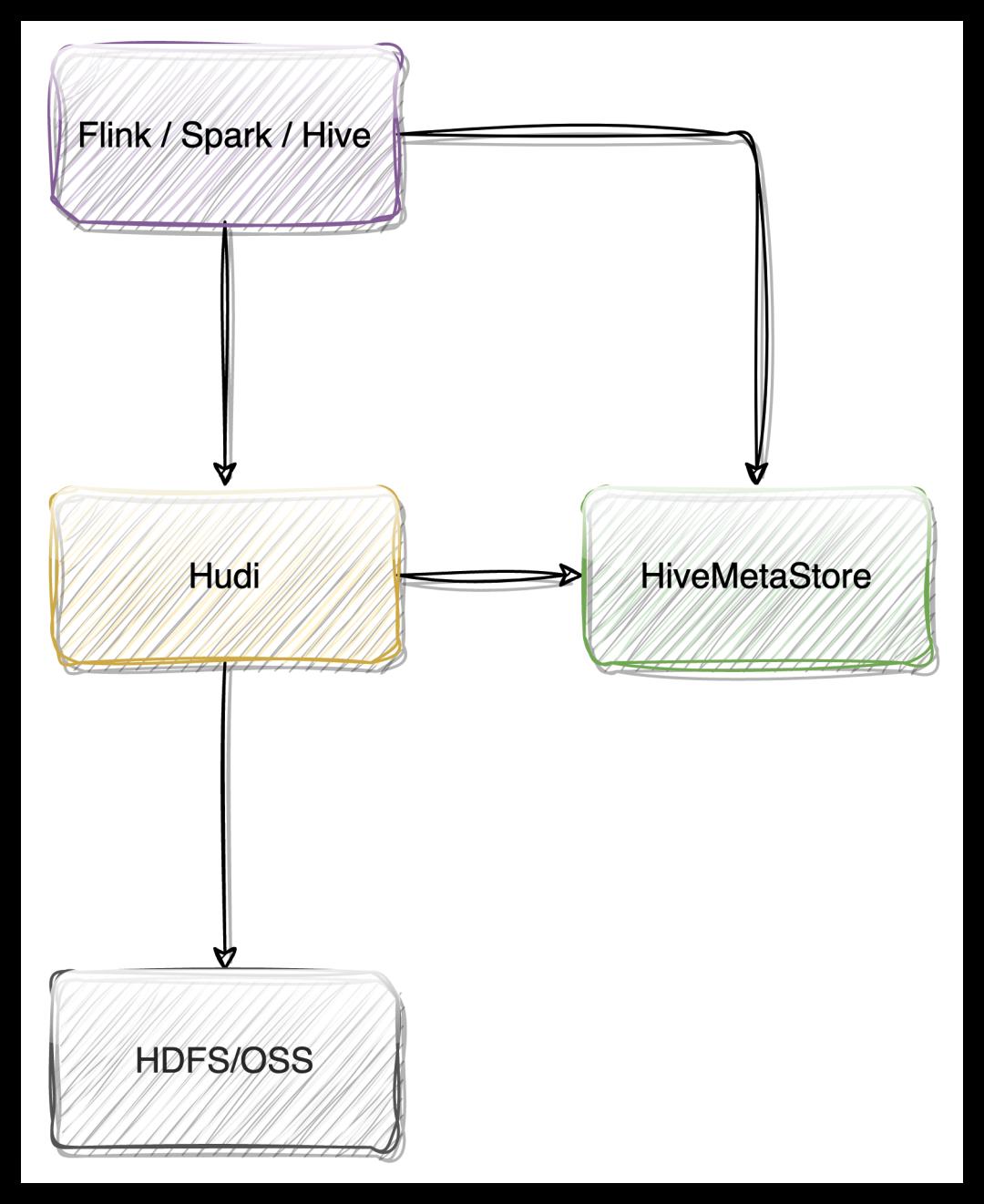

Flink Catalog 在 ChunJun 中的实践
下面将为大家介绍本文的重头戏,Flink Catalog 在 ChunJun 中的实践之路。
直接引入开源 Catalog
ChunJun 目前的所有 Catalog 为以下四种:

● Hive Catalog 需要的依赖
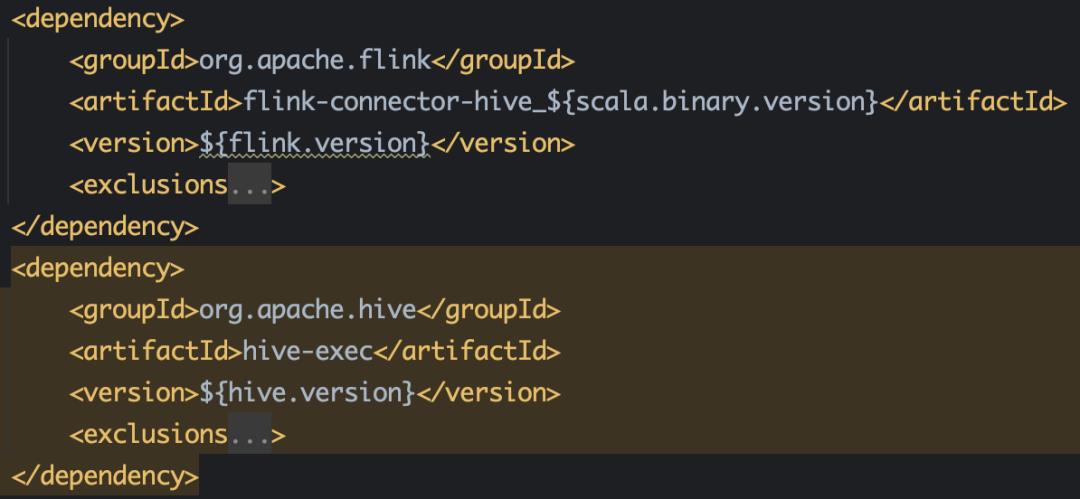
● Iceberg Catalog 需要的依赖

● JDBC Catalog
JDBC 因为 Flink 1.12 和 1.13 API 有变化,因此需要涉及源码的改动,改动一些 API 后,从源码引入。
● DT Catalog
结合内部业务,自定义的一种 Catalog ,下文将会进行详细介绍。
DT Catalog -存储元数据表设计
● 创建 mysql 元数据表 database_info
-- 创建表的 sql
create table database_info
(
`id` bigint PRIMARY KEY NOT NULL AUTO_INCREMENT COMMENT \'项目ID\',-- database id
`catalog_name` varchar(255) COMMENT \'catalog 名字\',
`database_name` varchar(255) COMMENT \'database 名字\',
`catalog_type` varchar(30) COMMENT \'catalog 类型, eg: mysql,oracle...\',
`project_id` int(11) NOT NULL COMMENT \'项目ID\',
`tenant_id` int(11) NOT NULL COMMENT \'租户ID\'
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
-- 创建索引
CREATE INDEX idx_catalog_name_database_name_project_id_tenant_id ON database_info (`catalog_name`, `database_name`, `project_id`, `tenant_id`);
● 创建 mysql 元数据表 table_info
-- 创建表的 sql
create table table_info
(
`id` bigint PRIMARY KEY NOT NULL AUTO_INCREMENT,
`database_id` bigint COMMENT \'database_info 表的 id\',
`table_name` varchar(255) COMMENT \'表名\',
`project_id` int(11) NOT NULL COMMENT \'项目ID\',
`tenant_id` int(11) NOT NULL COMMENT \'租户ID\'
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
-- 创建索引
CREATE INDEX idx_catalog_id_project_id_tenant_id ON table_info (`database_id`, `project_id`, `tenant_id`);
CREATE INDEX idx_database_id_table_name_project_id_tenant_id ON table_info (`database_id`, `table_name`, `project_id`, `tenant_id`);
● 创建 mysql 元数据表 properties_info
create table properties_info
(
`id` bigint PRIMARY KEY NOT NULL AUTO_INCREMENT ,
`table_id` bigint(20) COMMENT \'table_info 表的 id\',
`key` varchar(255) COMMENT \'表的属性 key\',
`value` varchar(255) COMMENT \'表的属性 value\'
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
CREATE INDEX idx_table_id ON properties_info (table_id);
● properties_info 里面存了什么?
schema.0.name=id,
schema.0.data-type=INT NOT NULL,
schema.1.name=name,
schema.1.data-type=VARCHAR(2147483647)
schema.2.name=age,
schema.2.data-type=BIGINT,
schema.primary-key.name=PK_3386,
schema.primary-key.columns=id,
connector=jdbc,
url=jdbc:mysql: //172.16.83.218:3306/wujuan?useSSL=false,
username=drpeco,
password=DT@Stack#123,
comment=,
scan.auto-commit=true,
lookup.cache.max-rows=20000,
scan.fetch-size=10,
lookup.cache.ttl=700000
table-name=t2,
使用 DT Catalog
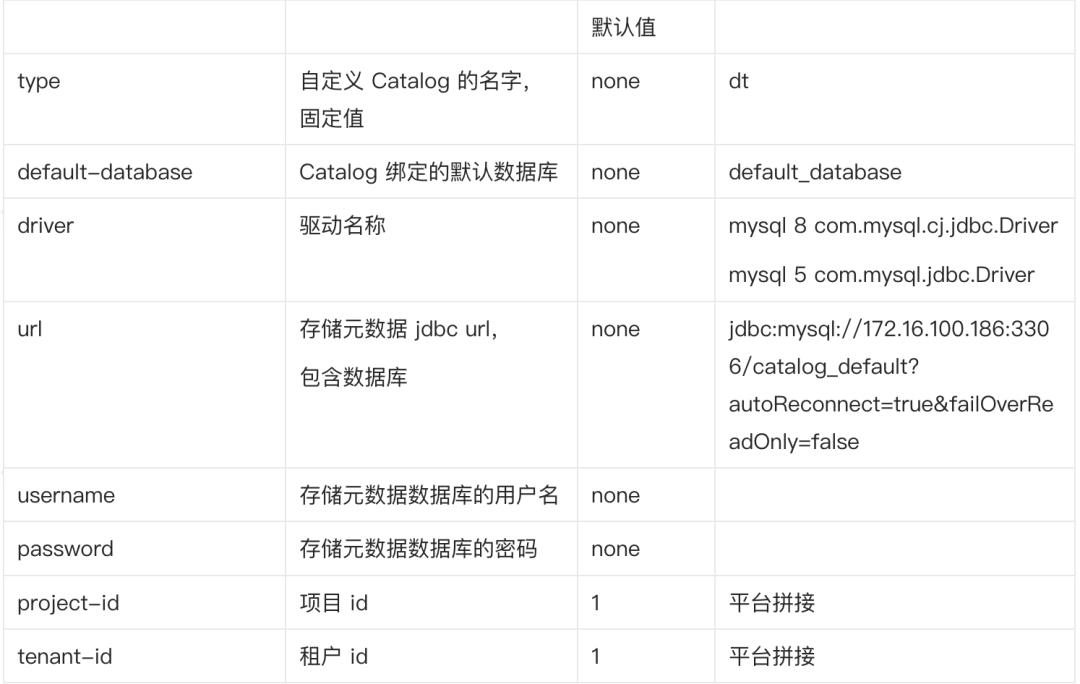
● 创建 DT Catalog
CREATE CATALOG catalog1
WITH (
\'type\' = \'dt\',
\'default-database\' = \'default_database\',
\'driver\' = \'com.mysql.cj.jdbc.Driver\',
\'url\' = \'jdbc:mysql://xxx:3306/catalog_default\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\',
\'project-id\' = \'1\',
\'tenant-id\' = \'1\'
);
● 创建 Database
DROP DATABASE [IF EXISTS] [catalog_name.]db_name [ (RESTRICT | CASCADE) ]
Drop a database with the given database name. If the database to drop does not exist, an exception is thrown.
IF EXISTS
If the database does not exist, nothing happens.
RESTRICT
Dropping a non-empty database triggers an exception. Enabled by default.
CASCADE
Dropping a non-empty database also drops all associated tables and functions.
create database if not exists catalog1.database1
drop database if exists catalog1.database1
-- 删除非空数据库,连通数据库中的所有表也一起删除
drop database if exists catalog1.database1 CASCADE
● 创建 Table
1)Rename Table
ALTER TABLE [catalog_name.][db_name.]table_name RENAME TO new_table_name
Rename the given table name to another new table name
2)Set or Alter Table Properties
ALTER TABLE [catalog_name.][db_name.]table_name SET (key1=val1, key2=val2, ...)
Set one or more properties in the specified table. If a particular property is already set in the table, override the old value with the new one.
-- 创建表
CREATE TABLE if not exists catalog1.default_database.table1
(
id int,
name string,
age bigint,
primary key ( id) not enforced
) with (
\'connector\' = \'jdbc\',
\'url\' = \'jdbc:mysql://172.16.83.218:3306/wujuan?useSSL=false\',
\'table-name\' = \'t2\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\'
);
-- 删除表
drop table if exists mysql_catalog2.wujuan_database2.wujuan_table
-- 重命名表名
ALTER TABLE catalog1.default_database.table1 RENAME TO table2;
-- 设置表属性
ALTER TABLE catalog1.default_database.table1
SET (
\'tablename\'=\'t2\',
\'url\'=\'dbc:mysql://172.16.83.218:3306/wujuan?useSSL=false\'
)
使用 DTCatalog 的具体场景和实现原理
● 全部是 DDL,只有 Catalog 的创建
CREATE CATALOG catalog1
WITH (
\'type\' = \'DT\',
\'default-database\' = \'default_database\',
\'driver\' = \'com.mysql.cj.jdbc.Driver\',
\'url\' = \'jdbc:mysql://172.16.100.186:3306/catalog_default?autoReconnect=true&failOverReadOnly=false\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\',
\'project-id\' = \'1\',
\'tenant-id\' = \'1\'
);
```
· 可以执行,但是没有意义,ChunJun 不会存储 Catalog 信息,只有平台存储;
· 不支持语法校验。
● 全部是 DDL,包含 Catalog、Database、Table 的创建
-- 初始化 Catalog
CREATE CATALOG catalog1
WITH (
\'type\' = \'dt\',
\'default-database\' = \'default_database\',
\'driver\' = \'com.mysql.cj.jdbc.Driver\',
\'url\' = \'jdbc:mysql://172.16.100.186:3306/catalog_default\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\',
\'project-id\' = \'1\',
\'tenant-id\' = \'1\'
);
-- 创建数据库
create database if not exists database1
-- 创建表
CREATE TABLE if not exists catalog1.default_database.table1
(
id int,
name string,
age bigint,
primary key ( id) not enforced
) with (
\'connector\' = \'jdbc\',
\'url\' = \'jdbc:mysql://172.16.83.218:3306/wujuan?useSSL=false\',
\'table-name\' = \'t2\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\'
);
· 无论创建数据库、表,删除数据库、表,必须包含 create catalog 语句;
· 可以执行,可以创建数据库和表;
· 不支持语法校验。
// 抛出异常的逻辑
StatementSet statementSet = SqlParser.parseSql(job, jarUrlList, tEnv);
TableResult execute = statementSet.execute(); -->
tableEnvironment.executeInternal(operations); -->
Pipeline pipeline = execEnv.createPipeline(transformations, tableConfig, jobName); -->
StreamGraph streamGraph = ExecutorUtils.generateStreamGraph(getExecutionEnvironment(), transformations); -->
// 抛出异常的方法
public static StreamGraph generateStreamGraph(StreamExecutionEnvironment execEnv, List<Transformation<?>> transformations)
if (transformations.size() <= 0)
throw new IllegalStateException(
"No operators defined in streaming topology. Cannot generate StreamGraph.");
...
return generator.generate();
// 如果没有 insert 语句的时候,无法生成 JobGraph,但是 DDL 是执行成功的。
// 因此捕获 FlinkX 抛出的特殊异常,此语句的异常 Message 是 FlinkX 里面处理的。
try
PackagedProgramUtils.createJobGraph(program, flinkConfig, 1, false);
catch (ProgramInvocationException e)
// 仅执行 DDL FlinkX 抛出的异常
if (!e.getMessage().contains("OnlyExecuteDDL"))
throw e;

● DDL + DML,包含 create + insert 语句
1)初始化 Catalog
CREATE CATALOG catalog1
WITH (
\'type\' = \'dt\',
\'default-database\' = \'default_database\',
\'driver\' = \'com.mysql.cj.jdbc.Driver\',
\'url\' = \'jdbc:mysql://172.16.100.186:3306/catalog_default\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\',
\'project-id\' = \'1\',
\'tenant-id\' = \'1\'
);
2.1)创建数据库
create database if not exists database1
2.2)创建源表
CREATE TABLE if not exists catalog1.default_database.table1
(
id int,
name string,
age bigint,
primary key ( id) not enforced
) with (
\'connector\' = \'jdbc\',
\'url\' = \'jdbc:mysql://172.16.83.218:3306/wujuan?useSSL=false\',
\'table-name\' = \'t2\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\'
);
3.1)创建数据库
create database if not exists catalog1.database2;
3.2)创建结果表
CREATE TABLE if not exists catalog1.database2.table2
(
id int,
name string,
age bigint,
primary key ( id) not enforced
) with (
\'connector\' = \'print\'
);
4)执行任务
insert into catalog1.database2.table2 select * from catalog1.database1.table1
· 不可以执行,可以提交;
· 支持语法校验。
● DML,只有 Insert 语句
-- 初始化 Catalog
CREATE CATALOG catalog1
WITH (
\'type\' = \'dt\',
\'default-database\' = \'default_database\',
\'driver\' = \'com.mysql.cj.jdbc.Driver\',
\'url\' = \'jdbc:mysql://172.16.100.186:3306/catalog_default\',
\'username\' = \'drpeco\',
\'password\' = \'DT@Stack#123\',
\'project-id\' = \'1\',
\'tenant-id\' = \'1\'
);
-- 执行任务
insert into catalog1.database2.table2 select * from catalog1.database1.table1
· 如果 Catalog 的 数据库和表都已经创建好了,那么直接写 insert 就可以提交任务;
· 不可以执行,可以提交;
· 支持语法校验。
《数据治理行业实践白皮书》下载地址:https://fs80.cn/380a4b
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack以上是关于ChunJun FTP Connector 功能扩展解读的主要内容,如果未能解决你的问题,请参考以下文章