python爬虫编写英译中小程序
Posted lian8
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫编写英译中小程序相关的知识,希望对你有一定的参考价值。
1.选择一个翻译页面,我选择的是有道词典(http://dict.youdao.com)
2.随便输入一个英语单词进行翻译,然后查看源文件,找到翻译后的内容所在的位置,看它在什么标签里
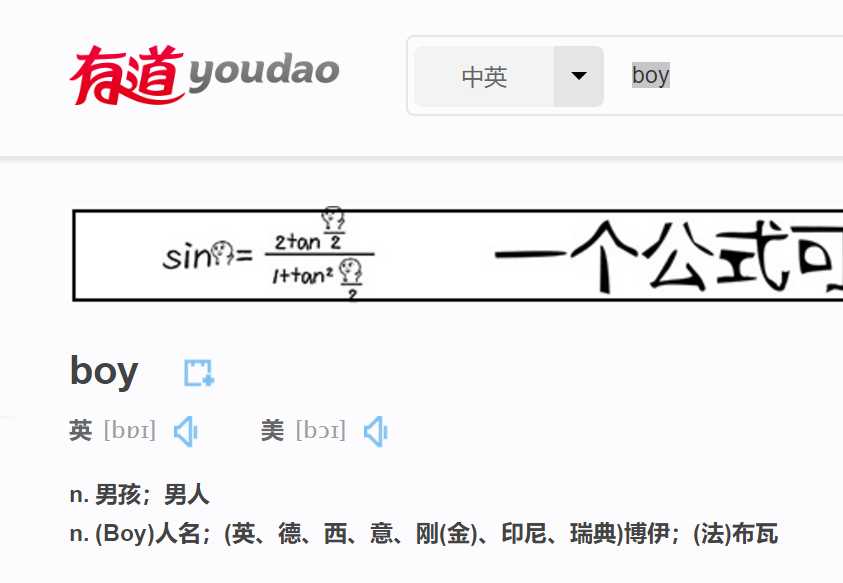

3.开始编写程序
(1)首先引入requests库跟BeautifulSoup库
![]()
(2)更改请求头,防止被页面发现是爬虫,可以在审查元素里找
(3)确定URL,在有道是 http://dict.youdao.com/w/%s/#keyfrom=dict2.top
(4)开始写简单的程序,主要内容就三行
第一步:r = requests.get(url=‘ ‘,headers=)
用requests向页面发出请求,事先写好相应的请求头和URL
第二步:soup = BeautifulSoup(r.text,"lxml")
用BeautifulSoup把获得的text文件,转化为HTML格式
第三步:s = soup.find(class_=‘trans-container‘)(‘ul‘)[0](‘li‘)
.find()方法用于寻找匹配的信息,class、ul、li是所在的标签,这一步根据不同的内容有所不同,
根据源文件相应改变,[0]文本所在位置
(5)进行优化,加入try...except...finally
4.完整程序
1 import requests 2 from bs4 import BeautifulSoup 3 4 word = input("Enter a word (enter ‘q‘ to exit):") 5 header ={‘User-agent‘:‘Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Mobile Safari/537.36‘} 6 while word !=‘q‘: 7 try: 8 r = requests.get(url=‘http://dict.youdao.com/w/%s/#keyfrom=dict2.top‘%word,headers=header) 9 10 soup = BeautifulSoup(r.text,"lxml") 11 12 s = soup.find(class_=‘trans-container‘)(‘ul‘)[0](‘li‘) 13 14 for item in s: 15 if item.text: 16 print(item.text) 17 print(‘=‘*40+‘ ‘) 18 except Exception: 19 print(‘Sorry,there is a error! ‘) 20 finally: 21 word =input("Enter a word (enter ‘q‘ to exit):")
以上是关于python爬虫编写英译中小程序的主要内容,如果未能解决你的问题,请参考以下文章